






Solving the Problem of Overfitting
The problem of overfitting
-
Underfitting, high bias
-
overfitting, high variance:
If we have too many features, the learned hypothesis may fit the training set very well, but fail to generalize to new examples.
Debugging and Diagnosing
-
address overfitting
-plotting hypothesis(always unpractical with too many features)
-
Options:
-
Reduce number of features
-Manually select which features to keep.
-Model selection algorithm(模型选择算法)
-
Regularization
-Keep all the features, but reduce the magnitude/values of parameters θ j \theta_j θj.
-Works well when we have a lot of features, each of which contributes a bit to predicting y y y.
-
-
Cost function
Regularization
Small values for parameters θ 0 , θ 1 , . . . , θ n \theta_0,\theta_1,...,\theta_n θ0,θ1,...,θn
-“Simpler” hypothesis
-Less prone to overfitting
If have overfitting, we can reduce the weight that some of the items in function carry by increasing their cost.
e.g.
Want to make the following function more quadratic:
θ 0 + θ 1 x + θ 2 x 2 + θ 3 x 3 + θ 4 x 4 \theta_0+\theta_1x+\theta_2x^2+\theta_3x^3+\theta_4x^4 θ0+θ1x+θ2x2+θ3x3+θ4x4
And we want to eliminate the influence of θ 3 x 3 \theta_3x^3 θ3x3 and θ 4 x 4 \theta_4x^4 θ4x4
We can modify cost function:
m i n θ 1 2 m ∑ i = 1 m ( h θ ( x ( i ) ) − y ( i ) ) 2 + 1000 ⋅ θ 3 2 + 1000 ⋅ θ 4 2 min_\theta\frac{1}{2m}\sum^{m}_{i=1}{(h_\theta(x^{(i)})-y^{(i)})^2}+1000\cdot\theta^2_3+1000\cdot\theta^2_4 minθ2m1∑i=1m(hθ(x(i))−y(i))2+1000⋅θ32+1000⋅θ42
Added two extra terms at the end to inflate the cost of θ 3 \theta_3 θ3 and θ 4 \theta_4 θ4 without actually getting rid of them.
In order for the cost function get close to zero($\theta_3,\theta_4\approx$0), we will have reduce the value of θ 3 \theta_3 θ3 and θ 4 \theta_4 θ4 to near zero and in return greatly reduce the values of θ 3 x 3 \theta_3x^3 θ3x3 and θ 4 x 4 \theta_4x^4 θ4x4.
We could regularize all of our theta parameters in :
m i n θ 1 2 m ∑ i = 1 m ( h θ ( x ( i ) ) − y ( i ) ) 2 + λ ∑ j = 1 n θ j 2 min_\theta\frac{1}{2m}\sum^{m}_{i=1}{(h_\theta(x^{(i)})-y^{(i)})^2}+\lambda\sum^n_{j=1}{\theta_j^2} minθ2m1∑i=1m(hθ(x(i))−y(i))2+λ∑j=1nθj2
λ \lambda λ , the regularization parameter, determines how much the costs of parameters are inflated.
If λ \lambda λ is chosen to be too large, it may smooth out the function too much and cause underfitting.
Regularized Linear Regression
Gradient Descent
θ j : = θ j ( 1 − α λ m ) − α 1 m ∑ i = 1 m ( h θ ( x ( i ) − y ( i ) ) x j ( i ) θ_j:=θ_j(1−α\frac{λ}{m})−α\frac{1}{m}∑_{i=1}^m(h_θ(x^{(i)}−y(i))x_j^{(i)} θj:=θj(1−αmλ)−αm1∑i=1m(hθ(x(i)−y(i))xj(i)
( 1 − α λ m ) (1−α\frac{λ}{m}) (1−αmλ) is always be less than 1.
Normal Equation
If λ ≥ 0 \lambda\geq0 λ≥0
θ = ( X T X + λ ⋅ L ) − 1 X T y \theta=(X^TX+\lambda\cdot L)^{-1}X^Ty θ=(XTX+λ⋅L)−1XTy
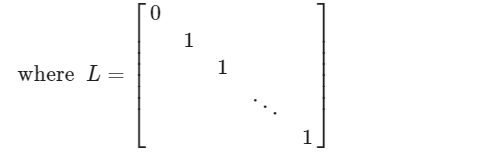
Dimension (n+1)×(n+1)
(m:#examples; n:#features)
If m < n, then X T X X^TX XTX is non-invertible (singular). However, when we add the term λ⋅L, then X T X + λ ⋅ L X^TX+ λ⋅L XTX+λ⋅L becomes invertible.
Regularized Logistic Regression
Cost Function
Cost function for logistic regression:
J ( θ ) = − 1 m ∑ i = 1 m [ y ( i ) l o g ( h θ ( x ( i ) ) ) + ( 1 − y ( i ) ) l o g ( 1 − h θ ( x ( i ) ) ) ] J{(θ)}=−\frac{1}{m}∑_{i=1}^m[y^{(i)}log(h_θ(x^{(i)}))+(1−y^{(i)}) log(1−h_θ(x^{(i)}))] J(θ)=−m1∑i=1m[y(i)log(hθ(x(i)))+(1−y(i))log(1−hθ(x(i)))]
Regularize this equation by adding a term to the end: J ( θ ) = − 1 m ∑ i = 1 m [ y ( i ) l o g ( h θ ( x ( i ) ) ) + ( 1 − y ( i ) ) l o g ( 1 − h θ ( x ( i ) ) ) ] + λ 2 m ∑ j = 1 n θ j 2 J{(θ)}=−\frac{1}{m}∑_{i=1}^m[y^{(i)}log(h_θ(x^{(i)}))+(1−y^{(i)}) log(1−h_θ(x^{(i)}))]+\frac{\lambda}{2m}\sum^n_{j=1}{\theta^2_j} J(θ)=−m1∑i=1m[y(i)log(hθ(x(i)))+(1−y(i))log(1−hθ(x(i)))]+2mλ∑j=1nθj2
∑ j = 1 n θ j 2 \sum^n_{j=1}{\theta^2_j} ∑j=1nθj2 means to explicitly exclude the bias term.
da}{2m}\sumn_{j=1}{\theta2_j}$
∑ j = 1 n θ j 2 \sum^n_{j=1}{\theta^2_j} ∑j=1nθj2 means to explicitly exclude the bias term.
















 231
231











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









