







首先看到这个题目,我们就会想到为什么决策树要剪枝?答案就是如果一棵决策树完全生长,那么这棵决策树就很有可能面临过拟合的问题。完全生长的决策树所对应的每个叶节点中只会包含一个样本,这样决策树就是过拟合的,所以我们就需要对这种决策树进行剪枝操作来提升我们决策树模型的泛化能力。
这也印证了一个原则:奥卡姆剃刀原理。这个原理最简单的描述就是“如无必要,勿增实体”,意思就是说如果多种模型或者方法都能够解释或者实现一种结果和现象,那么我们就选取最简单的那个模型或者方法。这个也正好与机器学习消除过拟合的思想是一致的。有一个示例,就是托勒密是地心说的代表人物,而哥白尼是日心说的代表人物,而当时地心说和日心说都能够解释当时的天文现象,但是地心说的理论比日心说的理论要复杂很多,根据奥卡姆剃刀原理,我们应该更倾向于哥白尼的日心说,后来也事实证明,日心说也是正确的。
说完了奥卡姆剃刀,我们再来说剪枝,一般来说,决策树的剪枝主要有两种方法,预剪枝(Pre-Pruning)和后剪枝(Post-Pruning),这里我参考了《百面机器学习》这本书的内容。
预剪枝
预剪枝的思想是在树种节点进行生长之前,先计算当前的划分是否能提升模型的泛化能力,如果不能的话,那么就不在进行子树的生长。一般来说,预剪枝对于何时停止决策树的生长有下面这几种方法:
1.当决策树达到一定的深度的时候,停止生长;
2.当到达当前节点的样本数量小于某个阈值的时候,停止树的生长;
3.计算决策树每一次分裂对测试集的准确度是否提升,当没有提升或者提升程度小于某个阈值的时候,则停止决策树的生长;
预剪枝具有思想直接、算法简单、效率高等特点,适合解决大规模的问题,但是如何准确地估计何时停止决策树的生长,针对不同的问题应该分别考虑,需要一定的经验判断。
后剪枝
后剪枝的思想其实就是让算法生成一棵完全生长的决策树,然后从底层向上计算是否剪枝,如果需要剪枝,剪枝过程就是把子树删除,用一个叶子节点替代,该节点的类别按照多数投票的方法进行判断。同样的,后剪枝也可以通过在测试集上的准确率进行判断,如果剪枝后的准确率有所提升或者没有降低,那么我们就可以进行剪枝。一般来说,后剪枝比预剪枝通常得到的决策树模型的泛化能力更好,但是时间上的开销更大。当然,后剪枝算法也有很多,这些后剪枝算法各有利弊,只不过是关注了不同的优化角度。这里我们举一个CART的CCP代价复杂度剪枝的例子,代价复杂度剪枝主要分成以下两个步骤:
1.从完整的决策树
T
0
{T_0}
T0开始,生成一个子树序列
{
T
0
,
T
1
,
T
2
,
.
.
.
,
T
n
}
{\text{\{ }}{{\text{T}}_0}{\text{,}}{{\text{T}}_1}{\text{,}}{{\text{T}}_2}{\text{,}}...{\text{,}}{{\text{T}}_n}{\text{\} }}
{ T0,T1,T2,...,Tn} ,其中
T
i
+
1
{T_{i + 1}}
Ti+1是有
T
i
{T_i}
Ti所生成,
T
n
{T_n}
Tn为数据的跟节点。
2.在子树序列中,根据真实的误差选择最佳的决策树。从
T
0
{T_0}
T0开始,每次裁剪
T
i
{T_i}
Ti中关于训练数据集合误差增加最小的分支得到
T
i
+
1
{T_{i+1}}
Ti+1。具体地说,当一棵树
T
T
T在节点
t
t
t剪枝的时候,它的误差可以用
R
(
t
)
−
R
(
T
t
)
R(t) - R({T_t})
R(t)−R(Tt)来表示,其中
R
(
t
)
R(t)
R(t)表示进行剪枝之后的该节点误差,
R
(
T
t
)
R({T_t})
R(Tt)表示未进行剪枝时子树
T
t
T_t
Tt的误差,通常我们用
∣
L
(
T
t
)
∣
|L({T_t})|
∣L(Tt)∣表示子树
T
t
T_t
Tt的叶子节点个数,那么树在节点
t
t
t处剪枝后的误差增加率可以表示为:
α
=
R
(
t
)
−
R
(
T
t
)
∣
L
(
T
t
)
∣
−
1
\alpha = \frac{{R(t) - R({T_t})}}{{|L({T_t})| - 1}}
α=∣L(Tt)∣−1R(t)−R(Tt)
我们来举一个例子,假设我们有
T
0
T_0
T0这一颗决策树,我们来对它进行剪枝:
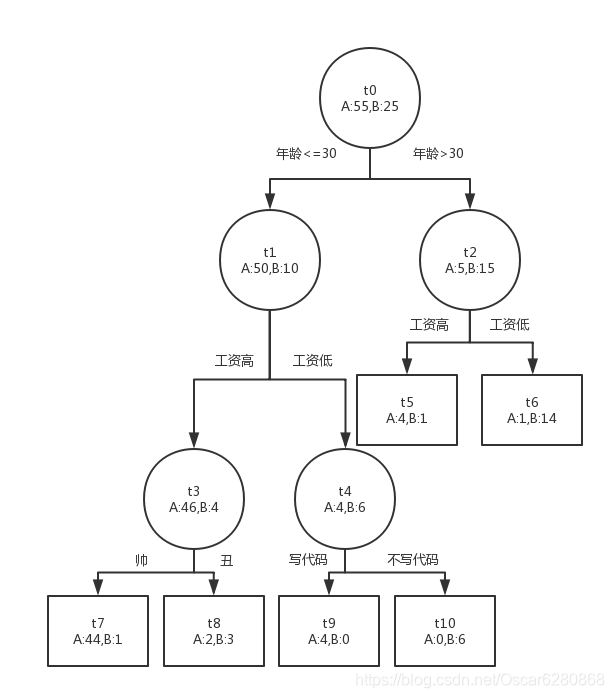
上面是一个女孩子们是否愿意相亲见面的一棵决策树,我们如何对这棵决策树进行剪枝呢?首先我们根据上述的误差增加率公式对每个节点的误差增加率进行计算:
α
(
t
0
)
=
25
−
(
1
+
1
+
1
+
2
+
0
+
0
)
6
−
1
=
4
\alpha ({t_0}) = \frac{{25 - (1 + 1 + 1 + 2 + 0 + 0)}}{{6 - 1}} = 4
α(t0)=6−125−(1+1+1+2+0+0)=4
α
(
t
1
)
=
10
−
(
1
+
2
+
0
+
0
)
4
−
1
=
2.33
\alpha ({t_1}) = \frac{{10 - (1 + 2 + 0 + 0)}}{{4 - 1}} = 2.33
α(t1)=4−110−(1+2+0+0)=2.33
α
(
t
2
)
=
5
−
(
1
+
1
)
2
−
1
=
3
\alpha ({t_2}) = \frac{{5 - (1 + 1)}}{{2 - 1}} = 3
α(t2)=2−15−(1+1)=3
α
(
t
3
)
=
4
−
(
1
+
2
)
2
−
1
=
1
\alpha ({t_3}) = \frac{{4 - (1 + 2)}}{{2 - 1}} = 1
α(t3)=2−14−(1+2)=1
α
(
t
4
)
=
4
−
(
0
+
0
)
2
−
1
=
4
\alpha ({t_4}) = \frac{{4 - (0 + 0)}}{{2 - 1}} = 4
α(t4)=2−14−(0+0)=4
由上述的计算我们可以知道
t
3
t_3
t3的误差增加率最低,我们就对
t
3
t_3
t3节点进行剪枝,剪枝完成之后如下图所示:
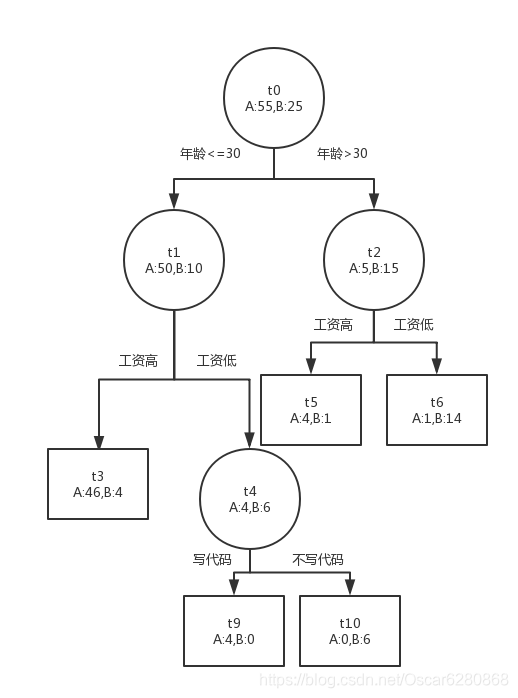
那么这个时候
t
3
t_3
t3没有了子叶,自身由节点变成了子叶。我们再继续上述的计算:
α
(
t
1
)
=
10
−
(
4
+
0
+
0
)
3
−
1
=
3
\alpha ({t_1}) = \frac{{10 - (4 + 0 + 0)}}{{3 - 1}} = 3
α(t1)=3−110−(4+0+0)=3
α
(
t
2
)
=
5
−
(
1
+
1
)
2
−
1
=
3
\alpha ({t_2}) = \frac{{5 - (1 + 1)}}{{2 - 1}} = 3
α(t2)=2−15−(1+1)=3
α
(
t
4
)
=
4
−
(
0
+
0
)
2
−
1
=
4
\alpha ({t_4}) = \frac{{4 - (0 + 0)}}{{2 - 1}} = 4
α(t4)=2−14−(0+0)=4
所以我们这个时候应该对
t
1
t_1
t1或者
t
2
t_2
t2节点进行剪枝:
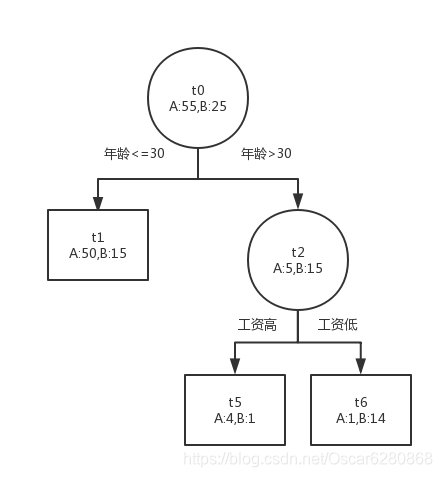
通过这样的剪枝方法,我们可以将完全生长的决策树进行剪枝,直到不能剪了为止,我们可以在生成决策树之前,留一部分数据进行测试验证,将我们每次剪枝得到的决策树拿去验证,选取效果最好的那颗决策树就可以了。所谓剪枝的目的,就是为了保留决策树种最主要的部分,将多余的部分去除,达到同样的分类或者回归的效果。希望这篇文章能够对大家决策树剪枝方面的理解有所帮助,谢谢。














 402
402











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









