







数据集下载:
import xgboost as xgb
import numpy as np
# 自己实现loss function,softmax函数
def log_reg(y_hat, y):
p = 1.0 / (1.0 + np.exp(-y_hat))
g = p - y.get_label()
h = p * (1.0 - p)
return g, h
# 自己实现错误率计算
def error_rate(y_hat, y):
return 'error', float(sum(y.get_label() != (y_hat > 0.5))) / len(y_hat)
if __name__ == '__main__':
# 读取数据
data_train = xgb.DMatrix('agaricus_train.txt')
data_test = xgb.DMatrix('agaricus_test.txt')
print('data_train:\n', data_train)
print(type(data_train))
# 设定相关参数
param = {'max_depth':2, 'eta':1, 'silent':1, 'objective':'binary:logistic'}
# param = {'max_depth':2, 'eta':1, 'silent':1, 'objective':'reg:logistic'}
watchlist = [(data_test, 'eval'), (data_train, 'train')]
n_round = 10
bst = xgb.train(param, data_train, num_boost_round=n_round, evals=watchlist, obj=log_reg, feval=error_rate)
# 计算错误率
y_hat = bst.predict(data_test)
y = data_test.get_label()
print('y_hat:\n', y_hat)
print('y:\n', y)
error = sum(y != (y_hat > 0.5))
error_rate = float(error) / len(y_hat)
print('total samples:%d' % len(y_hat))
print('the wrong numbers:%d' % error)
print('error ratio:%.3f%%' % error_rate)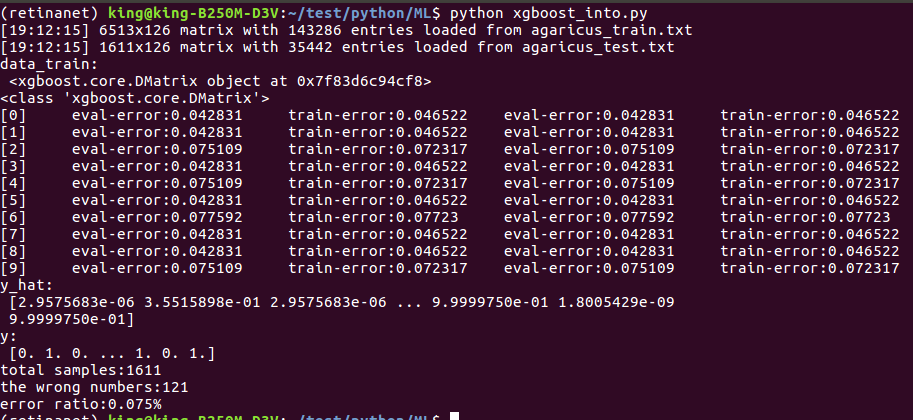
我们加入logistic回归作对比:
import xgboost as xgb
import numpy as np
import pandas as pd
import scipy.sparse
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
# 自己实现loss function,softmax函数
def log_reg(y_hat, y):
p = 1.0 / (1.0 + np.exp(-y_hat))
g = p - y.get_label()
h = p * (1.0 - p)
return g, h
# 自己实现错误率计算
def error_rate(y_hat, y):
return 'error', float(sum(y.get_label() != (y_hat > 0.5))) / len(y_hat)
def read_data(path):
y = []
row = []
col = []
values = []
r = 0 # 首行
for d in open(path):
d = d.strip().split() # 以空格分开
y.append(int(d[0]))
d = d[1:]
for c in d:
key, value = c.split(':')
row.append(r)
col.append(int(key))
values.append(float(value))
r += 1
x = scipy.sparse.csr_matrix((values, (row, col))).toarray()
y = np.array(y)
return x, y
if __name__ == '__main__':
# 读取数据
data_train = xgb.DMatrix('agaricus_train.txt')
data_test = xgb.DMatrix('agaricus_test.txt')
print('data_train:\n', data_train)
print(type(data_train))
# 设定相关参数
param = {'max_depth':2, 'eta':1, 'silent':1, 'objective':'binary:logistic'}
# param = {'max_depth':2, 'eta':1, 'silent':1, 'objective':'reg:logistic'}
watchlist = [(data_test, 'eval'), (data_train, 'train')]
n_round = 10
bst = xgb.train(param, data_train, num_boost_round=n_round, evals=watchlist, obj=log_reg, feval=error_rate)
# 计算错误率
y_hat = bst.predict(data_test)
y = data_test.get_label()
print('y_hat:\n', y_hat)
print('y:\n', y)
error = sum(y != (y_hat > 0.5))
error_rate = float(error) / len(y_hat)
print('total samples:%d' % len(y_hat))
print('the wrong numbers:%d' % error)
print('error ratio:%.3f%%' % error_rate)
print('logistic accuracy ratio:%.3f%%' % (1 - error_rate))
print('=========================================')
# logistic regression
x, y = read_data('agaricus_train.txt')
x_train, x_test, y_train, y_test = train_test_split(x, y, train_size=0.7, random_state=1)
lr = LogisticRegression(penalty='l2')
lr.fit(x_train, y_train.ravel())
y_hat = lr.predict(x_test)
acc = y_hat.ravel() == y_test.ravel()
print('acc:\t', acc)
print('XGBosst accuracy:\t', float(acc.sum()) / y_hat.size)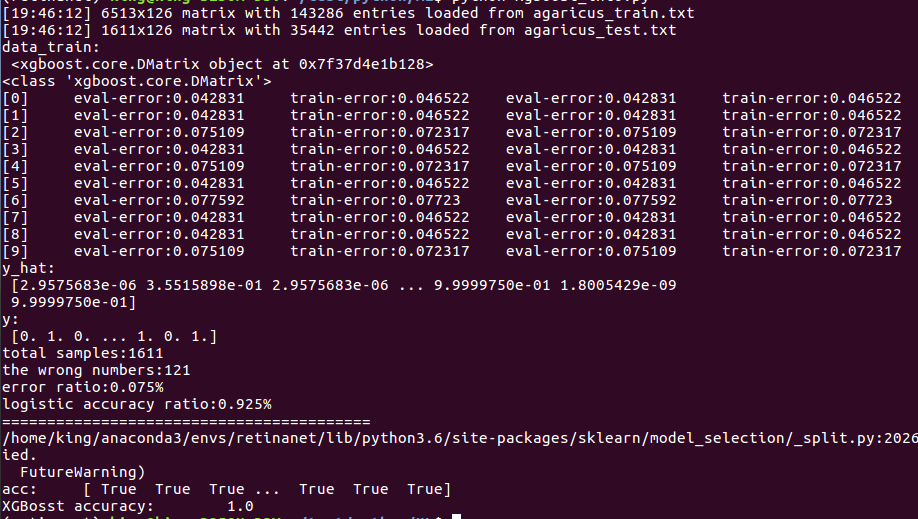















 1776
1776











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









