






1.聚类分析及py分类
系统聚类:将n个样品分为n类,先计算样本之间的距离。每次将距离最近的点合并到同一个类。然后,再计算类与类之间的距离,将距离最近的类合并为一个大类。不停的合并,直到合成了一个类。
方法步骤
- 初始状态:将每个样本视为一个独立的类,计算所有样本之间的距离,形成一个距离矩阵。
- 合并过程:找到距离矩阵中距离最小的两个类,将它们合并为一个新类,并更新距离矩阵。
- 重复合并:重复上述步骤,直到达到聚类数目1。
K均值聚类法(K-means)通过迭代优化将样本分配到K个预定的类中,使得每个类内的样本尽可能相似,而类间的样本尽可能不同。其核心思想是最小化类内平方误差,类相似度是类中对像的均值。
方法步骤
- 选择初始中心:随机选择K个样本作为初始聚类中心。
- 分配样本:将每个样本分配到距离最近的聚类中心。
- 更新中心:重新计算每个类的中心,即类内样本的均值。
- 重复迭代:重复步骤2和3,直到聚类中心不再变化或达到最大迭代次数
1.1聚类分析的类型
通过根据对象的不同分为 Q型聚类:对样品的聚类 和 R型聚类:对变量的聚类
1.2距离计算
(1)明式距离:
- 当q=1时,就是曼哈顿距离
- 当q=2时,就是欧氏距离
- 当q→∞时,就是切比雪夫距离
(2)马氏距离(曼哈顿距离):
优点:排除各个指标的相干性干扰,消除个指标量纲。
缺点:样品的协方差聚类过程中不变假设不合理
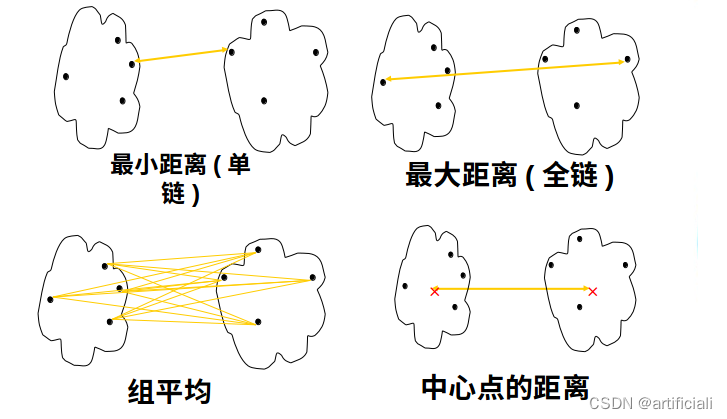
1.3定义类与类之间的距离
1最短距离法:两个类,选距离相互最近的点对
2最长距离法:两个类,选距离相互最长的点对
3中间距离法
4类平均距离法:两个类,元素两两之间的平均算法
5重心法:类用他的重新(该类的均值)做代表,类与类之间的距离用重心衡量
6距离平方和法:将n给样品格子一类,选择使离差平方和增大最小的两类合并,直到全部一类。
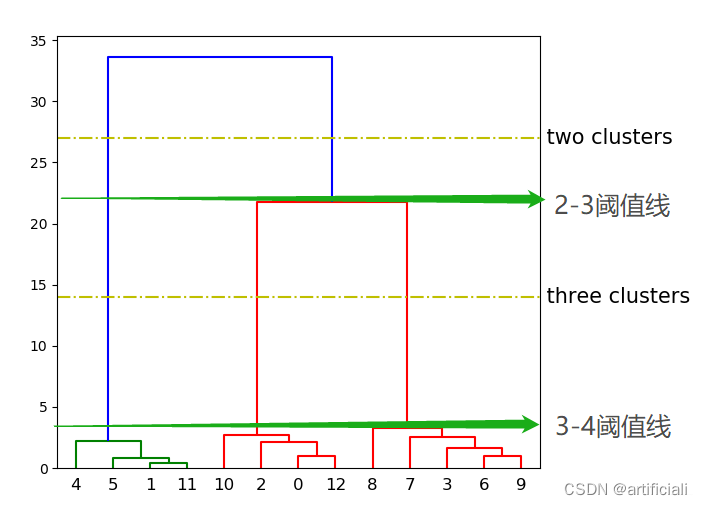
1.4谱系图
树状图中,横坐标为类的数量,纵坐标为距离,一般取距离(纵坐标)宽度大的情况所对应的类的数目,此时聚类结果更稳定。如下图所示,水平线与树状图中的垂直线有几个交点就表示此时是分几类的结果,本图可以看到2类和3类的水平线,通过分析可知3类的结果更稳定,因为从3类可以在最大的距离宽度下存在。
推荐:系统聚类思想及其Python实现 - 郝hai - 博客园 (cnblogs.com)
2.综合评价及py应用
2.1评价指标权重确定方法
评价指标权重:在评价指标体系中每个指标的重要程度。
2.2层次分析法确定权重
(1)层次分析法原理
思路:建立评价对象的综合评价指标体系,通过指标之间的两两比较确定各自的相对重要程度。
(2)层次分析法权重的计算
首先分析法的应用首先需要确定各个层次的目标体系,就是根据研究目标之间的内在联系和因果联系,将目标层次逐步分解为多层次的目标体系。
一.构造判断矩阵
二.判断标准
,A是一个正交矩阵,只需要做m(m-1)/2次比较。
三.对各个权属进行计算
(3)对判断矩阵进行一致性检验。
一.计算判断矩阵的最大特征根
二.计算判断阵一致指标 :
三.计算判断矩阵得随机一致性比率:
RI:判断矩阵的随机一致性标准,其值取决于评价指标个数的多少(m)
CR<0.1满足判断矩阵一致性要求,所求的综合评价权数是合适的
3.PCA
PCA 的核心思想是通过线性变换将 高维数据映射到低维空间中,使得映射后的数据能够尽可能地保留原始数据的信息,同时去除噪 声和冗余信息,从而更好地描述数据的本质特征。
1.在第一步中,我们先标准化 (standardization) 原始数据。标准 化防止不同特征上方差差异过大,计算原始数据 Xn × D的协方差矩阵 ΣD × D;
2.对 Σ 特征值分解,获得特征值 λi与特征向量矩阵 VD × D;
3.对特征值 λi从大到小排序,选择其中特征值最大的 p 个特征向量;
4.将原始数据 (中心化数据) 投影到这 p 个正交向量构建的低维空间中,获得得分 Zn × p。
应用
- 数据降维:减少数据维度,保留主要信息。
- 数据可视化:将高维数据投影到二维或三维空间中进行可视化。
- 噪声过滤:去除数据中的噪声,保留主要信号。
4.因子分析
基本思想
因子分析是一种多变量统计分析方法,通过少数几个因子来解释大部分变量的方差。因子分析假设观测变量可以由少数几个潜在因子线性组合而成,这些潜在因子称为公共因子,将相关性较高的分在同一类中,每一类代表一个基本结构,用少数不可测的公共因子函数来描述原观测分量的每一部分。
方法步骤
- 标准化数据:将数据标准化,使每个变量的均值为0,方差为1。
- 计算相关矩阵:计算标准化数据的相关矩阵。
- kmo检验统计量,比较变量间相关系数和偏相关系数的指标,越接近1,相关性越强,适合因子分析;Bartlett球检验,检验相关矩阵是否是单位矩阵,如果是单位不适合,拒接原假设
- 提取因子:使用主成分法或最大似然法提取因子,通常选择特征值大于1的因子。
- 因子旋转:对提取的因子进行旋转(如正交旋转或斜交旋转),使因子具有更好的解释性。
- 计算因子得分:计算每个样本的因子得分,用于后续分析。
应用
- 数据降维:减少数据维度,保留主要信息。
- 结构探索:探索数据中的潜在结构,识别潜在因子。
- 问卷分析:分析问卷数据,识别潜在的测量维度。
假设:
(1)m<=p 变量数<=方程数
(2)
(3),F2……Fm不相关且方差均为1
,不相关且方差均不同
与PCA比较
相同点
- 都是降维技术,旨在减少数据维度,保留主要信息。
- 都需要对数据进行标准化处理。
- 都涉及特征值分解和特征向量计算。
不同点
- 目标不同:PCA的目标是解释数据的总方差,而FA的目标是解释变量之间的协方差。
- 模型假设不同:PCA假设主成分是原始变量的线性组合,而FA假设观测变量是潜在因子的线性组合。
- 因子旋转:FA通常需要进行因子旋转以提高解释性,而PCA不需要。
- 应用场景不同:PCA更适用于数据降维和可视化,而FA更适用于结构探索和问卷分析。
因子载荷矩阵中的每个元素都可以看作是变量与因子之间的相关性度量。
共同度:越大表示x的第i个分量对于每一份F1……Fm的共同依赖程度越大
方差贡献率:第j列的各个元素平方和,衡量公共因子的重要指标
5.对应分析
对应分析是把R型(变量)因子分析 和 Q型(样品) 因子分析 统一起来,通过R型得到Q型的结 果,同时把Q和R型反应到一张坐标轴上面。
作用:分析两组或多组因素之间的关系
对应分析是列联表分析方法, 考察把行类别和列类别分组降维后, 行、列之间的关系。
步骤1:判断元素之间有无联系或是否独立。如果不独立可以进一步通过对应分析考察两因素各个水平之间的相关关系。使用卡方检验
卡方值越高,表示观测频率和预期频率之间的差异越大,表明变量之间的关联越强该值是观测到的频率与预期频率偏差程度的度量。 p 值有助于确定卡方值的显著性。非常小的 p 值(通常小于 0.05)表示观察到的差异不太可能偶然发生,这表明变量之间存在显着关联,这意味着变量之间的关联非常显著。
- 原假设 (H₀):两个分类变量之间没有关联。
- 备择假设 (H₁):两个分类变量之间存在关联。
如果值大,且p<0.05,所以拒绝原假设H₀,认为因素A和因素B不独立,即有密切联系可以进一步作对应分析。
步骤2:数据矩阵计算规格化的概率矩阵
步骤3:计算过度矩阵
步骤4:进行R型因子分析
步骤5:进行Q型因子分析

#!pip install prince
#%%
d81=pd.read_excel('Data.xlsx',index_col=0);
from scipy import stats
chi2=stats.chi2_contingency(d81) #列联表卡方检验
print('卡方值=%.4f, P值=%.4g'%(chi2[0],chi2[1]))
print('\n理论频数:\n',chi2[3].round(2))
#%%
pd.set_option('display.precision',3) #设置数据框输出精度
from prince import CA #对应分析
ca1=CA().fit(d81)
#%%
F=ca1.row_coordinates(d81) #行坐标 坐标
print(F)
#%%
G=ca1.column_coordinates(d81) #列坐标 坐标
print(G)
#%%
def CA_plot(ca,df): #作对应分析图,替代price的plot_coordinates函数
import matplotlib.pyplot as plt #加载基本绘图包
plt.rcParams['font.sans-serif']=['SimHei']; #设置中文字体为黑体
plt.rcParams['axes.unicode_minus']=False; #正常显示图中正负号
ca_plot=pd.concat([ca.row_coordinates(df), ca.column_coordinates(df)])
ca_plot['label']=ca_plot.index
Vi=ca.eigenvalues_; Wi=100*Vi/ca.total_inertia_
fig, ax = plt.subplots(figsize=(6,5.5))
ax.scatter(x=ca_plot[0],y=ca_plot[1])
ax.set_xlabel('Component 0 (' + str(round(Wi[0],2))+str('% inertia)'));
ax.set_ylabel('Component 1 (' + str(round(Wi[1],2))+str('% inertia)'));
plt.axvline(x=0,linestyle=':');plt.axhline(y=0,linestyle=':')
for idx, row in ca_plot.iterrows(): ax.annotate(row['label'], (row[0], row[1]) )
import numpy as np
return(pd.DataFrame({'特征值':Vi,'贡献率%':Wi,'累计贡献%':np.cumsum(Wi)}))
#%%
CA_plot(ca1,d81)6.相关与回归
6.1两个假设检验
样本线性相关系数(pearson)
(1)相关系数假设检验
r也有抽样误差。从同一总体内抽取若干大小相同的样本,各样本的相关系数总有波动。要判断不等于0的r值是来自总体相关系数的总体还是来自
的总体,必须进行显著性检验.t检验。
原假设 𝐻0:总体相关系数 𝜌=0
备择假设 H1:总体相关系数 𝜌≠0
显著性水平 α=0.05
- 原假设 𝐻0:假设总体相关系数 𝜌 为 0,即样本之间没有线性关系。
- 备择假设 𝐻1:假设总体相关系数 𝜌 不为 0,即样本之间存在线性关系。
- 显著性水平 𝛼:通常设定为 0.05,表示在 5% 的显著性水平下进行检验。
通过计算 t 值并与临界值进行比较,可以判断是否拒绝原假设。如果计算得到的 t 值大于临界值,则拒绝原假设,认为样本之间存在显著的线性关系。
- t 值用于检验样本相关系数𝜌是否显著不同于零。较大的 t 值表明样本相关系数显著不同于零。
- p 值是通过 t 值计算得到的概率值,表示在原假设为真的情况下,观察到当前样本相关系数或更极端值的概率。在这个例子中,p 值<0.05,表示在原假设(总体相关系数为零)为真的情况下,观察到样本相关系数为 0.959 或更极端值的概率非常低。
- p 值用于判断是否拒绝原假设。如果 p 值小于显著性水平(通常为 0.05),则拒绝原假设,认为样本之间存在显著的线性关系。
- t 值 :用于计算 p 值的中间步骤,表示样本相关系数的显著性。
- p 值:用于判断是否拒绝原假设,表示在原假设为真的情况下,观察到当前样本相关系数或更极端值的概率。
如果p 值,远小于 0.05,因此可以在显著性水平α=0.05 下拒绝原假设 𝐻0,认为变量和变量呈现线性关系。
注意:相关系数显著性与样本来量有关。
(2)回归系数的假设检验:
抽样出现误差,样本回顾系数可能不会恰好等于总体回归的系数。如果总体回归的系数为0,那么(因变量的估计值)是常数,无论自变量的实际值x如何变化都无影响。所以要检验,当总体回归的系数为0,样本回归系数b服从正态分布,t检验。
如果p 值,远小于 0.05,因此可以在显著性水平α=0.05 下拒绝原假设 𝐻0,认为回归系数有统计学意义,x和y间存在线性回归关系。
6.2多元线性回归模型
基本假设前提:
1.解释变量一般非随机
2.
3误差服从正态分布的假定:
4.n>p 样本容量>变量个数
(1)多元线性回归模型检验
1.模型的方差分析F检验
原假设(H0)
原假设是所有回归系数(除了截距项)都等于零,即模型没有解释能力。形式上表示为:
𝐻0:𝛽1=𝛽2=⋯=𝛽𝑝=0
说明y和所有x都没有回归关系,方程无意义。
备择假设(H1)
备择假设是至少有一个回归系数不等于零,即模型具有解释能力。
如果通过方差分析计算的F值大于临界值,或者p值小于显著性水平(如0.05),则拒绝原假设,认为模型显著。
2.系数t检验 差不多同上6.1
多元回归方程有统计意义不代表每一项偏回归系数都有意义,所以对每个偏回归系数作检验。
7.典型相关性分析
思想: 典型相关分析(Canonical Correlation Analysis)是研究两组变量之间相关关系的一种多元统计方法。他能够揭示出两组变量之间的内在联系。
我们知道,在一元统计分析中,用相关系数来衡量两个随机变量的线性相关关系,用复相关系数研究一个随机变量与多个随机变量的线性相关关系。然而,这些方法均无法用于研究两组变量之间的相关关系,于是提出了CCA。其基本思想和主成分分析非常相似。首先,在每组变量中寻找出变量的线性组合,使得两组的线性组合之间具有最大的相关系数;然后选取和已经挑选出的这对线性组合不相关的另一对线性组合,并使其相关系数最大,如此下去,直到两组变量的相关性被提取完毕为止。被选出的线性组合配对称为典型变量,它们的相关系数称为典型相关系数。
步骤1:计算典型相关系数
步骤2:数典型相关系检验
步骤3:计算典型相关变量
8.扩展线性模型
9.判别分析
判别分析:分类规则。
两群体Fisher线性判别分析
多群体Fisher线性判别分析
分类分析:分类结果。
两群体Fisher分类
两群体贝叶斯分类
多群体分类
9.1定义和应用
对于银行来说,最重要的是判断申请者是否能够成功还款,即将申请者分到下面两类中的一类:“能成功偿还贷款” 和“不能偿还贷款”,这个任务包含了两个步骤:
1. 判别分析 (Discriminate analysis):利用历史数据,通过这两类人的一些有区别的特征(如年龄、收入等),找到一个“最优的” 规则区分这两类人
2. 分类分析 (Classification analysis):根据新申请人的特征,将该申请人分到可能的一类中
判别分析 在寻找一种“分类规则”:利用变量的函数(判别函数)来描述或者解释两组或多组群体之间的区别。分类分析 则更偏向于给出“分类结果”:预测一个新观测对象的类别或者说是将其分配到一个类别,利用一些规则(分类函数)评估新观测对象的测量值向量,找到该对象最有可能属于的类别。
判别分析和分类分析的目标经常充当,特别是判别分析的最终目的通常是分类。判别分析和分类分析中,所有个体都有既定标签,即有“标准答案”,可供监督,故其属于有监督学习(有监督学习 (Supervised learning)
9.2两群体Fisher线性判别分析
假设:两个群体的均值向量不等,但具有相同的协方差矩阵
用来寻找两个群体间“最好”的线性组合法则,来最大限度地区分两个群体
9.2.1两群体Fisher分类
判别分析旨在寻找一种的分类规则,而分类分析更进一步:将新的观察对象分到一个合适的类别——即在分析过程中进行的预测部分。
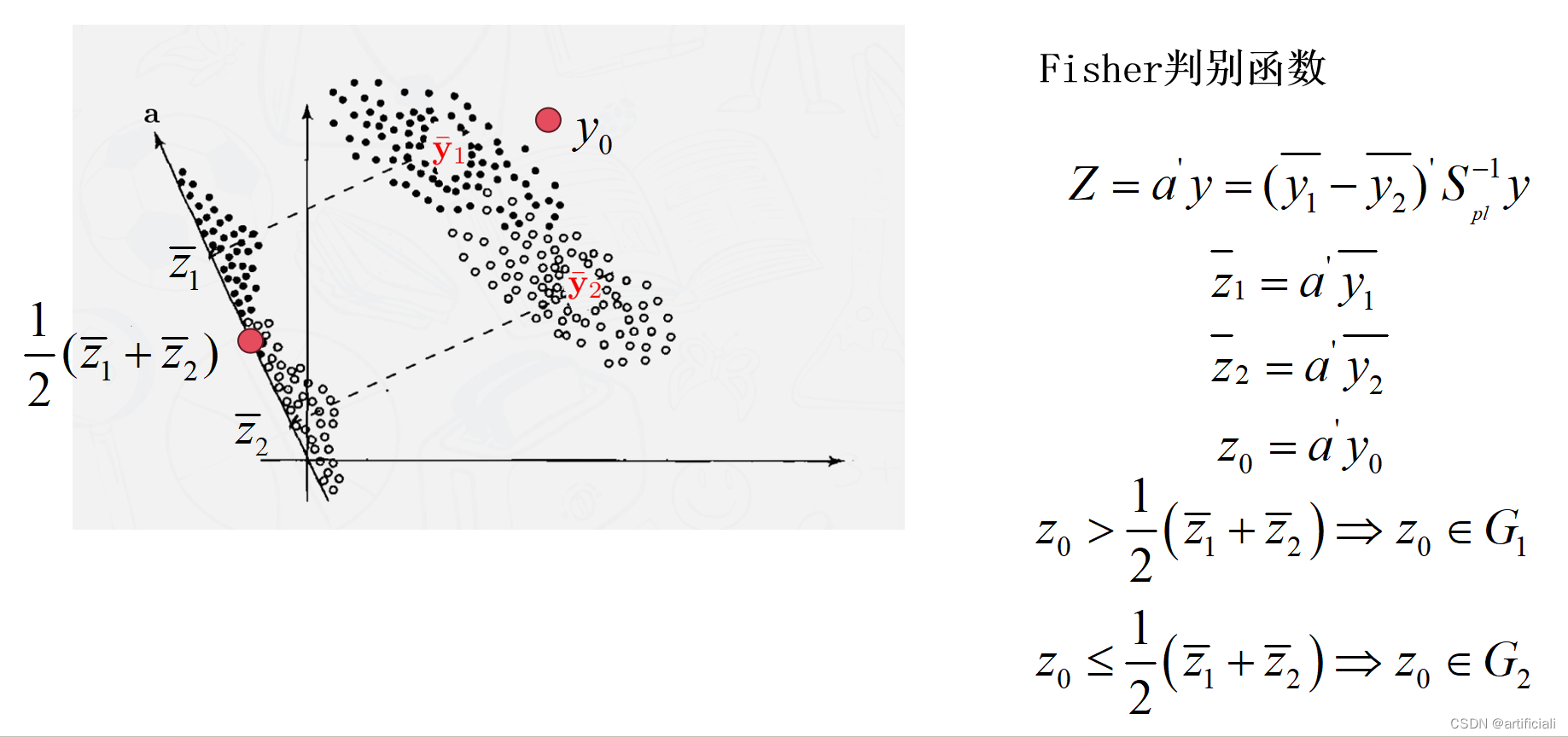
判别公式
假设:两个群体有相同的协方差 ,并且n1+n2-2>p
9.2.2两群体贝叶斯分类
区别:Fisher判别没有考虑先验信息,bayes判别有考虑先验信息
通常,一家公司陷入财务困境并最终破产的(先验)概率很小,所以我们应该首先默认一家随机选择的公司不会破产,除非数据压倒性地支持公司将会破产这一事件。所以这时事件发生的先验概率 (Prior probability)应该被考虑在内。
考虑误判的代价:
没有诊断出绝症的“代价”明显大于将病人误诊为绝症,所以这时误判代价 (Misclassification cost)应该被考虑在内。
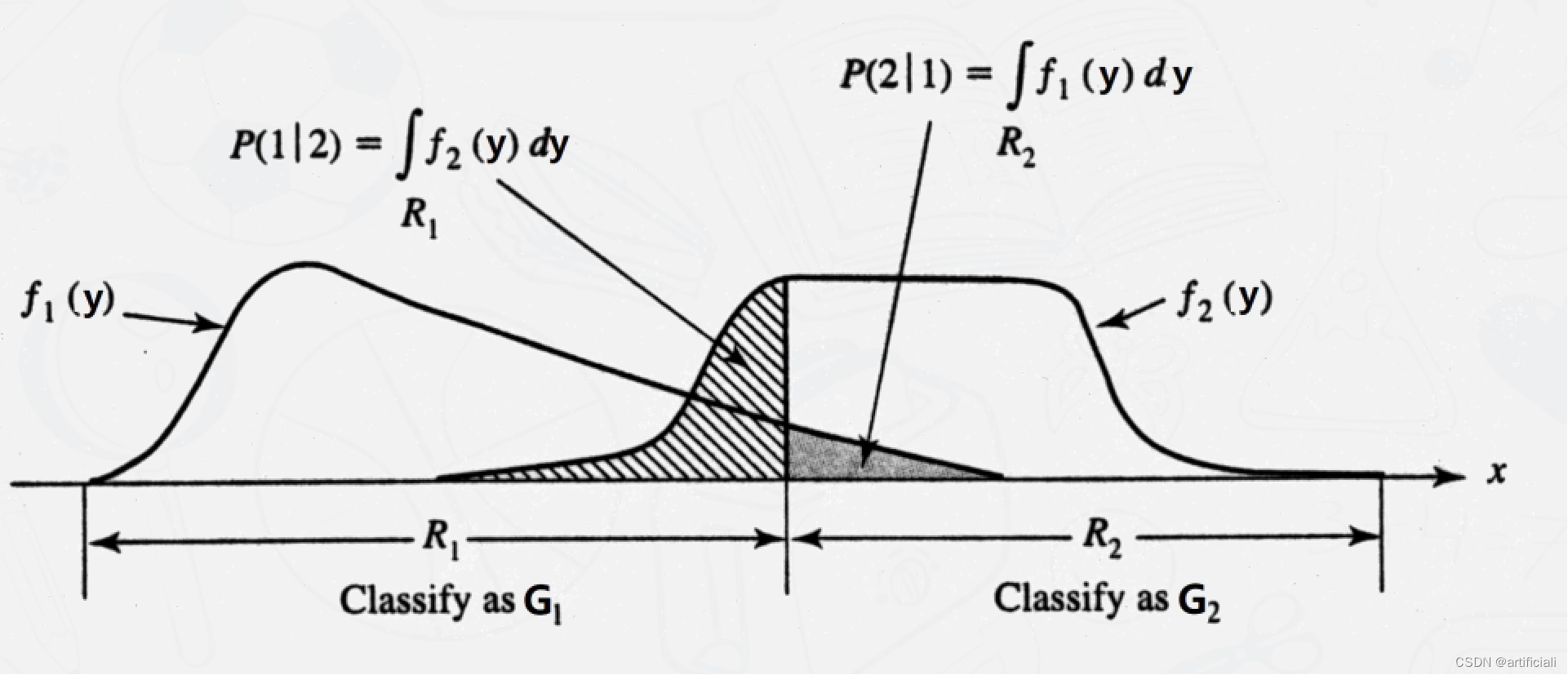
G1和G2代表两个总体,各自的先验概率为p,和P2(P1+p2=1)。
f1(y)和f2(y)分别是总体G1和G2中Y的概率密度函数。
R1和R2,代表按分类规则划分的两组区域。
例如,如果一个新观测对象分到Rk,那么我们声明该样本来自总体Gk,K=1,2.R1和R2是整个空间的分割。
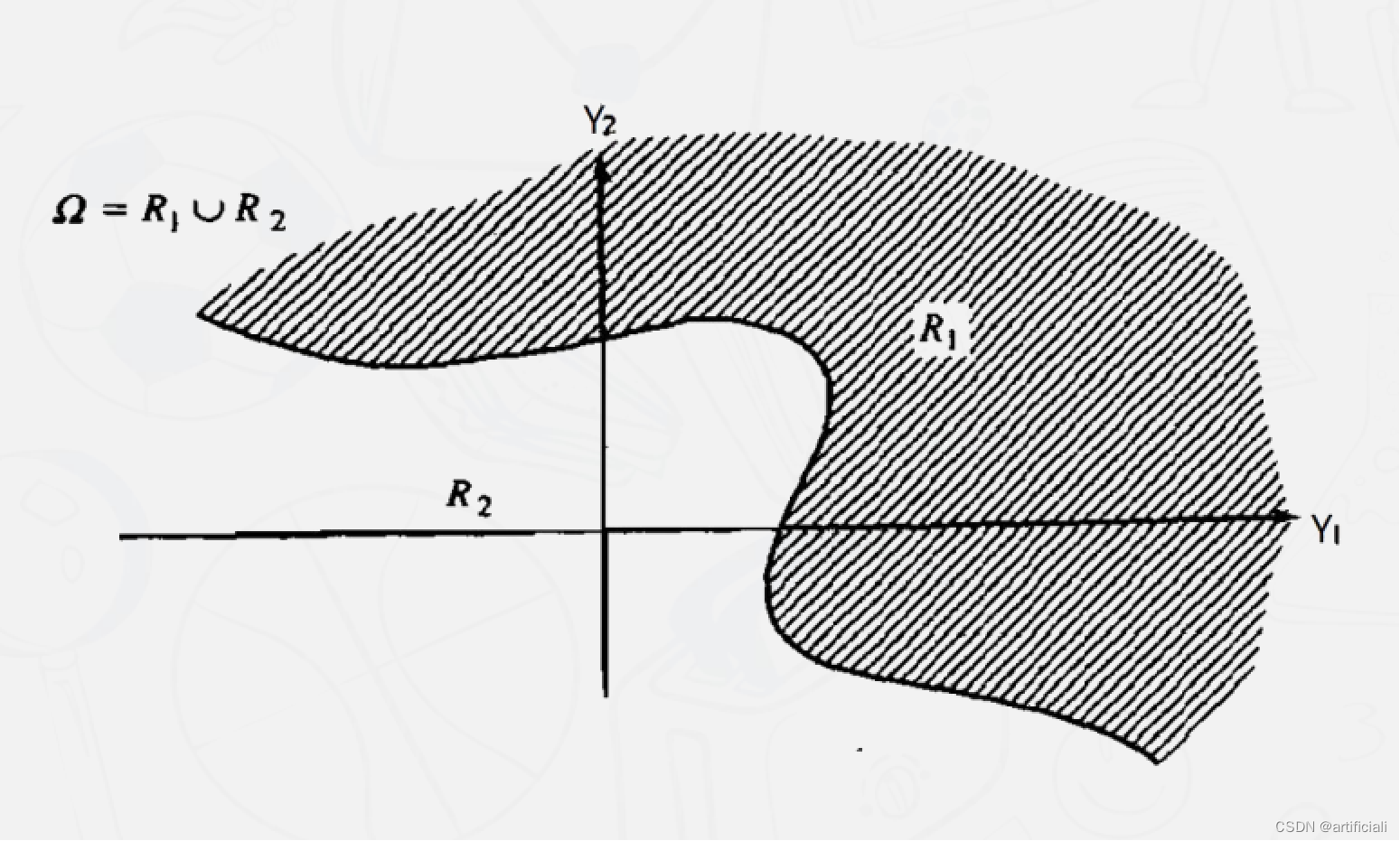
P(1/2)“是我们将样本y分为G1(y∈R1)然而实际上它来自G2的条件概率。
推导总错分率为(TPM):
P ( 属 于 G2 观 测 对 象 被 错 分 到 G1) =
p(G2)是先验概率
贝叶斯分类法则目标是最小化错分的期望代价(Expected cost of misclassification, ECM):
定理贝叶斯分类法则:
基于最小化ECM的贝叶斯分类法则为:
其中:
- 𝑓1(𝑦)和 𝑓2(𝑦)分别是类别1和类别2的条件概率密度函数。
- 错分成本:c(1|2)为将来来自总体G2,观测对象被错分到G1,的代价/成本(cost)
- 𝑐(1∣2)是将实际属于类别2的样本误分类为类别1的代价。
- 𝑐(2∣1)是将实际属于类别1的样本误分类为类别2的代价。
- 𝑝1和 𝑝2分别是类别1和类别2的先验概率。
不同情况下的错分成本:
(a)p2/p1=1(先验概率相同)
(b)c(1|2)/c(2|1)=1(错分成本相同)
(c)或
也就是一般情况:
当时,先验概率和错分成本的比值相等。
或即先验概率的比值是错分成本比值的倒数。
具体解释
- 公式 𝑅1 和 𝑅2:
- 这些公式表示在给定观测值 𝑦的情况下,如何根据条件概率密度函数和错分成本来决定样本属于哪个类别。
- 例如,公式 𝑅1表示如果 𝑓1(𝑦)/𝑓2(𝑦)大于等于某个阈值,则样本被分类为类别1。
- 错分成本的影响:
- 错分成本 𝑐(1∣2)和 𝑐(2∣1)影响分类决策的阈值。
- 如果错分成本相同,则分类决策仅依赖于条件概率密度函数和先验概率。
- 如果错分成本不同,则需要调整阈值以最小化总的分类错误代价。

















 1176
1176

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









