







DataFrame对象是Pandas库中使用最广、方法最多、功能最强大的一种数据结构。可以说,要想精通Pandas的使用,熟悉DataFrame的操作必不可少。
实例化与索引切片
结构与实例化
之前介绍过Series对象,可以将其理解成一个有灵活索引的一维数组,那么DataFrame就可以理解成一个有灵活行索引和列索引的二维数组。
与Series类似,DataFrame对象可以用二维数组、字典列表来初始化,还可以用Series对象来初始化。
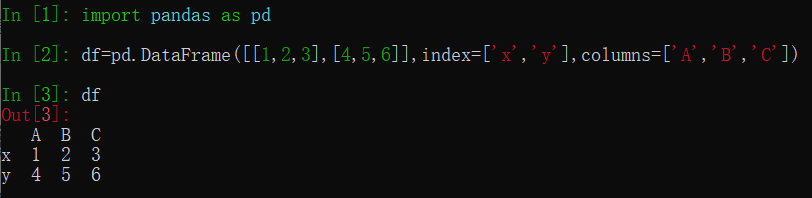
其初始化参数中比较重要的就是index和columns。通过上面的图可以看出,index传入的是行的索引,而columns传入的是列的索引。

使用字典列表初始化时需要注意列表中各字典的键必须相同。生成的DataFrame将以字典的键值作为列索引,行索引则是0…n-1的整数。
使用Series初始化时,DataFrame可以被看做Series的排列。使用字典的形式传入Series对象,可以指定各Series的列名。同样也要求Series的索引相同。

索引与切片
虽然DataFrame的结构是二维的,但它索引的方式与二维数组完全不同。当使用dataframe[index]这样的方式进行索引,将会获取列索引为index的列。

获取单个列时返回的是Series对象,印证了之前可以把DataFrame看成Series的排列的说法。只获取单列时,也可以使用df.index这种类似属性的方式,但这种方式只支持纯字符串列名的列,而且列名不能与DataFrame固有的属性和方法重名。因此建议尽量不使用这种方法来获取某一列。
DataFrame同样支持布尔索引和花式索引。

布尔索引的结果是各列分别布尔索引的结果的拼接。
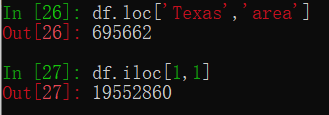
如果要获取某一行的数据,一种方法是使用values属性:

此时返回的是Numpy的ndarray对象。更常见的是使用在Series中也介绍过的索引器。其用法与Series类似。

以上都是只使用行索引或列索引,如果要同时使用行索引和列索引,则必须使用索引器,否则会报错。
在这之上的切片就很自然了:

同样是隐式切片含头不含尾,显式切片两边都包含。
数值运算
因为Pandas是建立在Numpy的基础上的,所以DataFrame和Series之间的运算与ndarray基本相同,基础运算都是逐个元素的运算。
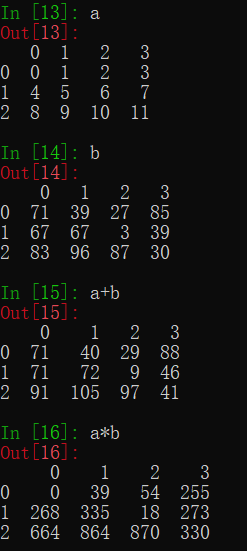
不过DataFrame之间和Series之间运算并不会像ndarray那样在数组形状不同时进行广播,而是会将索引对齐进行运算,两对象会被缺失值(NaN)填充成相同形状再进行运算,而缺失值与任何值运算结果都为缺失值。
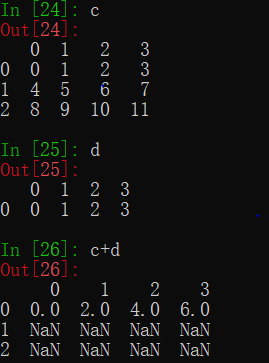
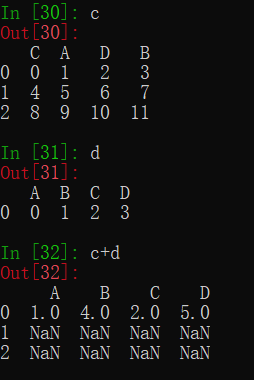
而当DataFrame对象与Series对象运算时,则会同时索引对齐并广播。
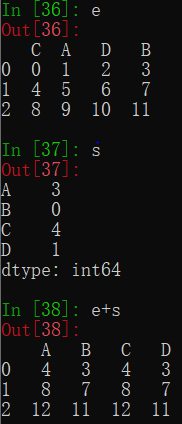
除了直接使用运算符,还可以用Dataframe的方法来运算。例如a+b就可以用a.add(b)代替。这样做的好处是可以使用一些参数来规定运算的额外规则。例如c.add(d,fill_value=0)可在相加前将两对象用0而不是缺失值填充为相同形状。
| Python运算符 | Pandas方法 |
|---|---|
| + | add() |
| - | sub()、substract() |
| * | mul()、multiply() |
| / | truediv()、div()、divide() |
| // | floordiv() |
| % | mod() |
| ** | pow() |
统计方法与分组聚合
统计方法
与Series相同,DataFrame也有许多统计用的方法,并且大部分名称相同。不同的是,因为DataFrame是二维,因此统计的结果基本都是一维的Series,并且和ndarray一样可以通过axis参数指定统计的方向。
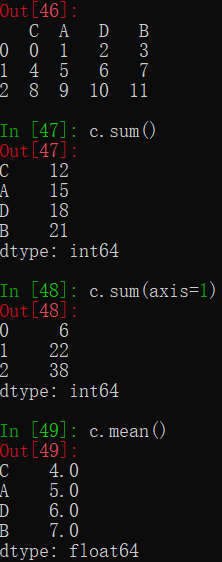
其他方法类似,不再展示。
分组
DataFrame还有一类常用而且功能强大的统计方法,就是分组聚合。
分组聚合的流程主要有三步:
- 分割步骤:将DataFrame按照指定的键分割成若干组;
- 应用步骤:对每个组应用函数,通常是累计、转换或过滤函数;
- 组合步骤:将每一组的结果合并成一个输出数组。

通常我们将数据分成多个集合的操作称之为分组,Pandas中使用groupby()函数来实现分组操作。
对分组后的子集进行数值运算时,不是数值的列会自动过滤。
data = {'level': [1, 2, 2, 3, 2, 4],
'year': [2014, 2015, 2014, 2014, 2015, 2017],
'key': ["a", "b", "c", "d", "e", "f"],
'value': [0.5, 0.9, 2.1, 1.5, 0.5, 0.1]
}
df = pd.DataFrame(data)
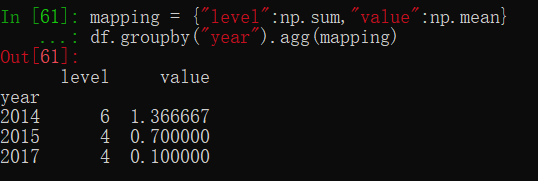
df.groupby("year") #单列分组 返回的是一个 DataFrameGroupBy 对象
df.groupby(["year","key"]) #多列分组
还可以使用类似花式索引的方法进行分组。
df["year"].groupby(df["level"]).sum() #df的 A 列(year)根据 B列(level) 进行分组

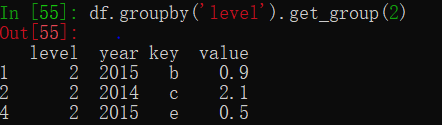
分组后返回的是DataFrameGroupBy对象,无法直接读取其中的数据,可以通过get_group()方法来获取某一分组。
df.groupby("level").get_group(2) # 按level值分组,获取level值为2的那一组
GroupBy对象支持迭代,可以产生一组二元元组(由分组名和数据块组成)。
for name,data in df.groupby("level"):
print(name)
print(data)

聚合
聚合函数为每个组返回单个聚合值。当创建了DataFrameGroupBy对象,就可以对分组数据执行多个聚合操作。比较常用的是通过聚合函数或等效的agg方法聚合。常用的聚合函数如下表:
| 函数名 | 说明 |
|---|---|
| count | 分组中非空值的数量 |
| sum | 非空值的和 |
| mean | 非空值的平均值 |
| median | 非空值的中位数 |
| std、var | 无偏标准差和方差 |
| min、max | 非空值的最小和最大值 |
| prod | 非空值的积 |
| first、last | 第一个和最后一个非空值 |
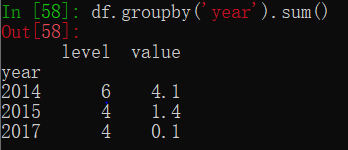
df.groupby("year").agg([np.sum,np.mean,np.std]) # 应用多个聚合函数
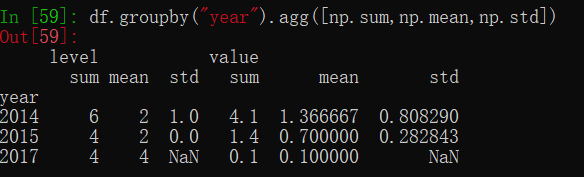
# 使用自定义函数聚合
def result(df):
return df.max() - df.min()
df.groupby("year").agg(result) #求每一组最大值与最小值的差
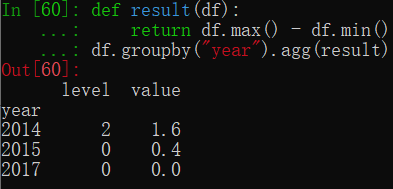
mapping = {"level":np.sum,"value":np.mean}
df.groupby("year").agg(mapping) # 对不同列使用不同聚合函数
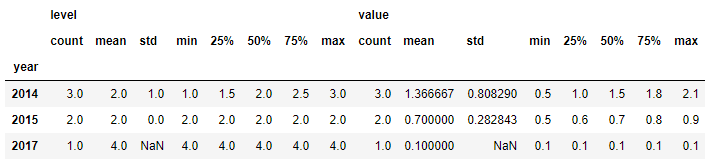
另外一个常用的方法,describe()可以审计数据集分布的中心趋势,分散和形状,不包括NaN值。















 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









