







Tri-training
半监督学习
之前提到的算法,多数都属于监督学习算法。其特点在于,构建一个包含标记数据的训练集,用来训练算法模型。
然而,获得标记数据是一个费时费力的高成本过程,实际工作中,更有可能的情况是:少量标记数据+大量未标记数据。
未标记数据的处理方式,一般有如下三种:
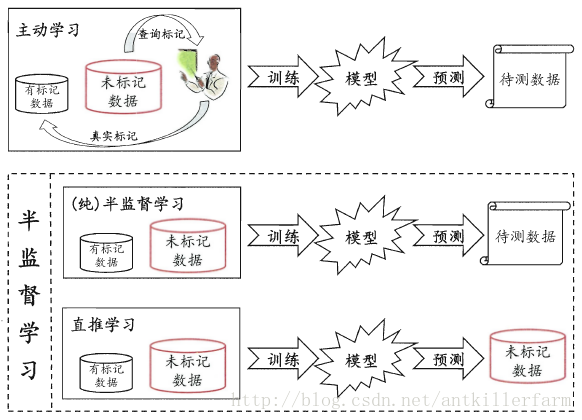
主动学习
1.根据标记数据生成一个简单的模型A。
2.挑出对改善模型性能帮助最大的样本数据B。
3.通过查询行业专家获得B的真实标记。
4.根据B的真实标记,更新模型A。
以SVM为例,对于改善模型性能帮助最大的样本往往是位于分类边界的样本,可将这些样本挑出来,查询它的标记。
纯半监督学习和推断学习
纯半监督学习和推断学习,都属于广义上的半监督学习。和主动学习不同,半监督学习无需专家提供的外部信息。
但标记数据总归不能无中生有,半监督学习的实现有赖于若干假设,其中主要有聚类假设和流形假设两种。其本质都是“相似的样本拥有相似的输出”。
纯半监督学习假定未标记数据为训练样本集,而推断学习则认为未标记数据为测试样本集。
虽然多数情况下,半监督学习能有效提升模型的泛化性能,然而这并不是绝对的。当半监督学习之后,模型的泛化性能反而下降时,我们首先需要检查数据是否满足算法所依赖的假
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1691
1691

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









