







【论文笔记 2】Topic-Aware Neural Keyphrase Generation for Social Media Language(ACL19)
社交媒体下的主题感知和关键词
简介
题目:Topic-Aware Neural Keyphrase Generation for Social Media Language
作者:Yue Wang1∗ Jing Li2† Hou Pong Chan1 Irwin King1 Michael R. Lyu1 Shuming Shi2
作者单位:腾讯AiLab+港中大
发表会议:ACL
发表年限:19
背景 Modivation
背景:在庞大的社交媒体流中有效地自动提取主题。
解决问题:解决社交媒体稀疏信息中的主题提取问题(关键短语预测)
采用方法:DL方法,VAE+GRU(Bi-GRU GRU)
传统方法
-
从帖子中提取单词或短语作为帖子的主题表示
限制:无法产生帖子中没有的词语,这些有时候包含了关键的信息。同时在社交媒体的文本中,这种情况较为常见,因为用户在日常交流中倾向于简写或用一些其他词语指代。
-
对一般文本的方法在处理社交语料的时候,不可避免会遇到数据稀疏的问题
限制:在单独看某一个微博或推文的时候,有时候很难知道其具体在讲什么东西
idea
- 使用生成模型解决对帖子中没有的短语的生成问题。所以方法中有keyphrases predict。
- 第一个在社交媒体数据下,研究关键短语生成的潜在主题(社交媒体+短语生成+潜在主题,他们是第一个)
关键工作:
-
Keyphrase Prediction
使用语料库级的潜在主题模型
-
Topic Modeling
不同于LDA,使用Neural Topic Model 神经主题模型
框架架构:

核心:主题模型+生成模型
-
主题模型(下方绿色):
采用NTM,这里的架构与Miao的NVDM-GSM一样,输出输出都是词袋模型。过程为对词袋模型的表示和重构。对隐空间的约束采用KL散度。隐空间学习到的Z即为主题分布,该部分的目的是获取隐含的主题。
-
生成模型(上方):
输入为序列模型和主题分布,输出为可以描述主题的一个单词序列。标准的seq2seq结构
Pipe Line
-
NTM生成主题分布
-
编码生成z的分布

-
对词进行重建

-
采用KL散度衡量重构误差
-
-
生成模型生成keyphrase
-
Sequence Encoder
采用双向GRU对序列模型表示的语料进行编码。提取语料中的上下文关系,然后对每一个词进行编码并储存。(hi为第i个词)
X s e q [ x 1 , x 2 , . . . , x ∣ x ∣ ] → M [ h 1 , h 2 , . . . , h ∣ x ∣ ] → A X_{seq}[x_1,x_2,...,x_{|x|}]→M[h_1,h_2,...,h_{|x|}]→A Xseq[x1,x2,...,x∣x∣]→M[h1,h2,...,h∣x∣]→A -
Sequence Decoder
编码表示M以及主题θ作为输入,生成关键短语的过程如下

y为生成的目标短语,x为语料中词汇。最终结果为每个时隙语料的联合概率(独立事件)具体过程如下:
-
改进GRU,添加主题信息(s为hidden state)

-
计算Attention权重
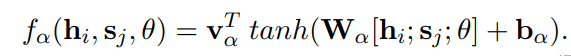
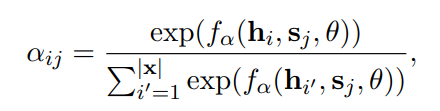
然后对所有的a,h加权求和

-
则第j个时隙的关键词是

-
上述过程为基于生成的过程,这里同时还加入了从原文抽取词汇的机制(确定是否从原文复制词汇,还是从模型生成词汇),这里是直接拼接起来了。

-
最终模型输出:第j个时隙的target word的分布(这块有误,后面那一项是个标量,八成是写错了。应该要加上前一个GRU的output)

-
-
-
损失函数采用二者加和

experiment
数据集:
- 中文微博
- StackExchange

结果
在不使用潜在主题的情况下,优于现有模型
使用潜在主题在社交媒体流这样的文法不严格的语料上(noisy)表现更好。














 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









