







NeRF 在2020年ECCV上名声大噪,作为best paper展示(https://www.matthewtancik.com/nerf)
作者在网上收罗了NeRF的相关评说,汇总如下,内容可能杂乱,可作为对NeRF初步认识的资料。
文章目录
- 参考链接1:https://zhuanlan.zhihu.com/p/380015071
- 参考链接2: https://zhuanlan.zhihu.com/p/466217848
- 参考链接3: https://www.analyticsvidhya.com/blog/2021/04/introduction-to-neural-radiance-field-or-nerf/
- 参考链接4: https://www.bilibili.com/video/av500646685/
- 参考链接5 :https://www.bilibili.com/video/BV1by4y1v7Sz/
参考链接1:https://zhuanlan.zhihu.com/p/380015071
Vanilla NeRF
什么是NeRF?
- NeRF所要做的 task 是 Novel View Synthesis,一般翻译为新视角合成任务
- 在已知视角下对场景进行一系列的捕获 (包括拍摄到的图像,以及每张图像对应的内外参),合成新视角下的图像
- NeRF 不需要中间三维重建的过程,仅根据位姿内参和图像,直接合成新视角下的图像。
- NeRF 引入了辐射场的概念,这在图形学中是非常重要的概念。
渲染方程式的定义:
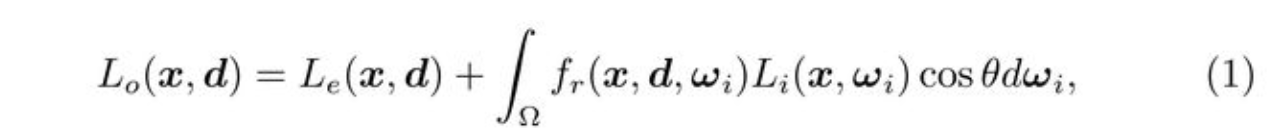
- 方程表示了空间点 x ∈ R 3 x \in R^3 x∈R3在方向 d ∈ R 3 d \in R^3 d∈R3 上的辐射 L o L_o Lo.
- 等式右边第一项 表示 x 为光源点时,自身在d方向释放的辐射。
- 等式右边第二项 表示该店折射在方向d 上的辐射,其中 Ω \Omega Ω 为入射方向 ω i \omega_i ωi的半球集合。
- f r ( ⋅ ) f_r(\cdot) fr(⋅)为散射函数, L i L_i Li为从 ω i \omega_i ωi方向接受到的辐射, $$
辐射和颜色的关系:
- 光就是电磁辐射, 或振荡的电磁场
- 光又有波长和频率,二者乘积为光速
- 光的颜色是由频率决定的
- 大多数光是不可见的,人眼可见的光谱称为可见光谱,对应的频率就是我们认为的颜色
**NeRF表示3D场为可学习的,连续的辐射场
F
θ
F_{\theta}
Fθ **
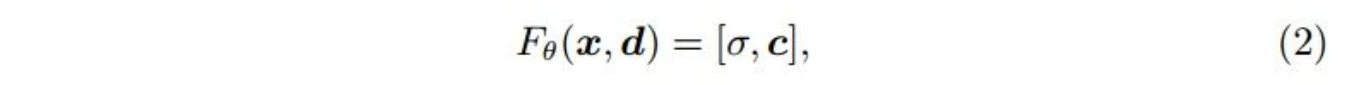


Positional Encoding
- deep networks 更倾向于学习低频的函数,实际场景的神经辐射场基本上都是高频的
- 作者提出了 Positional Encoding (注意这里的 Positional Encoding 和 Transformer 中的 Positional Encoding 很像,但是解决问题是不一样的
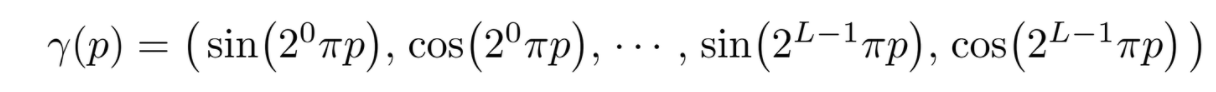


Hierarchical volume sampling
使用体渲染积分遇到的问题:
- 虽然可以离散的近似计算积分,采样点过多开销过大,采样点过少近似误差有太大。
解决办法: 最好尽可能的避免在空缺部分以及被遮挡了的部分进行过多的采样,因为这些部分对最好的颜色贡献是很少的
NeRF 提出分层采样训练的方式,如下图所示:
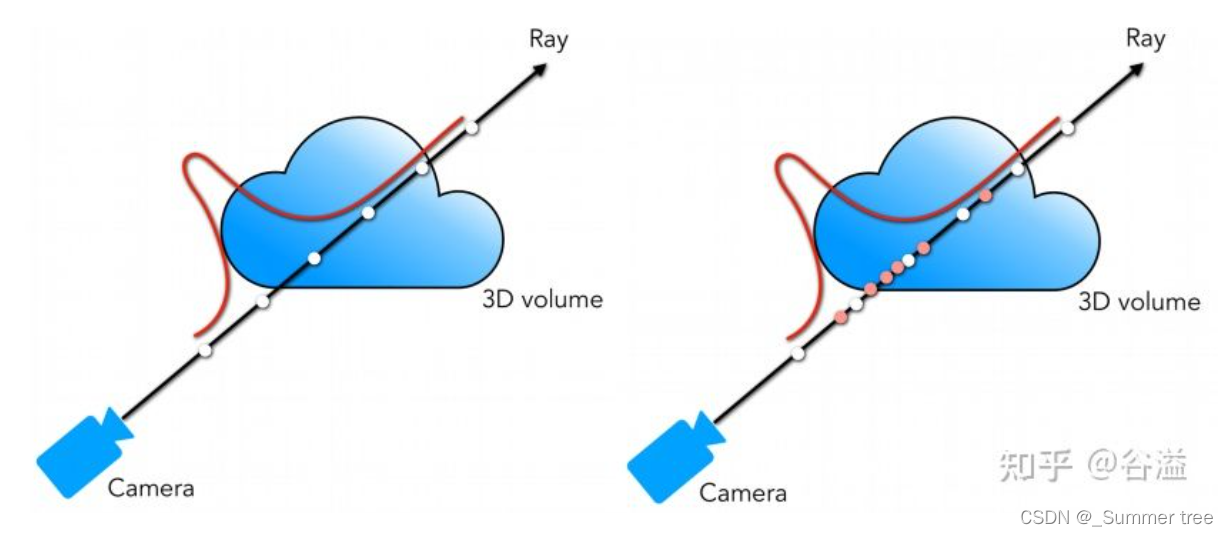
- 使用两个网络同时进行训练 (后称 coarse 和 fine 网络)
- coarse 网络输入的点是通过对光线均匀采样得到的
- 根据 coarse 网络预测的体密度值,对光线的分布进行估计,然后根据估计出的分布进行第二次重要性采样
- 然后再把所有的采样点 [公式] 一起输入到 fine 网络进行预测。
NeRF 存在的问题:
- 实时性不好
- 泛化性不强
- 不能处理动态场景
- 拍摄方式有限制
参考链接2: https://zhuanlan.zhihu.com/p/466217848
NeRF原理
NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis
NeRF主要功能: 使用静态场景下的多个视角的照片(大约几十至上百张),合成出任意新视角的图片。
NeRF的算法思路:
-
Step1 :
- 使用MLP学习该场景的隐式3D模型表达
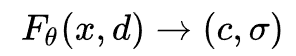
- MLP模型示意图。输入一个3d点x和观测方向d的高频编码向量,网络预测该点的密度sigma和颜色c
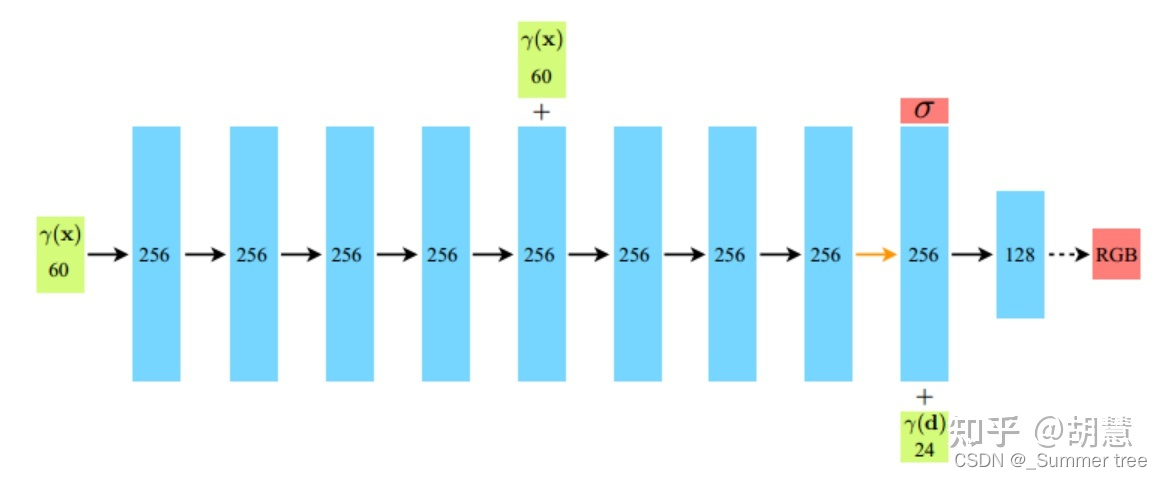
- 使用MLP学习该场景的隐式3D模型表达
-
Step 2:使用体渲染方程将3D场景渲染成图片
-
图形上的点 P(u,v,1) , 他的像素值 rgb 可以通过对该点P发出的射线上的所有的点 的 c 和体密度 进行积分得到。
-

-
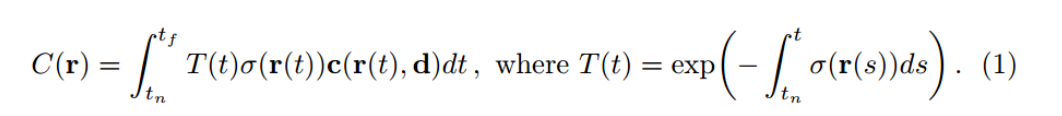
-
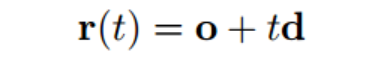
-
-
-
Step 3:训练
- 训练集是几十张或者几百张该场景不同相机位姿拍摄的图片
- 首先使用SFM算法求出所有图片的相机相对世界坐标系的位姿 (R,t)
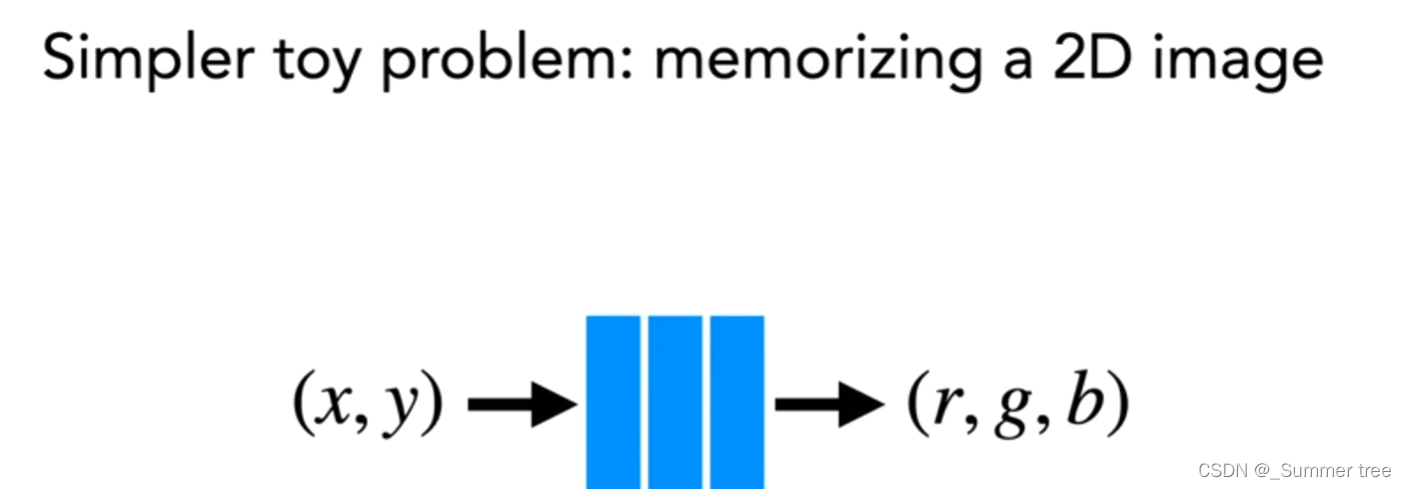
- 每张图片的每个像素点都是一个训练样本 (u,v) → rgb
- 以像素点(u,v)为例:
- 从该点发出的射线在世界坐标系中的表示为
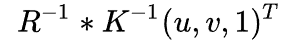
- 起始点 [公式] 的世界坐标也同样可以有相机的内外参求得
- 然后在该射线上采样n个采样点。
- 使用MLP预测这n个点的体密度,和c ,然后使用体渲染方程的离散公式算出该像素点的预测值 rgb。
- 然后计算预测的颜色值和真实颜色值的L2距离作为loss进行监督训练。
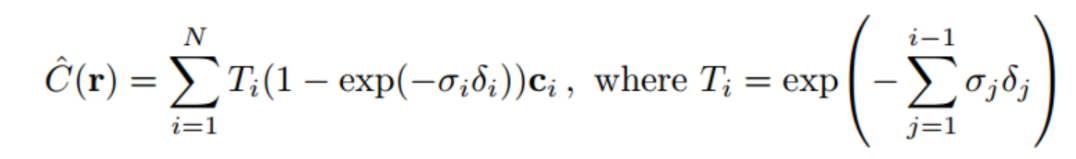
- 从该点发出的射线在世界坐标系中的表示为
-
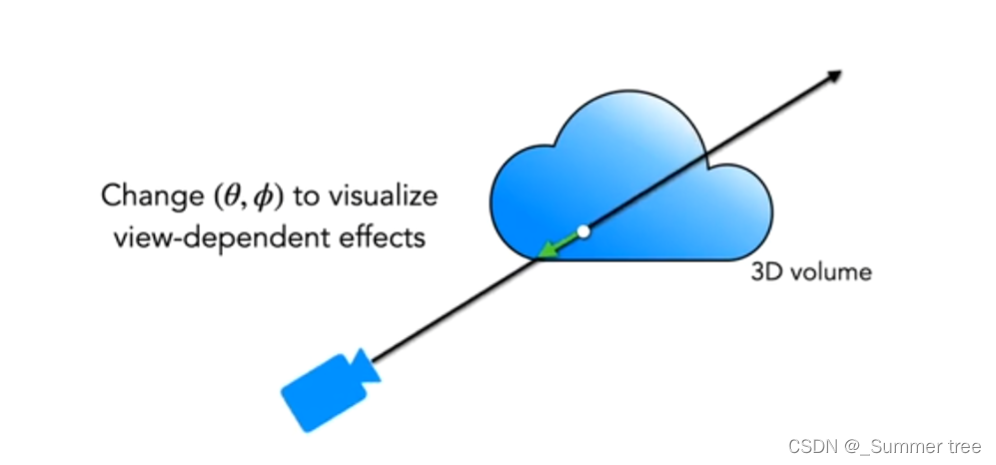
Step 4: 观测方向d的作用:
- 一个点的密度密度智能是该点位置x的函数。
- 但该点的颜色还取决于观测方向(我们观看空间中一个物体的某个点,从光源照射方向观看和从阴影方向观看,它的亮度是不一样的。)
-
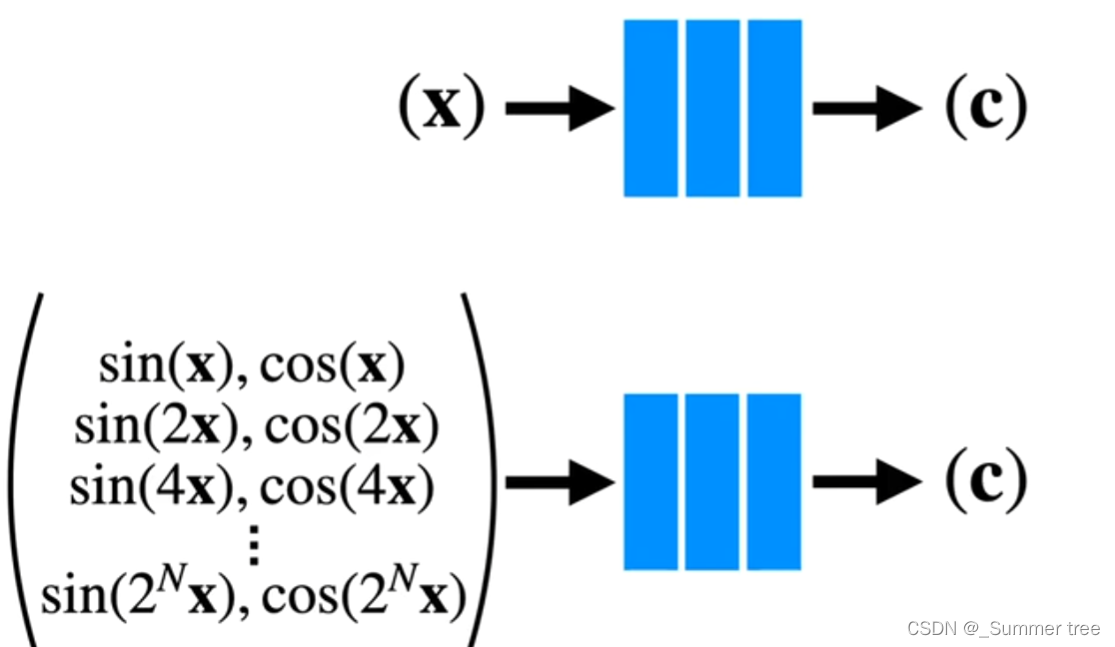
Step 5:Positional encoding
- 直接让MLP学习映射很难,将x,d 编码危机高维向量后学习会更加容易。
- 因此使用如下高频函数进行编码。
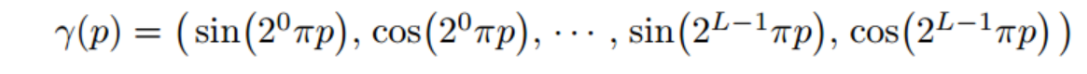
-
step 6:多层级采样策略
- 均匀采样方式采样射线上64个点
- 这64点的密度值估计出密度分布函数。
- 再使用逆采样算法集中对高密度的区域采样128点。
- 使用该策略可以提高采样的效率,不需要对射线上所有区域都进行密集的采样。
NeRF加速
FastNeRF: High-Fidelity Neural Rendering at 200FPS (等这篇文章看了之后,在看解读。 )
相关资料:https://microsoft.github.io/FastNeRF/
https://ieeexplore-ieee-org-s.nudtproxy.yitlink.com/document/9710021
Instant Neural Graphics Primitives with a Multiresolution Hash Encoding
相关资料: https://nvlabs.github.io/instant-ngp/
https://nvlabs.github.io/instant-ngp/assets/mueller2022instant.pdf
NeRF动态场景(人体)的拓展
HumanNeRF: Free-viewpoint Rendering of Moving People from Monocular Video
相关资料:https://www.semanticscholar.org/paper/HumanNeRF%3A-Free-viewpoint-Rendering-of-Moving-from-Weng-Curless/bd706601b75533a66a782f6229419f85b1cc5135
参考链接3: https://www.analyticsvidhya.com/blog/2021/04/introduction-to-neural-radiance-field-or-nerf/
神经辐射场(Neural Radiance Field, NeRF)是一种生成复杂场景新视图的方法。NeRF获取一组场景的输入图像,并通过在场景之间插入来渲染完整的场景。
- NeRF 的输出是一个体积,其颜色和密度取决于视图的方向和在该点发射的光亮度。
- 对于每条光线,我们都得到一个输出体积,所有这些体积构成了复杂的场景。
- 静态场景被表示为如上定义的连续5D函数。
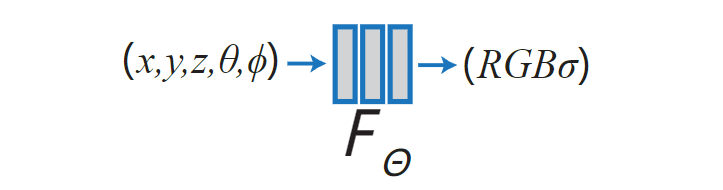
- 该方法使用一个全连接的神经网络-多层感知器(MLP)来表示该函数,从单个5D坐标(x, y, z, θ, φ)向后移动,输出一个体积密度(RGB颜色受视图影响)。
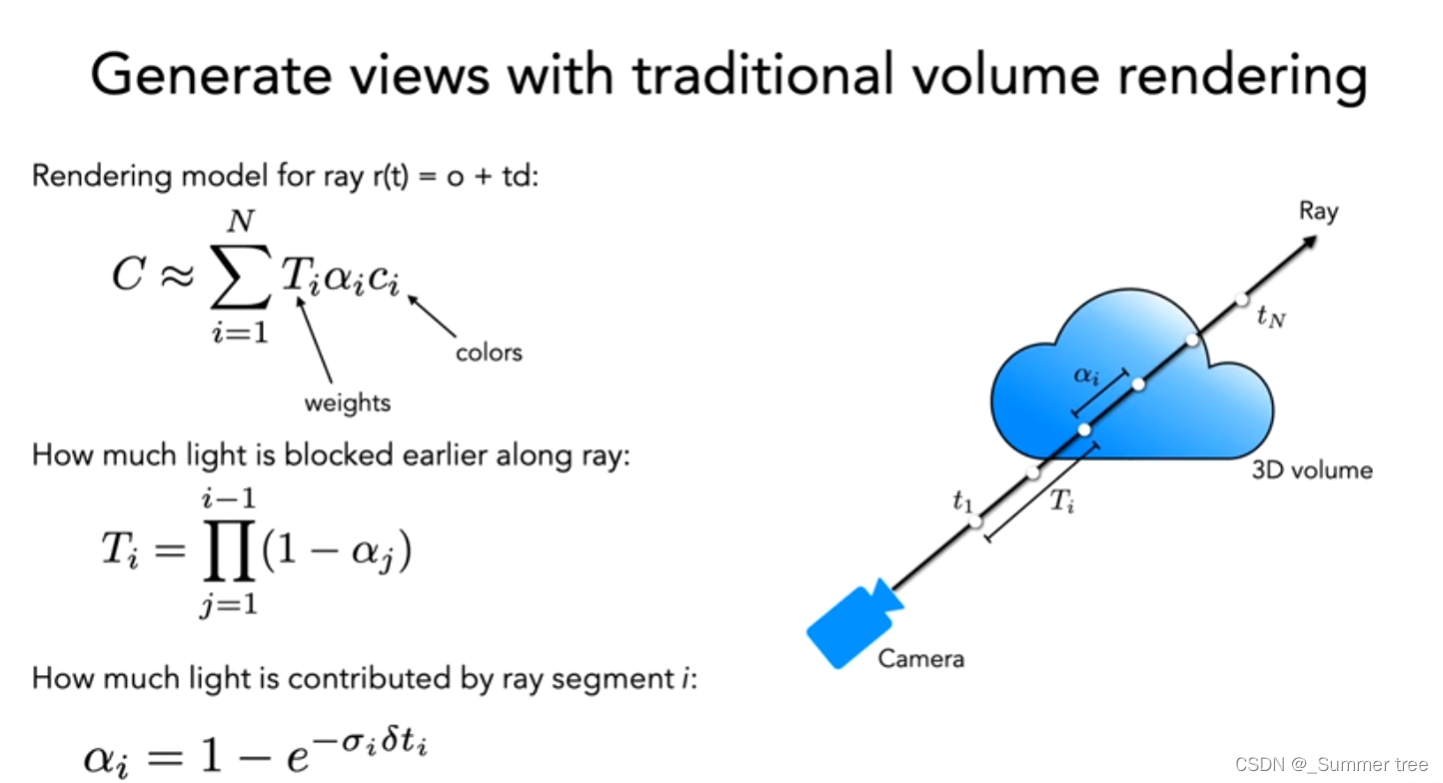
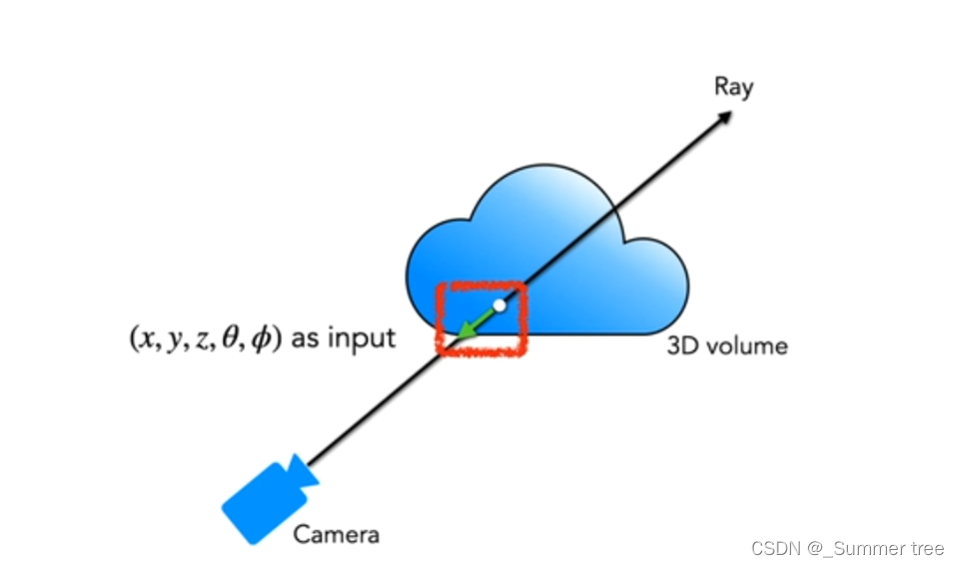
要渲染这个NeRF,有3个步骤:
- 相机光线通过场景来采样3D点
- 利用step1中的点及其对应的2D观察方向(θ, φ)作为输入到MLP,得到颜色(c = (r, g, b))和密度σ的输出集,
- 使用体绘制技术将这些颜色和密度累积到一个2D图像中[注:体绘制是指从采样的3D点创建一个2D投影]
参考链接4: https://www.bilibili.com/video/av500646685/






















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











