








https://magicfusion.github.io/MagicNaming/
写在前面:
【论文速读】按照#论文十问#提炼出论文核心知识点,方便相关科研工作者快速掌握论文内容。过程中并不对论文相关内容进行翻译。博主认为翻译难免会损坏论文的原本含义,也鼓励诸位入门级科研人员阅读文献原文。
文章目录
01 现有工作的不足?
Thesee approaches predominantly rely on finetuning generative models (lora or cross attention layers) on specific datasets, resulting in a bias towards close-up head images. This significantly diminishes the model’s capacity, e.g., for scene construction, stylization, emotional editing, and the action control of humans within generated images.
02 文章解决了什么问题?
Is it possible to make such models generate generic identities as simple as the famous ones, e.g., just use a name? In this paper, we explore the existence of a “Name Space”, where any point in the space corresponds to a specific identity.
- Note that like the names of celebrities, our predicted name embeddings are disentangled from the semantics of text inputs, making the original generation capability of text-to-image models well-preserved.
- By simply plugging such name embeddings, all variants (e.g., from Civitai) derived from the same base model (i.e., SDXL) readily become identity-aware text-to-image models.
- By embedding this point (i.e., name embedding) into text guidance, we can achieve consistent ID generation for generic identities.
03 关键的解决方案是什么?
we find some clues in the feature space spanned by text embedding of celebrities’ names.
- Specifically, we first extract the embeddings of celebrities’ names in the Laion5B dataset with the text encoder of diffusion models.
- Such embeddings are used as supervision to learn an encoder that can predict the name (actually an embedding) of a given face image.
- We experimentally find that such name embeddings work well in promising the generated image with good identity consistency.
04 主要的贡献是什么?
- We investigated the relationship between prompts and name embeddings, discovering that textual semantics and name embeddings are disentangled. Consistent ID generation for generic identities can be achieved by finding its name embedding.
- We extracted celebrity images from the Laion5B dataset and obtained name embedding by encoding names with text encoder. Through multi-level data filtering and refinement, we constructed the LaionCele dataset, which comprises 42,000 celebrities and approximately 810,000 authentic images.
- We designed and trained an image encoder to accomplish the mapping of any reference portrait to the N Space to get the corresponding name embedding. By simply plugging such name embedding into the text embedding, consistent ID generation centered around an specific identity can be achieved. In addition, ID interpolation can also generate fictional characters.
05 有哪些相关的工作?
- SDXL
- IP-Adapter
- PhotoMaker
06 方法具体是如何实现的?
In this paper, we investigate the existence of a “Name Space”(N Space), aiming to predict a “name” for each generic identity and guide the generative model to produce consistent identity generation in a manner that is similar to celebrity name formats.
- Specifically, we first investigate how celebrity names enable the generative model to produce consistent IDs. Experiments reveal that name embeddings and textual semantics in a text-to-image model are disentangled, e.g., altering name embeddings or their positions within the model does not disrupt the generation of the original semantics. Likewise, maintaining name embeddings while changing semantics does not affect the consistency of the generated IDs.

- The key to extending the generative model’s capability for consistent ID generation from celebrities to generic identities lies in finding corresponding name embeddings for the latter. To this end, we collect a subset from the laion5B dataset that contains celebrity name and image pairs.
- We conduct text encoding on the names to obtain their respective name embeddings ,thereby constructing a large-scale celebrity dataset with their name embeddings.
- Utilizing this dataset, we train an image encoder capable of predicting the “name” for any reference individual.
- To enhance the alignment with the textual embedding space, our image encoder employs the same CLIP model as used for text embeddings. Building upon this, we refine the output through a trilayer fully connected network to yield the final name embedding prediction.
- In the inference generation process, a technique analogous to classifier-free guidance was employed, involving the recalibration of name embeddings through the utilization of their mean values.
The loss function in the training process is defined as follows,

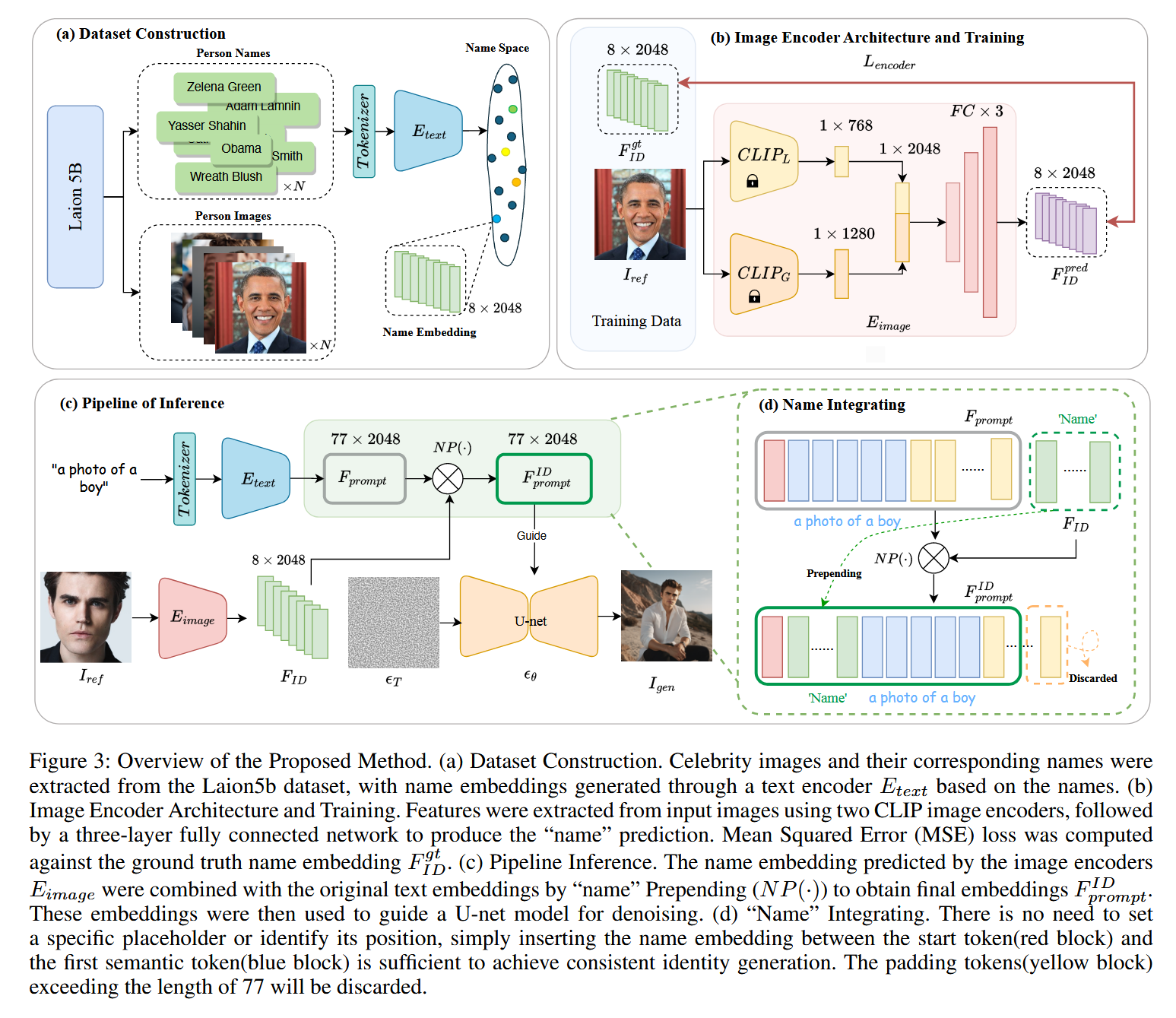
- (a) Dataset Construction. Celebrity images and their corresponding names were extracted from the Laion5b dataset, with name embeddings generated through a text encoder Etext based on the names.
- (b) Image Encoder Architecture and Training. Features were extracted from input images using two CLIP image encoders, followed by a three-layer fully connected network to produce the “name” prediction. Mean Squared Error (MSE) loss was computed against the ground truth name embedding F gt ID.
- © Pipeline Inference. The name embedding predicted by the image encoders Eimage were combined with the original text embeddings by “name” Prepending (N P (·)) to obtain final embeddings FpIrDompt. These embeddings were then used to guide a U-net model for denoising.
- (d) “Name” Integrating. There is no need to set a specific placeholder or identify its position, simply inserting the name embedding between the start token(red block) and the first semantic token(blue block) is sufficient to achieve consistent identity generation. The padding tokens(yellow block) exceeding the length of 77 will be discarded.

07 论文中的实验是如何设计的?
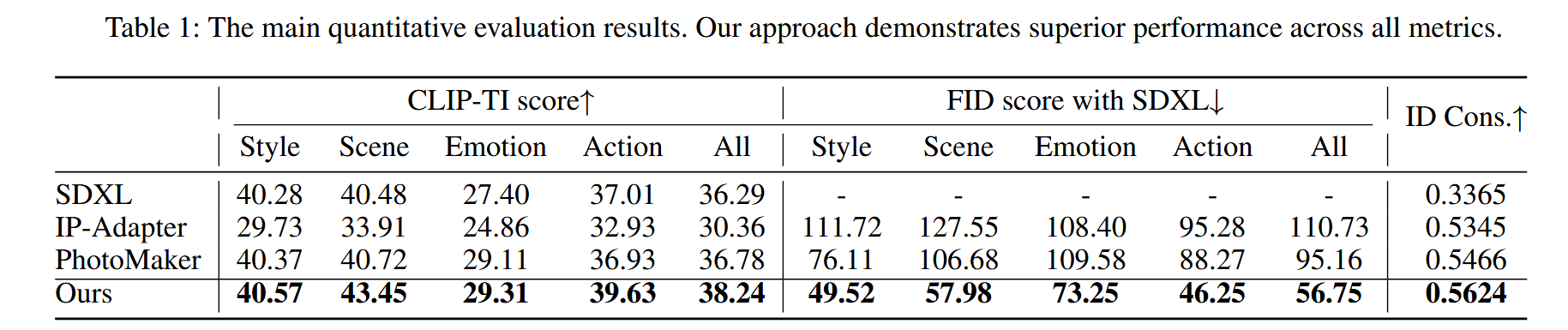
To demonstrate the effectiveness of our method, we conducted both quantitative and qualitative assessments, comparing and analyzing them against relevant works. e.g., IP-Adapter (Ye et al. 2023) and PhotoMaker (Li et al. 2023b).
For the testing prompt, we classified them into four tasks:
- (a)scene construction,
- (b)action control,
- © stylization
- (d)emotional editing.
These prompts present greater challenges compared to simple directives such as changing clothes or wearing hats. It is noteworthy that (a)scene construction and (b)action control pursue the generation of images that contain complete human figures and rich scene semantics rather than merely headshots.
For the evaluation images, we meticulously selected person images that SDXL could not generate with consistent ID based solely on name text, thereby mitigating the influence of the generative model’s inherent person recognition capabilities on ID consistency of generated images.
we performed grouped evaluations of the aforementioned four specified tasks utilizing a pair of evaluation metrics: the CLIP Text-Image Consistency (CLIP-TI) score and the Fre ́chet Inception Distance (FID).
Why choose FID score? Given the widespread acclaim of industry and user for the image generation results of SDXL (Rombach et al. 2022), we evaluated the similarity of each model’s outputs to those of SDXL by calculating their FID score. A lower FID score denotes a higher fidelity to SDXL’s synthesis quality and visual appeal.
08 实验结果和对比效果如何?
Visualization and Comparison:

(a)Scene Construction. Applications of scene construction with close-up head are highly constrained. Effective scene content and character portrayal are crucial for applications like print advertising and film production. Both IP-Adapter and PhotoMaker primarily generate portraits from the chest or neck up, with scene content corresponding to the text being incorporated only by adding relevant elements to the head’s background.
(b)Action Control. The inherent capability of the SDXL to generate human action scenes is notably aesthetically pleasing and impressive, e.g., “a woman is riding a horse”. However, after fine-tuning, most models show a significant drop in this ability. The generated images by PhotoMaker and IP-Adapter remain constrained to upper-body of individuals. resulting in incomplete scenes lacking in visual appeal.
©Stylization. One of SDXL’s key strength lies in its ability to synthesize diverse-styled imagery from textual descriptions alone. IP-adapter has negligible stylization capability. PhotoMaker, while integrating stylistic features, diverges from intended styles and is plagued by poor image fidelity and content ambiguity. Even more, instances of failed identity consistency have been observed in PhotoMaker.
(d)Emotional Editing. Our method maintain the intrinsic generative power of the generator model (e.g., SDXL), which enables us to leverage sophisticated semantic manipulation features, including the ability to edit emotional expressions. The facial expressions of characters generated by IP-Adapter and PhotoMaker exhibit less pronounced emotional variations.
Quantitative Evaluation
We concentrate more on maintaining complex semantic consistency in images produced by different generative models, which are driven by challenging textual prompts. Additionally, we place a significant emphasis on the visual appeal of the generated images, striving to achieve a high level of aesthetic quality.
Create Fictional Identities

In the N space, any given point corresponds to a person identity. For real individuals, we can obtain their mapping in the N space using the image encoder proposed and trained in this paper, thereby achieving consistent identity generation. Furthermore, by interpolating between any two points (i.e., name embedding) within the name space, we can create new fictional characters.
09 消融研究告诉了我们什么?
The necessity of constructing LaionCele datasets.

Therefore, it is evident that the dataset constructed in this study, LaionCele, holds substantial value and contribution to the field.
How does fine-tuning impair generative capacity?

Experimental results indicate that:
-
- Fine-tuning U-net and LoRA both incur a trade-off, enhancing identity consistency(ID Cons.) and reference similarity(Ref Simi.) at the expense of generative performance(CLIP-TI).
-
- Fine-tuning U-net results in a more pronounced degradation of generative capability, yet it yields greater improvements in identity consistency.
-
- Finetuning LoRA is more beneficial for augmenting reference similarity.
-
- In comparison to the larger laionCele dataset, smaller datasets(Ins700) exert less influence across all measured metrics.
Application: making any U-net identity-aware

The “name” sampled from the N Space can be easily utilized with alternative generative models to produce consistent ID generation without compromising the original specialized capabilities.
10 这个工作还可以如何优化?
参考文献
Alaluf, Y.; Richardson, E.; Metzer, G.; and Cohen-Or, D. 2023. A Neural Space-Time Representation for Text-toImage Personalization. ACM Trans. Graph., 42(6): 243:1243:10. Arar, M.; Gal, R.; Atzmon, Y.; Chechik, G.; Cohen-Or, D.; Shamir, A.; and Bermano, A. H. 2023. Domain-Agnostic Tuning-Encoder for Fast Personalization of Text-To-Image Models. In SIGGRAPH Asia, 72:1–72:10. ACM. Avrahami, O.; Lischinski, D.; and Fried, O. 2022. Blended Diffusion for Text-driven Editing of Natural Images. In CVPR, 18187–18197. IEEE. Banerjee, S.; Mittal, G.; Joshi, A.; Hegde, C.; and Memon, N. D. 2023. Identity-Preserving Aging of Face Images via Latent Diffusion Models. In IJCB, 1–10. IEEE. Cao, Y.; Li, S.; Liu, Y.; Yan, Z.; Dai, Y.; Yu, P. S.; and Sun, L. 2023. A Comprehensive Survey of AI-Generated Content (AIGC): A History of Generative AI from GAN to ChatGPT. CoRR, abs/2303.04226. Chen, H.; Zhang, Y.; Wang, X.; Duan, X.; Zhou, Y.; and Zhu, W. 2023a. DisenBooth: Identity-Preserving Disentangled Tuning for Subject-Driven Text-to-Image Generation. CoRR, abs/2305.03374. Chen, L.; Zhao, M.; Liu, Y.; Ding, M.; Song, Y.; Wang, S.; Wang, X.; Yang, H.; Liu, J.; Du, K.; and Zheng, M. 2023b. PhotoVerse: Tuning-Free Image Customization with Textto-Image Diffusion Models. CoRR, abs/2309.05793. Chen, M.; Chu, H.; and Wei, X. 2021. Flocking Control Algorithms Based on the Diffusion Model for Unmanned Aerial Vehicle Systems. IEEE Trans. Green Commun. Netw., 5(3): 1271–1282. Elarabawy, A.; Kamath, H.; and Denton, S. 2022. Direct Inversion: Optimization-Free Text-Driven Real Image Editing with Diffusion Models. CoRR, abs/2211.07825. Gal, R.; Alaluf, Y.; Atzmon, Y.; Patashnik, O.; Bermano, A. H.; Chechik, G.; and Cohen-Or, D. 2023a. An Image is Worth One Word: Personalizing Text-to-Image Generation using Textual Inversion. In ICLR. OpenReview.net. Gal, R.; Alaluf, Y.; Atzmon, Y.; Patashnik, O.; Bermano, A. H.; Chechik, G.; and Cohen-Or, D. 2023b. An Image is Worth One Word: Personalizing Text-to-Image Generation using Textual Inversion. In ICLR. OpenReview.net. Gal, R.; Arar, M.; Atzmon, Y.; Bermano, A. H.; Chechik, G.; and Cohen-Or, D. 2023c. Designing an Encoder for Fast Personalization of Text-to-Image Models. CoRR, abs/2302.12228. Hertz, A.; Mokady, R.; Tenenbaum, J.; Aberman, K.; Pritch, Y.; and Cohen-Or, D. 2023. Prompt-to-Prompt Image Editing with Cross-Attention Control. In ICLR. OpenReview.net. Hinz, T.; Heinrich, S.; and Wermter, S. 2022. Semantic Object Accuracy for Generative Text-to-Image Synthesis. IEEE Trans. Pattern Anal. Mach. Intell., 44(3): 1552–1565. Ho, J.; Jain, A.; and Abbeel, P. 2020. Denoising Diffusion Probabilistic Models. In Larochelle, H.; Ranzato, M.; Hadsell, R.; Balcan, M.; and Lin, H., eds., NeurIPS. Ho, J.; and Salimans, T. 2022. Classifier-Free Diffusion Guidance. CoRR, abs/2207.12598. Hua, M.; Liu, J.; Ding, F.; Liu, W.; Wu, J.; and He, Q. 2023. DreamTuner: Single Image is Enough for Subject-Driven Generation. CoRR, abs/2312.13691. Ku, M.; Li, T.; Zhang, K.; Lu, Y.; Fu, X.; Zhuang, W.; and Chen, W. 2023. ImagenHub: Standardizing the evaluation of conditional image generation models. CoRR, abs/2310.01596. Kumari, N.; Zhang, B.; Zhang, R.; Shechtman, E.; and Zhu, J. 2023. Multi-Concept Customization of Text-to-Image Diffusion. In CVPR, 1931–1941. IEEE. Li, C.; Zhang, C.; Waghwase, A.; Lee, L.; Rameau, F.; Yang, Y.; Bae, S.; and Hong, C. S. 2023a. Generative AI meets 3D: A Survey on Text-to-3D in AIGC Era. CoRR, abs/2305.06131. Li, W.; Wen, S.; Shi, K.; Yang, Y.; and Huang, T. 2022. Neural Architecture Search With a Lightweight Transformer for Text-to-Image Synthesis. IEEE Trans. Netw. Sci. Eng., 9(3): 1567–1576. Li, Z.; Cao, M.; Wang, X.; Qi, Z.; Cheng, M.; and Shan, Y. 2023b. PhotoMaker: Customizing Realistic Human Photos via Stacked ID Embedding. CoRR, abs/2312.04461. Liu, N.; Li, S.; Du, Y.; Torralba, A.; and Tenenbaum, J. B. 2022. Compositional Visual Generation with Composable Diffusion Models. In ECCV (17), volume 13677 of Lecture Notes in Computer Science, 423–439. Springer. Liu, V.; and Chilton, L. B. 2022. Design Guidelines for Prompt Engineering Text-to-Image Generative Models. In CHI, 384:1–384:23. ACM. Liu, X.; Zhang, X.; Ma, J.; Peng, J.; and Liu, Q. 2023a. InstaFlow: One Step is Enough for High-Quality DiffusionBased Text-to-Image Generation. CoRR, abs/2309.06380. Liu, Z.; Feng, R.; Zhu, K.; Zhang, Y.; Zheng, K.; Liu, Y.; Zhao, D.; Zhou, J.; and Cao, Y. 2023b. Cones: Concept Neurons in Diffusion Models for Customized Generation. In ICML, volume 202 of Proceedings of Machine Learning Research, 21548–21566. PMLR. Ma, J.; Liang, J.; Chen, C.; and Lu, H. 2023. SubjectDiffusion: Open Domain Personalized Text-to-Image Generation without Test-time Fine-tuning. CoRR, abs/2307.11410. Peng, X.; Zhu, J.; Jiang, B.; Tai, Y.; Luo, D.; Zhang, J.; Lin, W.; Jin, T.; Wang, C.; and Ji, R. 2023. PortraitBooth: A Versatile Portrait Model for Fast Identity-preserved Personalization. CoRR, abs/2312.06354. Pikoulis, I.; Filntisis, P. P.; and Maragos, P. 2023. Photorealistic and Identity-Preserving Image-Based Emotion Manipulation with Latent Diffusion Models. CoRR, abs/2308.03183. Prabhudesai, M.; Goyal, A.; Pathak, D.; and Fragkiadaki, K. 2023. Aligning Text-to-Image Diffusion Models with Reward Backpropagation. CoRR, abs/2310.03739. Ramesh, A.; Dhariwal, P.; Nichol, A.; Chu, C.; and Chen, M. 2022. Hierarchical Text-Conditional Image Generation with CLIP Latents. CoRR, abs/2204.06125. Rombach, R.; Blattmann, A.; Lorenz, D.; Esser, P.; and Ommer, B. 2022. High-Resolution Image Synthesis with Latent Diffusion Models. In CVPR, 10674–10685. IEEE. Ronneberger, O.; Fischer, P.; and Brox, T. 2015a. U-Net: Convolutional Networks for Biomedical Image Segmentation. In MICCAI (3), volume 9351 of Lecture Notes in Computer Science, 234–241. Springer. Ronneberger, O.; Fischer, P.; and Brox, T. 2015b. UNet: Convolutional Networks for Biomedical Image Segmentation. In Navab, N.; Hornegger, J.; III, W. M. W.; and Frangi, A. F., eds., Medical Image Computing and Computer-Assisted Intervention - MICCAI 2015 - 18th International Conference Munich, Germany, October 5 - 9, 2015, Proceedings, Part III, volume 9351 of Lecture Notes in Computer Science, 234–241. Springer. Ruiz, N.; Li, Y.; Jampani, V.; Pritch, Y.; Rubinstein, M.; and Aberman, K. 2023. DreamBooth: Fine Tuning Textto-Image Diffusion Models for Subject-Driven Generation. In CVPR, 22500–22510. IEEE. Schroff, F.; Kalenichenko, D.; and Philbin, J. 2015. FaceNet: A unified embedding for face recognition and clustering. In CVPR, 815–823. IEEE Computer Society. Shan, S.; Ding, W.; Passananti, J.; Zheng, H.; and Zhao, B. Y. 2023. Prompt-Specific Poisoning Attacks on Text-toImage Generative Models. CoRR, abs/2310.13828. Song, J.; Meng, C.; and Ermon, S. 2021. Denoising Diffusion Implicit Models. In ICLR. Taigman, Y.; Yang, M.; Ranzato, M.; and Wolf, L. 2014. DeepFace: Closing the Gap to Human-Level Performance in Face Verification. In CVPR, 1701–1708. IEEE Computer Society. Tumanyan, N.; Geyer, M.; Bagon, S.; and Dekel, T. 2023. Plug-and-Play Diffusion Features for Text-Driven Image-toImage Translation. In CVPR, 1921–1930. IEEE. Valevski, D.; Lumen, D.; Matias, Y.; and Leviathan, Y. 2023. Face0: Instantaneously Conditioning a Text-to-Image Model on a Face. In SIGGRAPH Asia, 94:1–94:10. ACM. von Platen, P.; Patil, S.; Lozhkov, A.; Cuenca, P.; Lambert, N.; Rasul, K.; Davaadorj, M.; and Wolf, T. 2022. Diffusers: State-of-the-art diffusion models. https://github.com/ huggingface/diffusers. Wang, Q.; Bai, X.; Wang, H.; Qin, Z.; and Chen, A. 2024. InstantID: Zero-shot Identity-Preserving Generation in Seconds. CoRR, abs/2401.07519. Wei, Y.; Zhang, Y.; Ji, Z.; Bai, J.; Zhang, L.; and Zuo, W. 2023. ELITE: Encoding Visual Concepts into Textual Embeddings for Customized Text-to-Image Generation. In ICCV, 15897–15907. IEEE. Xiao, G.; Yin, T.; Freeman, W. T.; Durand, F.; and Han, S. 2023. FastComposer: Tuning-Free Multi-Subject Image Generation with Localized Attention. CoRR, abs/2305.10431. Xie, J.; Li, Y.; Huang, Y.; Liu, H.; Zhang, W.; Zheng, Y.; and Shou, M. Z. 2023. BoxDiff: Text-to-Image Synthesis with Training-Free Box-Constrained Diffusion. In ICCV, 74187427. IEEE. Yan, Y.; Zhang, C.; Wang, R.; Zhou, Y.; Zhang, G.; Cheng, P.; Yu, G.; and Fu, B. 2023. FaceStudio: Put Your Face Everywhere in Seconds. CoRR, abs/2312.02663. Ye, H.; Zhang, J.; Liu, S.; Han, X.; and Yang, W. 2023. IPAdapter: Text Compatible Image Prompt Adapter for Textto-Image Diffusion Models. CoRR, abs/2308.06721. Yuan, G.; Cun, X.; Zhang, Y.; Li, M.; Qi, C.; Wang, X.; Shan, Y.; and Zheng, H. 2023. Inserting Anybody in Diffusion Models via Celeb Basis. In Thirty-seventh Conference on Neural Information Processing Systems. Zhang, B.; Qi, C.; Zhang, P.; Zhang, B.; Wu, H.; Chen, D.; Chen, Q.; Wang, Y.; and Wen, F. 2023. MetaPortrait: Identity-Preserving Talking Head Generation with Fast Personalized Adaptation. In CVPR, 22096–22105. IEEE. Zhang, Z.; Chen, H.; Yin, X.; and Deng, J. 2021. Joint Generative Image Deblurring Aided by Edge Attention Prior and Dynamic Kernel Selection. Wirel. Commun. Mob. Comput., 2021: 1391801:1–1391801:14.




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











