







 本文是作者学习Stanford机器学习课程的心得笔记,介绍了机器学习的基础概念,包括回归、分类,以及监督学习和非监督学习。同时,文章简述了神经网络的历史,从起源、低潮到重生,探讨了深度学习的重要性和常用模型,如自动编码器、限制波尔兹曼机和卷积神经网络。
本文是作者学习Stanford机器学习课程的心得笔记,介绍了机器学习的基础概念,包括回归、分类,以及监督学习和非监督学习。同时,文章简述了神经网络的历史,从起源、低潮到重生,探讨了深度学习的重要性和常用模型,如自动编码器、限制波尔兹曼机和卷积神经网络。
DECLARATION
为了紧跟时代的步伐,在机器学习的浪潮中获得一点乐趣,本人最近对机器学习产生了前所未有的学习热情。但我的专业属于摄影测量与遥感,并不专门研究机器学习,所以纯属小白,如有错误还请指正,大家共同学习。
开博目的:
- 希望能和各位博友进行交流学习,共同进步。
- 希望能通过笔记加深自己对机器学习算法的理解和认知(我忘的快⁄(⁄ ⁄•⁄ω⁄•⁄ ⁄)⁄)。
学习动机:
- 当下,人工智能和机器学习非常火热,这必然也是未来的一种趋势,就业前景应该比较乐观。
- 2016年3月, AlphaGo对战世界围棋冠军、职业九段选手李世石,并以4:1的总比分获胜,令人振奋人心,包括我。
- 其实,机器学习在我的专业领域也具有一定的应用前景,例如遥感影像的分类会涉及到监督分类和非监督分类。所以可以说是科研和事业两不误。
1. Machine Learning-Overview
最近在Coursera正在学习Stanford机器学习大牛Andrew Ng开设的机器学习课程,感觉Andrew Ng的课非常通俗易懂,对我这种入门级的小白帮助很大,现在已经学习完了,并获得了证书(得意脸),基本对机器学习的思想具有了一定系统化的认知,但是对于算法的精髓理解的还不是很透彻。
根据目前的理解,机器学习的应用主要包括:
(1)回归/预测
主要用于连续型的输出,例如预测房价等,模型有线性回归,非线性回归等。
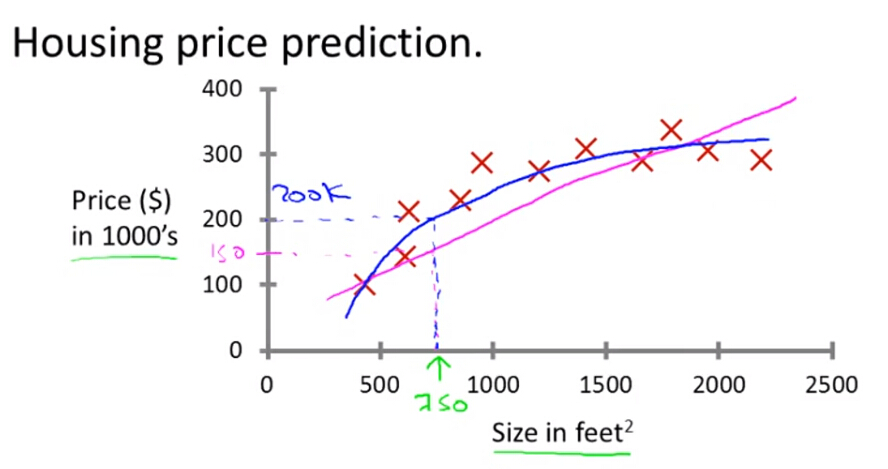
(2)分类
主要用于离散型的输出,例如对产品的正反面评价,如逻辑回归等。
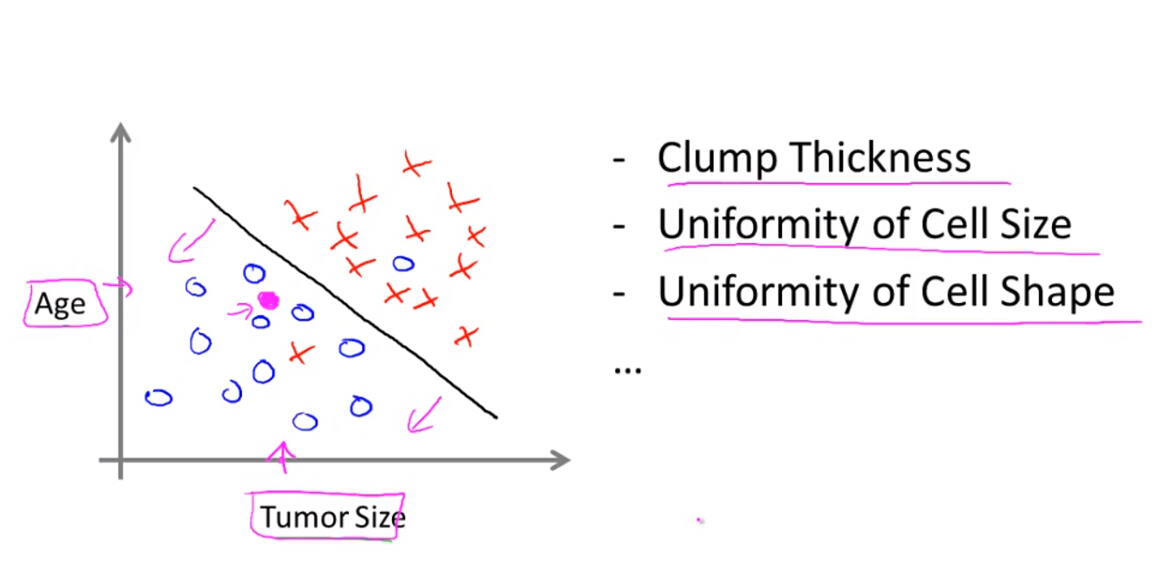
机器学习的算法主要包括两大类:
(1) 监督学习
利用一些带标签的样本对模型进行训练,获取最佳参数。
(2)非监督学习
利用一些无标签的样本对模型直接进行自训练。
2. Neural Networks- Overview
(1)神经网络的渊源
起源
神经网络作为一个计算模型的理论,1943年最初由科学家 Warren McCulloch 和 Walter Pitts 提出。 1957年,康奈尔大学教授Frank Rosenblatt提出了“感知器”(Perceptron)的概念,是第一个用算法来精确定义神经网络的人,创造了第一个具有自组织自学习能力的数学模型,是日后许多新的神经网络模型的始祖。
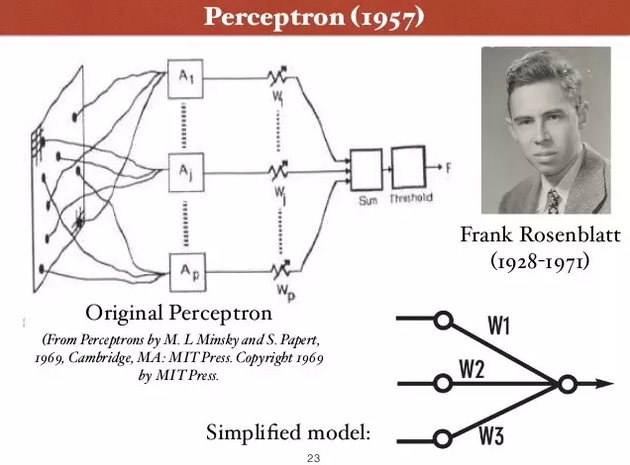
低潮
Rosenblatt 乐观地预测,感知器最终可以 “学习、做决定、翻译语言”。感知器的技术,六十年代一度走红,美国海军曾出资支持这个技术的研究,期望它 “以后可以自己走、说话、看、读、自我复制、甚至拥有自我意识”。Rosenblatt 和 Minsky 实际上是间隔一级的高中校友。但是六十年代,两个人在感知器的问题上展开了长时间的激辩。Rosenblatt 认为感应器将无所不能,Minsky 则认为它应用有限。1969 年,Marvin Minsky 和 Seymour Papert 出版了新书:“感知器:计算几何简介”。书中论证了感知器模型的两个关键问题:
第一,单层的神经网络无法解决不可线性分割的问题,典型例子如异或门,XOR Circuit ( 通俗地说,异或门就是:两个输入如果是异性恋,输出为一。两个输入如果是同性恋,输出为零 )
第二,更致命的问题是,当时的电脑完全没有能力完成神经网络模型所需要的超大的计算量。
此后的十几年,以神经网络为基础的人工智能研究进入低潮,相关项目长期无法得到政府经费支持,这段时间被称为业界的核冬天。Rosenblatt 自己则没有见证日后神经网络研究的复兴。1971年,他 43 岁生日时,不幸在海上开船时因为事故而丧生。
重生
1970年,当神经网络研究的第一个寒冬降临时。在英国的爱丁堡大学,一位二十三岁的年轻人,Geoffrey Hinton,刚刚获得心理学的学士学位。Hinton 六十年代还是中学生时,就对脑科学着迷。当时一个同学给他介绍关于大脑记忆的理论是:大脑对于事物和概念的记忆,不是存储在某个单一的地点,而是像全息照片一样,分布式地存在于一个巨大的神经元的网络里。
分布式表征 (Distributed Representation),是神经网络研究的一个核心思想。
它的意思是,当你表达一个概念的时候,不是用单个神经元一对一地存储定义;概念和神经元是多对多的关系:一个概念可以用多个神经元共同定义表达,同时一个神经元也可以参与多个不同概念的表达。
举个最简单的例子。一辆 “大白卡车”,如果分布式地表达,一个神经元代表大小,一个神经元代表颜色,第三个神经元代表车的类别。三个神经元同时激活时,就可以准确描述我们要表达的物体。
分布式表征和传统的局部表征 (Localized Representation) 相比,存储效率高很多。线性增加的神经元数目,可以表达指数级增加的大量不同概念。
分布式表征的另一个优点是,即使局部出现硬件故障,信息的表达不会受到根本性的破坏。这个理念让 Hinton 顿悟,使他四十多年来,一直在神经网络研究的领域里坚持下来没有退缩。本科毕业后,Hinton 选择继续在爱丁堡大学读研,把人工智能作为自己的博士研究方向。周围的一些朋友对此颇为不解。“你疯了吗? 为什么浪费时间在这些东西上? 这 (神经网络) 早就被证明是扯淡的东西了。”Hinton 1978 年在爱丁堡获得博士学位后,来到美国继续他的研究工作。
(2)神经网络的精髓
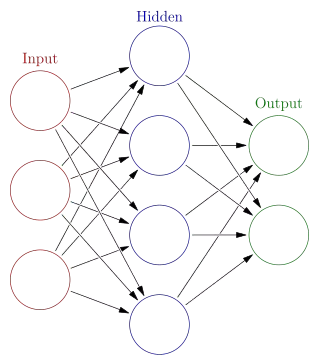
人工智能研究的方向之一,是以所谓 “专家系统” 为代表的,用大量 “如果-就” (If - Then) 规则定义的,自上而下的思路。人工神经网络(Artifical Neural Network),标志着另外一种自下而上的思路。神经网络没有一个严格的正式定义,它的基本特点,是试图模仿大脑的神经元之间传递,处理信息的模式。
一个计算模型,要划分为神经网络,通常需要大量彼此连接的节点 (也称“神经元”),并且具备两个特性:每个神经元,通过某种特定的输出函数 (也叫激励函数 activation function),计算处理来自其它相邻神经元的加权输入值神经元之间的信息传递的强度,用所谓加权值来定义,算法会不断自我学习,调整这个加权值,在此基础上,神经网络的计算模型,依靠大量的数据来训练,还需要:
成本函数 (cost function):用来定量评估根据特定输入值, 计算出来的输出结果,离正确值有多远,结果有多靠谱。
学习的算法 ( learning algorithm ):这是根据成本函数的结果, 自学, 纠错, 最快地找到神经元之间最优化的加权值。
神经网络算法的核心就是:计算、连接、评估、纠错、疯狂培训。随着神经网络研究的不断变迁,其计算特点和传统的生物神经元的连接模型渐渐脱钩。但是它保留的精髓是:非线性、分布式、并行计算、自适应、自组织。
(2)深度学习
起源
深度学习的概念源于人工神经网络的研究。含多隐层的多层感知器就是一种深度学习结构。深度学习通过组合低层特征形成更加抽象的高层表示属性类别或特征,以发现数据的分布式特征表示。
深度学习的概念由Hinton等人于2006年提出。基于深度置信网络(DBN)提出非监督贪心逐层训练算法,为解决深层结构相关的优化难题带来希望,随后提出多层自动编码器深层结构。此外Lecun等人提出的卷积神经网络是第一个真正多层结构学习算法,它利用空间相对关系减少参数数目以提高训练性能。
模型
Deep Learning的常用模型或者方法:
- 自动编码器(AutoEncoder)
- 稀疏编码(Sparse Coding)
- 限制波尔兹曼机(Restricted Boltzmann Machine,RBM)
- 深度置信网络(Deep Belief Networks,DBNs)
- 卷积神经网络(Convolutional Neural Networks,CNNs)
同机器学习方法一样,深度机器学习方法也有监督学习与无监督学习之分。不同的学习框架下建立的学习模型很是不同。例如,卷积神经网络(CNNs)就是一种深度的监督学习下的机器学习模型,而深度置信网(DBNs)就是一种无监督学习下的机器学习模型。
第一次先写这吧!















 2003
2003

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









