







目录
前言
FastAPI真的是个非常好用的东西。首先它是异步,但是我想说的是Fast API对于保证数据交互传递过程中的一致性,保持的非常好。
当然,能做到这一点也是因为它站在了巨人肩膀上,因为它的schema是依靠pydantic来做的。
大家用Fast API的过程中会越来越发现,Fast API实现的东西并不多,它大部分的功能都是基于其他工具的(如pydantic、startllete)。
今天想记录一下Fast API中实现的一个非常好用的工具——Depends,它能帮我们减少很多的代码。当然,我也是看官方文档然后结合自己的理解来写这篇文章,小伙伴们如果有精力还是建议去看官方文档,Fast API的官方文档写的很通俗易懂的。
一、Depends的是干什么的?
我们知道Fast API对于路径参数(path parameter)、请求参数(Query parameters)、请求体参数(body parameters)有很明确的区别。简单的说一下,
- path parameters 也就是你在路径里怎么传参,如 www.baidu.com/image/baike?id=001 这种,你想把image作为参数传,那么你要写成 www.baidu.com/{type}/
- Query parameters 可以当成是get请求中的查询参数,如 www.baidu.com/image/baike?id=001 ,其中id=001 就是查询参数
- body parameters 默认是json形式传参,用于post请求中的请求体,使用继承BaseModel的类进行schema
而我们今天要说的Depends,其实就是对于Query parameters的schema
为什么要Depends呢?大家看完fastAPI 用于post请求的body parameters的schema参数,是不是觉得这种schema方式很好,只要提供一个类,就可以完成传参的校验,并且还可以在Fast API的docs可视化文档中形成参数提示。也增加了代码的可重复利用性,减少了代码冗余。
那么,类比过来,对于get请求的Query parameters,我们是不是也希望有这么一种方式,可以写一个类,然后就可以自动解析url中的参数,并且进行schema,还在docs文档中生成提示?
对了,Depends可以完美完成,并且Depends还不止这些作用,还可以用来提供数据库连接、外部api连接等等,我们后面接着看吧。
二、Depends的两种用法
1、Depends(function)形式
记住一点:我们管Depends这种方式,叫做 Dependency Injection。当然内部Fastapi做了很多工作。但是请记住Dependency Injection,对于我们理解很有用处。
引用官方文档一个例子,如下:
from typing import Optional
from fastapi import Depends, FastAPI
app = FastAPI()
async def common_parameters(q: Optional[str] = None, skip: int = 0, limit: int = 100):
return {"q": q, "skip": skip, "limit": limit}
@app.get("/items/")
async def read_items(commons: dict = Depends(common_parameters)):
return commons
if __name__ == '__main__':
uvicorn.run(app, host="0.0.0.0", port=8080, loop="asyncio")
我们看到了Depends的使用,它接收了一个参数,是一个function。这个function里定义了一些参数。那么我们运行起来,看看这个接口有什么不同?打开http://127.0.0.1:8080/docs连接,查看可视化文档。

我们找到了这个接口,看看它的chema有什么?
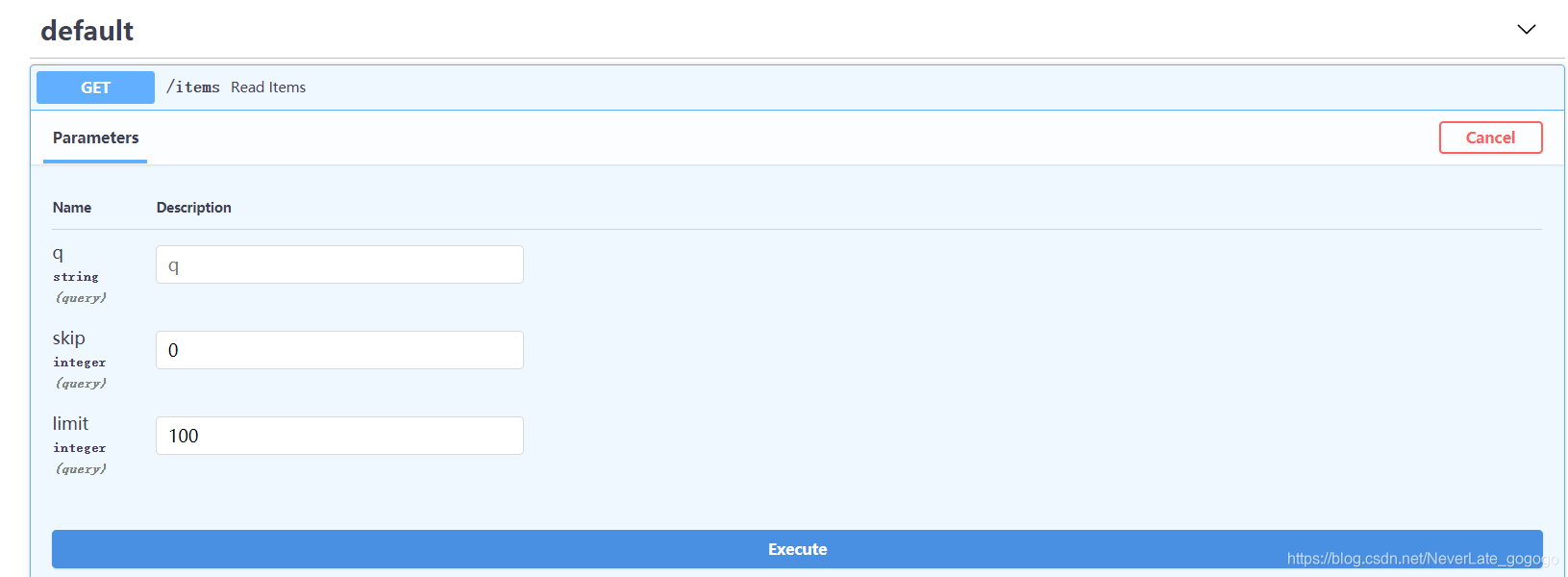
多了三个参数query参数 q、skip、limit,那么他们是从哪里来的呢?
没错,就是从Depends(common_parameters)这里来的。并且,由于我们设置了默认值,所以是否对q、skip、limit传参是可选的。我们点击Execute,如下:

看Request URL,证明了是把 Depends(common_parameters)当成Query parameters来使用的。
那么参数被怎么使用了呢?这个你就不用担心了,因为FastAPI已经帮你做了参数解析,什么意思呢?还记得:commons: dict = Depends(common_parameters)这句话吧,
意思就是:当有人访问http://127.0.0.1:8080/items?skip=0&limit=100这种地址时,后台会自动将自动把skip=0&limit=100这段解析出来,并赋值给commons参数,由于function返回的是一个dict,所以commons也是一个dict,我们就可以通过common.get(limit)得方式去访问这些传入的参数了。当然function也可以返回tuple、list等形式,那么commons就是对应的类型。
那么,可以像这种形式访问吗? http://127.0.0.1:8080/items 答案是可以的。为什么,因为我们在function: common_parameters 中都给参数设置了默认参数,所以可以使用默认参数。下面我们来验证一下,使用浏览器访问http://127.0.0.1:8080/items,如下所示:
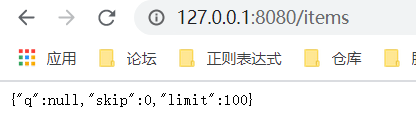
正确的返回。
那么,如果我在function中设置一个必传参数呢?如下代码。首先我们看一下docs可视化文档有什么变化。如下,多了一个required的参数desc,也就是说这个是必须输入的。
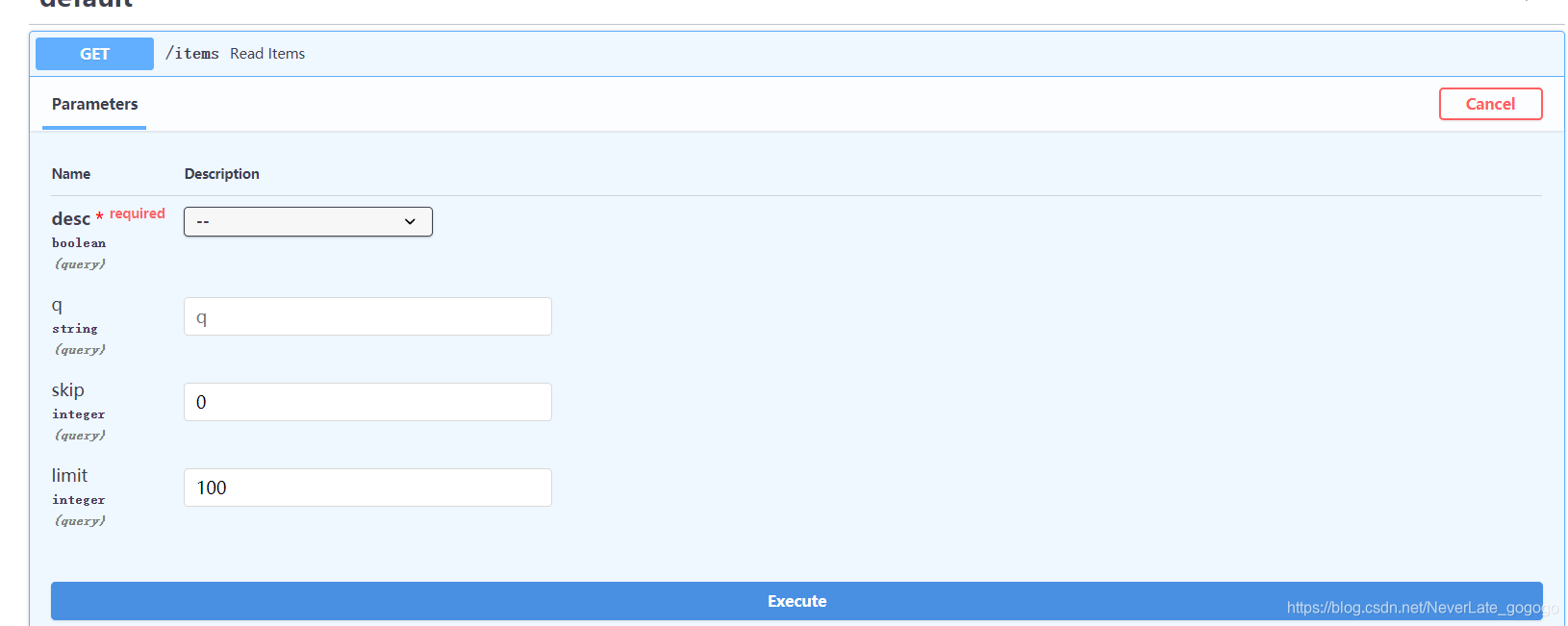
那我们使用浏览器访问http://127.0.0.1:8080/items ,我就是不传desc,你能把我咋滴。如下,报错了,说的是没有传递desc参数。

那我给desc传递一个str类型的参数呢?报错了,提示说要传bool值。

通过以上的分析,我们就很明确Depends的方式,诠释了Dependency Injection的含义。真的是很好用。今后有时间了要看看Depends的源码,学习一下别人的实现方式,再补充到这篇文章。
段官方文档说明下Depends为什么可以完成注入,主要是以下3个步骤:
- 首先查看是否有dependence的使用,如果有,调用 depedency function,从URL中解析出要使用的参数传给 depedency function
- 获取depedency function的result,也就是return的值
- 将获取的dict值注入到 路径参数 中
以上三步,也说明了为什么我们写在Depends(function)里的参数可以进入到路径参数中。
所以后台得到的路径参数是,前端传递的url路径参数,经过Depends加工后传递给后台路径函数的。
另外,Depends(function) 的function要写成同步的还是异步的,其实都可以。
2、Depends(class)形式
其实使用Depends(function)这种形式有一些缺陷。这里再贴一下我们前面的代码,使用Depends(function)形式。从可读性角度,这种方式适合于参数比较容易被理解其含义的情景。
为什么?因为这种形式ID E并不能给你提供提示(hint)。
from typing import Optional
from fastapi import Depends, FastAPI
app = FastAPI()
async def common_parameters(q: Optional[str] = None, skip: int = 0, limit: int = 100):
return {"q": q, "skip": skip, "limit": limit}
@app.get("/items/")
async def read_items(commons: dict = Depends(common_parameters)):
return commons
if __name__ == '__main__':
uvicorn.run(app, host="0.0.0.0", port=8080, loop="asyncio")
而class形式的传参其实是对function的一种升级,为什么这么说呢?,比如,我要实现一个参数相对复杂的Depends,比如Person,有name,age,height、sex等等。那么使用class的形式就比较好,会有hint提示,并且还可以使用 属性访问形式来访问元素。
但是,大家有没有想过,为什么Depends接收class也行呢?
官网上说:Depends可以接收任何callable的对象。 但是是不是落下一点,你这个callable对象得有返回值吧?就像我们上面的common_parameters函数一样。我们可以试试没有返回值,是什么样的。代码如下。
from typing import Optional
from fastapi import Depends, FastAPI
app = FastAPI()
async def common_parameters(q: Optional[str] = None, skip: int = 0, limit: int = 100):
pass
@app.get("/items/")
async def read_items(commons= Depends(common_parameters)):
return commons
if __name__ == '__main__':
uvicorn.run(app, host="0.0.0.0", port=8080, loop="asyncio")
查看docs,我们发现校验的参数不变,唯一变化的就是async def read_items(commons= Depends(common_parameters)) 里面的commons是None。能想通,因为commons得到的是Depends(function)中function的返回值嘛。你返回None,可不commons就为None了。
所以Dpends接收的cllable对象有没有返回值都行。

但是这样commons这个参数就没意义了不是,所以我认为,从可用的角度上改成下面这句话:
” Depends接收任何有返回值的callable对象 “ 比较合适。
ok,我们使用Depends(class)的形式实现一把,看看有啥发现,代码如下:
import uvicorn
from fastapi import Depends, FastAPI
from typing import Optional
from pydantic import BaseModel
app = FastAPI()
class CommonQueryParams:
def __init__(self, q: Optional[str] = None, skip: int = 0, limit: int = 100):
self.q = q
self.skip = skip
self.limit = limit
@app.get("/items")
async def read_items(common=Depends(CommonQueryParams)):
return common
if __name__ == '__main__':
uvicorn.run(app, host="0.0.0.0", port=8080, loop="asyncio")
我们来看看docs有啥变化不,如下。可以正常访问,并没有啥变化。
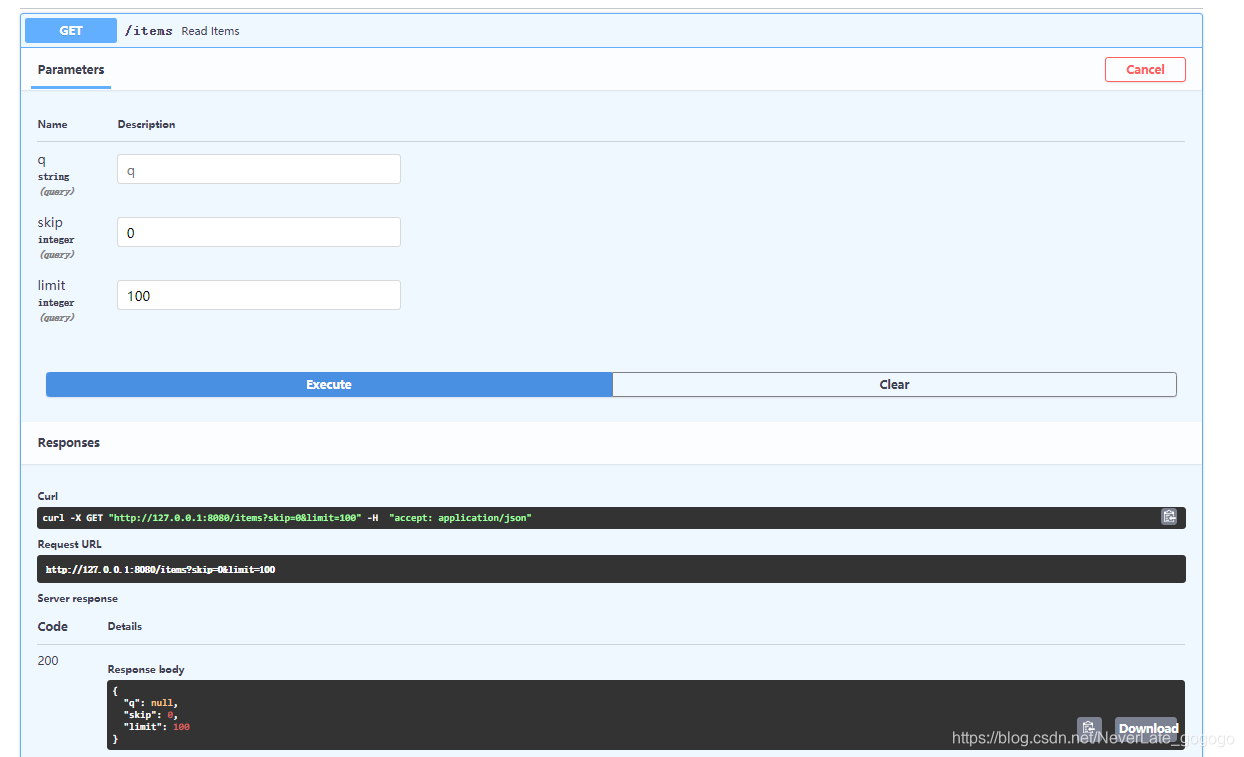
但是,从后台使用common时,common就时一个CommonQueryParams的类型了。并且可以使用common.limit的这种属性访问形式访问元素了。
三、拓展
那么,大家有没有认真想过这句话, “的Depends可以接收任何的callable对象”。
为什么function和class都可以作为Depends参数,因为他们可以调用,即他们可以写成A()的形式。那么理论上,一个拥有__call__方法的对象也是可以传入Depends的。我们来试试。代码如下
import uvicorn
from fastapi import Depends, FastAPI
from typing import Optional
from pydantic import BaseModel
app = FastAPI()
class CombineWord:
def __init__(self, q: Optional[str] = None):
self.q = q
def __call__(self):
return self.q + "world"
@app.get("/items")
async def read_items(word=Depends(CombineWord(q="hello"))):
return word
if __name__ == '__main__':
uvicorn.run(app, host="0.0.0.0", port=8080, loop="asyncio")
运行起来后,我们从docs来访问,如下,运行成功,并且返回了要拼写的字符串。
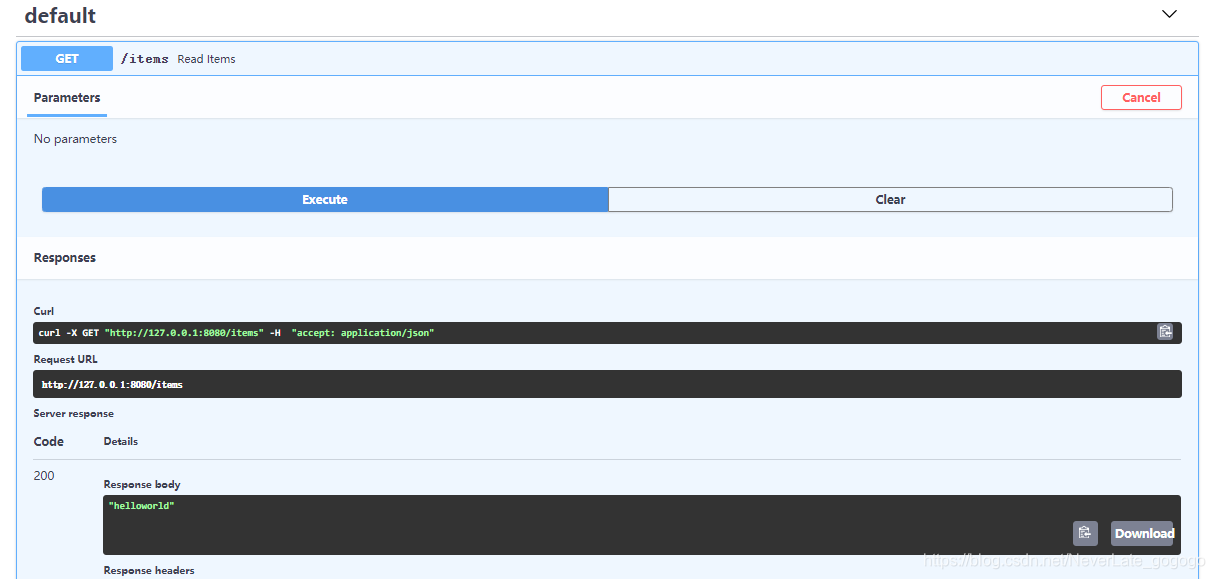
所以,大家可以根据自己的需要来给Depends传参,非常灵活。
四、实际项目中的应用-Depends(database_connection)
在实际项目中,后端开发时,用到的比较多的Depends比较多的是3个场景:
- Depends(current_user) 在路由函数中,经常需要知道当前的用户是谁,用一个def get_current_user()方法实现获取,然后Depends(current_user)
- Depends(database) 创建数据库session,特别常用,使用def connecton()获取数据库session,然后Depends(connection),看举例代码
- Depends(common_params) 有一些公共参数,可以提取出来,然后使用Depends(common_params)
1、Depends(databse)来获取数据库seesion
# db.py用于初始化数据库
# 执行db.init(config)
import logging
from urllib.parse import quote_plus
from sqlalchemy import create_engine
from sqlalchemy.orm import sessionmaker, scoped_session
context = {
"db_url": None,
"engine": None,
"smaker": None
}
scoped_context = {
"db_url": None,
"engine": None,
"smaker": None
}
logs = logging.getLogger("sqlalchemy")
def init(config):
db_url, engine, smaker = make_context(config)
logs.debug("try to crate all database objects")
Base.metadata.create_all(engine) # 创建所有数据表
context["db_url"] = db_url
context["engine"] = engine
context["smaker"] = smaker
scoped_context["db_url"] = db_url
scoped_context["engine"] = engine
scoped_context["smaker"] = scoped_session(smaker)
def make_context(c):
logs.debug("database config: %s", c)
db_url = make_url(c)
engine = create_engine(
db_url,
encoding=c.get("encoding" "utf8"),
echo=c.get("echo", False),
echo_pool=c.get("echo_pool", False),
pool_recycle=c.get("pool_recycle", 3600),
pool_size=c.get("(pool_size", 256)
)
smaker = sessionmaker(bind=engine, expire_on_commit=c.get("expire_on_commit", False))
logs.debug("create session maker")
return db_url, engine, smaker
def make_url(c):
protocol = c["protocol"]
username = c["username"]
password = c["password"]
password = quote_plus(password)
host = c["host"]
port = c["port"]
database = c["database"]
template = "{}://{}:{}@{}:{}/{}"
db_url = template.format(protocol, username, password, host, port, database)
url_tip = template.format(protocol, username, "XXXXXX", host, port, database)
logs.debug(f"create db engine to {url_tip}")
return db_url
def make_session(ctx=None, scoped=False):
c = ctx if ctx is not None else (scoped_context if scoped else context)
m = c["smaker"]
s = m()
return s
@contextlib.contextmanager
def session_context(ctx=None, scoped=False):
session = make_session(ctx, scoped)
try:
yield session
session.commit()
except Exception:
session.rollback()
raise
finally:
session.colse()
def connection():
with session_context() as session:
yield sessionimport uvicorn
from fastapi import Depends, FastAPI
app = FastAPI()
@app.get("/items")
async def read_items(database=Depends(connection)):
# 这里的connection就是一个mysql的session连接了
data = database.query("selext xxx from yyy")
return data
@app.get("/users")
async def read_items(database=Depends(connection)):
# 这里的connection就是一个mysql的session连接了
data = database.query("selext xxx from user")
return data
if __name__ == '__main__':
uvicorn.run(app, host="0.0.0.0", port=8080, loop="asyncio")
每次需要使用数据库操作时,就很方便了。
2、Depends(current_user) 以后再举例子吧

















 3087
3087

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









