









朋友之间也是。能够包容你偶尔不理智不成熟的一面的朋友一定是你最宝贵的朋友,愿意陪你幼稚,愿意在面对问题的时候,站在你这边,和你一起想办法,这些都是太可贵的情谊了。
这些偏爱从来都不是人家该给你的,而是你真的运气很好,遇到了千金不换的朋友。
人总要长大的,但偶尔发现有人愿意把你当作小朋友一样去爱,是一种奢侈的幸福。
Dilated Convolution
Demo: https://github.com/ndrplz/dilation-tensorflow
Last Edited: Mar 25, 2019 9:23 AM
Tags: ASPP,CRF,Dialated Conv,HDC
论文地址: https://arxiv.org/pdf/1511.07122.pdf
HDC论文地址:https://arxiv.org/pdf/1702.08502.pdf
ASPP论文地址:https://arxiv.org/abs/1802.02611
Dilated Convolution中文版论文:点击
前言
图像分类任务采用的连续的Pooling和Subsampling层整合多尺度的内容信息,降低图像分辨率,以得到全局的预测输出。
在FCN中通过Pooling层增大感受野、缩小图像尺寸,然后通过Upsampling层来还原图像尺寸,但是这个过程中造成了精度的损失。为了减小这种精度的损失,理所当然想到的是去掉pooling层,然而这样就导致特征图感受野太小。
因此空洞卷积(Dilated Convolution)这种不改变原图片大小(分辨率不变),同时又能提高感受野的卷积方式应运而生。
介绍Dilated Convolution的Github项目。
上来先看一张原理图:
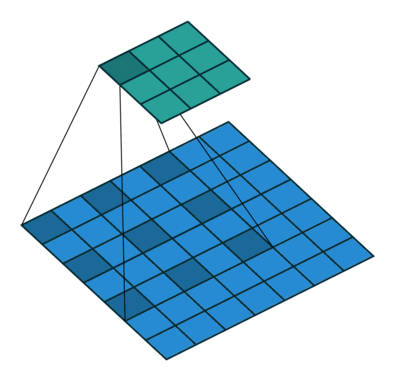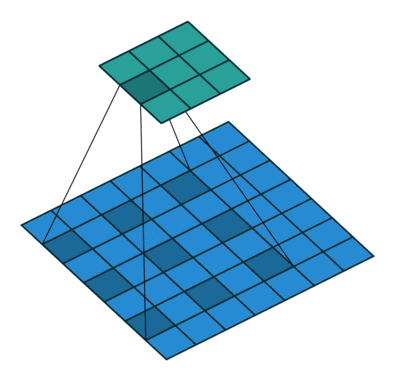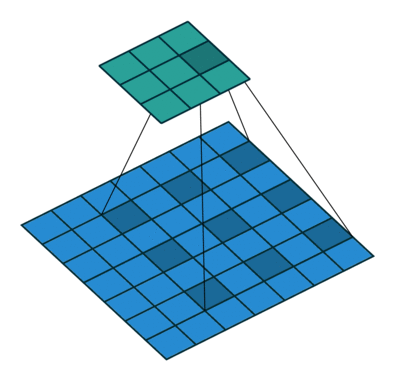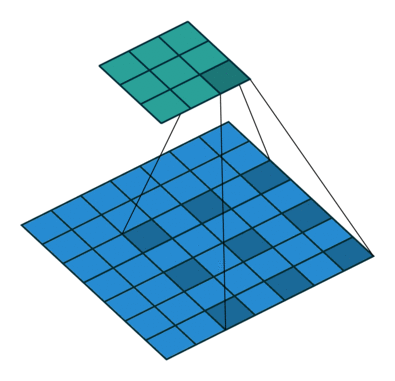
这个是Dilated Convolution的过程图。
原理

上图是三个空洞卷积的示例,分别是扩张率(Dilation Rate)为1,2,4。这里可以简单的通过红色点的间距计算扩张率,扩张率为=间距+1。

感受野(即上图中所有的绿色矩形区域部分)计算公式为:
F i + 1 = ( 2 i + 2 − 1 ) ( 2 i + 2 − 1 ) F_{i+1}=(2^{i+2}-1)(2^{i+2}-1) Fi+1=(2i+2−1)(2i+2−1)
通过该公式,我们可以快速的计算出(a)的感受野为3×3,(b)的感受野为7×7,(c)的感受野为15×15。
从这里我们可以发现,通过这种方式,各层的参数的数量是一致的,但其感受野却呈指数形式进行增长。这明显比使用传统(Conventional)的卷积(Convolution)更加容易提高我们获取图像特征信息的能力。因为传统的的卷积的感受野的计算公式为:
r e s u l t = ( k e r n e l − 1 ) × l a y e r + 1 result=(kernel-1)×layer+1 result=(kernel−1)×layer+1
从上述公式可以看出传统的卷积的感受野是线性增长的。如果要达到7×7的感受野,Dilated Convolution需要的是一个扩展率(Dilation Rate)为2的卷积核,传统的Convolution需要3层3×3的卷积核。
那是否会有什么缺点呢?(先继续看吧)

从上图蓝色圈中部分可以看出,(a)的核大小为3×3,(b)的核大小为5×5,(c)的核大小为9×9。
Multi-Scale Context Aggregation

为什么这里的感受野(Receptive Field)和上述公式计算不一致?
从上图Layer可以看出总共有8层,前7层卷积核大小为3x3,最后一层为1x1。
在前7层在卷积操作之后紧跟着一个逐元素截断(Point-wise Truncation)——max(⋅,0)。这里其实是采用了ReLU(/'relu:/)(Rectified Linear Unit)。
ϕ = m a x ( 0 , x ) \phi = max(0, x) ϕ=max(0,x)

特点:输入小于0,则输出结果为0;输入大于0则不变。
同时扩张率(Dilation Rate)从小到大,感受野从小到大,获取更多的特征。最终的输出是采用 1×1×C 的卷积操作得到的。
网络结构
本文设置了两种网络架构,一种是前端网络,另外一种是前端+上下文模块网络(如下图)。可见,后者包括了前者。

前端(front-end)
上图中fc-final之前的部分称为前端,之后的部分是上下文模块。前端用到的是VGG-16网络,不过将最后两个poooling层移除了,并且随后的卷积层被空洞卷积代替。pool3和pool4之间的空洞卷积的空洞率为2,在pool5之后的空洞卷积的空洞率为4。实际上,只需要前端而不需要前端之后的部分就能够进行稠密预测。下面是前端在VOC-2012数据集与FCN-8s,DeepLab,DeepLab-Msc方法的对比,从下面的表格中可以看出前端网络的效果都比其他几个方法都好。
作者发现前端模型比其它模型在稠密预测中精度更高,主要是归因于去除了那些对于分类网络来说是有效设计,但对密集预测算作残留成分(vestigial components)的部分。


Experiment
除了前端网络,这篇文章还提出了前端网络+上下文模块的网络,也就是上图【前端模块+上下文网络结构】所示的网络结构。当训练的时候,上下文模块接受来自前端网络的特征图作为输入。实验表明,上下文模块和前端模块联合训练精度并没有产生显著的改进,但是还是有提高的。作者又将前端网络+上下文模块与其它网络进行联合,分为三种网络结构,实验定量结果、实验定性结果如下图所示。


实验结果表明,上下文模块提高了三种配置中的每一种的准确性。 基本上下文模块(Front+Basic)提高了每种配置的准确性。 大型上下文模块(Front+Large)以更大的幅度提高准确性。 实验还表明,上下文模块和结构化预测是相互作用的:上下文模块在有或没有后续结构化预测的情况下都能提高准确性。
结论
-
(1)证明了扩展卷积适合用于密集预测,因为它能够在不损失分辨率的情况下扩大感受野,这一点表现在本文提到的前端模块中,因为前端模块是改进VGG16,再加上扩张卷积形成的,可以有效的进行密集预测。作者利用扩张卷积设计了一种新的网络结构,可以在插入现有的语义分割系统时可靠地提高准确性。这一点表现在前端模型+上下文网络结构,从实验中也可以看到前端网络+上下文模块与其它网络进行联合预测。
-
(2)通过实验还证明了,去除图像分类网络中的残余组件(vestigial components)可以提高现有卷积网络对语义分割的准确性。
缺陷
如果在一个网络中采用了几层的Dilated Convolution(比如上述例子),你就会发现一个问题——信息的获取是不连续的,并且有部分信息将会丢失。
The Gridding Effect
如果我们多次叠加扩展率(Dilation Rate)为2的3×3的Kernel的时候,就会出现下图的问题:

这里我们简单通过一张图来解释:

当我们N次卷积中采用递增的扩展率(Dilation Rate)[1,2,3,4,5]来卷积的时候,就会出现以上的问题,这将会使得从采样中的数据越来越稀疏,不利于卷积学习。
我们会发现我们的Kernel并不连续,即并非所有的元素(Pixel)都参与了卷积的过程。因此这种以棋盘(checker-board)分布处理数据的方式会损失信息的连续性(局部信息完全丢失,信息之间太远不相关)。这对Pixel-Level Dense Prediction的任务来说是致命的。
Dilated Convolution主要是设计于获取更大的视野(Long-ranged Information),然而光采用Dilation Rate或许对于一些大的物体分割有较好的效果,但是不利于小物体的分割。
如果能够适应物体的尺寸,那势必解决了上述的问题。
HDC
全称:Hybrid Dilated Convolution

| 图片 | 覆盖率 |
|---|---|
| 图(a) | 100% |
| 图(b) | (3×3)/(5×5)=36% |
| 图(c) | (3×3)/(9×9)=11% |

M
i
=
m
a
x
[
M
i
+
1
−
2
r
i
,
M
i
+
1
−
2
(
2
M
i
+
1
−
r
i
)
,
r
i
]
,
M
n
=
r
n
M_i=max[M_{i+1}-2r_i,M_{i+1}-2(2M_{i+1}-r_i),r_i], M_n=r_n
Mi=max[Mi+1−2ri,Mi+1−2(2Mi+1−ri),ri],Mn=rn
设计目标为:
M 2 ≤ K ( K 为 内 核 大 小 ) M_2\leq K(K为内核大小) M2≤K(K为内核大小)
例子
比如K=3,如果r=[1,2,5]则:
M 2 = m a x [ M 3 − 2 r 2 , − M 3 + 2 r 2 , r 2 ] = m a x [ 1 , − 1 , 2 ] = 2 M_2=max[M_3-2r_2,-M_3+2r_2,r_2]=max[1,-1,2]=2 M2=max[M3−2r2,−M3+2r2,r2]=max[1,−1,2]=2
此时:
M 2 = 2 ≤ K = 3 M_2=2\leq K=3 M2=2≤K=3
满足设计要求

如果r=[1,2,9],则:
M 2 = m a x [ M 3 − 2 r 2 , − M 3 + 2 r 2 , r 2 ] = m a x [ 5 , − 5 , 2 ] = 5 M_2=max[M_3-2r_2,-M_3+2r_2,r_2]=max[5,-5,2]=5 M2=max[M3−2r2,−M3+2r2,r2]=max[5,−5,2]=5
此时:
M 2 = 5 > K = 3 M_2=5>K=3 M2=5>K=3
不满足设计的要求。

效果对比

ASPP
全称:Atrous Spatial Pyramid Pooling (ASPP)
- 为什么要提出ASPP?
- 语义分割挑战:在多尺度上识别目标
- 解决思路:在给定的特征层上使用不同采样率的卷积进行重采样。
- 实施方法:使用不同采样率的空洞卷积并行采样。
在处理多尺度物体分割时,我们通常会有以下几种方式来操作:

然而仅仅(在一个卷积分支网络下)使用Dilated Convolution去抓取多尺度物体是一个不合适的方法。比方说,我们用一个HDC的方法来获取一个大(近)车辆的信息,然而对于一个小(远)车辆的信息都不再受用。假设我们再去用小Dilated Convolution的方法重新获取小车辆的信息,则这么做非常的冗余。

DeeplabV3+架构图,可以看到Encoder中使用了多重的空洞卷积(Dilated Convolution)模型
ASPP模块平行的使用不同扩张率的扩张卷积,执行空间金字塔合并获取多尺度信息。

基于港中文和商汤组的PSPNet里的Pooling Module(其网络同样获得当年的SOTA结果), ASPP则在网络Decoder上对于不同尺度上用不同大小的扩张率(Dilation Rate)来抓去多尺度信息,每个尺度则为一个独立的分支,在网络最后把他合并起来再接一个卷积层输出预测 label。这样的设计则有效避免了在Encoder上冗余的信息的获取,直接关注与物体之间之内的相关性。



可以查看实现的模型:【点击跳转】
附录
-
如何理解空洞卷积(dilated convolution)? - 知乎
- 详解了Dilated Convolution,包括了优化的过程。
-
CVPR 2017论文笔记- Dilated Residual Networks-云栖社区-阿里云
- Dilated Residual Networks
-
論文閱讀筆記二十:MULTI-SCALE CONTEXT AGGREGATION BY DILATED CONVOLUTIONS(ICRL2016) - IT閱讀
-
論文學習:Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation - IT閱讀
-
语义分割–Understand Convolution for Semantic Segmentation - DFan的NoteBook - CSDN博客















 154
154

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









