







1. 背景
1.1 简介
在louvain社区检测中,可以通过计算节点的模块度来确定节点属于哪个社区。模块度是一种衡量网络社区结构优化程度的指标,它衡量了网络内部节点连接紧密度与社区之间连接稀疏度的差异。社区检测算法本质上是一种聚类算法,它旨在将图中的节点分组,使得组内的节点之间有着更紧密的连接,而组间的连接相对较稀疏。
Louvain 是一种基于图数据的社区发现算法,算法的优化目标为最大化整个数据的模块度Q:

其中m为图中边的总数量, 表示所有指向节点 i 的连边权重之和,
表示节点 i,j 之间的连边权重。模块度概念不是Louvain算法发明的,而Louvain算法只是一种优化关系图模块度目标的一种实现而已。
2. 算法思想
具体的步骤如下:
1. 构建网络图:将节点和它们之间的连接关系表示为一个网络图;
2. 计算模块度:使用louvain算法对网络进行社区划分,并计算每个节点的模块度;
3. 确定节点所属社区:根据节点的模块度,将节点划分到具有最大模块度增益的社区中。
算法流程:
1. 初始化,为每个节点分配不同的社区;
2. 遍历节点,按模块度最大化准则归属社区;
3. 合并同社区节点生成新的节点;
4. 构造新图;
5. 重复2-5,直到算法收敛稳定。
在实际使用中发现,louvain 算法会存在大社区合并小社区的现象,不符合实际业务的使用要求,为此对整个流程进行优化,在原流程 3 和 4 之间新增权重更新的步骤:
1. 判断新图边权重是否小于一定比例;
2. 低权重边切断(低权置0)。

3. 在反作弊中的应用
在实际业务场景中,过去作弊者最常使用的方式是低成本批量机器作弊被已经被我们严格打击殆尽,目前也只能逐步迁移成了高成本小批量团伙人为作弊,这是黑产攻击方式的演化趋势,也是风控团队技术发展的必要趋势。
1. 一个电商风控场景:
精准定位了作弊团伙,拦截作弊订单/交易,增强了风险防控能力,联合公司法务部对多个作弊黑产团伙也进行了数次抓捕。风险账户的社区发现结果:

2. 一个例子:
通过利用原始 louvain 算法对用户进行分群挖掘之后的可视化图像,从该图中可以看出大部分用户为正常无关联用户,中间深色部分为异常聚集用户。

对中心聚集部分进行放大,可以明显观察到聚集群体之间也存在着部分关联,由此可见几个较大的黑产团伙之间也存在着资源共用、行为相似的情况。
原始 Louvain 算法效果:
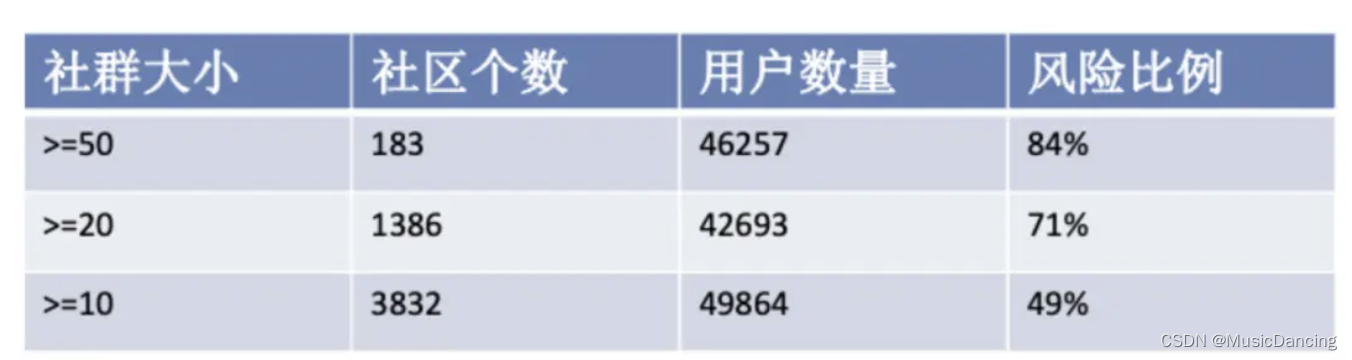
优化 Louvain 算法效果:
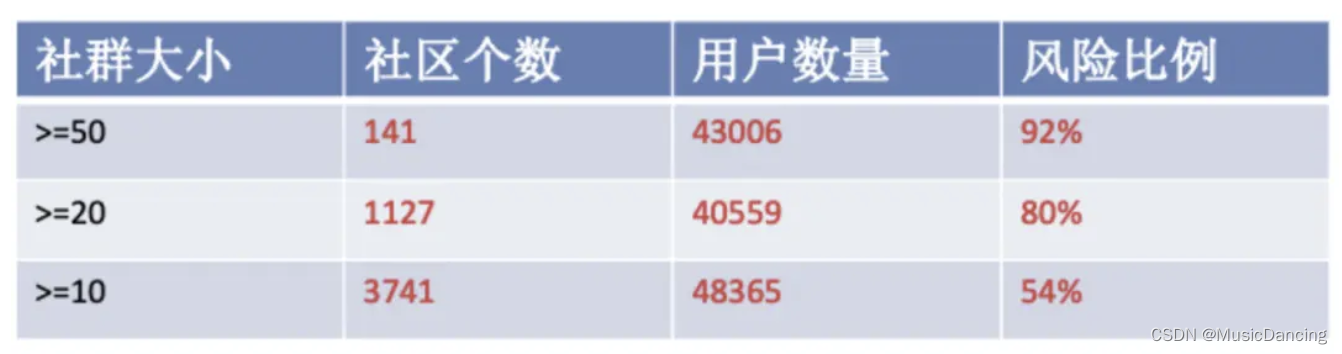
易知社群越大,该社群的用户风险比例越高。优化后的方式可以将大社区拆分,保留更多风险数据在群内,提高了群内用户的风险比例,从而对业务产生更大的价值。对某一团伙进行用户抽样,可以看出抽样用户均属于恶意引流违规,对社区内所有用户审核后发现 95% 以上为黑产用户,从中可以得到该群体用户大部分为黑产用户的结论。
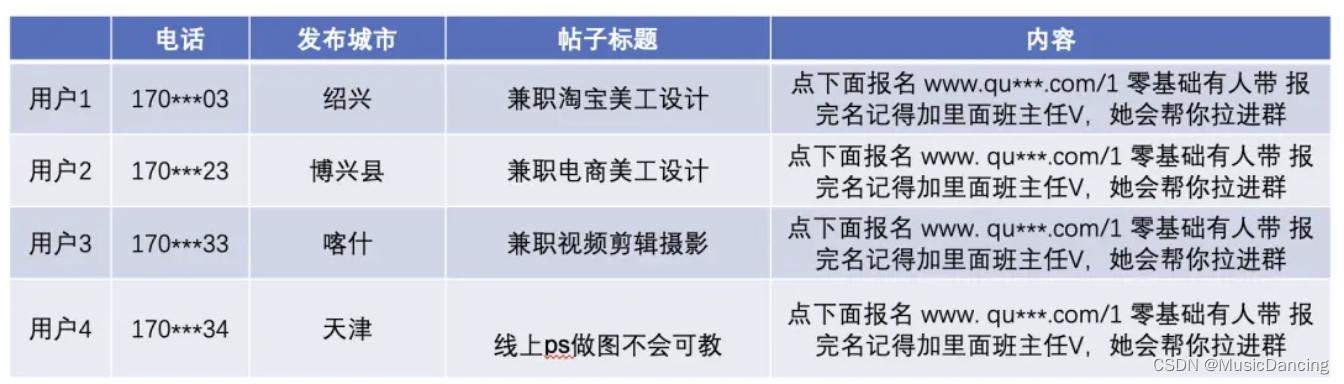
实际业务应用中,聚集群体通过自定义相关指标(社群大小、社群权重,群体资源比等)进行筛选,在黑产团伙识别中,平均识别准确率可达 70% 以上,黑产用户召回数量提升30%+,未暴露风险用户识别能力大幅度提升。
3. 未来的规划:
1. 多数业务场景,不存在一个算法模型可以解决所有问题,所以未来会增加更多的算法模型进行融合结果处理;
2. 黑产账户被处理之后通常会快速的申请其他新账户,会导致新账户与其他节点没有连边关系,为了保证可以及时捕捉到该账户,将会引入更多的行为类特征关系来处理冷启动问题。
4. 算法优缺点与优化思路
Louvain是一种基于模块度优化的方法,它通过在每次迭代中合并最相似的模块来寻找社区结构。
4.1 优缺点
1. 优点
1. 高效性:是一种快速且可扩展的社区检测算法,适用于大规模网络的社区发现;支持定义边权;
2. 自动化:无需预先指定社区数量,算法能够自动发现网络中的社区结构;
3. 效果好:结果具有较高的质量和稳定性;
4. 灵活性:可应用于不同类型的网络,包括社交网络、生物网络、交通网络等;
5. 能够在整个图中进行全局搜索,而不仅仅是在局部进行优化;
6. 包含层次结构的社团,可以依据社团大小、社团特殊属性来限制最后形成的社团。类似决策树中根据增益、叶子节点数量来限制节点分裂 。
2. 缺点
1. 多轮迭代,不支持流式系统;
2. 最差时间复杂度较大,小概率遇到边界数据时,耗时较长;
3. 实际情况中数据分布不均匀时,模块度定义的第二项会产生一定负干扰;4. 对于重叠社区的处理较为困难。
3. 解决方案

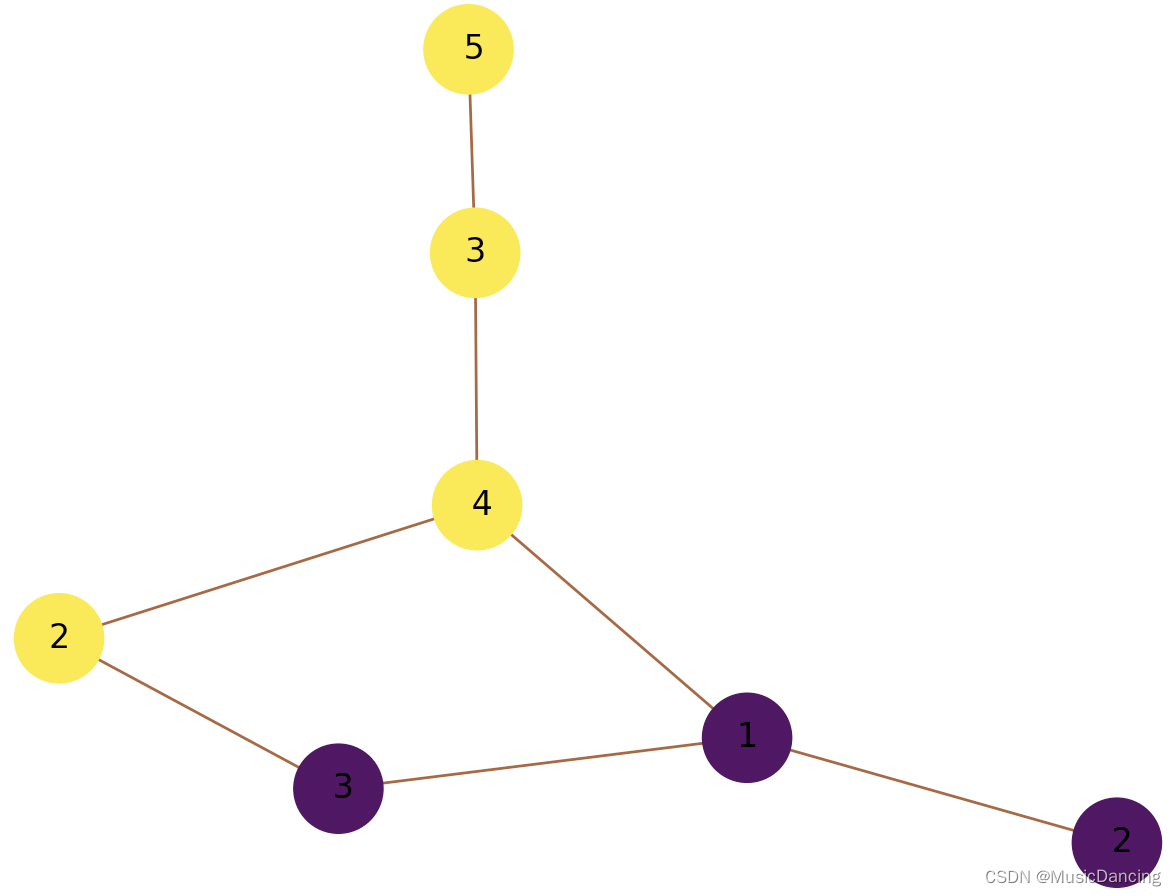
louvain可能出现分离群合并的倾向,举一个极端的例子,假设某个小群X和某个大群Y之间只有一条权重为1的边连接,小群除了这一条边之外就没有和任何其它的节点或者社群连接了,此时上式括号里的第二项的计算结果会非常小,
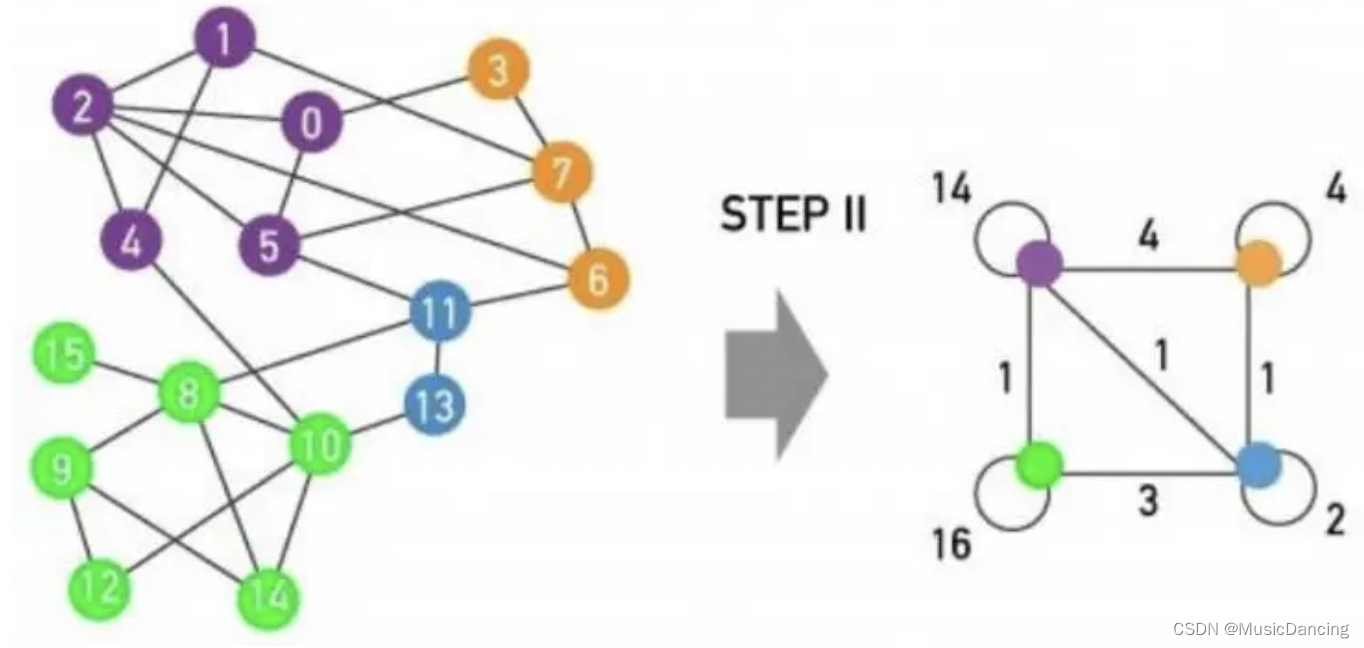
以上图为例,绿色社区 和 紫色社区之间的权重为1,绿色社区和其它社区连接的边的权重之和为 4,则4/(1+3+1+1+4)小于1(注意louvain是迭代计算的,每一次迭代,图的结构都会发生变化,公式中的参数的取值都会发生变化),二者合并。但其实并不希望他们合并,直观上二者已经是独立的社群了不需要进一步合并。
解决这个问题的方法有3种:
1. 过滤掉权重比较弱的边,将弱边的权重置为0;
2. 修改模块度增益的公式,设置一个阈值,即模块度增益必须 > 该阈值才会发生合并;
3. 使用分层louvain,即假设louvain 迭代了10次,则可以取第8次的迭代结果,可以通过可视化每次迭代的modulairty来实现,当modularity收敛不再发生变化时,取那一次对应的迭代结果,类似于kmeans的手肘法。
4.2 优化思路
模块度的最优求解本身是个 NP 问题,即时间复杂度为 O(M!),常规数据中无法在短时间内求到最优解。louvain利用贪心算法对求解过程做了一定优化,在此基础上,还可以做以下优化:
1. 利用边属性对社团中的边进行关于合并优先级的排序,能取消louvain的多轮迭代,适配流式计算系统。比如边介数:社团中任意两个点的最短路径通过该边的次数;
2. 实际数据中社团分布不均匀时,建议降低模块度中第二项的权重。
5. 好用的工具&数据集
1. NetworkX:
一款Python在复杂网络分析领域的软件包,功能强大,几乎覆盖复杂网络分析中的所有可计算的概念,非常好用。
2. 腾讯云:
1. 图数据库 TGraph:支持高效存储和查询大规模图数据,适用于社区检测等图分析任务;
2. 图计算引擎 TGI:提供了高性能的图计算能力,可用于社区检测、图分析等任务。
6. 思考
1. 社区检测算法(Louvain、infomap、LPA 流程简介,GN算法、SLPA算法、K-L算法);
(1)Louvain算法的算法流程
1、通过局部的更改节点社区分类来优化Modularity:先将每个节点指定到唯一的一个社区,然后按顺序将节点在这些社区间进行移动。以节点 i 为例,它有三个邻居节点 j1, j2, j3,分别尝试将节点 i 移动到 j1, j2, j3 所在的社区,并计算相应的 modularity 变化值,哪个变化值最大就将节点 i 移动到相应的社区中去,如果最大的变化值也为负,则不移动。
2、按照这个方法反复迭代,直到网络中任何节点的移动都不能再改善总的modularity值为止。
3、1,2两个步骤看做第一阶段,把第一阶段得到的社区视为一个新的节点。重新构造子图,两个节点之间边的权值为相应两个社区之间各边的权值的总和。
4、重复1,2,3步骤的操作,直到Modularity不再增加为止。
(2) LPA算法的算法流程
1、为所有节点指定一个唯一的标签;
2、逐轮刷新所有节点的标签,直到达到收敛要求为止。
对于每一轮刷新,节点标签刷新的规则如下:
对于某一个节点,考察其所有邻居节点的标签,并进行统计,将出现个数最多的那个标签赋给当前节点。当个数最多的标签不唯一时,随机选一个。
(3)Label Propagation算法:是一种基于标签传播的社区发现方法。
原理:给每个顶点分配一个标签,然后通过标签的传播来确定社区结构。在处理具有噪声标签的网络时表现良好。
(4)Walktrap算法:是一种基于游走的社区发现方法。它通过在图中随机游走,寻找最短的路径来确定社区结构。优点:能够处理复杂的网络结构,且对噪声和异常值具有较强的鲁棒性。
(5)Infomap算法:是一种基于信息传播的社区发现方法。它通过计算顶点之间的互信息来确定社区结构。优点:能够处理大规模网络,且在处理具有不同大小社区的网络时表现良好。
2. Louvain算法是用模块度来优化,那模块度怎么改进呢(模块化密度),还有呢;
3. LPA算法从本质上来看是社区发现算法还是聚类算法;
4. 做风险社区检测,用Louvain还是LPA更合适?
7. 应用
7.1 无权图
from community import community_louvain as louvain
# from community import partition_at_level
def gen_graph():
G = nx.Graph()
G.add_nodes_from([x for x in range(6)])
G.add_edges_from([(1, 2), (1, 3), (1, 4),
(2, 3), (2, 4), (3, 4), (3, 5)])
return G
def draw_graph(G, partition):
# values = [partition.get(node) for node in G.nodes()]
community_list = list(partition.values()) # 各节点对应的社区ID
plt.figure()
nx.draw(G, with_labels=True, cmap=plt.cm.Reds,
node_size=300, node_color=community_list, edge_color='sienna')
plt.show()
if __name__ == '__main__':
G = gen_graph()
partition = louvain.best_partition(G)
# {0: 0, 1: 1, 2: 1, 3: 2, 4: 1, 5: 2}
modularity = louvain.modularity(partition, G)
# 0.03061224489795908
draw_graph(G, partition)
如下:

或
node_list, community_list = partition.keys(), list(partition.values())
pos = nx.spring_layout(G)
# 根据其分区对节点进行着色
cmap = cm.get_cmap('viridis', max(community_list) + 1)
nx.draw_networkx_nodes(G, pos, node_list, node_size=40,
cmap=cmap, node_color=community_list)
nx.draw_networkx_edges(G, pos, alpha=0.5)
plt.show()7.2 有权图
def gen_graph_weight():
G = nx.Graph()
edges = []
with open('weight.csv') as f:
for line in f:
u, v, w = line.strip().split(',')
edges.append((u, v, int(w)))
G.add_weighted_edges_from(edges)
return G
def draw_graph(G, partition):
values = list(partition.values()) # 各节点对应的社区ID
plt.figure()
nx.draw(G, with_labels=True, node_size=1000, node_color=values, edge_color='sienna')
plt.show()
if __name__ == '__main__':
G = gen_graph_weight()
partition = louvain.best_partition(G)
draw_graph(G, partition)如下:
weight.csv

8. 一些trick
8.1 在图中找到社区并返回相应的树状图
一个树状图是一棵树,每个级别都是图节点的一个分区。级别0是第一个分区,其中包含最小的社区,最好的分区是len(dendrogram) - 1。级别越高,社区越大。
louvain.generate_dendrogram(graph,
part_init=None, # 算法使用此节点的分区。是一个字典(节点ID: 社区ID)
weight='weight', # 在图中用作权重的键
resolution=1.0, # 社区的大小
randomize=None,
random_state=None)
G = nx.erdos_renyi_graph(50, 0.01)
dendrogram = louvain.generate_dendrogram(G)
for level in range(len(dendrogram) - 1):
print("level ", level, ":", louvain.partition_at_level(dendrogram, level))函数返回字典列表(分区的列表)
level 0 : {0: 0, 1: 12, 2: 2, 3: 3, 4: 4, 5: 5, 6: 6, 7: 7, 8: 8, 9: 9, 10: 10, 11: 11, 12: 12, 13: 13, 14: 14, 15: 15, 16: 16, 17: 20, 18: 38, 19: 19, 20: 12, 21: 28, 22: 22, 23: 23, 24: 24, 25: 25, 26: 9, 27: 27, 28: 28, 29: 37, 30: 30, 31: 31, 32: 32, 33: 33, 34: 34, 35: 35, 36: 36, 37: 37, 38: 38, 39: 39, 40: 40, 41: 1, 42: 32, 43: 17, 44: 18, 45: 2, 46: 20, 47: 21, 48: 26, 49: 29}
8.2 返回给定级别的节点的分区
一个树状图是一棵树,每个级别都是图节点的一个分区。级别0是第一个分区,其中包含最小的社区,最好的分区是len(dendrogram) - 1。级别越高,社区越大。
partition = louvain.partition_at_level(dendrogram, # 分区的列表,即字典,其中i+1的键是i的值
level) # 属于[0..len(dendrogram)-1]的级别best_partition 直接结合partition_at_level() 和 generate_dendrogram() 以获取最高模块度的分区。
8.3 生成以社区为节点的图
如果两个社区之间的链接权重之和为w,则它们之间存在权重为w的链接
louvain.induced_graph(partition, graph, weight='weight')8.4 计算图的分区的模块度
louvain.modularity(partition, graph, weight='weight')















 455
455











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









