






论文名字:Towards Efficient and Scale-Robust Ultra-High-Definition Image Demoir´eing
论文下载地址:https://arxiv.org/abs/2207.09935
论文代码地址: https://xinyu-andy.github.io/uhdm-page
论文内容:获取多语义信息并交互融合以处理超高清图像去摩尔纹。
具体内容:随着拍照设备的进步,超高清图像的获取更加容易,也对超高清图像的去摩尔纹技术提出了新的要求:处理负担小、处理分辨率高。
现有方法都是从低分辨率图像上训练和测试,在4K图像上难以去除摩尔纹,但他们也能承受对应的计算成本(即方法的计算成本可负担但效果欠佳),作者认为这些方法欠缺多尺度特征的有效提取策略(可能还有融合策略)。
**笔者观点:**去摩尔纹有种常用的方法是将输入下采样(通常是两次)放到对应的三个分支中,分辨率大小的改变意味着语义信息的不同,最直观的感受是同样10×10大小的感受野,缩略图看到的是一个结构而高清图看到的只是细节,此外同一分支中随着卷积的增加,语义信息也在发生改变。而分支之间的交互也即语义之间的交互都放在输出阶段,缺少有效交互和融合。因此作者想从这一点下手解决问题。
提出的方法一共分三点:DRDB模块、SAM模块、损失函数。整体结构框架如下(图画的真不赖):
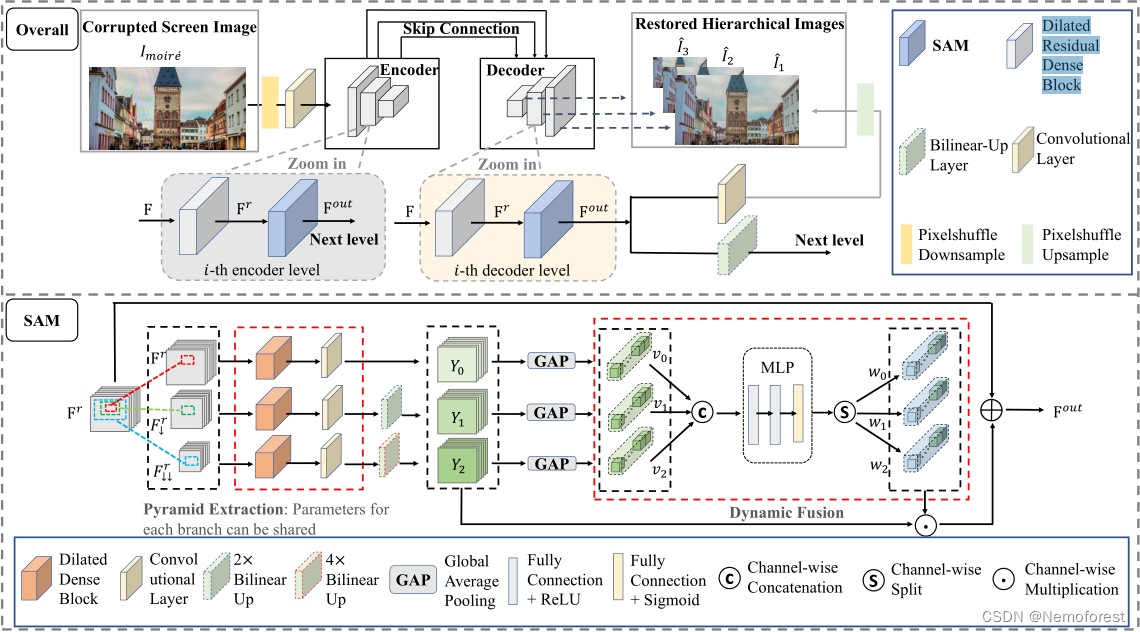
DRDB(Dilated Residual Dense Block)
老面孔了,就是简单的密集块加空洞卷积,最后使用残差链接,感兴趣的可以查看这篇内容:残差密集块。
SAM(Semantic-Aligned Scale-Aware Module)
这是作者提出的模块,也是解决多尺度(语义)的核心。由两个小模块组成,分别是: pyramid feature extraction 和cross-scale dynamic fusion
Pyramid feature extraction
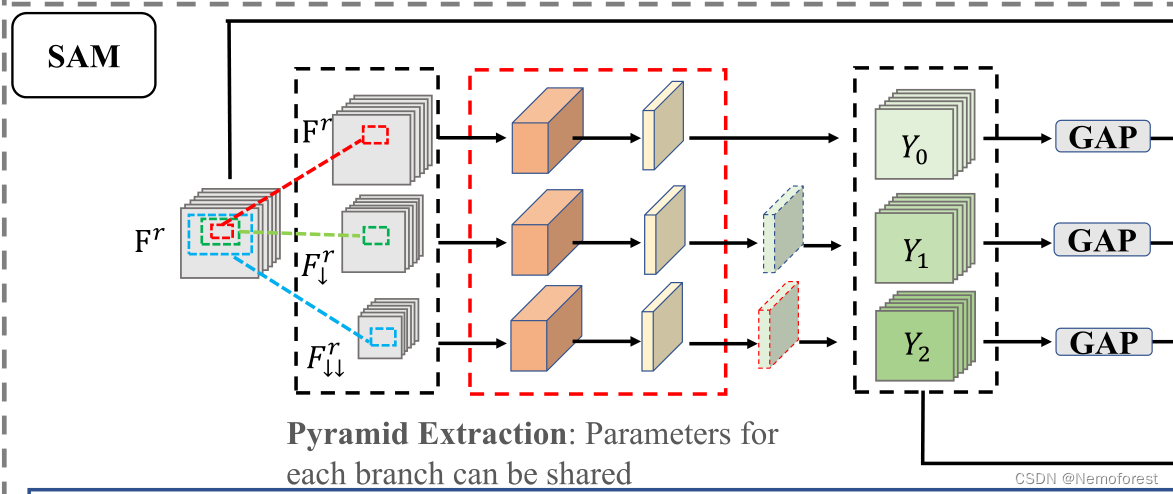
首先对输入使用双线性差值进行下采样,然后经过扩展密集块(密集块+空洞卷积)再经过一个卷积层,由于这里的模块结构一样,因此参数也可以共享。为了保持输出的大小一致,因此增加了双线性差值上采样得到结果 Y 0 , Y 1 , Y 2 Y_0,Y_1,Y_2 Y0,Y1,Y2
Cross-scale dynamic fusion
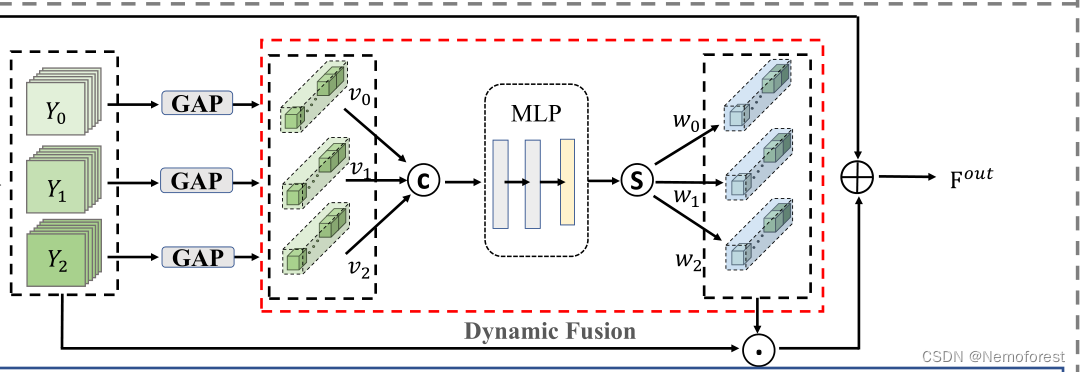
对上一个模块的输出在空间维度做一个GAP,得到每一个channel一个值,拼接起来,过三层全连接层,分解回三个尺度,再对上一个模块的输出做一个相乘的操作,最后是一个残差链接。
**笔者观点:**这里其实就是一个channel-attention的操作。因为4K图像的分辨率很高,而摩尔纹的尺度范围也很大,可以是很大范围的摩尔纹也可以是一个很小范围内的摩尔纹,每张图像的侧重都不一样,因此需要做一个attention的操作,这点在论文中可以得到印证。但是我感到疑惑的是为什么不是把三个尺度各自作为一个整体而是全部channel都看作是单独的元素(如果这里不是做3分支而是做成5分支甚至50分支,操作都是一样的,并没有体现出三分支的特点)可能是模型足够强大可以学到最优的参数?此外,对齐不清楚体现在哪里?
损失函数
采用深度监管策略,简单讲就是在中间层加入分支对主干网络进行监督,感兴趣的可以查看 深度监管策略,在该模型中则是获得三种尺度的输出图像,具体见整体结构框架图像。同时对语义信息采取感知损失。
Experiments
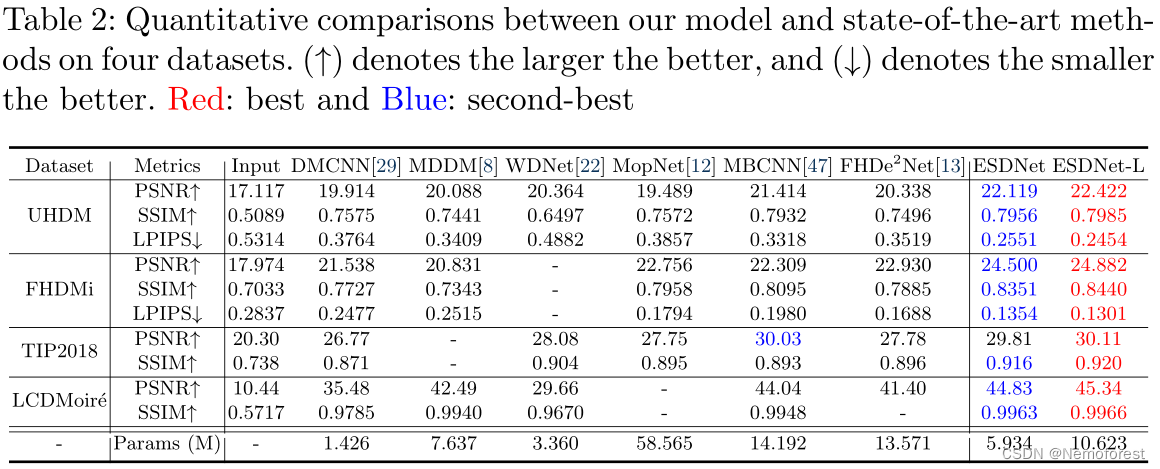
数据集:FHDM i、TIP2018、LCDMoire、UHDM
评价指标:PSNR、SSIM、LPIPS
定量/定性

消融实验

A代表SAM中两个模块都没有
A+代表SAM中两个模块都没有,但是参数两调整到和E一致
B代表有金字塔上下文提取,且共享参数
D代表有金字塔上下文提取,不共享参数
C代表有跨尺度动态融合
E代表拥有全部组件的模型
金字塔上下文提取,且共享参数
D代表有金字塔上下文提取,不共享参数
C代表有跨尺度动态融合
E代表拥有全部组件的模型















 3289
3289











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









