







Notes:
前面章节中主要讲了机器学习的一个应用方向:回归预测。接下来的课程主要讲机器学习的另外一个应用方向:分类。其中,逻辑回归模型(Logistic Regression Model)主要用于分类应用。
1. Classification with two classes
假设要解决两类的分类问题,即y=0和y=1,利用线性回归的模型解决分类问题往往不是很理想,而且线性回归模型的输出值有可能远远大于1或小于0,而逻辑回归模型的输出值可保持在0和1之间,能较好的解决分类问题。
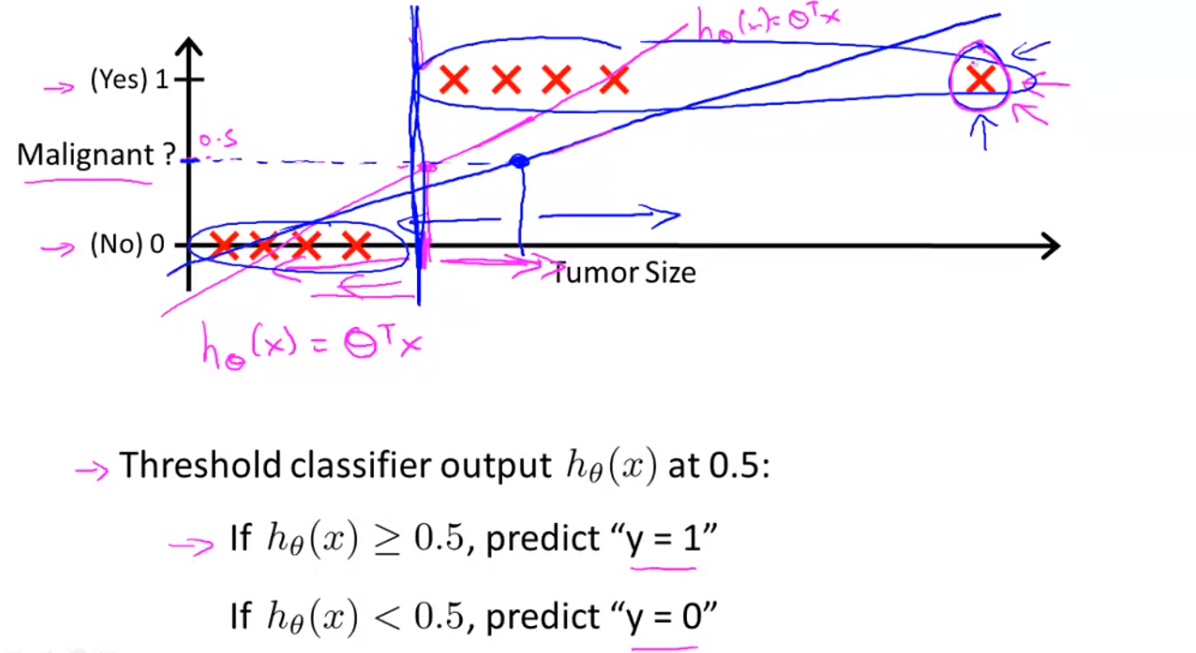

2. Hypothesis Presentation
(1)逻辑回归模型的假设函数为:
其中, g(z) 为S函数(Sigmoid Function)或逻辑函数(Logistic Fucntion),它的值域是0到1。
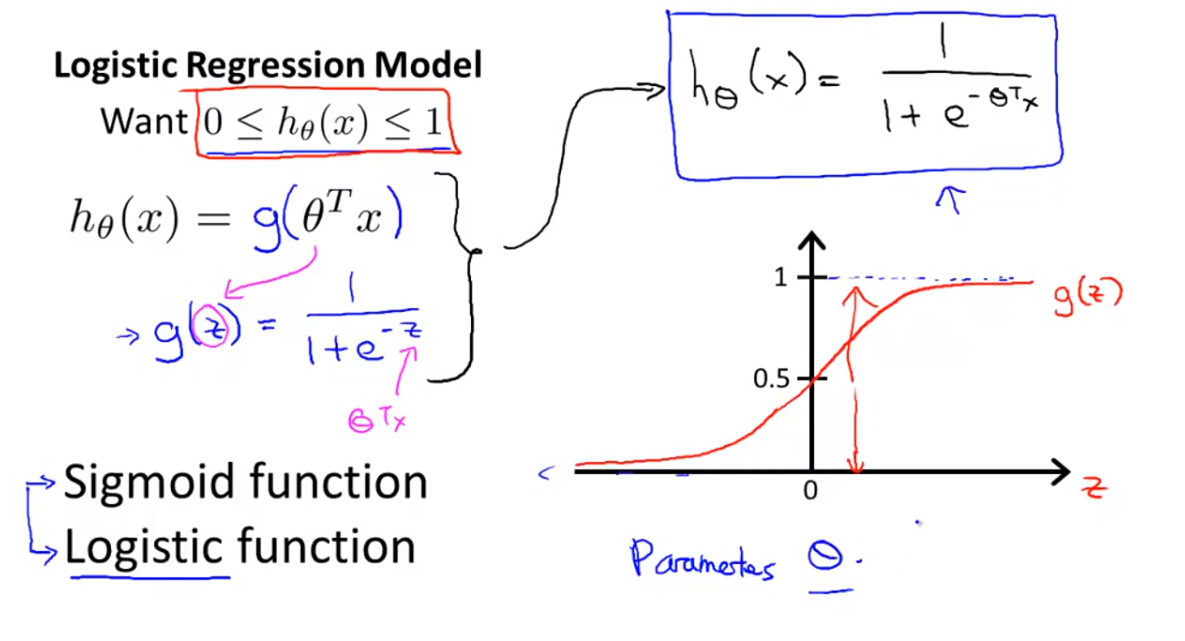
(2)逻辑回归模型假设函数的意义
逻辑回归模型是依靠逻辑函数输出某一样本属于某一类(y=1)的概率大小。

3. Decision Boundary
(1)决策边界即是分类的边界,上节中我们知道假设函数是样本属于某一类的概率,所以需要我们定义一个阈值,大于阈值的则分类为1(y=1);小于阈值的则分类为0(y=0),假设阈值为0.5,根据Sigmoid函数的函数曲线可知:
- 当 z=θTx 大于0时, hθ(x) 大于0.5
- 当 z=θTx 小于0时, hθ(x) 小于0.5
即:
所以,当有新样本时,直接计算 θTx 的正负属性,即可判别该样本的类别。

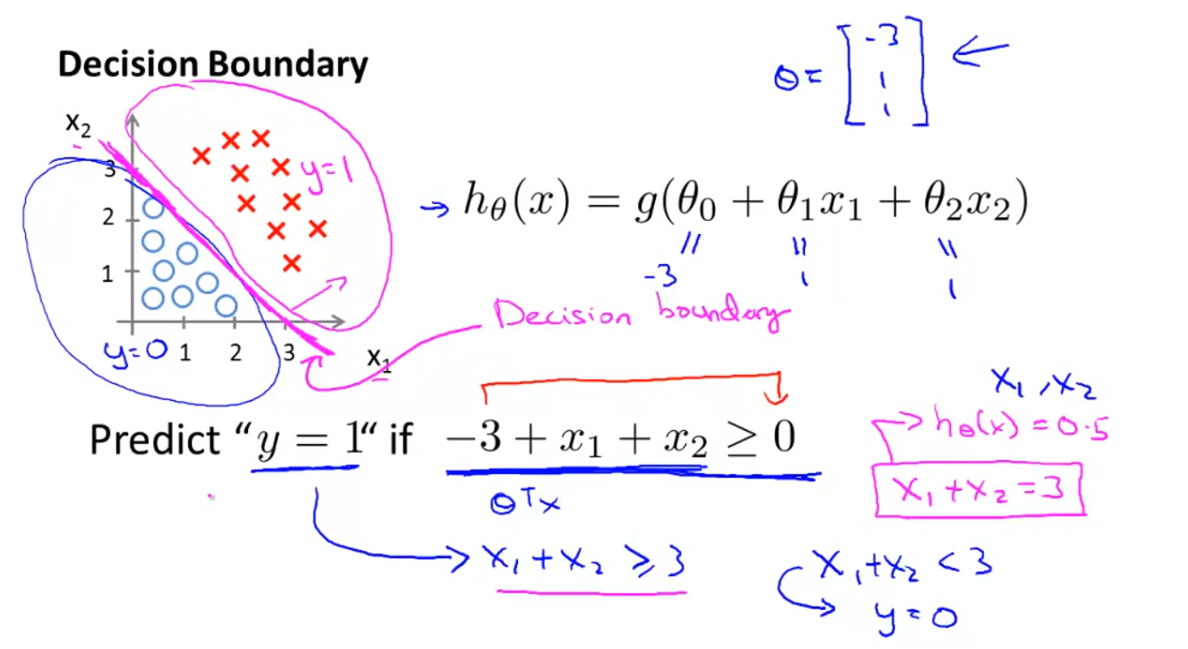
(2)线性决策边界
下图可以看出决策边界大致呈线性关系,则
θTx
为简单的多项式模型即可得出准确的决策边界。假设已知参数
θ
(下节中讲如何训练参数),令假设函数的分类阈值为0.5,则可根据
θTx
的正负进行判别样本类别。如果
θTx
大于0,则y=1;如果
θTx
小于0,则y=0。
(3)非线性决策边界
下图可以看出决策边界呈非线性关系,则
θTx
必须为复杂的多项式模型才可确定复杂的决策边界。假设已知参数
θ
(下节中讲如何训练参数),令假设函数的分类阈值为0.5,根据
θTx
的正负进行判别样本类别。如果
θTx
大于0,则y=1;如果
θTx
小于0,则y=0。

Notes:
- 多项式模型越复杂,决策边界越复杂;
- 决策边界是假设函数的属性,即是训练出来的参数决定的决策边界,而不是训练数据集确定的决策边界。
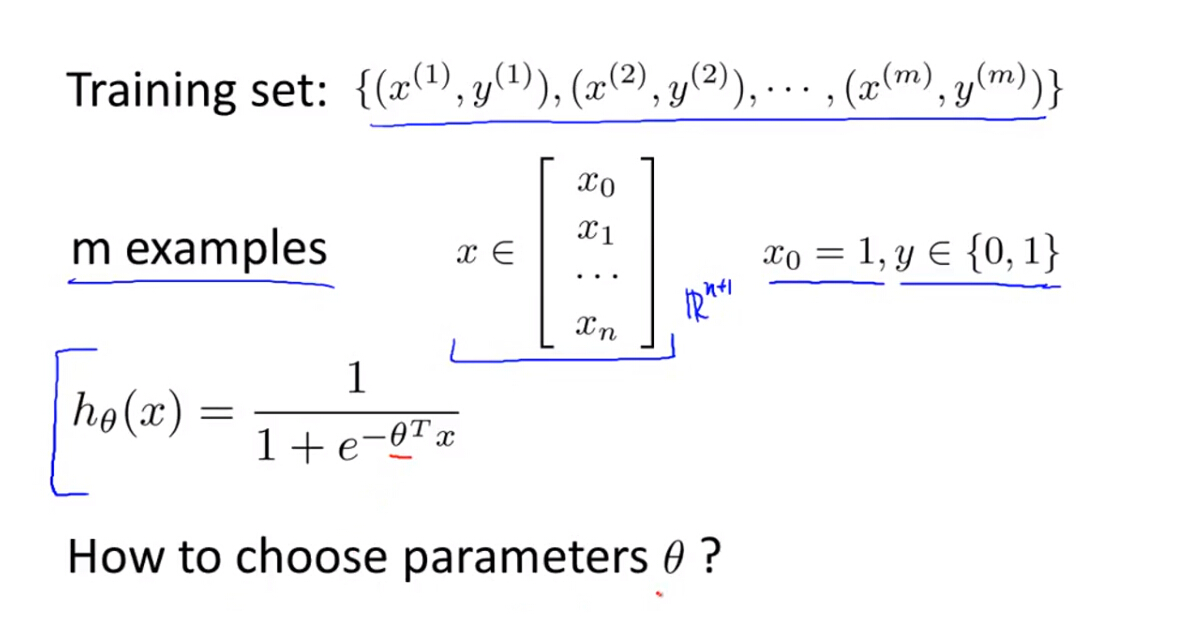
4. Cost Function for Logistic Regression
(1)前面直接给定了逻辑回归模型的参数值,接下来要利用梯度下降优化算法进行参数选取,首先要建立逻辑回归模型的代价函数。
(2)为了定义逻辑回归模型的代价函数 J(θ) ,首先定义Cost函数,Cost函数可以理解为如果我们要把样本判别为y=1时所要付出的代价。
对于线性回归模型(Linear Regression),Cost函数为:
Cost(hθ(x),y)=12(hθ(x)−y)2因为线性回归模型的假设函数 hθ(x) 是线性模型,所以其代价函数属于凸函数。但是对于逻辑回归模型,其假设函数 hθ(x) 是Sigmoid函数,属于非线性模型,所以其代价函数如果按照上述线性代价函数使用,则其代价函数属于非凸函数,可能会出现局部最优解的问题。所以下一步需要建立逻辑回归模型的代价函数 J(θ) 。
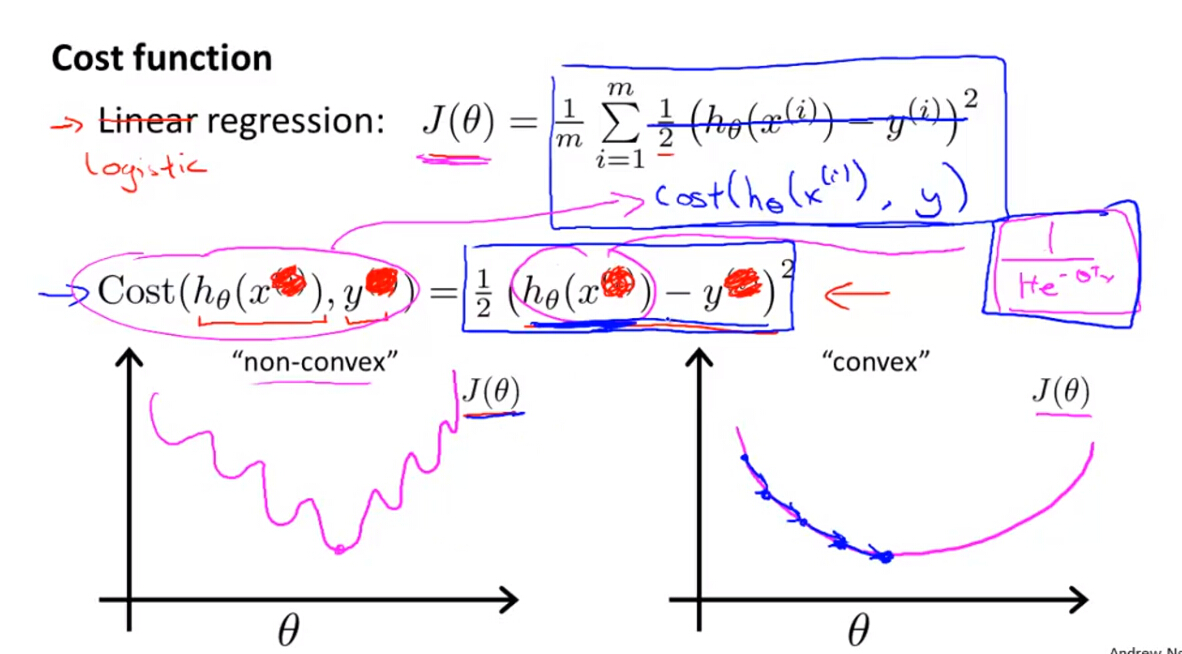
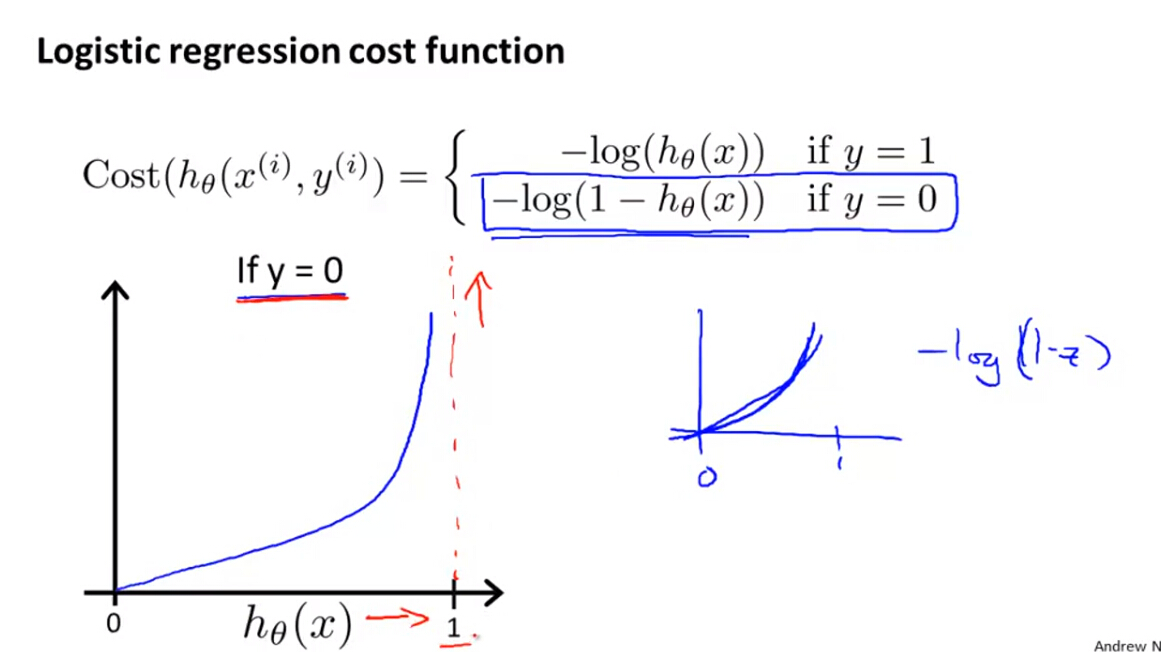
(3)逻辑回归模型的代价函数是一个分段函数,其Cost函数定义如下:
这个Cost函数可以这样理解:
如果真实值y=1,则根据cost函数的函数曲线可以知道:
当假设函数的预测值靠近0时,则Cost函数的值趋于无穷大,即将样本判别为1(错误)的代价比较大。
当假设函数的预测值靠近1时,则Cost函数的值趋于0,即将样本判别为1(正确)的代价比较小。如果真实值y=0,则根据cost函数的函数曲线可以知道:
当假设函数的预测值靠近0时,则Cost函数的值趋于0,即将样本判别为0(正确)的代价比较小。
当假设函数的预测值靠近1时,则Cost函数的值趋于无穷大,即将样本判别为0(错误)的代价比较大。


5. Simplified Cost Function and Gradient Descent
(1)前面的Cost函数是分段函数,为了方便之后的梯度下降法,需要将分段函数简化为一个函数
即是计算判别为某一类别的概率。下一步主要讲梯度优化算法的实现。


(2)利用梯度优化算法训练逻辑回归模型,关键在于计算代价函数关于所有参数的偏导数项。
根据求导可以发现,线性回归和逻辑回归的梯度下降算法在形式上是一样的,只是其中的假设函数
hθ(x)
不同,一个是线性模型(多项式),一个是非线性模型(Sigmoid函数),所以本质上是不一样的。梯度下降参数更新如下:

(3)在利用梯度下降算法计算逻辑回归模型优化参数时,也可以利用之前说的代价函数官员迭代次数的曲线图进行验证算法的正确性,另外,特征尺度归一化也可应用于逻辑回归模型。
6. Advanced Optimization Algorithms
除了梯度下降法,还有其他更加复杂的优化算法,例如:
- 共轭梯度法(Conjugate Gradient)
- 变尺度法(BFGS)
- 限制变尺度法(L-BFGS)
这些算法的优点主要是不需要手动选择学习率,运算速度较梯度下降较快,缺点是比较复杂。应用这些算法对参数进行优化时的主要步骤是:
- 给定样本
x
和参数
θ - 计算代价函数和代价函数 J(θ) 关于不同参数的偏导数项 ∂∂θjJ(θ)
- 将代价函数和偏导数项算法带入优化算法,即可求出最优参数值。

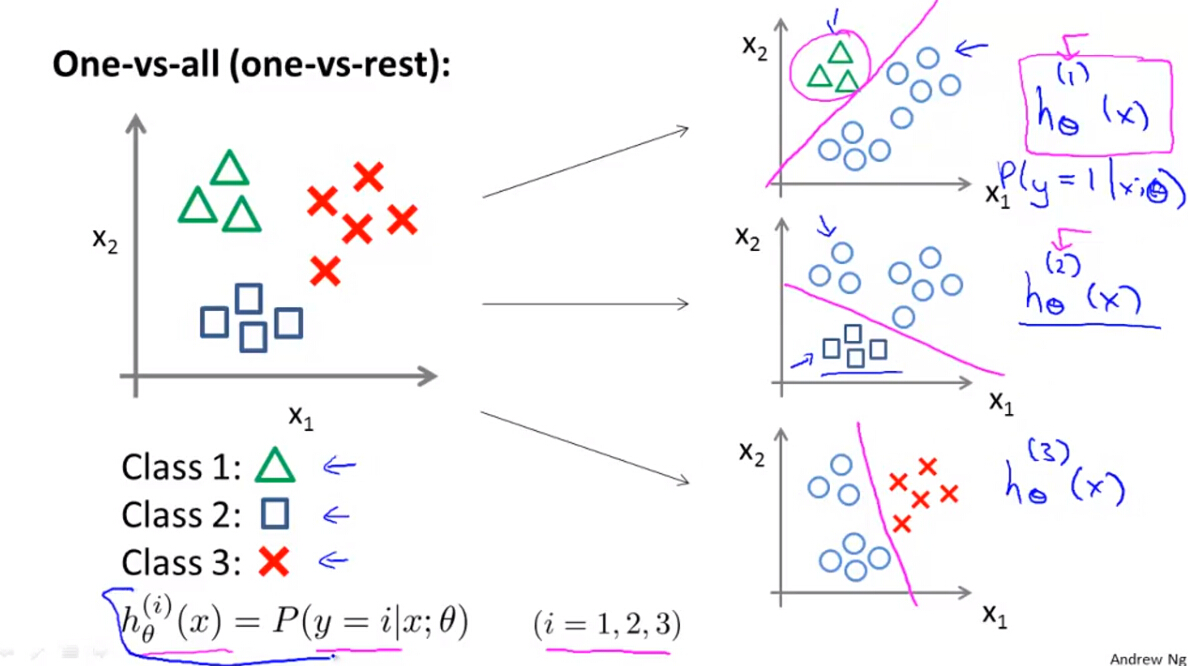
7. Multiclass Classification: One-vs-all
前面所讲的是关于两类问题的分类问题,如果应用到多类别中,则可以根据“一对多”的原则进行分类,具体来说是:
- 首先将某一类与其他类作为两类,这样就变成了两类问题,对于这一类,利用训练样本解算出关于这类的最佳假设函数模型 h(1)θ(x) 。
- 对于每一类别,都按照上述方法解算出最佳假设函数模型 h(i)θ(x) 。
- 针对新加入的样本,同时解算上述假设函数模型,求取最大值( Maximize h(i)θ(x) )即可判别样本所属类别。
















 1577
1577

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









