










前言
系列专栏:【机器学习:算法项目实战】✨︎
本专栏涉及金融、医疗、电商、图像识别、自然语言处理等多个领域的真实案例,让读者从基础的监督学习(如线性回归、逻辑回归、决策树、随机森林)、无监督学习(聚类算法、降维技术)到进阶的深度学习(神经网络、卷积神经网络CNN、循环神经网络RNN等),都能够全面掌握机器学习领域的核心算法,了解不同行业背景下机器学习的应用。
在当今金融科技飞速发展的时代,股票市场作为经济的晴雨表,吸引着无数投资者和研究者的目光。准确预测股票价格的走势,对于投资者制定合理的投资策略、降低风险以及获取收益具有至关重要的意义。然而,股票价格的波动受到众多复杂因素的影响,如宏观经济形势、公司财务状况、行业趋势、市场情绪等,使得其预测成为一项极具挑战性的任务。
机器学习技术的兴起为解决这一难题提供了新的途径和方法。其中,XGBoost(极端梯度提升决策树)凭借其卓越的性能和强大的泛化能力,在众多机器学习算法中脱颖而出,成为了股票价格预测领域的热门工具之一。它能够有效地处理大规模数据集,自动挖掘数据中的特征和规律,并且在处理非线性关系方面表现出色,非常适合于股票市场这种复杂多变的数据分析场景。
在实际应用中,为了确保模型的准确性和可靠性,我们需要采用合适的技术和方法。TimeSeriesSplit 交叉验证是一种专门针对时间序列数据的验证方法,它充分考虑了时间序列数据的顺序性和相关性特点,能够更真实地模拟模型在实际应用中的表现。通过合理地划分训练集和验证集,我们可以更好地评估模型的性能,并及时发现和解决过拟合或欠拟合等问题。
同时,GridSearchCV超参数调优也是模型训练过程中不可或缺的环节。XGBoost 模型包含众多超参数,如学习率、树的深度、正则化参数等,这些超参数的取值直接影响着模型的性能。通过对超参数进行精细调优,我们可以找到一组最适合当前数据集和任务的参数组合,从而最大限度地提高模型的预测精度。
本博客将深入探讨如何基于 XGBoost 极端梯度提升决策树实现股票价格预测,并详细介绍 TimeSeriesSplit 交叉验证以及超参数调优的相关知识和实践技巧。我们将从原理到实践,逐步引导读者掌握这一强大的工具,希望能够为广大投资者和机器学习爱好者提供有益的参考和借鉴,助力大家在股票市场的分析和预测中取得更好的成果。让我们一起开启这场充满挑战与机遇的机器学习之旅,探索股票价格预测的奥秘。
文章目录
1. 库和数据集
1.1 相关库介绍
Python 库使我们能够非常轻松地处理数据并使用一行代码执行典型和复杂的任务。
Numpy– Numpy 数组速度非常快,可以在很短的时间内执行大型计算。Pandas– 该库有助于以 2D 数组格式加载数据框,并具有多种功能,可一次性执行分析任务。Matplotlib/Seaborn– 此库用于绘制可视化效果,用于展现数据之间的相互关系。Sklearn– 包含多个库,这些库具有预实现的功能,用于执行从数据预处理到模型开发和评估的任务。XGBoost– 包含 eXtreme Gradient Boosting 机器学习算法,是帮助我们实现高精度预测的算法之一。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib.dates as mdates
import seaborn as sns
from xgboost import XGBRegressor
from sklearn.preprocessing import MinMaxScaler
from sklearn.model_selection import TimeSeriesSplit, GridSearchCV
from sklearn.model_selection import learning_curve, LearningCurveDisplay
from sklearn.metrics import mean_absolute_error, \
mean_absolute_percentage_error, \
mean_squared_error, root_mean_squared_error, \
r2_score
np.random.seed(0)
1.2 数据集介绍
我们将在这里用于执行分析和构建预测模型的数据集是苹果股价数据。AAPL.csv 股票数据集,是苹果公司(Apple Inc.)在股票市场上的交易数据集合。包含开盘价、最高价、最低价、收盘价等数据。数据集下载链接🔗
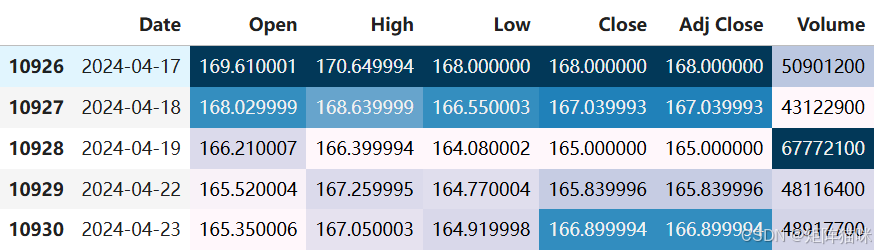
data = pd.read_csv('AAPL.csv')
data.tail(5).style.background_gradient()
2. 数据预处理
函数 pandas.to_datetime 可以将标量、数组、Series 或 DataFrame/dict-like 转换为时间数据类型
print(type(data['Close'].iloc[0]),type(data['Date'].iloc[0]))
# Let's convert the data type of timestamp column to datatime format
data['Date'] = pd.to_datetime(data['Date'])
print(type(data['Close'].iloc[0]),type(data['Date'].iloc[0]))
# Selecting subset
cond_1 = data['Date'] >= '2021-04-23 00:00:00'
cond_2 = data['Date'] <= '2024-04-23 00:00:00'
data = data[cond_1 & cond_2].set_index('Date')
print(data.shape)
<class 'numpy.float64'> <class 'str'>
<class 'numpy.float64'> <class 'pandas._libs.tslibs.timestamps.Timestamp'>
(755, 6)
这里我们使用 2021-04-23 00:00:00 至 2024-04-23 00:00:00 的数据集来训练模型
3. 数据可视化
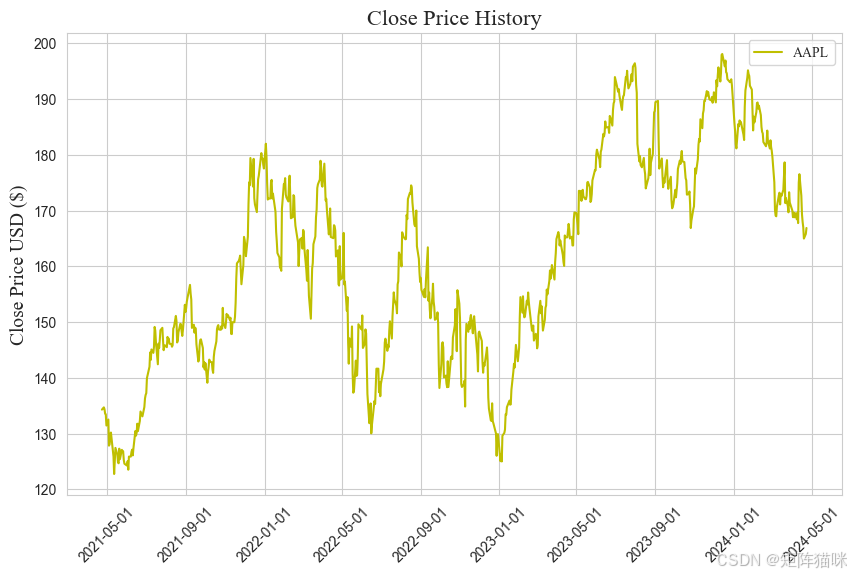
可视化一种使用视觉技术分析数据的方法。它用于发现趋势和模式,或借助统计摘要和图形表示来检查假设。可视化可以通过图形快速识别股价的趋势走向。
sns.set_style('whitegrid')
# plt.style.use('seaborn-v0_8-whitegrid')
fig, ax = plt.subplots(figsize=(10, 6))
# 绘制数据
ax.plot(data['Close'], color='y' ,label='AAPL')
# 设置x轴为时间轴,并显示具体日期
locator = mdates.AutoDateLocator(minticks=8, maxticks=12) # 自动定位刻度
formatter = mdates.DateFormatter('%Y-%m-%d') # 自定义刻度标签格式
ax.xaxis.set_major_locator(locator)
ax.xaxis.set_major_formatter(formatter)
# 设置标题
plt.title('Close Price History', fontdict={'family': 'Times New Roman', 'fontsize': 16})
# 旋转刻度标签以提高可读性
plt.xticks(rotation=45)
plt.ylabel('Close Price USD ($)', fontdict={'family': 'Times New Roman', 'fontsize': 14})
plt.legend(loc="upper right", prop={'family': 'Times New Roman'})
# 显示图形
plt.show()
4. 特征工程
特征工程有助于从现有特征中派生出一些有价值的特征。这些额外的功能有时有助于显著提高模型的性能,当然也有助于更深入地了解数据。
4.1 特征缩放(归一化)
选择 Close \text{Close} Close 价格特征来训练模型
values = data['Close'].values.reshape(-1, 1)
reshape 方法用于改变数组的形状。第一个参数 -1 表示自动推断该维度的大小,使得数组在保持总元素数量不变的情况下,根据第二个参数的要求进行重塑。第二个参数 1 指定了新数组的第二维度为 1。举例说明,如果原始的 data 是一个一维数组 [1, 2, 3, 4],执行 data.reshape(-1, 1) 后,data 将变为一个二维数组 [[1], [2], [3], [4]]。如果原始的 data 是一个二维数组,比如 [[1, 2], [3, 4]] ,执行该操作后会将其转换为一个二维数组,其中每个元素都被转换为一个包含单个元素的列表,即 [[1], [2], [3], [4]]。
# 创建 MinMaxScaler实例,进行拟合和变换,生成NumPy数组
scaler = MinMaxScaler()
values_scaled = scaler.fit_transform(values)
print(values_scaled.shape)
在 scikit-learn 库中,MinMaxScaler() 函数将数据集中的每个特征[列]进行线性变换,使得特征值映射到一个指定的区间,通常是 [0, 1]。对于特征中的每个
x
x
x 值,转换公式为
x
n
e
w
=
x
−
x
m
i
n
x
m
a
x
−
x
m
i
n
x_{new}=\frac{x-x_{min}} {x_{max}-x_{min}}
xnew=xmax−xminx−xmin,其中
x
m
i
n
x_{min}
xmin是该特征的最小值,
x
m
a
x
x_{max}
xmax是该特征的最大值。这种缩放方法可以帮助改善算法的收敛速度和性能,特别是在特征尺度差异较大的情况下。
4.2 构建监督学习数据
在时间序列预测中,我们将时间序列数据转换为监督学习格式,可以方便地应用各种机器学习模型进行预测。
# 定义滞后步数(即使用过去多少天的数据来预测未来的值)
lag = 2
X_list = [] # 初始化特征列表
y_list = [] # 初始化目标列表
# 遍历时间序列数据,生成监督学习数据
for i in range(len(values_scaled) - lag):
# 提取当前行及其滞后行的数据,并展平数组
X_list.append(values_scaled[i:i+lag, :].flatten())
# 提取目标行的目标值(这里我们使用下一个时间点的收盘价作为目标)
y_list.append(values_scaled[i+lag, -1]) # 提取收盘价作为目标值
X = np.array(X_list) # [samples, num_features]
y = np.array(y_list) # [target]
上述代码的目的是进行时间序列数据的预处理,将原始的时间序列数据转换为适合机器学习模型输入的监督学习数据格式。lag:表示每个样本中包含的滞后步数,它决定了模型在预测时考虑的历史数据长度。X_list:用于存储分割后的特征数据样本的列表。y_list:用于存储每个特征数据样本对应的目标值的列表。
for i in range(len(values_scaled) - lag):使用for循环遍历values_scaled,但会在倒数第lag个元素处停止,因为后面不足lag个数据来构建特征。X_list.append(values_scaled[i:i + lag, :].flatten()):- 对于每个索引
i,从标准化后的时间序列数据values_scaled中提取从i到i + lag行的数据。这里的:表示选择所有的列。例如,如果lag = 2,当i = 0时,它会选择第 0 \text{0} 0 行和第 1 \text{1} 1 行的数据。 - 然后使用
flatten()函数将提取的二维数组[lag, num_features]展平为一维数组。这样做是为了将这些数据作为一个特征向量。展平后的数据被添加到X_list中。
- 对于每个索引
y_list.append(values_scaled[i + lag, -1]):这里是提取目标值。对于每个索引i,选择i + lag行的最后一个元素(这里假设最后一个元素是收盘价,索引为 -1)作为目标值。例如,当i = 0且lag = 2时,会选择第 2 \text{2} 2 行的最后一个元素作为目标值。这个目标值被添加到y_list中。
5. 实例化模型、定义超参数空间
model = XGBRegressor(
objective='reg:squarederror',
n_estimators=1000,
learning_rate=0.03,
eval_metric=['mae', 'rmse'] # 指定多个评估指标
)
# 定义超参数的搜索空间
param_grid = {
'n_estimators': [500, 800, 1000],
'learning_rate': [0.01, 0.03, 0.05],
'max_depth': [3, 5, 7]
}
6. 交叉验证与超参数调优
在 scikit-learn 中,TimeSeriesSplit用于对时间序列数据进行交叉验证
C
r
o
s
s
Cross
Cross
V
a
l
i
d
a
t
i
o
n
Validation
Validation。交叉验证是一种评估模型性能的技术,通过将数据集划分为不同的子集来训练和测试模型。当使用TimeSeriesSplit(n_splits = 5)时,它的目的是将时间序列数据划分为 5 个不同的折叠Fold用于交叉验证,同时保持数据的时间顺序。这种划分方式对于时间序列数据很重要,因为传统的随机划分可能会导致信息泄露,比如未来的数据信息被用于训练模型来预测过去的数据。
# 时序交叉验证划分
tscv = TimeSeriesSplit(n_splits=5)
# 使用GridSearchCV进行超参数调优
grid_search = GridSearchCV(
estimator=model,
param_grid=param_grid,
scoring='neg_mean_squared_error', # 根据需要可更改评估指标,这里以均方误差为例
cv=tscv,
verbose=2
)
# 执行超参数搜索,传入完整的数据集X和y
grid_search.fit(
X, y,
verbose=False, # 设置 verbose=False
)
# 输出最佳超参数组合
best_params = grid_search.best_params_
print("Best Hyperparameters:", grid_search.best_params_)
# 输出最佳模型在交叉验证中的平均得分,依据选择的评估指标
print("Best Model CV Score:", -grid_search.best_score_)
Best Hyperparameters: {'learning_rate': 0.01, 'max_depth': 3, 'n_estimators': 800}
Best Model CV Score: 0.011451393913332147
# 输出最佳模型
best_model = grid_search.best_estimator_
7. 交叉验证与模型评估
# 基于交叉验证的数据集划分
for i, (train_index, test_index) in enumerate(tscv.split(X)):
X_train, X_test = X[train_index], X[test_index]
y_train, y_test = y[train_index], y[test_index]
# 模型预测
y_pred = best_model.predict(X_test)
# 模型评估
mae = mean_absolute_error(y_test, y_pred)
print(f"Fold {i} - Mean Absolute Error: {mae:.4f}")
mape = mean_absolute_percentage_error(y_test, y_pred)
print(f"Fold {i} - Mean Absolute Percentage Error: {mape * 100:.4f}%")
mse = mean_squared_error(y_test, y_pred)
print(f"Fold {i} - Mean Squared Error: {mse:.4f}")
rmse = root_mean_squared_error(y_test, y_pred)
print(f"Fold {i} - Root Mean Squared Error: {rmse:.4f}")
r2 = r2_score(y_test, y_pred)
print(f"Fold {i} - R²: {r2:.4f}\n")
Fold 0 - Mean Absolute Error: 0.0273
Fold 0 - Mean Absolute Percentage Error: 4.9005%
Fold 0 - Mean Squared Error: 0.0012
Fold 0 - Root Mean Squared Error: 0.0343
Fold 0 - R²: 0.9157
Fold 1 - Mean Absolute Error: 0.0304
Fold 1 - Mean Absolute Percentage Error: 9.9030%
Fold 1 - Mean Squared Error: 0.0015
Fold 1 - Root Mean Squared Error: 0.0383
Fold 1 - R²: 0.9249
Fold 2 - Mean Absolute Error: 0.0239
Fold 2 - Mean Absolute Percentage Error: 10.9447%
Fold 2 - Mean Squared Error: 0.0010
Fold 2 - Root Mean Squared Error: 0.0315
Fold 2 - R²: 0.9503
Fold 3 - Mean Absolute Error: 0.0184
Fold 3 - Mean Absolute Percentage Error: 2.4598%
Fold 3 - Mean Squared Error: 0.0007
Fold 3 - Root Mean Squared Error: 0.0256
Fold 3 - R²: 0.9386
Fold 4 - Mean Absolute Error: 0.0194
Fold 4 - Mean Absolute Percentage Error: 2.5440%
Fold 4 - Mean Squared Error: 0.0007
Fold 4 - Root Mean Squared Error: 0.0255
Fold 4 - R²: 0.9582
依据以上 Fold 的得分,我们可以清晰观察到最佳 Fold 为 Fold 4。MSE 得分越低,R² 得分越高越好
7.1 学习曲线分析
接下来,我们可以结合交叉验证的思想来绘制一种“近似”的学习曲线。具体来说,我们可以使用交叉验证的结果来评估模型在不同训练样本数量下的性能,在sklearn中,我们可以通过导入learning_curve函数绘制学习曲线,以帮助分析模型在不同训练集大小上的性能表现,进而判断模型是否存在高偏差或高方差问题,以及增大训练集是否有助于减小过拟合。
learning_curve(estimator = best_model, X = X, y = y, cv=tscv, scoring='neg_mean_squared_error', n_jobs=3)
(array([ 12, 41, 70, 99, 128]),
array([[-1.70530316e-06, -1.70530316e-06, -1.70530316e-06,
-1.70530316e-06, -1.70530316e-06],
[-5.53802634e-05, -5.53802634e-05, -5.53802634e-05,
-5.53802634e-05, -5.53802634e-05],
[-1.03683801e-04, -1.03683801e-04, -1.03683801e-04,
-1.03683801e-04, -1.03683801e-04],
[-1.79304546e-04, -1.79304546e-04, -1.79304546e-04,
-1.79304546e-04, -1.79304546e-04],
[-1.81057192e-04, -1.81057192e-04, -1.81057192e-04,
-1.81057192e-04, -1.81057192e-04]]),
array([[-0.19550753, -0.06879683, -0.0530716 , -0.38532008, -0.42156308],
[-0.1990692 , -0.0705243 , -0.05437699, -0.39042858, -0.42688051],
[-0.08159986, -0.02014378, -0.01245156, -0.20970311, -0.23760865],
[-0.04160304, -0.00901894, -0.00506435, -0.13518084, -0.15840036],
[-0.0406867 , -0.00842727, -0.0047505 , -0.13327182, -0.15635491]]))
train_sizes, train_scores, test_scores = learning_curve(estimator = best_model, X = X, y = y, cv=tscv, scoring='neg_mean_squared_error', n_jobs=3)
函数将返回三个主要结果:train_sizes:生成的训练样本数。train_scores:训练集上的分数,维度为 (len(train_sizes), cv分割数)。test_scores:测试集上的分数,维度与 train_scores 相同。
display = LearningCurveDisplay(train_sizes=train_sizes,
train_scores=train_scores,
test_scores=test_scores,
score_name="NMSE") # 负均方误差
display.plot()
plt.title(f'{best_model.__class__.__name__} Learning Curve',
fontdict={'family':'Times New Roman','fontsize': 16})
plt.show()
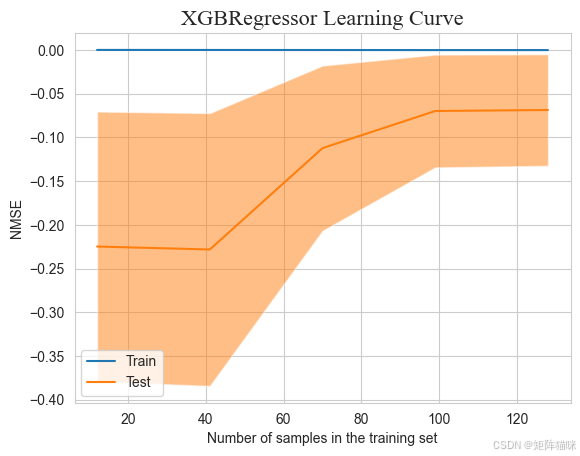
在 sklearn 中,当你使用某些模型评估函数或进行交叉验证时,可能会遇到负均方误差的情况。例如,在 cross_val_score 函数中,如果指定 scoring='neg_mean_squared_error',则返回的分数实际上是负均方误差。这种设计以便在模型选择和调优过程中能够直接通过比较分数大小来判断模型的优劣(分数越高,模型越好)。
7.2 损失曲线分析
在机器学习项目中,evals_result()函数常用于评估模型性能,并返回包含不同评估指标结果的字典或类似结构。在使用基于梯度提升的模型,如 LightGBM 或 XGBoost 时,evals_result() 可以用于获取训练过程中每一轮或每一棵树的评估结果,包括损失函数值和自定义的评估指标,如 MAE、RMSE 等。
def error(model, tscv, fold):
# 获取指定折的数据集划分
all_splits = list(tscv.split(X, y))
train_idx, test_idx = all_splits[fold]
X_train, X_test = X[train_idx, :], X[test_idx, :]
y_train, y_test = y[train_idx], y[test_idx]
# 设置损失与早停轮数,如果验证集的性能在连续10轮内没有提升,则提前停止训练
model.set_params(eval_metric=['mae', 'rmse'], early_stopping_rounds=10)
model.fit(X_train, y_train, eval_set=[(X_train, y_train), (X_test, y_test)],
verbose = False)
# 提取评估结果
results = model.evals_result()
mae_train = results['validation_0']['mae']
rmse_train = results['validation_0']['rmse']
mae_test = results['validation_1']['mae']
rmse_test = results['validation_1']['rmse']
return mae_train, mae_test, rmse_train, rmse_test
以上代码定义了一个名为 error 的函数,其主要目的是针对给定的模型、时间序列交叉验证对象 tscv 以及指定的折数 fold,进行模型的训练、评估,并返回训练集和测试集上的平均绝对误差
MAE
\text{MAE}
MAE 以及均方根误差
RMSE
\text{RMSE}
RMSE 指标。
# 初始化模型,计算 MAE、RMSE
model = XGBRegressor(**best_params)
mae_train, mae_test, rmse_train, rmse_test = error(model, tscv, fold = 4)
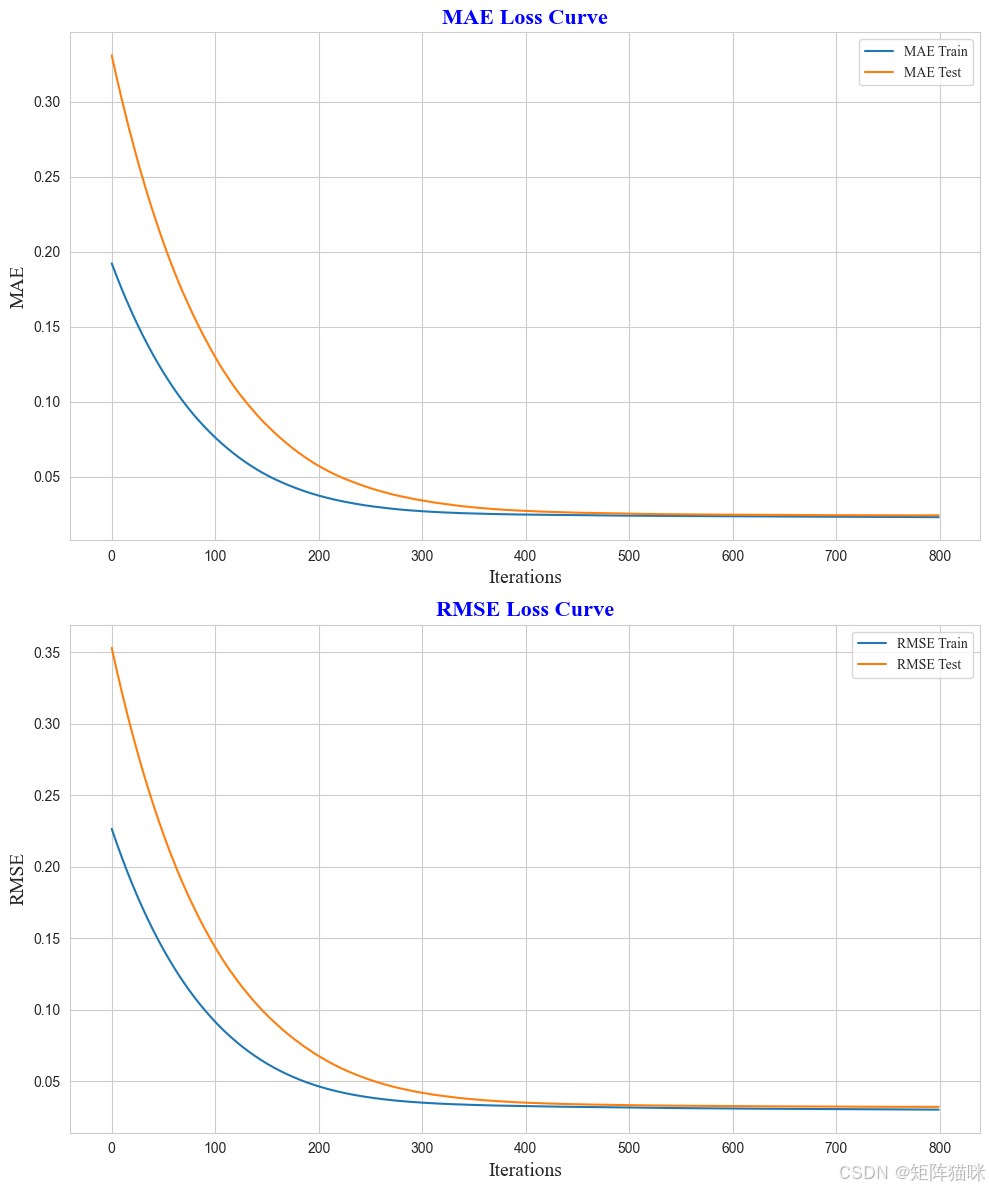
通过以上函数 error 的计算,我们可以绘制出 Fold 4 的
MAE
\text{MAE}
MAE 和
RMSE
\text{RMSE}
RMSE 验证损失曲线
fig, ax = plt.subplots(ncols=2, nrows=1,
figsize=(18, 6))
# MAE
ax[0].plot(mae_train, label='MAE Train')
ax[0].plot(mae_test, label='MAE Test')
ax[0].set_title('MAE Loss Curve',
fontdict={'family': 'Times New Roman',
'fontsize': 16,
'fontweight': 'bold',
'color': 'blue'})
ax[0].set_xlabel('Iterations',
fontdict={'family': 'Times New Roman',
'fontsize': 14})
ax[0].set_ylabel('MAE',
fontdict={'family': 'Times New Roman',
'fontsize': 14})
ax[0].legend(prop={'family': 'Times New Roman'})
# RMSE
ax[1].plot(rmse_train, label='RMSE Train')
ax[1].plot(rmse_test, label='RMSE Test')
ax[1].set_title('RMSE Loss Curve',
fontdict={'family': 'Times New Roman',
'fontsize': 16,
'fontweight': 'bold',
'color': 'blue'})
ax[1].set_xlabel('Iterations',
fontdict={'family': 'Times New Roman',
'fontsize': 14})
ax[1].set_ylabel('RMSE',
fontdict={'family': 'Times New Roman',
'fontsize': 14})
ax[1].legend(prop={'family': 'Times New Roman'})
# 调整子图之间的间距
plt.tight_layout()
# 显示图形
plt.show()
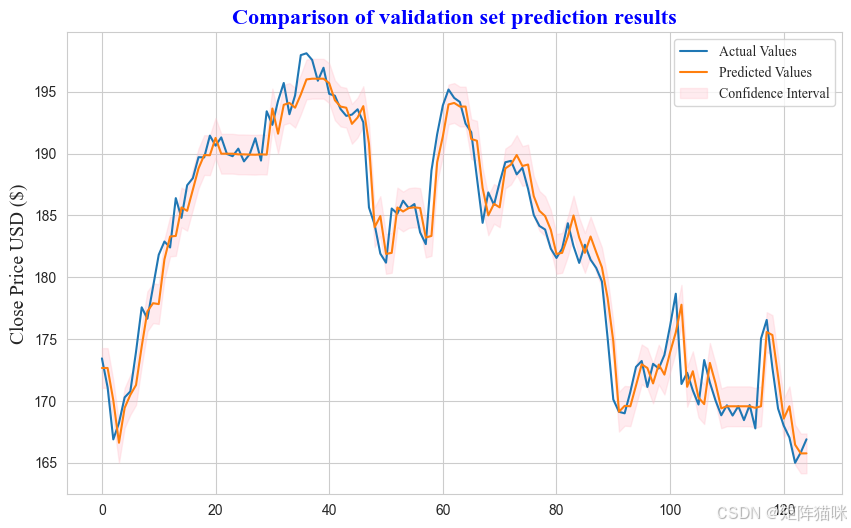
7.3 验证集预测
在进行验证预测之前,我们首先构建一个模型在每一个折叠 Fold 上的预测函数predicction
def prediction(model, tscv, fold):
# 获取指定折的数据集划分
all_splits = list(tscv.split(X, y))
train_idx, test_idx = all_splits[fold]
X_train, X_test = X[train_idx, :], X[test_idx, :]
y_train, y_test = y[train_idx], y[test_idx]
# 设置早停轮数,验证集的性能在连续10轮内没有提升,则提前停止训练
model.set_params(early_stopping_rounds=10)
model.fit(X_train, y_train, eval_set=[(X_test, y_test)],
xgb_model = best_model, verbose = False)
y_pred = model.predict(X_test)
return y_test, y_pred
上述代码,通过 eval_set 指定了仅使用测试集 (X_test, y_test) 作为验证集来监控模型性能,并且传入了xgb_model = best_model 最佳模型实例,保证了模型的最优性能,并在此基础上继续训练。最终返回折叠 Fold 上的测试值与预测值。
y_test, y_pred = prediction(model, tscv, fold=4) # Fold 4
上述代码,通过prediction函数返回 Fold 4 的 y_test, y_pred值。其实在这一步上,省略了模型初始化的过程,因为在上文损失分析中,已经对模型进行了初始化。若有兴趣可以尝试其它 Fold。
在绘制验证集预测图形之前,我们需要将原先缩放的目标数据,以及模型预测数据进行反归一化
y_test_denormalized = scaler.inverse_transform(y_test.reshape(1, -1)).ravel()
y_pred_denormalized = scaler.inverse_transform(y_pred.reshape(1, -1)).ravel()
.reshape(1, -1):将一维数组形状重塑为一个二维数组,其中第一维的大小为1,第二维的大小由-1自动推断,以适应原一维数组中元素的数量。这样做是因为scaler.inverse_transform 方法通常期望输入数据是二维的,形式为[num_samples, num_features]。ravel() 函数用于将二维数组展平为一维数组,得到最终的反归一化数据尺度与原始数据尺度相同。
# 计算标准误差 (Standard Deviation)
standard_dev = np.std(y_pred_denormalized, ddof=1) / np.sqrt(len(y_pred_denormalized))
# 根据正态分布的特性,计算z分数
# 对于95%的置信水平,z分数约为1.96(这是基于标准正态分布的双侧区间)
z_score = 1.96
# 计算置信区间的上下界
lower_bound = y_pred_denormalized - z_score * standard_dev
upper_bound = y_pred_denormalized + z_score * standard_dev
plt.figure(figsize=(10,6))
x_coords = np.arange(len(y_pred_denormalized))
plt.plot(y_test_denormalized, label='Actual Values')
plt.plot(y_pred_denormalized, label='Predicted Values')
plt.fill_between(x=x_coords,
y1=lower_bound, y2=upper_bound,
color='pink', alpha=0.3, label='Confidence Interval')
plt.title('Comparison of validation set prediction results',
fontdict={'family': 'Times New Roman',
'fontsize': 16, 'fontweight': 'bold', 'color': 'blue'})
plt.ylabel('Close Price USD ($)', fontdict={'family': 'Times New Roman', 'fontsize': 14})
plt.legend(prop={'family': 'Times New Roman'})
plt.show()
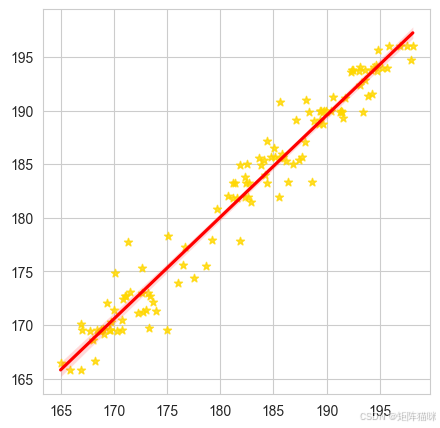
7.4 回归拟合图
通过 regplot() 函数绘制数据图并查看模型的拟合效果。
plt.figure(figsize=(5, 5), dpi=100)
sns.regplot(x=y_test_denormalized, y=y_pred_denormalized, scatter=True, marker="*", color='gold',line_kws={'color': 'red'})
plt.show()
7.5 评估指标
以下代码使用了一些常见的评估指标:平均绝对误差(MAE)、平均绝对百分比误差(MAPE)、均方误差(MSE)、均方根误差(RMSE)和决定系数(R²)来衡量模型预测的性能。这里我们将通过调用 sklearn.metrics 模块中的 mean_absolute_error mean_absolute_percentage_error mean_squared_error root_mean_squared_error r2_score 函数来对模型的预测效果进行评估。
mae = mean_absolute_error(y_test, y_pred)
print(f"MAE: {mae:.4f}")
mape = mean_absolute_percentage_error(y_test, y_pred)
print(f"MAPE: {mape * 100:.4f}%")
mse = mean_squared_error(y_test, y_pred)
print(f"MSE: {mse:.4f}")
rmse = root_mean_squared_error(y_test, y_pred)
print(f"RMSE: {rmse:.4f}")
r2 = r2_score(y_test, y_pred)
print(f"R²: {r2:.4f}")
MAE: 0.0194
MAPE: 2.5440%
MSE: 0.0007
RMSE: 0.0255
R²: 0.9582
若要提高模型预测的准确度,接下来我们将尝试使用深度学习进行股票市场预测,在下一章节我们将探讨如何使用深度学习时序预测来预测股票市场。
深度学习时序预测(TSF)
- (Ⅰ):基于前馈神经网络FNN实现股价多变量时序预测(PyTorch版)
- (Ⅱ):基于循环神经网络RNN实现股价多变量时序预测(PyTorch版)
- (Ⅲ):基于门控循环单元GRU实现股价多变量时序预测(PyTorch版)
- (Ⅳ):基于长短期记忆 LSTM 实现股价多变量时序预测(PyTorch版)
- (Ⅴ):基于双向门控循环单元BiGRU实现股价多变量时序预测(PyTorch版)
- (Ⅵ):基于双向长短期记忆 BiLSTM 实现股价多变量时序预测(PyTorch版)
- (Ⅶ):基于CNN(二维卷积Conv2D)+LSTM 实现股价多变量时序预测(PyTorch版)
- (Ⅷ):基于CNN(一维卷积Conv1D)+LSTM+Attention 实现股价多变量时序预测(PyTorch版)
- (Ⅸ):基于LSTM-Transformer混合模型实现股价多变量时序预测(PyTorch版)
- (Ⅹ):基于LSTM-Transformer混合模型实现股价多变量时序预测——(skorch版)


















 1779
1779

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











