






大语言模型可解释性研究概述
大语言模型(Large Language Models, LLMs)近年来取得了突破性进展,在自然语言处理的多个任务中展现出惊人的能力。然而,这些模型的内部工作机制仍然是一个"黑箱",难以解释其决策过程和推理逻辑。为了增进对LLMs的理解和控制,可解释性研究成为了一个重要的研究方向。
本文将从工具、论文和研究群体三个维度,全面梳理LLM可解释性研究的最新进展,为读者提供该领域的全景图。
LLM可解释性研究工具
可视化与分析工具
-
The Learning Interpretability Tool (LIT): 这是一个开源平台,用于机器学习模型的可视化和理解。它支持分类、回归和生成模型(文本和图像数据),包括显著性方法、注意力归因、反事实分析、TCAV、嵌入可视化等功能。
-
TransformerViz: 这是一个交互式工具,可以通过潜在空间来可视化Transformer模型。它能够帮助研究人员直观地了解模型内部的表征和计算过程。
-
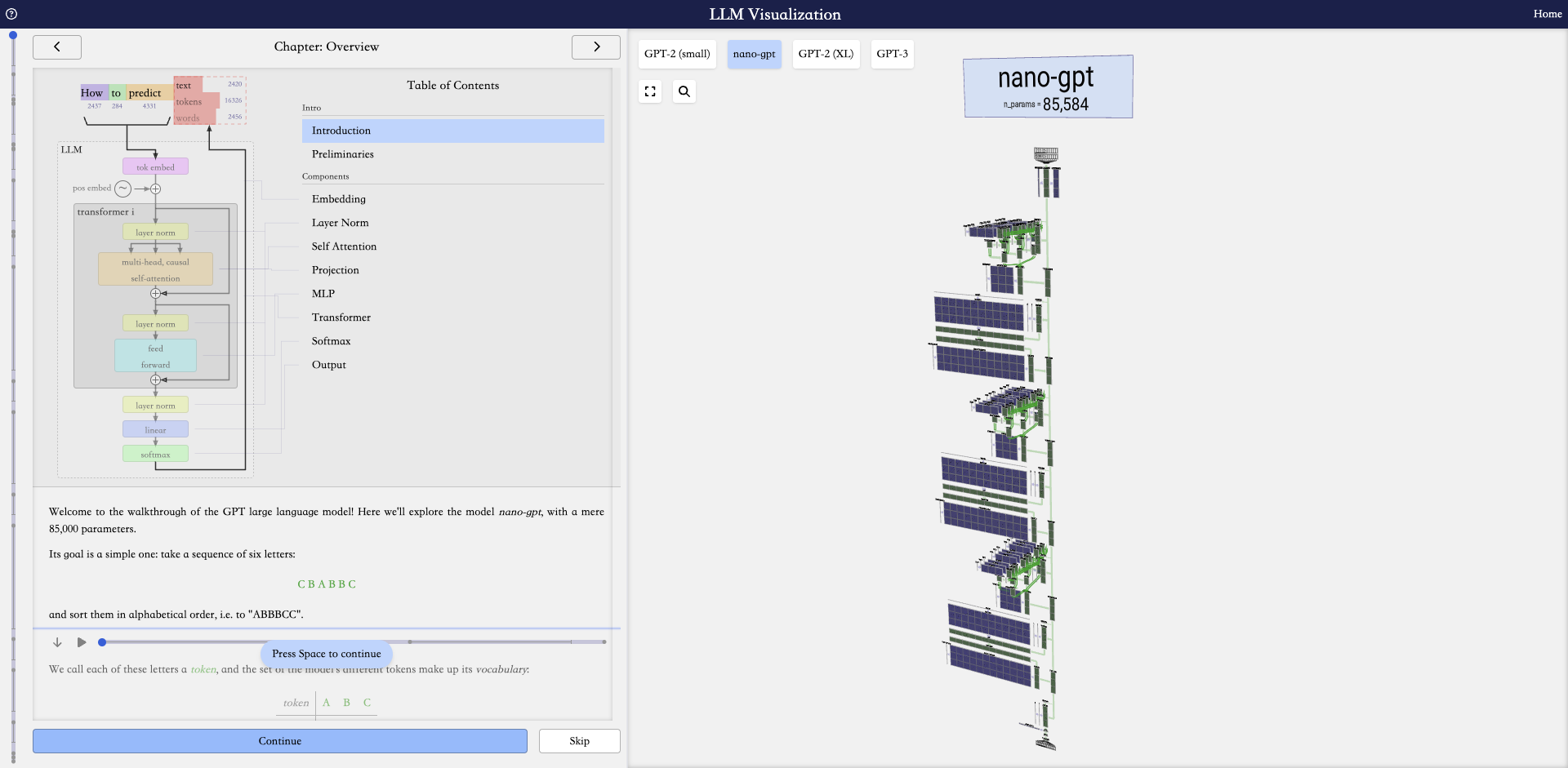
LLM Visualization: 该工具提供了LLMs底层工作原理的可视化,有助于理解模型的内部结构和信息流动。
解释和分析库
-
TransformerLens: 这是一个用于生成语言模型机制可解释性的库。它提供了一系列工具和方法,用于分析和解释Transformer模型的内部工作机制。
-
Inseq: 专注于序列生成模型的可解释性研究,提供了一套完整的工具和方法。
-
Automated Interpretability: 由OpenAI开发,这个库提供了自动生成、模拟和评分神经元行为解释的代码。
重要研究论文
-
Interpretability Illusions in the Generalization of Simplified Models: 这篇论文揭示了基于简化模型(如线性探测)的可解释性方法可能存在泛化错觉的问题。
-
Finding Neurons in a Haystack: Case Studies with Sparse Probing: 该研究探讨了在大语言模型的神经元激活中表示高级人类可解释特征的方法。
-
Language models can explain neurons in language models: 这项研究探索了如何使用GPT-4等语言模型来解释类似模型中神经元的功能。
-
Emergent Linear Representations in World Models of Self-Supervised Sequence Models: 该论文研究了在自监督序列模型的世界模型中出现的线性表示。
-
The Geometry of Truth: Emergent Linear Structure in Large Language Model Representations of True/False Datasets: 这项研究使用真/假数据集调查了大语言模型中真理的表示方式。
这些论文代表了LLM可解释性研究的不同方向,包括模型简化的局限性、神经元级别的解释、跨模型解释、表征学习以及特定概念(如真理)的表示研究等。
LLM可解释性研究群体
-
PAIR (People + AI Research): 这是Google的一个研究小组,致力于开发开源工具、交互式可视化和可解释性方法研究。
-
Alignment Lab AI: 这个研究组专注于AI对齐问题,其中包括可解释性研究。
-
EleutherAI: 这是一个非营利AI研究实验室,关注大型模型的可解释性和对齐问题。
-
Nous Research: 这个研究组讨论各种可解释性相关主题。
这些研究群体为LLM可解释性研究提供了重要的平台和资源,促进了学术界和工业界的交流与合作。
未来展望
随着LLMs在各个领域的广泛应用,可解释性研究将继续深入。未来的研究方向可能包括:
-
开发更精确和可靠的解释方法,减少解释中的偏差和错误。
-
探索跨模态的可解释性技术,以应对多模态LLMs的兴起。
-
研究LLMs的认知过程,包括推理、记忆和知识表示等方面。
-
将可解释性研究与模型安全、偏见缓解等领域结合,提高LLMs的可信度和公平性。
-
探索可解释性技术在模型优化和调试中的应用,促进LLMs的持续改进。
结语
LLM可解释性研究是一个快速发展的领域,对于理解和改进这些强大的AI系统至关重要。通过本文的梳理,我们看到了该领域的丰富工具、深入的研究论文和活跃的研究群体。未来,随着研究的深入和新技术的涌现,我们有望对LLMs的内部工作机制有更清晰的认识,从而开发出更可靠、更透明的AI系统。
项目链接:www.dongaigc.com/a/in-depth-analysis-on-llm-interpretability
https://www.dongaigc.com/a/in-depth-analysis-on-llm-interpretability

















 228
228

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









