







 博主分享了使用Java处理2个多GB的大.sql文件的过程,包括文件分割、字符集问题、Oracle到PostgreSQL的迁移、函数处理、批量执行SQL及内存优化。遇到的挑战有文件编辑限制、数据格式转换、函数兼容性等,最终实现0%错误率的数据迁移。
博主分享了使用Java处理2个多GB的大.sql文件的过程,包括文件分割、字符集问题、Oracle到PostgreSQL的迁移、函数处理、批量执行SQL及内存优化。遇到的挑战有文件编辑限制、数据格式转换、函数兼容性等,最终实现0%错误率的数据迁移。
楼主喜欢用Java应对各种小需求,以此提高工作效率。
客户在集群上提供了一份.sql文件,有2个多G,用vim等编辑器打不开,只能less一部分,而且内容有乱码(中文部分,也不清楚该份文件的编码格式)——改一下vim的字符集配置就可以解决。
下载文件到本地,尝试用notepad++打开,提示“File is to be opened by Notepate++”;用MySQL Workbench打开,出现卡死。
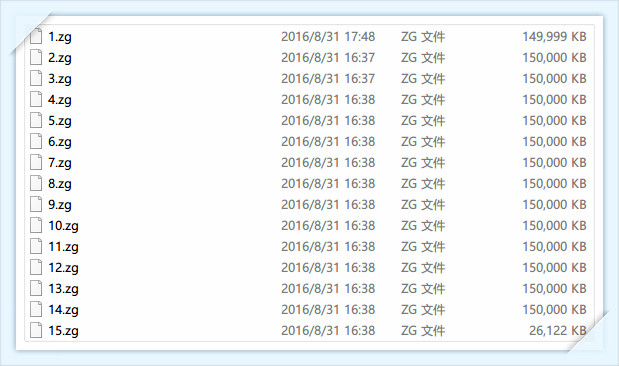
使用文件分割器,对其进行分割。把文件拆分成15等份,每份150MB。
通过less可以看到建表语句,为oracle,改成postgresql版,并建好表。打开1.zg,把insert into之外的语句删掉后,用Navicat for PostgreSQL工具运行sql,出现字符集错误。
以下为数据样式示例:
insert into TB_IMSI_PARAM (NUM, IMSI, SIMNO, COST, PWD, MONTHFEE, EXPDATE, REMARK, CALLFEE, CALLEDFEE, GROUP_ID, GROUP_SHORT_NUM, SHORTNUM_FEE, CONF_FEE, IN_DATE, CARD_TYPE, MOD_DATE, IS_LONG_CARD, SMS_MOFEE, PUKCODE, ACTIVECODE, WIFI_MOFEE, AGENTCODE, SALE_PRICE, UPDATE_TIME, PRODUCT_ID)
values ('GD005', '460018172970051', '8986010712769238551', 2400, '123456', 0, 7, '皇岗集散中心(动)08.01.31-30', 2500, 2501, 57440, '1012', null, null, null, 30, to_date('27-06-2008 10:38:50', 'dd-mm-yyyy hh24:mi:ss'), null, 2013, null, null, 27, 'AYaGD005', null, null, 32);
insert into TB_IMSI_PARAM (NUM, IMSI, SIMNO, COST, PWD, MONTHFEE, EXPDATE, REMARK, CALLFEE, CALLEDFEE, GROUP_ID, GROUP_SHORT_NUM, SHORTNUM_FEE, CONF_FEE, IN_DATE, CARD_TYPE, MOD_DATE, IS_LONG_CARD, SMS_MOFEE, PUKCODE, ACTIVECODE, WIFI_MOFEE, AGENTCODE, SALE_PRICE, UPDATE_TIME, PRODUCT_ID)
values ('GD005', '460018172966280', '8986010712769234780', 2400, '123456', 0, 7, '集散中心(动)08.1.9-30', 2500, 2501, 57420, '0034', 0, 0, null, 30, to_date('27-06-2008 10:38:50', 'dd-mm-yyyy hh24:mi:ss'), null, 2013, null, null, 27, 'AYaGD005', null, null, 32);我们可以发现文件中携带to_date('27-06-2008 10:38:50', 'dd-mm-yyyy hh24:mi:ss')函数,该函数在mysql中没找到,但是postgresql有,所以我们没有必要花大幅功力去切割这个函数。
在实践中,想要对每个文件进行insert into table values(...),values(...)....
最后证实在values中有嵌入函数时,是不能采用该策略的,所以该部分代码不贴。
同时,大家都知道,用oracle工具导出文件时,会有如下:
commit;
prompt 10000 records committed…
commit;
prompt 20000 records committed…
……
这些语句要记得处理。切割并不能保证每份文件都是完整的,所以sql语句的不完整只会在头和尾。有如下几种情况:
1.zg 尾:insert into TB_IMSI_PARAM (NUM, IMSI, SIMNO, COST, PWD, MONTHFEE, EXPDATE, REMARK, CALLFEE, CALLEDFEE, GROUP_ID, GROUP_SHORT_NUM,
2.zg 头:SHORTNUM_FEE, CONF_FEE, IN_DATE, CARD_TYPE, MOD_DATE, IS_LONG_CARD, SMS_MOFEE, PUKCODE, ACTIVECODE, WIFI_MOFEE, AGENTCODE, SALE_PRICE, UPDATE_TIME, PRODUCT_ID)
values (‘GD005’, ‘460018172966280’, ‘8986010712769234780’, 2400, ‘123456’, 0, 7, ‘集散中心(动)08.1.9-30’, 2500, 2501, 57420, ‘0034’, 0, 0, null, 30, to_date(‘27-06-2008 10:38:50’, ‘dd-mm-yyyy hh24:mi:ss’), null, 2013, null, null, 27, ‘AYaGD005’, null, null, 32);
1.zg 尾:values (‘GD005’, ‘460018172966280’, ‘8986010712769234780’, 2400, ‘123456’, 0, 7, ‘集散
2.zg 头:中心(动)08.1.9-30’, 2500, 2501, 57420, ‘0034’, 0, 0, null, 30, to_date(‘27-06-2008 10:38:50’, ‘dd-mm-yyyy hh24:mi:ss’), null, 2013, null, null, 27, ‘AYaGD005’, null, null, 32);
1.zg 尾:insert into TB_IMSI_PARAM (NUM, IMSI, SIMNO, COST, PWD, MONTHFEE, EXPDATE, REMARK, CALLFEE, CALLEDFEE, GROUP_ID, GROUP_SHORT_NUM, SHORTNUM_FEE, CONF_FEE, IN_DATE, CARD_TYPE, MOD_DATE, IS_LONG_CARD, SMS_MOFEE, PUKCODE, ACTIVECODE, WIFI_MOFEE, AGENTCODE, SALE_PRICE, UPDATE_TIME, PRODUCT_ID)
2.zg 头:values (‘GD005’, ‘460018172966280’, ‘8986010712769234780’, 2400, ‘123456’, 0, 7, ‘集散中心(动)08.1.9-30’, 2500, 2501, 57420, ‘0034’, 0, 0, null, 30, to_date(‘27-06-2008 10:38:50’, ‘dd-mm-yyyy hh24:mi:ss’), null, 2013, null, null, 27, ‘AYaGD005’, null, null, 32);
编码如下:
package com.sibat.uhuibao;
import java.io.BufferedReader;
import java.io.BufferedWriter;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStreamReader;
import java.io.OutputStreamWriter;
import java.util.Collections;
import java.util.List;
import com.zh.zsr. 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 142
142

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









