







这篇文章主要讲的是利用推特内容和股票历史价格推测股票走势。
Abstract
股票市场是随机的,预测是基于混沌的数据,本文提出一种深度生成网络–基于文本和价格信号,该模型介绍了recurrent,连续的潜在变量(continuous latent variable)来更好的处理随机性。然后利用神经变分推断(neural variational inference)来解决难以处理的后验推理,他们也提供带有时间辅助的混合目标函数,来灵活捕捉预测依赖。
1. Introduction
在NLP中,新闻和社交媒体是两大主要的信息资源,而他们对应的模型通常是有区别的(discriminative)。传统方法使用特征工程,而随着神经网络的出现,事件驱动的方法 和 结构化的事件 表示开始被研究起来。更有直接利用层次attention对新闻序列进行直接挖掘的。但股票预测还是很难,因为他被新闻时间随机影响着,从而导致一种随机游走(random-walk)的特征。相比于判别式(discriminative)模型,生成式(generative)模型在描绘从市场信息到股票信号的生成过程并引入随机性方面具有天然优势。然而,这些模型用词袋来代表混乱的社会文本,并使用简单的离散潜变量。本质上,股票走势预测是一个时间序列问题。 现有的 NLP 研究没有解决运动预测之间时间依赖性的重要性。例如,当一家公司遭遇重大丑闻时 d1 交易日,一般到 d2 日,其股价在接下来的交易日会出现下跌趋势,即 [d1, d2]。
如果股票预测器可以识别这种下降模式,则可能有利于 [d1, d2] 期间的所有走势预测。 否则,此区间的准确性可能会受到损害。 这种预测依赖性是公共信息的结果,例如 公司丑闻,需要随着时间的推移来被吸收(影响的滞后性?),而这种预测依赖性也很大程度上在时间很接近的预测中被共享。
旨在解决上述在高市场随机性、混乱市场信息和时间相关预测建模方面的突出研究空白, 本文提出StockNet, 一个深度生成模型。我们提出了一种具有变分架构的新型解码器,并为端到端训练推导出一个循环变分下界。
为了全面的探索市场信息,StockNet直接学习没有预-提取 结构化的事件的data。我们通过参考基本信息来建立市场资源,比如推特内容,科技特征,历史股价等。为了准确描述预测依赖性,我们假设股票的运动预测可以从学习在滞后窗口中预测其历史运动中受益。我们建议将交易日对齐作为框架基础(第 4 节),并进一步提供新的多任务学习目标(第 5.3 节)。
2. Problem formulating
我们的目标是在目标交易日 d 预测预选股票集合 S 中目标股票 s 的走势。我们使用由相关社交媒体组成的市场信息语料库 M, 比如推特、历史价格, 区间lag为[d- Δ \Delta Δd, d-1], 其中 Δ \Delta Δd是固定长度的lag。然后只有两种走势,1表示升,0表示降:
Y
=
1
(
P
d
c
>
P
d
−
1
c
)
Y=1(P_d^ c > P_{d-1}^ c)
Y=1(Pdc>Pd−1c)
其中
p
d
c
p_d^c
pdc表示针对影响股价的公司行为调整的调整后收盘价。调整后的收盘价被广泛用于预测股价 或金融波动。
3. Data Collection
金融里,股票被分为9类:
Basic Materials, Consumer Goods, Healthcare,
Services, Utilities, Conglomerates, Financial, Industrial Goods and Technolog
由于高交易量股票往往在 Twitter 上被更多地讨论,我们选择了 88 只股票从 2014 年 1 月 1 日到 2016 年 1 月 1 日的两年价格变动,这些股票来自Conglomerates (综合企业集团)的所有 8 只股票和 其他8个行业资本规模排名前10的股票。我们观察到有许多目标的移动比率非常小。 在三向股票趋势预测任务中,通过设置股价变化的上限和下限,将这些变动归为另一个“保留”类别。由于我们针对可从社交媒体识别的股票变化的二元分类,我们设置了两个特定的阈值,0.5%和0.55%,并且简单地移除掉了38.72%的移动百分比介于两个阈值之间的选择目标。移动百分比≤-0.5% 和 >0.55% 的样本分别标记为 0 和 1。选择两个阈值来平衡两个类别,从而在整个数据集中产生了 26,614 个预测目标,其中两个类别分别占 49.78% 和 50.22% 。对数据进行划分:从2014年1月1日到2015年8月1日的20339个数据(movements)用作training,2015年8月1到10月1的2555个数据用来validation,2015年10月1日到2016年1月1日的3720个数据用来Testing。
对于推特数据,他们使用了正则表达式来踢去股票相关的文本,具体怎么操作可以看文章,不再介绍。
4. Model Overview
我们概述了数据对齐(data alignment)、模型分解(model factorization)和模型组件(model component)。
如第 1 节所述,我们假设预测交易日 d 的走势可以受益于预测其前交易日的走势。 然而,由于样本独立的一般原则,直接在具有时间接近的目标日期的样本之间建立连接对于模型训练是有问题的。作为替代方案,我们注意到,在目标交易日为 d 的样本中,很可能存在滞后期 d 以外的其他交易日,可以模拟接近 d 的预测目标。受启发于这个观测和多任务学习,我们不只是对d天做预测,而是所有存在于lag中的交易日。比如,如下图Figure-2,要预测8月7号并且lag=5天,那么从8月2号到8月6号都应该预测,这些预测之间的关系可以因此被捕获在样本范围内。

考虑到lag中并不是每一天都是交易日,比如周末和假期,他们只把交易日当作最基础的单位,而不是按照正常日历中的日子来计算。为此,我们首先找出一个样本中引用的所有T个符合条件的交易日,换句话说,存在于时间间隔内
[
d
−
Δ
d
+
1
,
d
]
[d-\Delta d +1, d]
[d−Δd+1,d],为清楚起见,在一个样本的范围内,我们将这些交易日索引为
t
∈
[
1
,
T
]
t \in [1,T]
t∈[1,T],并且他们中的每一个都被映射到交易日
d
t
d_t
dt上。于是该文提出交易日匹配(trading day alignment),会把这些包括推特内容和价格信息的input匹配到这T个交易日上。特别地,在第t个交易日,他们会使用Corpus语料库
M
t
M_t
Mt中
[
d
t
−
1
,
d
t
]
[d_{t-1}, d_t]
[dt−1,dt]的市场信号以及
d
t
−
1
d_{t-1}
dt−1中的股票信息
p
t
p_t
pt,用来预测
d
t
d_t
dt的movements
y
t
y_t
yt (涨 or 跌)。在Figure2中他们展示了一个匹配样本,并且可以产生一个预测序列
y
∗
=
[
y
1
,
.
.
.
y
T
−
1
]
y^* = [y_1, ... y_{T-1}]
y∗=[y1,...yT−1]作为时间辅助目标。这个用来提高预测精度。
他们在下图Figure1中模拟了生产过程:

会把观测到的市场信息从预测任务中产生的潜在驱动因素(latent driven factor
Z
=
[
z
1
,
.
.
.
z
T
]
Z=[z_1, ... z_T]
Z=[z1,...zT])编码成一个随机变量
X
=
[
x
1
,
.
.
.
x
T
]
X=[x_1, ...x_T]
X=[x1,...xT]。关于前面提到的多任务学习,他们会用
∫
Z
p
θ
(
y
,
Z
∣
X
)
\int _Z p_\theta (y, Z|X)
∫Zpθ(y,Z∣X)代替
p
θ
(
y
T
∣
X
)
p_\theta (y_T|X)
pθ(yT∣X)建模条件概率分布:
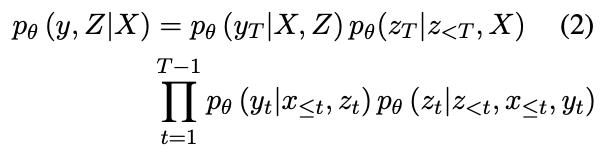
具体的公式解释可以详细看看论文。
总而言之,本文提出的StockNet包含三个自下而上(bottom-up)部分:
1, Market Information Encoder(MIE) 编码推特内容和价格到
X
X
X,
2, Variational Movement Decoder (VMD) 用 X , y X, y X,y推断 Z Z Z , 然后通过 X , Z X, Z X,Z解码走势 y y y。
3, Attentive Temporal Auxiliary (ATA) 通过模型训练的注意力机制整合时间损失。
5. Model Components
5.1 Market Information Encoder(MIE)
MIE编码社交媒体和股价信息,用来增强市场信息的质量,并且生成下一步需要用到的X, 每一个临时input被定义为:
x
t
=
[
c
t
,
p
t
]
x_t = [c_t, p_t]
xt=[ct,pt]
其中
c
t
,
p
t
c_t, p_t
ct,pt分别是corpus embedding和历史价格向量。需要
c
t
c_t
ct的基本策略是首先给Message Embedding Layer投喂messages,用于他们的低维度表示,然后根据质量选择性地将它们聚集到一起,为了处理一句话里讨论多个股票的情况,除了文本信息之外,我们还结合了消息中提到的股票代码的位置信息。 特别地,这个layer包含一个前向GRU和后向GRU,对应一个股票信息s的前、后上下文。对于消息库中的第t个交易日,会讲第
k
k
k(
k
∈
k\in
k∈[1,K])个信息表示成
W
W
W, 其中
W
l
∗
=
s
,
l
∗
∈
[
1
,
L
]
W_{l^*}=s, l^*\in[1,L]
Wl∗=s,l∗∈[1,L],然后他的词嵌入矩阵是
E
=
[
e
1
,
e
2
,
.
.
.
,
e
L
]
E=[e_1, e_2, ..., e_L]
E=[e1,e2,...,eL]。 两个GRU如下

其中
f
∈
[
1
,
.
.
.
,
l
∗
]
,
b
∈
[
l
∗
,
.
.
.
,
L
]
f\in[1, ..., l^*], b\in[l^*, ..., L]
f∈[1,...,l∗],b∈[l∗,...,L],在前面和后面的上下文中,股票代码被视为最后一个单元,其中隐藏值
h
f
,
h
b
h_f, h_b
hf,hb被平均以获得消息嵌入m 。聚集关于第k个交易日的所有消息embeddings, 会得到一个messages embedding matrix
M
t
∈
R
d
m
×
K
M_t \in R^{d_m \times K}
Mt∈Rdm×K,该层将小批量的五阶张量作为输入,并使用共享参数生成批量中的所有
M
t
M_t
Mt。
由于推特内容的质量参差不齐,受启发于News-Level attention , 我们在集体智慧测量中根据各自的显着性对信息进行加权, 首先会把 M t M_t Mt 非线形地映射到 u t u_t ut,normalized attention weight over the corpus,
u
t
=
ζ
(
w
u
T
t
a
n
h
(
W
m
,
u
M
t
)
)
u_t = \zeta(w_u^T tanh(W_{m,u}M_t))
ut=ζ(wuTtanh(Wm,uMt))
其中
ζ
(
)
\zeta()
ζ()是softmax, 然后
W
,
w
W,w
W,w都是模型参数,然后我们相应地撰写消息以获取语料库嵌入:
c
t
=
M
t
u
t
T
c_t = M_tu_t^T
ct=MtutT
由于决定股票走势的是价格变化而不是绝对价格值,
进入网络后, 会用最后调整收盘价来normalize:
p
t
=
p
~
t
/
p
~
t
−
1
c
−
1
p_t = \tilde{p}_t / \tilde{p}_{t-1}^c-1
pt=p~t/p~t−1c−1,而不是直接输入原始价格向量
p
t
~
=
[
p
~
t
c
,
p
~
t
h
,
p
~
t
l
]
\tilde{p_t}=[\tilde{p}_t^c, \tilde{p}_t^h, \tilde{p}_t^l]
pt~=[p~tc,p~th,p~tl] (包括交易日 t 调整后的收盘价、最高价和最低价)。最后
x
t
=
c
o
n
c
a
t
(
c
t
,
p
t
)
x_t=concat(c_t, p_t)
xt=concat(ct,pt)。
5.2 Variational Movement Decoder (VMD)
VMD 的目的是从编码的市场信息 X 中反复推断和解码潜在驱动因素 Z 和走势y。
Inference
虽然潜在驱动因素有助于描述导致股票走势的市场状况,但等式 (2)中所示的生成模型中的后验推论难处理。遵循 VAE 的精神,我们使用深度神经网络来拟合潜在分布,比如先验、后验,通过神经逼近(neural approximation)和重新参数(reparameterization)化来回避棘手问题。
首先会应用一个变分逼近器,
q
ϕ
(
z
t
∣
z
<
t
,
x
≤
t
,
y
t
)
q_\phi(z_t|z_{<t}, x_{\leq t}, y_t)
qϕ(zt∣z<t,x≤t,yt)替代麻烦的后验,于是就有下面的分解:
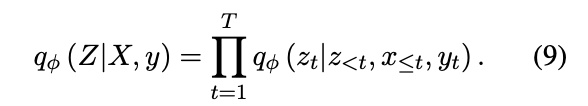
神经毕竟的目的在于缩小
q
ϕ
(
Z
∣
X
,
y
)
,
p
θ
(
Z
∣
X
,
y
)
q_\phi(Z|X,y), p_\theta(Z|X,y)
qϕ(Z∣X,y),pθ(Z∣X,y)之间的KL散度。会用到下面的方式,而不是直接逼近:

然后把等式(2), (9)放到(10)中,就有:

Decoding
根据时间序列,VMD 采用带有 GRU 单元的 RNN 来循环提取特征和解码股票信号
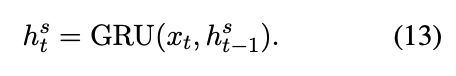
然后会让逼近器q 服从高斯正态分布
N
(
μ
,
δ
2
I
)
N(\mu, \delta^2I)
N(μ,δ2I), 其中
μ
,
δ
\mu,\delta
μ,δ分别是这样获得:
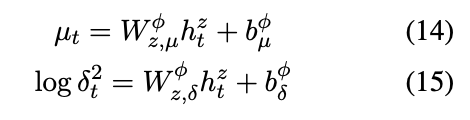
然后共享隐藏表示:
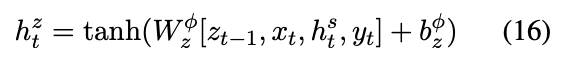
然后重新参数化
z
t
z_t
zt:
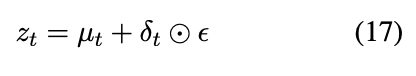
公式有点多,建议看原文推导
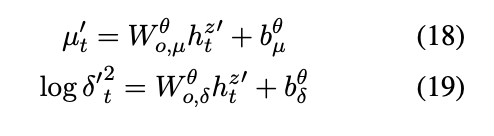
全是公式。。
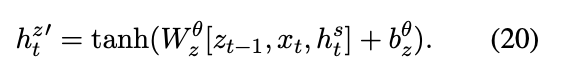
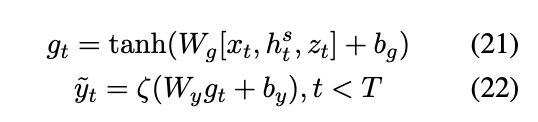
5.3 Attentive Temporal Auxiliary (ATA)
会计算两个分数,一个是information score,一个是dependency score,

其中W是矩阵参数, information score是
v
i
′
v_i'
vi′,dependency score是
v
d
′
v_d'
vd′,

其中
G
∗
G^*
G∗是集成表示,
G
∗
=
[
g
1
,
.
.
,
g
T
−
1
]
G^*=[g_1, .., g_{T-1}]
G∗=[g1,..,gT−1],而
G
T
G_T
GT是临时市场信息的最后表示(final representation of temporal market information)。
将
v
i
′
,
v
d
′
v_i', v_d'
vi′,vd′整合到一起形成最终的normalized attention weight
v
∗
v^*
v∗,然后放到下面公式中:
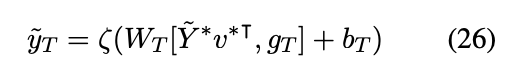
然后会用到蒙特卡洛方法去逼近等式(11)中的期望项(expectation term),
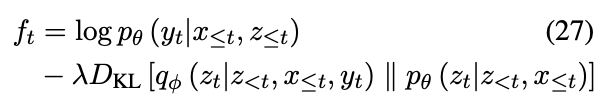
Final temporal weight vector:

最终的Objective
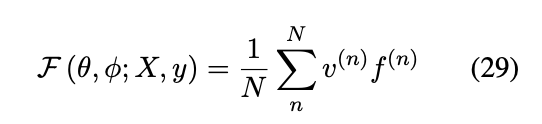
6. Experiments
setup就不说了,说一下evaluation metrics
6.2 Evaluation metrics
会用到Matthews Correlation Coefficient (MCC)
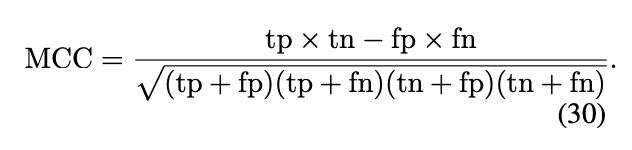
6.3 Baselines
5个Baselines:

本文提出的StockNet还有几个变种:
TechnicalAnalyst: 只用历史股价信息
FundamentalAnalyst: 只用推特文本内容
IndependentAnalyst: 没有临时辅助目标(temporal auxiliary targets)
DiscriminativeAnalyst: 直接优化似然目标函数(likelihood objective),KL项的影响会被拿掉
6.4 Results
实验结果

TLSDA是MCC中最好的,而HAN是ACC中最好的。
ARIMA模型,只比随机猜测(50%)稍微好一点, 并没有产生令人满意的结果,对于同样金使用历史股价的TechnicalAnalyst,其表现的比ARIMA更好。
Fundamental和Technical的优良表现,说明结合推特文本内容和历史股价是有效果的。其他一些分析可以看看原文,大概就是一些对潜在原因的解释。
6.5 Effects of Temporal Auxiliary
等式(28)中的
α
\alpha
α控制着目标函数级别(objective-level)的临时辅助(temporal auxiliary)的整体效果.
Figure4展示了HedgeFundAnalyst和DiscriminativeAnalyst如何随着
α
\alpha
α变动的。前者在0.5的时候达到最好,而后者是0.7的时候。

尽管在一开始的时候随着
α
\alpha
α增加,表现会下降,但中间某一个时刻,表现会得到提升,以至于结果比没有用临时辅助的模型更好。














 1609
1609











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









