






 本文探讨了大模型评测的挑战,如全面性、成本和数据污染,介绍了不同类型的模型评测策略,以及客观与主观评测的区别。重点提到了提示词工程在提高评测真实性的应用,并以OpenCompass为例,展示了如何评估实习模型在特定数据集上的性能。
本文探讨了大模型评测的挑战,如全面性、成本和数据污染,介绍了不同类型的模型评测策略,以及客观与主观评测的区别。重点提到了提示词工程在提高评测真实性的应用,并以OpenCompass为例,展示了如何评估实习模型在特定数据集上的性能。
-
教程部分
-
评测背景,挑战与机遇

-
通过评测促进模型发展,了解模型的优点和缺点。
-
聚焦垂直领域,如医疗金融,测试模型在这些领域的能力。
-
构造高质量的中文评测体系,促进中文社区的大模型发展。
-
根据评测结果反补模型的迭代,提升模型的能力。
-
持续拓展评测能力维度,如数学代码智能体等。
2)挑战
-
大模型的评测面临全面性的挑战,需要构造一个能够扩展且覆盖面广的能力维度体系。
-
评测大模型的成本较高,包括GPU资源和人工打分的成本。
-
存在数据污染的问题,需要研发数据污染检测技术。
-
鲁棒性是另一个挑战,需要解决模型对提示词的敏感性。

如何测评对象:
-
模型评测根据类型划分,包括基座模型和SFT微调模型等。
-
评测基座模型需要设计特定方法。
-
评测开源的SFT模型需要考虑经过处理后的效果。
-
评测API模型需要发送网络请求并分析回复结果。
-
根据模型类型的不同,设定不同的评测方法。

主观和客观评价:
-
评测分为客观评测和主观评测。
-
客观评测包括问答题、选择题等,有固定答案。
-
主观评测包括开放性问答题,需要人工评价或模型评价。
-
主观评测可以采用打分或直接比较模型回答的方式。
-
评测方式的选择根据题目特点和成本考虑。


提示词工程:
-
提示词工程:对题目进行丰富,提供更具体的细节和要求。
-
模型推理:使用模型对丰富后的题目进行评测。
-
反映模型性能:通过丰富题目后的评测结果更真实地反映模型的性能
-
集中分数:避免泛泛而谈,导致分数偏向集中。
-
人工智能全面介绍:作为一个例子,说明题目宽泛缺乏细节的问题。

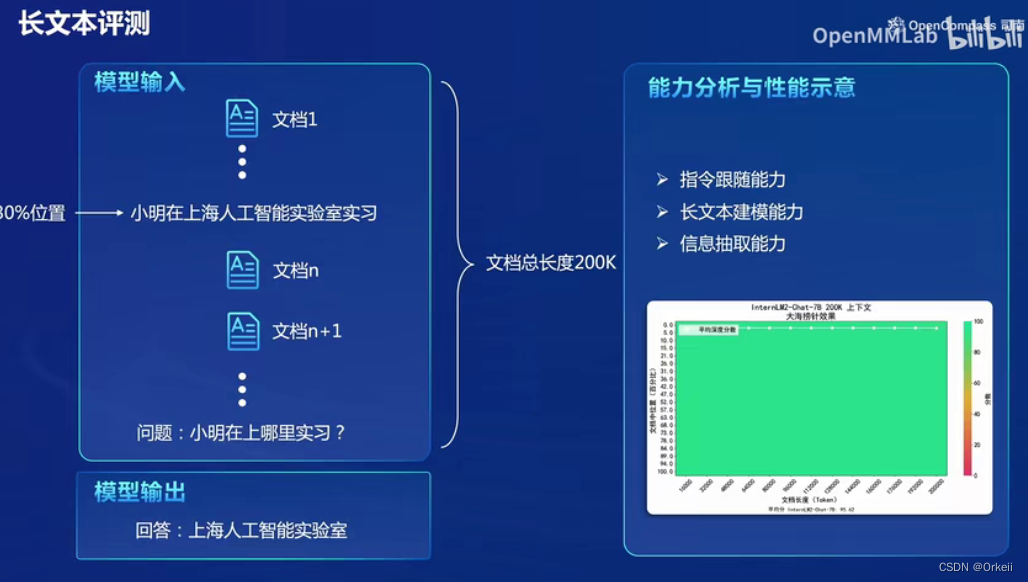
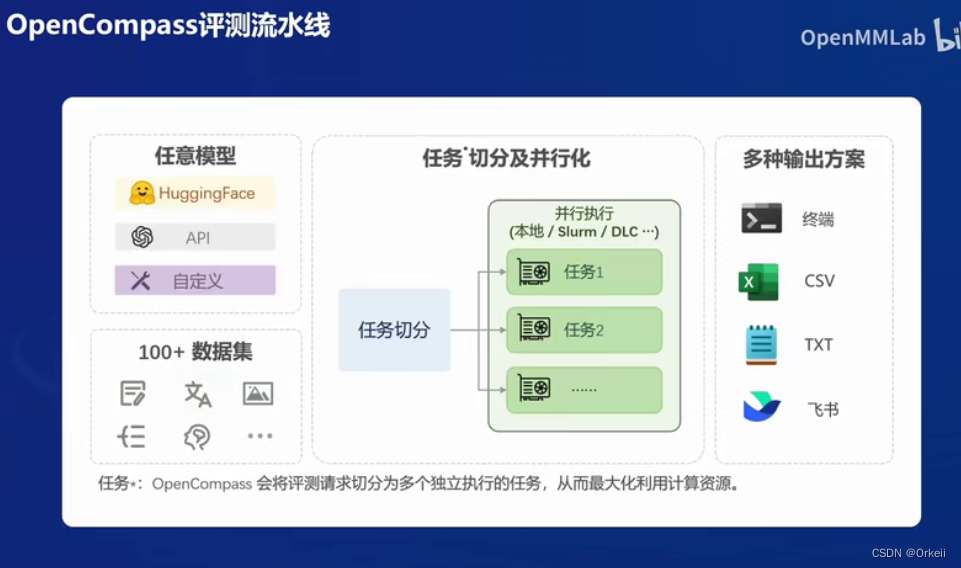

作业:
-
使用 OpenCompass 评测 internlm2-chat-1_8b 模型在 C-Eval 数据集上的性能
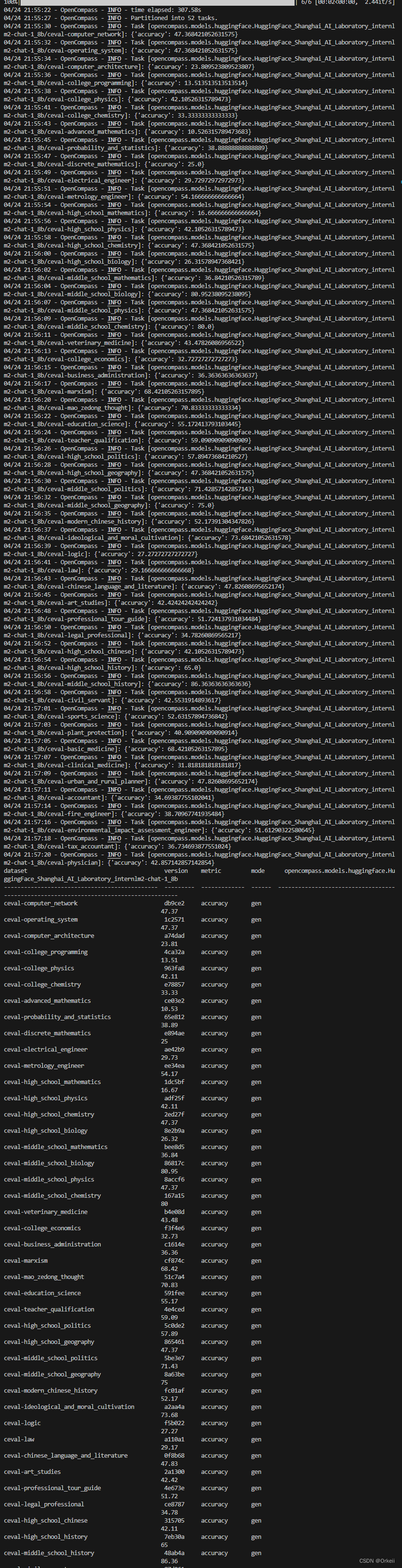















 275
275

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









