






多目标跟踪的发展现状如何,与单目标跟踪有什么区别和联系

附赠自动驾驶学习资料和量产经验:链接
单目标跟踪 (SOT) 领域内更多地侧重解决一个general obejct tracking (ID-unavailabe) 的问题,对从未在训练集中出现过的目标我们也希望能持续地跟踪上。两种主流的大方向:第一种是判别式跟踪(CF、fintune-based等),通过在线刻画样本特征,这种parametric的机制非常好能区分前背景,并且可以在线随时更新(比如CF通过moving average,fintune-based通过backprop)。第二种是生成式跟踪(SiameseNet),离线通过某种相似度的metric构建了一个泛化性较强的embedding space。这两种方式在meta-learning的观点下可以统一,前者是optimization/model-based model,在线过程可以理解为parametric的回归;而后者是metric-based model,在线过程可以理解为non-parametric的最近邻分类。近期有部分工作来整合这两个部分,比如在孪生网络中加入optimization/model-based model: DROL/MLT/GradNet。
多目标跟踪 (MOT) 领域主要还是针对common object (ID-availabe) 的前提下,如何解决数据关联的问题。数据关联问题则通常有多种解法(如贪心、基于barpartite graph matching的匈牙利/KM算法、图论中的最大流/最小割问题等);而多目标跟踪的运动模型、外观模型等则可以看做是辅助解决关联问题的元件。按分类看,其中一大传统主流tracking-by-detection框架需要基于检测结果,通常是级联或二阶段形式,然后通过帧间矩形框的重合度(SORT)或者外观的相似度以减少IDS(DeepSORT)来做数据关联;另外近年比较火的joint-tracking-detection框架则是检测head和跟踪head并行且可多任务、端到端地学习(比如类似JDE基于外观的embedding作为数据关联的代价,或者类似D&T/FFT/CenterTrack直接基于帧间运动预测offset),而Tractor++这篇更是通过一个回归器在检测结果上操作从而极大简化了数据关联这一步。
个人感觉SOT领域比较关注的问题是如何把MOT中基于pure matching的一个offline-trained ReID model 做成通过梯度下降或者参数预测的online-trained discriminative model (optimization/model-based meta learning)。SiameseNet和MOT的操作比较相似,其默认省略online training也是通过pure matching学度量方式 (metric-based meta learning)。其近期有比较好的表现感觉是充分挖掘了end-to-end的红利,因为早期基于优化的KCF和一些基于finetune的做法是把online model完全独立于offline training部分设计的,即只在tracking的时候来做。而近期DiMP在RR的问题下代火了把gradient descent当成meta-info的设计思路,使之能一起参与训练训到feature,弥补掉了这个end-to-end的gap,所以效果自然非常promising。而参数预测在设计方式上感觉更加meta, 把某些具有weight-shifting的机制做成meta-info,比如利用gradients或者statistics来更新feature (MLT/TADT/GradNet/CLNet),从而使得当前的参数迁移到novel class的domain里面。
在任务设定上,SOT、MOT再加上视频目标检测(VOD) 都是一个video-level object detection问题。VOD是最直接的object detection添加了时序信息的推广任务;而单目标跟踪类似于video-level的object search (few-shot object detection)这个task的setting,因为通常retrival (few-shot classification)的设置都是单样本的;而多目标跟踪则是video-level的instance detection问题,可以理解为是VOD多加上帧间ID的匹配(数据关联)需求。(类似这三者的关系,在instance segmentation的任务下,我们分别有semi-supervised video object segmentation、video instance segmentation以及unsupervised video object setmentation三个sub-tasks)。
另外,单目标跟踪的主流做法基本上是在一个局部小区域上操作,而多目标跟踪是全图操作。单目标跟踪领域近期我个人觉得非常好的工作Siam RCNN/UnifiedDet/GlobalTrack把单目标跟踪当成全局conditional detection来做,将来两个问题可能会更加紧密一些。
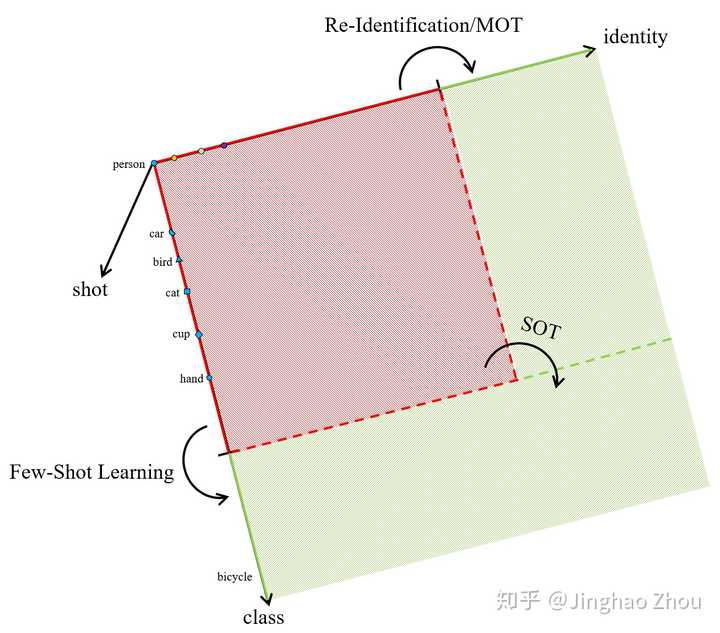
评论区有人问common和general object强调的点,最近正好整理了一波。identity和class可以看成是两个独立的aixs。红色是训练数据,绿色是测试数据。Re-Identification和MOT训练数据adapt到测试数据gap较小,只存在indentity上的迁移。而few-shot learning则是强调对novel class的迁移。SOT可以看做是两个需求同时存在,只不过具体解决的时候通常会把一个class的不同indentity当做不同class来处理,所以本质上SOT大多是投影到class轴当成few-shot learning来迁移class的。我绿色画了两块,下面那一块绿色可能更符合general SOT的目标,GOT-10k这个数据集也是这么组织的。
另外还有一点就是identity这一轴的adaptation训练测试,因为只提供retrival的正样本而没有负样本信息所以相当于没有额外label信息,这也是符合ReID应用场景的,故只限于1-way-N-shot metric-based model来解。而few-shot learning M-way-N-shot的setting下,neta_train中提供了M个class的label信息,所以可以提前学一个discriminative model;当然你也可以用KNN这种lazy learning的方式忽略掉label而只去memorize meta-train的信息,即一个M-way-N-shot metric-based model,判别力自然会差很多。
















 8433
8433

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









