






1.安装包并运行
install.packages("xgboost")
require(xgboost)2.导入数据
set.seed(2021)seed:随机种子,用于产生可复现的结果
data("agaricus.train",package="xgboost")
data("agaricus.test",package="xgboost")
train <- agaricus.train
test <-agaricus.test
这份数据需要我们通过一些蘑菇的若干属性判断这个品种是否有毒。数据以 1 或 0 来标记某个属性存在与否。
class(train$data)可以看到样例数据为稀疏矩阵类型

如果数据不是稀疏矩阵类型,则需要进行预处理。
3.数据预处理
这部分以iris为例
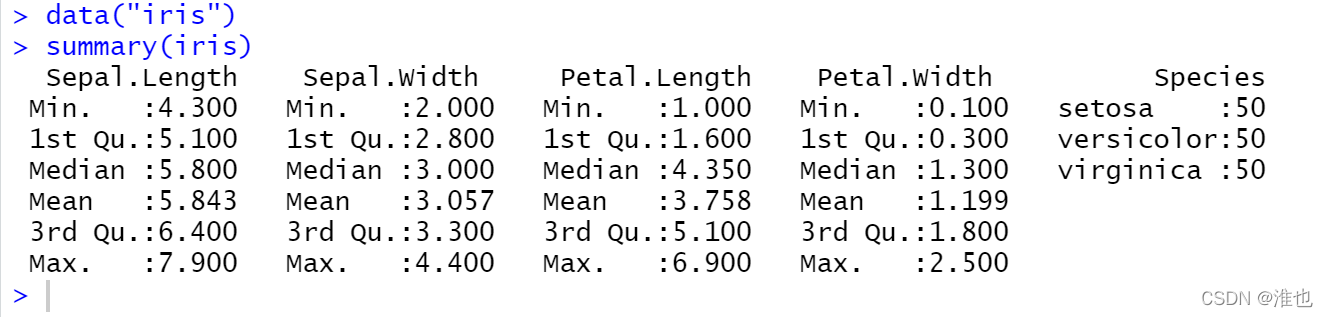

"numeric"
"list"
"list"
library(Matrix)
# 训练集的数据预处理
# 将trainset的1-4列(自变量)转换为矩阵
traindata1 <- data.matrix(trainset[,c(1:4)])
# 利用Matrix函数,将sparse参数设置为TRUE,转化为稀疏矩阵
traindata2 <- Matrix(traindata1,sparse = T)
# 将因变量转换为numeric类型,-1是为了从0开始计数
train_y <- as.numeric(trainset[,5])-1
# 将自变量和因变量拼接为list
traindata <- list(data=traindata2,label=train_y) 拼接之后的结果:data是自变量,label是因变量
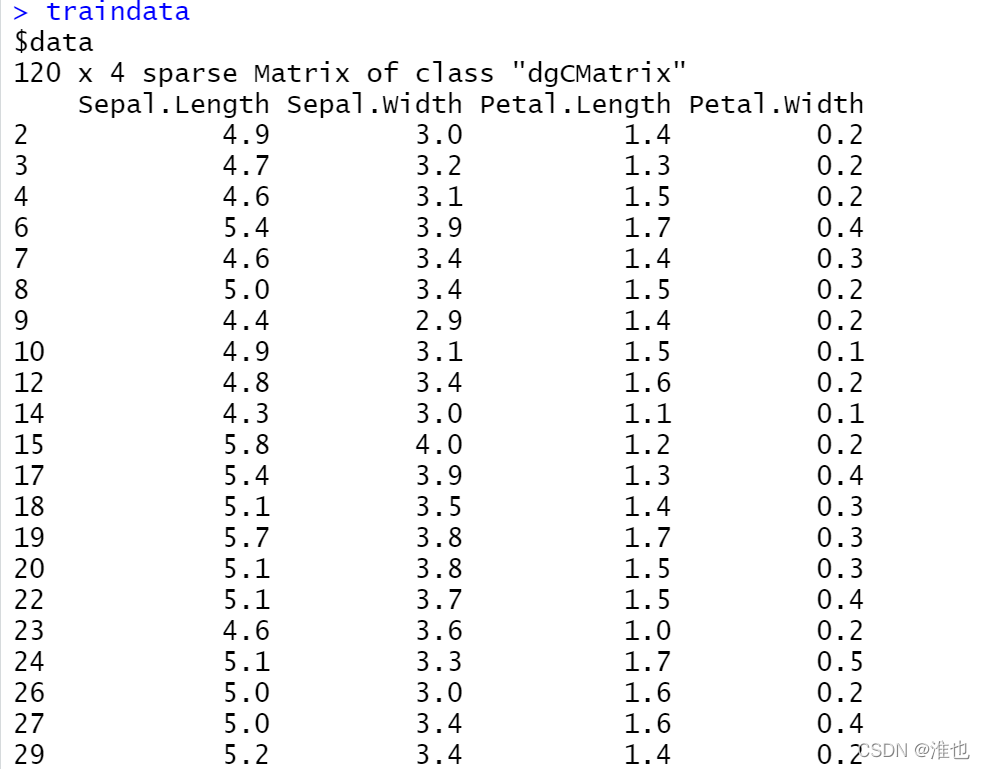
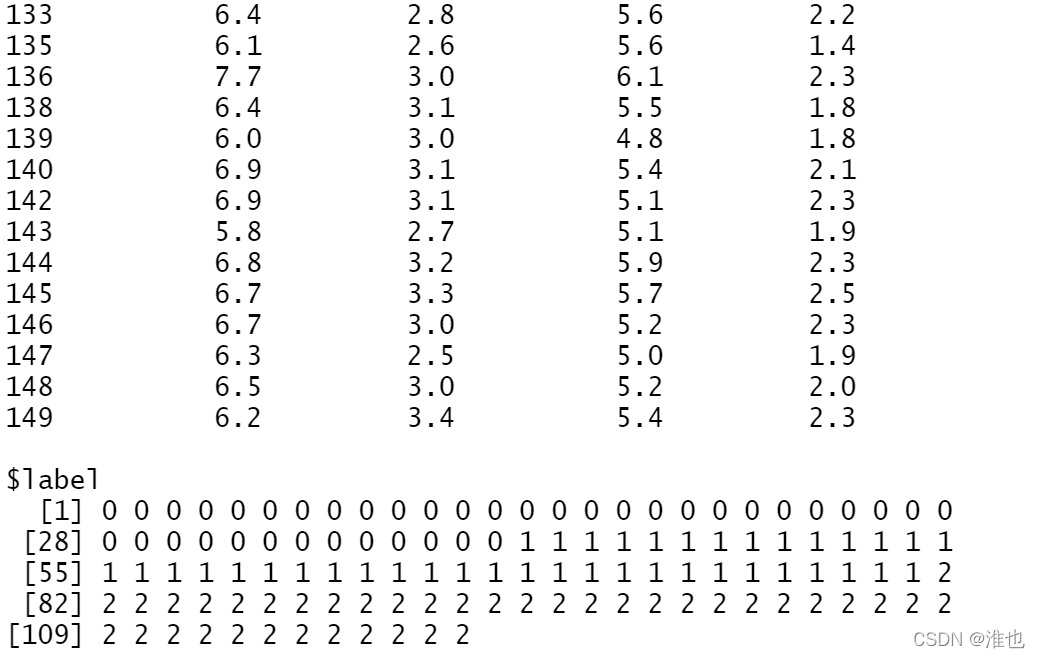
# 构造模型需要的xgb.DMatrix对象,处理对象为稀疏矩阵
dtrain <- xgb.DMatrix(data = traindata$data, label = traindata$label) 测试集也是同样的步骤
# 测试集的数据预处理
# 将自变量转化为矩阵
testset1 <- data.matrix(testset[,c(1:4)])
# 利用Matrix函数,将sparse参数设置为TRUE,转化为稀疏矩阵
testset2 <- Matrix(testset1,sparse=T)
# 将因变量转化为numeric
test_y <- as.numeric(testset[,5])-1
# 将自变量和因变量拼接为list
testset <- list(data=testset2,label=test_y)
# 构造模型需要的xgb.DMatrix对象,处理对象为稀疏矩阵
dtest <- xgb.DMatrix(data=testset$data,label=testset$label)
library(Matrix)
# 训练集的数据预处理
# 将trainset的1-4列(自变量)转换为矩阵
traindata1 <- data.matrix(trainset[,c(1:4)])
# 利用Matrix函数,将sparse参数设置为TRUE,转化为稀疏矩阵
traindata2 <- Matrix(traindata1,sparse = T)
# 将因变量转换为numeric类型,-1是为了从0开始计数
train_y <- as.numeric(trainset[,5])-1
# 将自变量和因变量拼接为list
traindata <- list(data=traindata2,label=train_y)
# 建立模型
model_xgb <- xgboost(data=dtrain,booster='gbtree',max_depth=6,eta=0.5,objective='multi:softmax',num_class=3,nround=25)
#用测试集预测
pre <- predict(model_xgb,newdata=dtest)
#模型评估
library(caret)
xgb.cf <-caret::confusionMatrix(as.factor(pre),as.factor(test_y))
xgb.cf
从混淆矩阵的对角线可以看出,预测的正确率较高
只有一个第二类预测成了第三类,其余全正确

4.建立模型
bst <- xgboost(data=train$data,label=train$label,max.depth = 2,eta = 0.5,nround = 2,objective="binary:logistic")eta:range: [0,1],参数值越大,越可能无法收敛。把学习率 eta 设置的小一些,小学习率可以使得后面的学习更加仔细。
max_depth:每颗树的最大深度,树高越深,越容易过拟合
nround:迭代次数
objective:定义最小化损失函数类型,常用参数binary:logistic,multi:softmax,multi:softprob
其它参数在这里
![]()
我们迭代了两次,可以看到函数输出了每一次迭代模型的误差信息。这里的数据是稀疏矩阵,当然也支持普通的稠密矩阵。如果数据文件太大不希望读进 R 中,我们也可以通过设置参数data = 'path_to_file'使其直接从硬盘读取数据并分析。目前支持直接从硬盘读取 libsvm 格式的文件。
5.进行预测
pred <- predict(bst,test$data)做交叉验证的函数参数与训练函数基本一致,只需要在原有参数的基础上设置nfold:
cv.res <- xgb.cv(data = train$data,label=train$label,max.depth=2,eta=1,nround=2,objective="binary:logistic",nfold=5)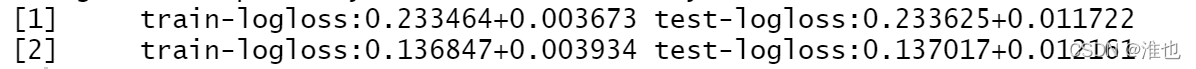
交叉验证的函数会返回一个 data.table 类型的结果,方便我们监控训练集和测试集上的表现,从而确定最优的迭代步数。
6.ROC曲线和AUC值
#在测试集上预测
pred2=round(predict(bst,newdata = test$data))
#输出混淆矩阵
table(agaricus.test$label,pred2,dnn = c("真实值","预测值"))
require(pROC)
xgboost_roc<-roc(agaricus.test$label,as.numeric(pred2))
#绘制ROC曲线和AUC值
plot(xgboost_roc,print.auc=TRUE,auc.polygon=TRUE,grid=c(0.1,0.2),gird.col=c("green","red"),max.auc.polygon=TRUE,auc.polygon.col="skyblue",print.thres=TRUE,main='xgboost模型和ROC曲线')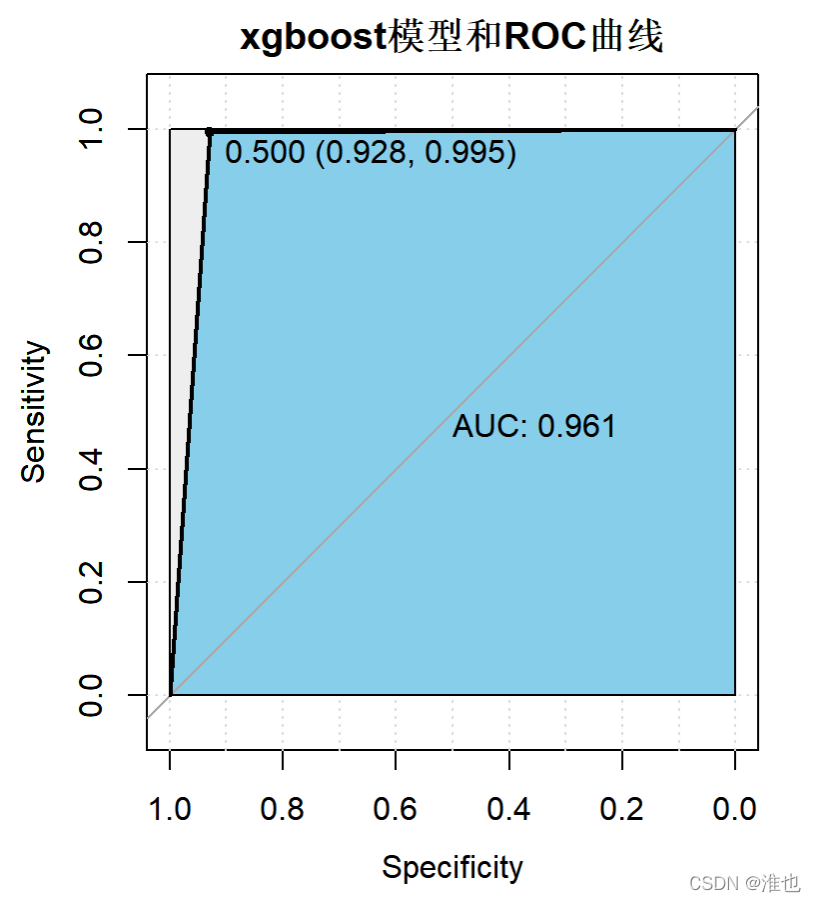

















 630
630

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









