







【0】README
1)本文旨在介绍算法设计技巧包括 贪婪算法、分治算法、动态规划 以及相关的荔枝等;
【1】贪婪算法
1)intro: 贪婪算法是分阶段进行的,在每个阶段,可以认为所做的决定是最好的,而不考虑将来的后果;
2)我们已经看到过的贪婪算法有:
alg1)迪杰斯特拉算法:该算法计算单源(起点固定)有权最短路径,使用到了 二叉堆优先来选取权值最小的邻接顶点,因为每次都选择权值最小的邻接顶点作为输出,当然 是最好的决定了,满足贪婪算法的特性;
alg2)普利姆算法:该算法用于在无向有权图中寻找 最小生成树(该树是一个连通图,且图中所含边的权值最小),普利姆算法是基于迪杰斯特拉算法的,且在普利姆算法过程中,有且只有一个连通图;
alg3)克鲁斯卡尔算法:同普利姆算法一样,该算法用于在无向有权图中寻找最小生成树;与普利姆算法不同的是,该算法连续地按照最小的全选择边,并且当所选的边不产生圈时就把它作为取定的边;
【1.1】贪婪算法的经典荔枝——(找零问题):说某商店的硬币只有 1角,5角,10角,12角;
1)problem+solutions:
1.1)problem:那现在如果要找15角的零钱,且要求 硬币数量最少,应该怎么找?
1.2)solutions:方法一:按照贪婪算法的定义,则首先选择一个12角,3个1角 ,总硬币数量为4个;方法二:其实我们也可以选择一个10角 和 一个5角来找零钱,没必要一开始就选择币值最大的硬币;
2)总结:从上面找零钱的贪婪算法荔枝就知道,贪婪算法并不总能给出最优的解决方案;
【1.2】贪婪算法的荔枝——Huffman编码 Huffman 编码源码
0)哈夫曼编码的应用: 文件压缩,用0,1 代码表示文件中的字母;要知道一般的字符编码都是等长的,见下图:
(干货——哈夫曼编码的应用很重要,因为伟哥说他电话面试的时候, ali 的 项目经理有问到,这也是为什么我把它写在了 开头的原因)
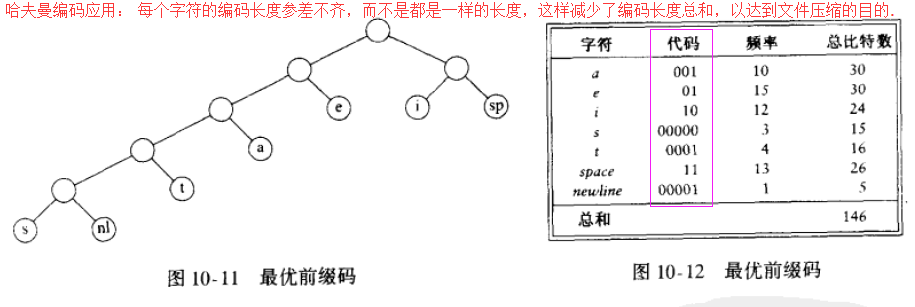
1)哈夫曼算法描述:该算法是对一个由树组成的森林进行的(因为我可以把一个顶点看做一个树);
step1)起初,每个节点都看做一颗树,该树(根)的权值等于其树叶的频率和;(频率?就是指一个字母出现的次数/总的 字母出现次数,因为为了减少编码长度,频率小的应该尽可能地远离树根,频率大的应该尽可能地接近树根)
step2)任意选取最小权的两颗树 t1 和 t2,并任意形成以 t1 和 t2 为子树的新树,将这样的过程进行(节点数-1)次,即 对 step2)循环执行(节点数-1)次;(这里也符合贪婪算法的定义,即每次哈夫曼算法都要选择权值最小的树合并以建立哈夫曼编码树,既然每次都选择权值最小的树,那么在每个阶段,这个决定是最好的)
step3)最终的树就是 最优哈夫曼编码树,遍历该哈夫曼树,左边上0,右边上1 即可;
2)看了描述,想必你也猜到了,哈夫曼算法用到了二叉堆优先队列(小根堆),因为它要选取权值最小的树;(堆节点使用了 结构体指针类型,下面会讲到为什么会选择结构体指针类型而不选结构体类型或 int基本类型作为堆节点类型)
3)将哈夫曼算法 与 二叉堆优先队列结合起来 阐述源码的实现steps:
补充)我们先看节点类型
#define ElementNum 7
// 堆节点类型是 结构体指针类型 而不是单纯的 int类型.
#define ElementType HeapNode
// 二叉堆的堆节点类型为 结构体指针类型.
struct HeapNode;
typedef struct HeapNode* HeapNode;
struct HeapNode
{
int value; // 字符出现的频率
char flag; // 字符标识
HeapNode left;
HeapNode right;
};
// 二叉堆的结构体.
struct BinaryHeap;
typedef struct BinaryHeap *BinaryHeap;
struct BinaryHeap
{
int capacity;
int size;
HeapNode* array; // 堆节点类型是结构体指针. 而优先队列是结构体指针数组.
};
struct HuffmanCode;
typedef struct HuffmanCode* HuffmanCode;
struct HuffmanCode
{
char flag;
char code[ElementNum-2+1]; // 因为还有 '\0'
// 为什么 code的长度是ElementNum-2,因为 如元素个数是7,其最大高度为5.
};step1)将 森林中的树标识(字符)和树频率 插入堆;
char flag[ElementNum] = {'a', 'e', 'i', 's', 't', 'p', 'n'};
int frequency[ElementNum] = {10, 15, 12, 3, 4, 13, 1};
ElementType root, temp1, temp2;
int i;
BinaryHeap heap;
// step1: 建堆.
heap = initBinaryHeap(ElementNum+1); // 因为0号下标不用.
if(heap==NULL)
{
return ;
}
for(i=0; i<ElementNum; i++)
{
insert(createHeapNode(frequency[i], flag[i]), heap);
}
printBinaryHeap(heap);
// step1: over.step2)只要堆不为空,连续两次删除堆中最小元素已选择权值最小的树,并构建哈夫曼树;构建后再次插入到小根堆中;继续step2,直到堆为空,退出step2;
// step2: 依次删除堆中最小元素 以 构建哈夫曼树.
while(!isEmpty(heap))
{
temp1 = deleteMin(heap);
if(!isEmpty(heap))
{
temp2 = deleteMin(heap);
root = createHeapNode(temp1->value+temp2->value, ' ');
root->right = temp1; // 优先发右边.
root->left = temp2;
// 合并后,其根还要插入堆.
insert(root, heap);
}
}
// step2 over.
// step3 save huffman code. huffmanCodeRecursion(root, 0); // step3 over. // 记录完 哈夫曼编码后,打印编码效果. for(i=0; i<ElementNum; i++) { printf("\n code[%c] = %s", codes[i].flag, codes[i].code); }// (递归实现)记录每个字符的哈夫曼编码;root == 哈夫曼树根, depth == 树的深度, 从0开始取. void huffmanCodeRecursion(HeapNode root, int depth) { if(root->left) { code[depth] = '0'; code[depth+1] = '\0'; huffmanCodeRecursion(root->left, depth+1); } if(root->right) { code[depth] = '1'; code[depth+1] = '\0'; huffmanCodeRecursion(root->right, depth+1); } else { codes[counter].flag = root->flag; copyCodes(code, codes[counter++].code); // printf("%s\n", code); // 取消本行注释可以调试程序. } }
4)测试用例如下:
void main()
{
char flag[ElementNum] = {'a', 'e', 'i', 's', 't', 'p', 'n'};
int frequency[ElementNum] = {10, 15, 12, 3, 4, 13, 1};
ElementType root, temp1, temp2;
int i;
BinaryHeap heap;
// step1: 建堆.
heap = initBinaryHeap(ElementNum+1); // 因为0号下标不用.
if(heap==NULL)
{
return ;
}
for(i=0; i<ElementNum; i++)
{
insert(createHeapNode(frequency[i], flag[i]), heap);
}
printBinaryHeap(heap);
// step1: over.
// step2: 依次删除堆中最小元素 以 构建哈夫曼树.
while(!isEmpty(heap))
{
temp1 = deleteMin(heap);
if(!isEmpty(heap))
{
temp2 = deleteMin(heap);
root = createHeapNode(temp1->value+temp2->value, ' ');
root->right = temp1; // 优先发右边.
root->left = temp2;
// 合并后,其根还要插入堆.
insert(root, heap);
}
}
// step2 over.
printf("\n === nodes in huffman tree are as follows.===\n");
printPreorder(root, 1);
// step3 save huffman code.
huffmanCodeRecursion(root, 0);
// step3 over.
// 记录完 哈夫曼编码后,打印编码效果.
for(i=0; i<ElementNum; i++)
{
printf("\n code[%c] = %s", codes[i].flag, codes[i].code);
}
printf("\n");
}

【1.3】近似装箱问题
1)intro:有两种版本的装箱问题:第一种是联机装箱问题,必须将每一件物品放入一个箱子后才处理下一件物品;第二种是脱机装箱问题;
2)补充)联机算法和脱机算法:
2.1)联机算法:说联机算法就好比 英语听力考试(或口语考试),做完这道题,才能做下一题;
2.2)脱机算法:说脱机算法就好比 一般性考试,只需要在规定时间内完成即可,做题没有先后顺序;
【1.3.1】联机装箱算法
1)几种联机装箱算法介绍
算法1)下项适合算法:效果最差,只要当前箱子无法盛放物品,就开辟一个新箱子;
算法2)首次适合算法: 从头到尾扫描所有箱子,并把物品放入足够盛下它的第一个箱子中。如没有箱子可以盛放,再开辟新箱子;
算法3)最佳适合算法: 该方法不是把一项新物品放入所发现的能容纳它的箱子,而是放到 所有箱子中能够容纳它的最满箱子;
2)联机算法的主要问题:在于将 大项物品装箱困难,特别是当他们在输入的晚期出现的时候。围绕这个问题的自然方法是将各项物品排序,把最大的物品放在最先;这就要借鉴 脱机算法的idea了;
【1.3.2】脱机装箱算法
1)intro: 脱机装箱算法 说白了:就是将各项物品排序,吧最大的物品放在最前面;然后再进行装箱;可能你也猜到了,因为 脱机装箱问题 需要吧 物品排序,然后选择 最大的物品;这就要用到 二叉堆优先队列了(二叉堆是大根堆);
2)几种脱机装箱算法介绍和源码实现
补充)个人觉得,碰到一个问题,要寻找解决问题的算法,首先要确定数据类型,即结构体的成员,这个很重要,会省去很多不必要的麻烦;下面看 装箱问题的结构体类型。
// 堆节点类型为 int. #define ElementType int #define Error(str) printf("\n error: %s \n",str) #define ElementNum 7 #define SUM 10 // 箱子的最大容量是10 struct BinaryHeap; typedef struct BinaryHeap *BinaryHeap; struct BinaryHeap { int capacity; int size; ElementType *array; }; // 货物(箱子)结构体. struct Good; typedef struct Good* Good; typedef struct Good* Box; struct Good { int value; // 这里的value 对于货物 指代 货物重量. // 这里的value 对于箱子 指代 箱子的剩余容量. Good next; }; // 定义一个仓库结构体, 包含多个箱子. struct Warehouse; // 仓库可以看多箱子数组. typedef struct Warehouse* Warehouse; struct Warehouse { int capacity; int size; Box* array; // 多个箱子. };
算法1)首次适合递减算法:物品排序后,应用首次适合算法 得到 首次适合递减算法;首次适合递减算法源码
step1)基于物品的重量建立大根堆;
// step1: 建立大根堆. heap = initBinaryHeap(ElementNum+1); // 堆的下标0的元素不用,这是老生常谈了. if(heap==NULL) { return ; } for(i=0; i<ElementNum; i++) { insert(goods[i], heap); } //step1 over.step2)首次适合递减算法
// step2: 应用首次适合递减算法. printf("\n\t === review for first fit decreasing alg ===\n"); first_fit_decreasing(heap, warehouse);
测试用例如下:// 首次适合递减算法.(把物品放入能够盛下它的第一个箱子中) void first_fit_decreasing(BinaryHeap heap, struct Warehouse warehouse) { int i, weight; Good temp; Box* array = warehouse.array; // step2: 删除大根堆中最大元素.用删除的元素 添加到 箱子中. while(!isEmpty(heap)) { i=0; weight = deleteMin(heap); while(weight > array[i++]->value); if(array[i-1]->value == SUM) { warehouse.size++; } temp = array[i-1]; // 因为上面的 while循环多加了一个1. while(temp->next) { temp = temp->next; } temp->next = createGood(weight); // 因为i 自加了一次, 所以要减1. if(temp->next) // 如果内存分配成功. { array[i-1]->value -= weight; } } printBoxes(warehouse); }void main() { int i; int goods[] = {2, 5, 4, 7, 1, 3, 8}; BinaryHeap heap; struct Warehouse warehouse; initWarehouse(&warehouse, ElementNum); // 初始化仓库(箱子数组); // step1: 建立大根堆. heap = initBinaryHeap(ElementNum+1); // 堆的下标0的元素不用,这是老生常谈了. if(heap==NULL) { return ; } for(i=0; i<ElementNum; i++) { insert(goods[i], heap); } //step1 over. printBinaryHeap(heap); // step2: 应用首次适合递减算法. printf("\n\t === review for first fit decreasing alg ===\n"); first_fit_decreasing(heap, warehouse); }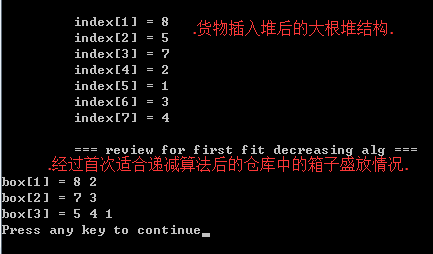
算法2)最佳适合递减算法:物品排序后,应用最佳适合算法 得到 最佳适合递减算法;最佳的意思就是,在可以存放物品的前提下,物品被存放后,箱子的剩余容量最小的为最佳,或存放后箱子最满的为最佳;(数据类型同 首次适合递减算法) 最佳适合递减算法源码
step1)同样,建立大根堆
step2)应用最佳适合递减算法// step1: 建立大根堆. heap = initBinaryHeap(ElementNum+1); // 堆的下标0的元素不用,这是老生常谈了. if(heap==NULL) { return ; } for(i=0; i<ElementNum; i++) { insert(goods[i], heap); } //step1 over.
// 应用最佳适合递减算法.(注意是最佳不是首次适合递减算法) printf("\n\t === review for best fit decreasing alg ===\n"); best_fit_decreasing(heap, warehouse);测试用例// 最佳适合递减算法.(首先遍历箱子,找出该货物存放后,对应箱子的剩余容量最小的箱子) void best_fit_decreasing(BinaryHeap heap, struct Warehouse warehouse) { int i, weight, diff; Box temp; Box* array = warehouse.array; int minIndex=-1, minValue = SUM; // step2: 删除大根堆中最大元素.用删除的元素 添加到 箱子中. while(!isEmpty(heap)) { weight = deleteMin(heap); for(i=0; i<warehouse.size;i++) // 遍历仓库中的所有箱子. { diff = array[i]->value - weight; // diff 此刻表示差值. if(diff>=0 && diff <= minValue) // key if condition. { minValue = diff; minIndex = i; if(diff==0) //当差值等于0时,表示最佳的. { break; } } } // 所有箱子遍历over. if(minValue == SUM) // 没有找到适合的箱子,需要开辟一个新箱子(size++). { minIndex = i; warehouse.size++; } // 装货入箱. temp = array[minIndex]; while(temp->next) { temp = temp->next; } temp->next = createGood(weight); if(temp->next) // 如果内存分配成功. { array[minIndex]->value -= weight; } // 装货over. //printBoxes(warehouse); // 取消这行注释用于调试. } printBoxes(warehouse); }void main() { int i; int goods[] = {2, 5, 4, 7, 1, 3, 8}; BinaryHeap heap; struct Warehouse warehouse; initWarehouse(&warehouse, ElementNum); // 初始化仓库(箱子数组); // step1: 建立大根堆. heap = initBinaryHeap(ElementNum+1); // 堆的下标0的元素不用,这是老生常谈了. if(heap==NULL) { return ; } for(i=0; i<ElementNum; i++) { insert(goods[i], heap); } //step1 over. printBinaryHeap(heap); // 应用最佳适合递减算法.(注意是最佳不是首次适合递减算法) printf("\n\t === review for best fit decreasing alg ===\n"); best_fit_decreasing(heap, warehouse); }
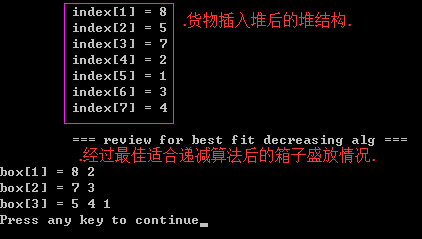
Attention)写代码,要先写 首次适合递减alg 的源码,因为它要简单些,然后再写 最佳适合递减alg, 且 最佳适合递减算法 是基于 首次适合递减算法的;
【2】分治算法
0)intro:对于分治算法,我们只以 归并排序进行讲解,它是理解分治算法的最佳荔枝,没有之一;
1)我们已经看过的分治算法有:最大子序列和问题, 归并排序和快速排序;时间复杂度都是 O(NlogN);
2)分治算法分为 分和治:
2.1)分:将一个大问题分为两个大致相同的小问题;
2.2)治:将两个小问题的解合并,得到整个问题的解;
【2.1】看个荔枝:归并排序 归并排序源码
1)归并排序的思想:基于分治思想,是递归算法一个很好的荔枝,是用于分析递归例程方法的经典荔枝;
2)归并排序中基本操作:是 合并两个已排序 的表。因为两个表已经排序,所以若将输出放到 第3个表中,则该算法可以通过对输入数据一趟排序来完成;
3)归并排序的steps:
step1)后序遍历raw 数组,依据 [left, center] 和 [center+1, right] 分割数组为两个子数组;
step2)合并数组操作在 分割完后进行,后序遍历的意思就是 非递归操作在递归之后进行;
// 对数组raw[left, right]进行归并排序. // 归并排序是合并两个已排序的表,并吧合并结果存储到 第三个数组temp中. void mergesort(ElementType* raw, ElementType* temp, int left, int right) { int center; if(left < right) { center = (left + right) / 2; mergesort(raw, temp, left, center); mergesort(raw, temp, center + 1, right); mergeArray(raw, temp, left, right); // 合并已排序的两个表[left,center] 和 [center+1,right] } }
step3)合并两个已排序数组到第3个数组中;
step3.1)把数组raw[left,center]或raw[center+1,right]中的元素copy到 temp数组中.
step3.2)把没有copy完的数组中的元素copy到 temp数组中, 要知道合并完后,肯定还有一个数组中的元素没有 copy完,因为两个数组的长度不等.
step3.3)现在temp 数组中的元素已经有序了,再把temp中的数组copy 回 raw数组中.
// 合并数组raw[left,center] 和 数组raw[center+1, right] 到 temp数组. void mergeArray(ElementType* raw ,ElementType* temp, int left, int right) { int center = (left+right)/2; int start1, start2; int end1, end2; int index; start1 = left; //第一个数组起点. end1 = center; //第一个数组终点. start2 = center+1; // 第二个数组起点. end2 = right; // 第二个数组终点. index = left; // 数组索引. // 依序合并2个数组到 第3个数组 分3个steps: // step1: 把数组raw[left,center]或raw[center+1,right]中的元素copy到 temp数组中. while(start1 <= end1 && start2 <= end2) { if(raw[start1] < raw[start2]) // 谁小,谁就copy到 temp数组中. { temp[index++] = raw[start1++]; } else { temp[index++] = raw[start2++]; } } // step1 over. // 合并完后,肯定还有一个数组中的元素没有 copy完,因为两个数组的长度不等. // step2: 把没有copy完的数组中的元素copy到 temp数组中; while(start1 <= end1) { temp[index++] = raw[start1++]; } while(start2 <= end2) { temp[index++] = raw[start2++]; } // step2 over. // step3: 现在temp 数组中的元素已经有序了,再把temp中的数组copy 回 raw数组中. for(index = left; index <= right ; index++) { raw[index] = temp[index]; } }
4)归并排序的运行示意图
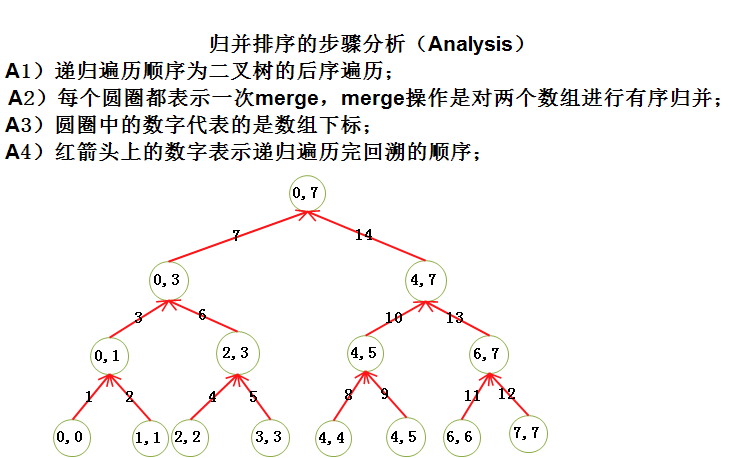
对上图的分析(Analysis):
A1)上面的关于归并排序的steps的描述中这样提到:归并排序的基本操作是合并两个已排序的表;结合上面的递归流程图,我们发现,首先 从 (0,0) 和 (1,1)开始,他们都只表示一个元素,当然这两个子数组是有序的;对其他叶子节点也是同样的道理,接着就合并两个子数组了;
A2)为什么归并排序是基于分治算法思想的呢? 因为从上图,我们可以看出,该归并排序算法 首先将 数组分割成若干个子数组(分割终点是 left>=right)即,分割数组直到最后的子数组的元素个数为1为止,然后再对元素个数为1的两个子数组进行合并,再对元素个数为2的两个子数组进行合并...... 这不是分治这是什么?
5)测试用例
int main()
{
ElementType raw[] = {10, 100, 20, 90, 60, 50, 120, 140, 130, 5};
int size = 10;
ElementType *tempArray;
tempArray = createArray(size);
if(tempArray==NULL)
{
return -1;
}
mergesort(raw, tempArray, 0, size-1);
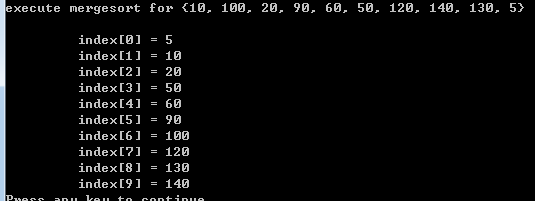
printf("\nexecute mergesort for {10, 100, 20, 90, 60, 50, 120, 140, 130, 5}\n");
printArray(raw, size);
return 0;
}
【3】动态规划
1)intro:动态规划是将问题分为一系列相互联系的子问题,求解一个子问题可能要用到已经求解过的 子问题的解的 算法设计技巧;
2)problem+solutions:
2.1)problem:任何数学递归公司都是可以直接用递归算法计算的,但编译器常常不能正确的对待递归算法,结果导致递归算法很低效;
2.2)solutions:我们给编译器一些帮助,将递归算法重新写成非递归算法(如将递归算法通过循环来代替),让后者把那些子问题的答案系统地记录在一个表内。利用这种方法的一个技巧叫做动态规划;
【3.1】 用一个表代替递归
【3.1.1】荔枝1:斐波那契数列(Fibonacci Sequence) 斐波那契数列源码
1)intro: 斐波那契数列(Fibonacci sequence):又称黄金分割数列、因数学家列昂纳多·斐波那契以兔子繁殖为例子而引入,故又称为“兔子数列”,指的是这样一个数列:0、1、1、2、3、5、8、13、21、34、……在数学上,斐波纳契数列以如下被以递归的方法定义:F(0)=0,F(1)=1,F(n)=F(n-1)+F(n-2)(n≥2,n∈N*);

对上图的分析(Analysis): 上述递归算法如此慢的原因在于算法模仿了递归。为了计算 FN, 存在一个对 FN-1 和 FN-2 的调用。 然而, 由于FN-1递归地对 FN-2 和 FN-3 进行调用, 因此存在两个单独的计算FN-2 的调用;如果我们试探整个算法,可以发现,FN-3 被计算了3次, FN-4 计算了5次, 而FN-5计算 了8次;如下图所示, 冗余计算的增长是爆炸性的;
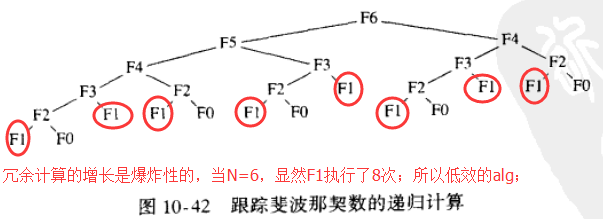
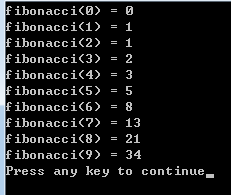
2)使用循环计算斐波那契数的线性算法(为什么使用循环会这么快? 这符合动态规划的定义,因为斐波那契数列 靠后的数列值的计算需要用到 靠前的数列值,把求每一个斐波那契数列值的看做一个子问题, 这符合动态规划定义中的叙述 “求解一个子问题可能要用到已经求解过的 子问题的解”)
#include <stdio.h>
int elements[255];
// 计算斐波那契数的线性算法
void fibonacci(int index)
{
if(index==0)
{
elements[index]=0;
}
else if(index==1)
{
elements[index]=1;
}
else // 还必须要这个 else 语句.
{
elements[index] = elements[index-1] + elements[index-2];
}
}
void main()
{
int i;
int size = 10;
for(i=0; i<size; i++)
{
fibonacci(i);
printf("fibonacci(%d) = %d\n", i, elements[i]);
}
}
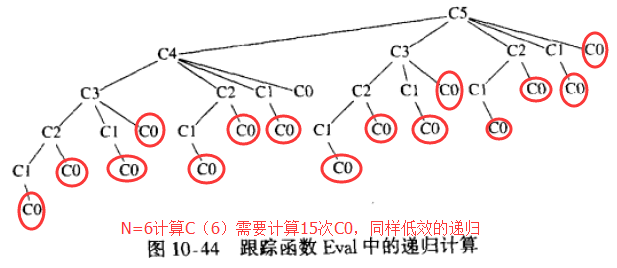
【3.1.2】荔枝2:求解递归关系 求解递归关系源码
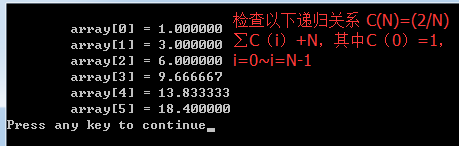
1)算法描述:我们想要检查以下递归关系 C(N)=(2/N)∑C(i)+N,其中C(0)=1,i=0~i=N-1;
 |  |
#include <stdio.h>
#include <malloc.h>
#define Error(str) printf("\n\terror: %s\n", str)
void eval(int n)
{
double* array;
int i;
i = 0;
array = (double*)malloc(sizeof(double) * (n+1));
if(array == NULL)
{
Error("failed eval, for out of space !");
return ;
}
array[i] = 1.0;
printf("\n\tarray[%d] = %8lf", i, array[i]);
for(i=1; i<=n; i++)
{
array[i] = 2 * array[i-1] / i + i;
printf("\n\tarray[%d] = %8lf", i, array[i]);
array[i] += array[i-1];
}
}
int main()
{
eval(5);
printf("\n");
return 0;
}
1.1)迪杰斯特拉算法:用于在稀疏图中计算从一个给定的起点到其他顶点的最短路径;当然了 对于每一个顶点 都执行一次 迪杰斯特拉算法 与可以计算 所有点对最短路径; 迪杰斯特拉算法 对 稀疏图运行得更快;1.2)佛洛依德算法:用于在稠密图中 计算所有点对最短路径;佛洛依德算法 对稠密图运行得更快,因为它的循环更加紧凑;运行时间为 O(|V|^3);
2)Floyd alg 求解最短路径的一般过程(steps):佛洛依德算法源码
step1)设置两个矩阵distance 和 path, 初始时将图的邻接矩阵赋值给distance, 将矩阵path中的全部元素赋值为-1;// step1: 邻接矩阵 和 path矩阵 int distance[ElementNum][ElementNum] = { {0, 5, MyMax, 7}, {MyMax, 0, 4, 2}, {3, 3, 0, 2}, {MyMax, MyMax, 1, 0}, }; int path[ElementNum][ElementNum] = { {-1, -1, -1, -1}, {-1, -1, -1, -1}, {-1, -1, -1, -1}, {-1, -1, -1, -1}, };step2)以顶点k 为中间顶点, k取0~n-1(n为图中顶点个数), 对图中所有顶点对{i, j}进行如下检测与update: 如果distance[i][j] >distance[i][k] +distance[k][j], 则将distance[i][j] 改为distance[i][k]+distance[k][j]的值, 将path[i][j] update 为 k, 否则什么也不做;(干货——说白了,顶点k就做为一个中转站,检测通过中转站k的路径即 i -> k ->j 是否比 不通过中转站的路径 i -> j 的路径的访问代价(权值)要小,如果小的话,更新 distance[i][j],且顶点k 作为 path[i][j] 的中转点,否则不做任何处理)// 弗洛伊德算法用于 计算所有点对最短路径. // distance 是邻接矩阵, 而 path 是中转点. void floyd_all_pairs(int distance[ElementNum][ElementNum], int path[ElementNum][ElementNum]) { int i, j, k; for(k=0; k<ElementNum; k++) // step2: 以顶点k 作为中转站顶点. { for(i=0; i<ElementNum; i++) { for(j=0; j<ElementNum; j++) { if(distance[i][j] > distance[i][k] + distance[k][j]) // 经过中转站k的访问代价是否减小. { distance[i][j] = distance[i][k] + distance[k][j]; path[i][j] = k; } } } } }
3)我们看个实际的 荔枝:
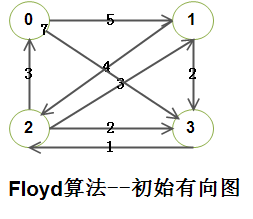
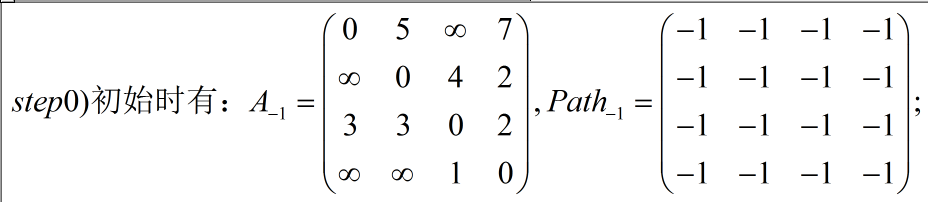

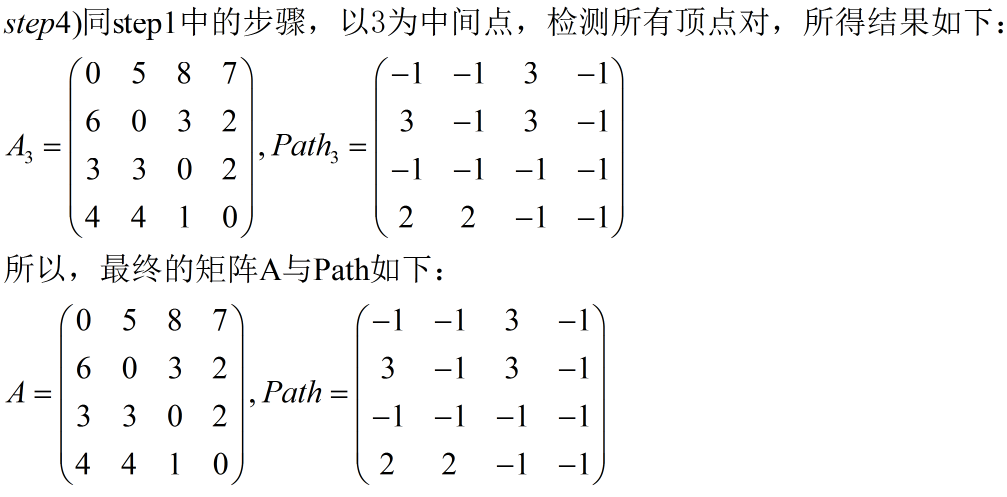
4)测试用例
int main()
{
// 邻接矩阵
int distance[ElementNum][ElementNum] =
{
{0, 5, MyMax, 7},
{MyMax, 0, 4, 2},
{3, 3, 0, 2},
{MyMax, MyMax, 1, 0},
};
int path[ElementNum][ElementNum] =
{
{-1, -1, -1, -1},
{-1, -1, -1, -1},
{-1, -1, -1, -1},
{-1, -1, -1, -1},
};
// 弗洛伊德算法用于 计算所有点对最短路径.
floyd_all_pairs(distance, path);
// 打印 floyd 的 计算结果.
printf("\n\t === distance array are as follows.===\n");
printArray(distance);
printf("\n\t === path array are as follows.===\n");
printArray(path);
}
补充)那为什么 佛洛依德算法也满足 动态规划的定义呢?
因为第k个 更新 distance 和 path 的阶段 依赖于 第(k-1)个阶段,即 第 k个阶段和 第k-1 个阶段是有联系的。如 distance[3][4] = ∞, 而 distance[3][1] + distance[1][4]=10 那所以 distance[3][4]=10(更新),path[3][4]=1;接着又继续更新,当k=4的时候,因为 distance[2][3]=∞,distance[2][4]=10,distance[2][4]+distance[3][4] = 20 而不是无穷大,即是 靠后的更新阶段 依赖于靠前的更新阶段的更新结果;
动态规划总结)
C1)动态规划是强大的算法设计技巧, 它给解提供了一个起点;C2)它基本上是首先求解一些更简单的问题的分治算法的范例, 重要的区别在于这些简单的问题不是原问题明确的分割。因为子问题反复被求解, 所以重要的是将它们的解记录在一个表中而不是重新计算它们;C3)在某些情况下, 解可以被改进, 而在另一些情况下, 动态规划方法则是所知道的最好的处理方法;C4)在某种意义上,如果你看出一个动态规划问题,那么你就看出所有的问题;(碉堡 有木有)















 4050
4050

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









