







在之前的课程中,我们分享的推理任务大部分都只由一个模型构成,但在真实的业务场景下,往往需要我们将多个模型放在一起去运行,才能获取到这个任务的最终预期结果。
因此,本次分享将通过一个简单的示例演示如何使用 OpenVINO™ 完成多模型串行的推理任务部署,看如何通过一个 Notebook 完成从车辆检测到车辆特征识别的具体任务的落地。
01 前期操作
打开 Jupyter Notebook,来到编号为218的任务中,可以看到这边有一张流程图,这张流程图明确说明了本次任务的开发流程。

首先,我们会有一张输入图片被送到前处理模块中,前处理模块会将原始图片的格式转化成后续模型所要求的输入格式,经过 resize 等前处理操作以后,图片会被送到后面的目标检测模型中,从而提取出该图片中每一辆车辆的位置信息。我们会通过位置信息进一步对原始画面进行截取,截取出车辆的特写图,再将这些特写图送到后续的识别模型中,识别出每一辆车所对应的具体特征,比如说它的颜色、它的车辆种类等。
之所以没有通过整张图片被送入到识别模型的形式去检测车辆特征,是因为如果我们将整张图片送到识别模型进行识别的话,如果这张图片中包含了很多辆车,此时会产生大量的误识别。
除此以外,我们也可以通过截取的方式,截取到一张满屏都是车辆的单张车辆特写图,进一步为我们后期模型去放大它的车辆特征表示,以提高它后面识别的精确性。
本次任务会用到 Open Model Zoo 中的车辆识别模型和一个检测模型。
检测模型
我们来看一下车辆检测模型,车辆检测模型其实是在原始画面中去找车辆的具体位置。它是一张标准的 bgr 图片,输出是由4个维度所构成的,前2个维度可以忽略不计,后面第3个维度200是指该模型对于单张图片它所能处理的被检测目标的上限,也就是我们最多可以检出200个目标。第4个维度的7是由图片的id、label信息、置信度,以及车辆在图片中的具体位置信息等所构成的。

识别模型
再看一下识别模型,这个识别模型主要是通过分类算法来检测出车的具体类别。它的输入同样是一张 bgr 通道的图片,输出有两个部分构成,一个是对于颜色类别的判断,一个是对于类型类别的判断。

02 回归代码
在这个输出示例中,我们会对画面中的每一辆车进行画框,然后标定它的分类结果。

Step 1:载入依赖库,并下载预训练模型
需要载入相应的依赖库,再通过 OpenVINO™ 的 Open Model Zoo 自带的模型下载工具下载我们的预训练模型。
Step 2:定义模型的初始化模块
我们需要定义模型的初始化模块。由于本次用到的都是来自 Open Model Zoo 中标准IR格式的模型,所以我们可以通过一个统一的模块来对这两个模型进行初始化,并且返回模型编译好的对象,我们也会通过 input_keys 和 output_keys 的值去找到输入和输出的相关的信息。

Step 3:获取模型对于输入图像的尺寸要求
除了对模型进行初始化以外,还要进一步的获取这两个模型对于输入图像的尺寸上要求,比如检测模型的输入高度、输入宽度,以及识别模型输入的高度和识别模型输入的宽度。
Step 4:定义画图功能
此外,我们还需要定义一个画图的功能,用来对最终结果在原始图片上进行可视化呈现。
Step 5:读取、下载并处理图片
接下来,我们需要去读取这样一张图片,从链接中下载图片,然后送到前处理模块中,对其进行通道转化和 resize 等等一些前处理操作。

完成前处理操作以后,车辆的图片就被展示出来了。肉眼可以看到这个图里是有一辆灰色的轿车,稍后我们看一下模型最终识别的效果是否准确。

Step 6:进一步完成推理输出
接着通过推理任务进一步完成对推理的输出。这是一个检测模型,通过我们刚才定义的输入图像,导入进来以后,并通过 output_keys 来获取它所对应的输出。
Step 7:过滤无效对象
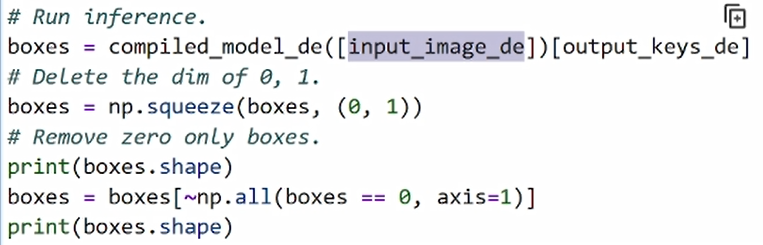
由于在 Open Model Zoo 的示例中,原始输出的前两个维度都是1,我们可以通过 squeeze 也就是降维的方法将前两个维度将其过滤。此外,由于我们的原始模型输出包含了200个对象,然而在真实画面中其实并没有200个对象,所以为了进一步缓解后期任务中去遍历这200个对象所带来的算力上的压力,我们需要采取措施对其进行二次过滤。

换而言之我们会将一些无效的 box 过滤掉,只是我们通过这种方式来判断 box的值是不是为0,如果是0的话,我们会把它进行一个筛选,最终我们会提取出其中两个有效的对象。其实这两个对象并不能代表这张图像中只有两个车辆目标,所以我们还要对它进行进一步的后处理操作。
Step 8:进行后处理操作
我们这边会定义一个 crop_images 的方法,用来将我们刚才所判断到的检测到的车辆位置信息在原始的画面中进行截取,此时我们需要通过置信度的方法,将一些置信度过低的车辆的目标对它进行过滤,最终将我们所检测到的车辆的具体的4个点的位置信息统统绑定在1个列表中。

Step 9:运行并提前相关信息
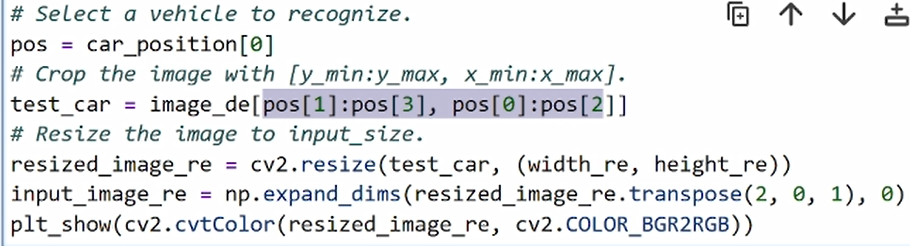
运行一下,然后我们可以找到这个列表中的第一个值,提取它所对应的4个点的位置信息,并在原始的画面中进行截取。
03 运行效果
我们可以看一下运行的效果。

将图片的具体特征进行识别
很明显这张图中只有一辆车,所以我们截取的第一个位置信息就是这辆车所对应的这张特写图,然后我们将这个特写图送到后面的识别网络中,对它的具体特征进行识别。因为识别网络是支持色彩和类别识别的,所以需要去定义色彩的分类范围,首先是不同的颜色,还有不同的车辆类别,然后我们进一步去匹配识别模型它的前处理操作。
因为识别模型会有两个输出结果,所以我们会通过这种方式分别去获取这两个分类结果所对应的输出,编号1就是色彩空间上的输出。

大家也不难发现,输出里后面两个维度的1其实也是无效值,所以我们也需要对其进行降维的操作,同样是通过 squeeze 方式对它任意降维,那么同样的方法我们也可以获取车辆类别的一个输出的结果。
此时,原始输出其实是由一串置信度所构成的,每一个值分别对应了不同类别所对应的置信度的大小。我们通过 argmax 方法可以将置信度最大的值所对应的编号给它求出来,这个时候才是我们最终想获取的结果信息。

运行效果:可视化呈现
可以看到,此时我们已经检测出这个车的颜色是 gray,它的类别是 car。为了进一步在我们的原始图像做一个可视化的展示,我们还需要将刚才输出的这个标签放到我们画面中。方法比较简单,大家可以简单的了解一下这个代码。
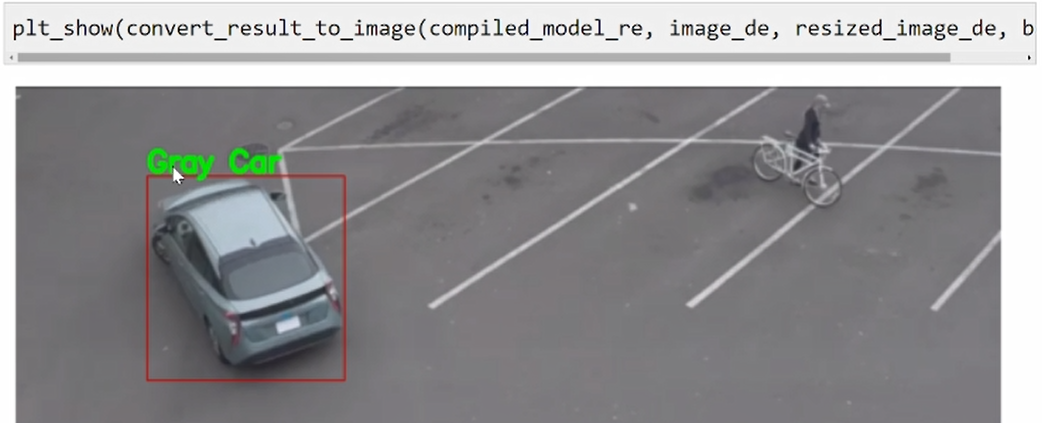
可以看到,我们首先在画面中画了一个框,然后将 gray 和 car 的标签信息放在框上。
本次课程分享到这里就结束啦,有疑惑的同学欢迎随时私信Nono哦!















 4984
4984











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









