






在这个数据集datasets这个文件中包含了,测试集(test)、训练集(train)、验证集(valid)这三个集,在这里统称图像文件;另外还有data.yaml文件和一个classes.txt文件
这里先来看data.yaml文件
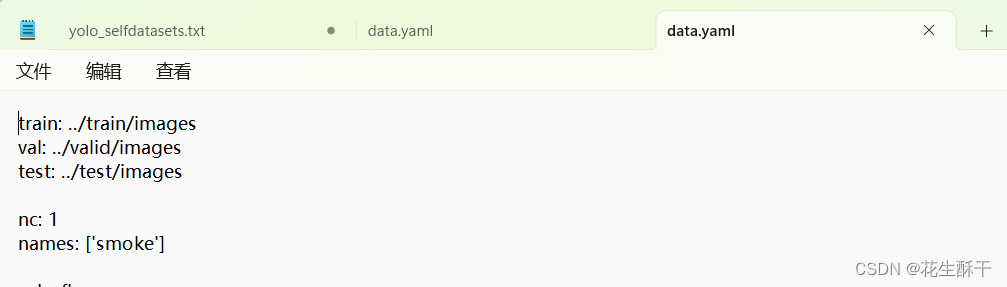
前三行标记了train、valid、test三个集的文件地址;
nc 代表要训练的数据类别个数(这里只有smoke,因此是1);
names 顾名思义
图像文件中的单个集中又可以分为:images文件(图像文件)和labels文件(标签文件)
随意查看其中一个标签文件:
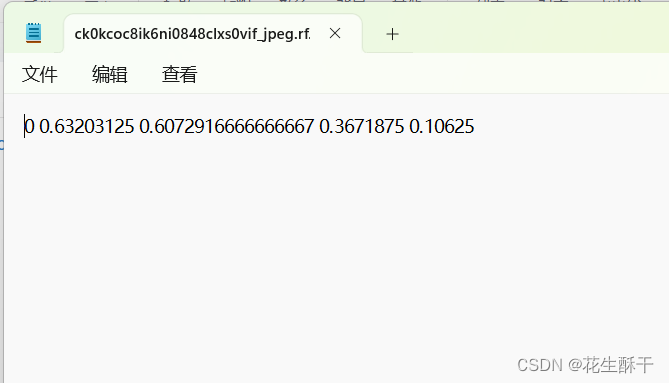
这五个数据又对应:
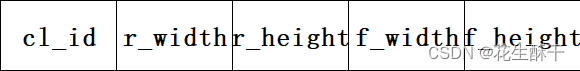
也就是:类别编号、相对宽度、相对高度、框宽度、框高度,除类别编号外,其他数据都进行了归一化处理,也就是数据在0~1之间(这种归一化处理,提高了算法性能、不会因为图像的不当处理大小影响对应类别位置、减少过拟合风险)
而这个txt格式的文件被称为类别文件,用来匹配对应的类别名称例如在本文中提到的数据集中只有一个类别:(这里的类别只有一个smoke)

这个模式其实就是这种:

是不是看起来不舒服,文件模型拘无定式,也可以是这种:(根据自己个人喜好)


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









