







视频生成模型评测基准 VBench,以其全面且细致的评测体系及评估效率,被国内外众多大模型厂商、研究机构及科技媒体所采用。VBench 榜单上的评分,已成为衡量视频生成模型性能的重要指标,并为模型能力提升提供了方向参考。
近日,VBench 评测基准已在司南评测社区集上线,诚邀开发者下载使用。本篇文章将详细解读 VBench 系列工作。
在人工智能蓬勃发展的当下,视频生成模型广泛应用于内容创作、娱乐、安防等领域,从影视特效制作到短视频生产,再到智能监控,其技术突破不断重塑人们的生活与工作模式。但随着各类视频生成模型不断涌现,如何精准评估其性能,成为研究者和从业者面临的关键问题。
-
到底哪个视频生成模型性能最强?
-
每个模型各自有什么特长?
-
AI 视频生成领域目前还有哪些值得关注的问题待解决?
在此背景下,上海人工智能实验室、南洋理工大学S-Lab、香港中文大学、南京大学联合发布了视频生成模型评测体系 VBench,其相关研究论文成功入选 CVPR 2024 Highlight 论文名单。
VBench 不仅包含了 16 个分层和解耦的评测维度,确保了评估的全面性和细致度,还通过贴近人类感知的评测方法,提高了评估结果的真实性和可靠性。其开源的代码及提示词体系,更是促进了技术的透明度和社区的参与,加速了视频生成技术的创新与迭代。
最新发布的 VBench++ 支持更广泛的视频生成任务,包括文本生成视频和图像生成视频,并配有一套自适应的图像套件,以便在不同的设置下进行公平评估。不仅评估技术质量,还评估生成模型的可信度,从而提供对模型性能的全面评估。
VBench 系列工作不仅在学术界引起了广泛关注,也在产业界产生了深远影响。VBench 榜单目前已经成为视频生成模型领域权威榜单,榜单内容多次被知名视频模型厂商、头部科技媒体引用,能否在 VBench 榜单上名列前茅,已成为衡量视频生成模型性能的重要参考标准,深刻影响着行业的技术发展方向和产品研发策略。
VBench 评测基准现已在司南评测社区集上线,欢迎大家使用。
https://hub.opencompass.org.cn/dataset-detail/VBench


VBench 论文链接:
https://arxiv.org/abs/2311.17982
VBench++ 论文链接:
https://arxiv.org/abs/2411.13503
开源链接:
https://github.com/Vchitect/VBench
模型评测实时排行榜详见:
https://huggingface.co/spaces/Vchitect/VBench_Leaderboard
评测结果更符合人类感知
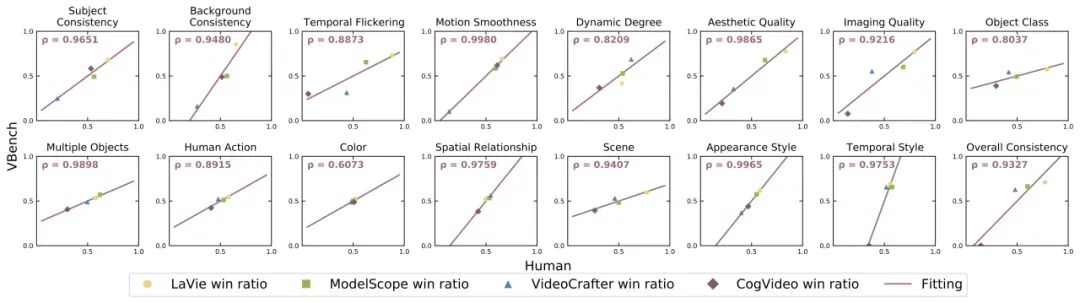
针对每个细分维度,联合团队测试了 VBench 评测结果与人工评测结果之间的相关度,发现 VBench 评测方法与人类感知具备较高的一致性。下图中,横轴代表不同维度的人工评测结果,纵轴则展示了 VBench 方法自动评测的结果,可见 VBench 在各个维度均与人类感知高度对齐。
全面开源,简单部署,一键安装
目前,VBench 已全面开源,且支持一键安装。详情可访问:https://github.com/Vchitect/VBench

同时,包含不同能力评测基准和不同场景内容评测基准的提示词体系(Prompt List)同步开源。详情可访问:https://github.com/Vchitect/VBench/tree/master/prompts
为视频生成模型能力提升带来有价值参考
不仅可对现有模型进行评测,VBench 还可以发现不同模型中可能存在的各种问题,为未来视频生成模型发展提供有价值的指标参考。基于 VBench 的评测结果,联合团队在论文中为视频生成模型能力提升提出了系列策略:
1、“时序连贯性”及“视频的动态程度”应同时提升
时序连贯性(Subject Consistency、Background Consistency、Motion Smoothness)与视频中运动的幅度(Dynamic Degree)之间有一定的权衡关系。部分模型在背景一致性和动作流畅度方面表现较好,但在动态程度方面得分较低,而另一部分模型则相反。
2、分场景内容进行评测,发掘不同模型潜力
部分模型在不同场景上表现出的性能存在较大差异,需深度挖掘模型在某个能力维度的上限,进而针对性地提升短板。
3、复杂运动类别中的时空表现均不佳
在空间上复杂度高的类别,模型美学质量维度得分往往低。这表明当前模型在处理时序建模方面仍然存在一定的不足,时序上的建模局限可能会导致空间上的模糊与扭曲,从而导致视频在时间和空间上的质量都不理想。
4、对于难生成的类别,提升数据量收益不大
研究人员对视频数据集 WebVid-10M 进行了统计,发现其中约有 26% 的数据与 “Human”有关,占比最高。然而,在评估结果中,“Human”类别却是模型表现最差的场景。表面在复杂的生成类别中,仅仅增加数据量可能不会对性能带来显著的改善。或许可通过引入相关的先验知识或控制,来指导模型学习。
5、提升数据质量应优先于数据量
“Food”类别在 WebVid-10M 中仅占据 11%,但在评测中几乎总是拥有最高的美学质量分数。这意味着,在百万量级数据的基础上,筛选或提升数据质量,比增加数据量更会对模型能力带来帮助。
6、待提升的能力:准确生成多物体,表现物体间的关系
多数视频生成模型在多对象生成(Multiple Objects)和空间关系(Spatial Relationship)方面不及图片生成模型,提升组合能力在未来研究中具备重要性。

















 1219
1219

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









