




 本文介绍了聚类分析的基础知识,包括相似性度量和类间相似性度量的方法,如Minkowski距离、马氏距离、最短距离法等。通过实例展示了如何计算样本和类间的距离,强调了数据标准化和处理多重相关性的重要性。最后,讨论了系统聚类法及其在构建聚类图中的应用。
本文介绍了聚类分析的基础知识,包括相似性度量和类间相似性度量的方法,如Minkowski距离、马氏距离、最短距离法等。通过实例展示了如何计算样本和类间的距离,强调了数据标准化和处理多重相关性的重要性。最后,讨论了系统聚类法及其在构建聚类图中的应用。
文章目录
一、聚类分析
1. 概述
- 聚类分析(cluster analyses)可作为一种定量方法,从数据分析的角度,给出一个准确、细致的分类工具。
2. 相似性度量
2.1. 样本的相似性度量
1. 重点内容
- 核心思想:用距离来度量样本点间的相似程度。距离近的样品聚为一类。
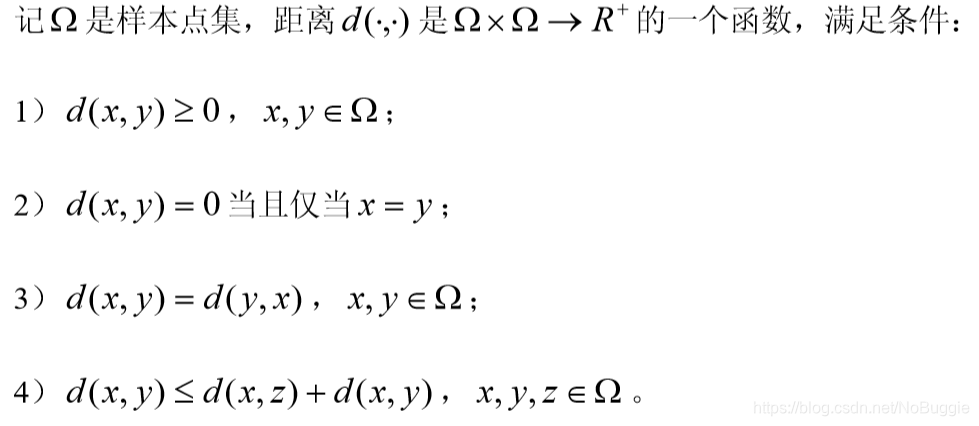
- 在聚类分析中,对于定量变量,常用的是 Minkowski 距离
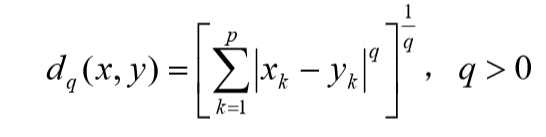

- 在 Minkowski 距离中,常用的是欧氏距离,它的主要优点是当坐标轴进行正交旋转时,欧氏距离是保持不变的。因此,如果对原坐标系进行平移和旋转变换,则变换后样本点间的距离和变换前完全相同。
- 采用 Minkowski 距离时,一定要采用相同量纲的变量。如果变量的量纲不同,测量值变异范围相差悬殊时,建议首先进行数据的标准化处理,然后再计算距离。
- 在采用 Minkowski 距离时,还应尽可能地避免变量的多重相关性。多重相关性(multicollinearity)所造成的信息重叠,会片面强调某些变量的重要性。
- 由于 Minkowski 距离的这些缺点,一种改进的距离就是马氏距离,定义如下:
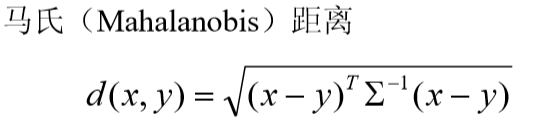
其中x, y为来自p 维总体Z的样本观测值,Σ为Z的协方差矩阵,实际中Σ往往是不知道的,常常需要用样本协方差来估计。马氏距离对一切线性变换是不变的,故不受量纲的影响。 - 此外,还可采用样本相关系数、夹角余弦和其它关联性度量作为相似性度量。
2. 示例
下
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















——聚类分析&spm=1001.2101.3001.5002&articleId=103206892&d=1&t=3&u=d211ce3a3ebe41e78b0ad6b64655cc24)
 2011
2011

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











