







入门算法学习,看的第一本是深入浅出的《算法图解》一书,本博客是对《算法图解》一书的学习笔记,将书中的分享的算法示例用Python3语言实现。
如果你也想要阅读这本书,百度云盘链接:https://pan.baidu.com/s/1s967vfgEBd1vSrfwVI9Y3g 提取码:【be9k】
或者也可以留言你的邮箱,我将PDF共享给你~
贪婪算法
- 贪婪算法(又称贪心算法)是指,在对问题求解时,总是做出在当前看来是最好的选择。也就是说,不从整体最优上加以考虑,他所做出的是在某种意义上的局部最优解。
- 贪婪算法很简单:每步都采取最优的做法。用专业术语说,就是你每步都选择局部最优解,最终得到的就是全局最优解。
贪婪算法工作原理

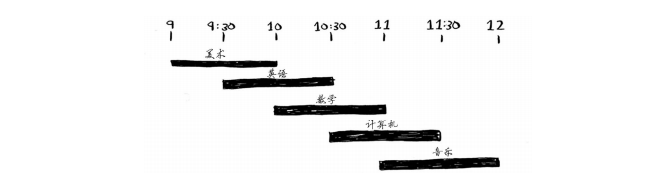
你希望在这间教室上尽可能多的课。如何选出尽可能多且时间不冲突的课程呢?
这个问题好像很难,不是吗?实际上,算法可能简单得让你大吃一惊。具体做法如下。
-
(1) 选出结束最早的课,它就是要在这间教室上的第一堂课。
-
(2) 接下来,必须选择第一堂课结束后才开始的课。同样,你选择结束最早的课,这将是要在这间教室上的第二堂课。
-
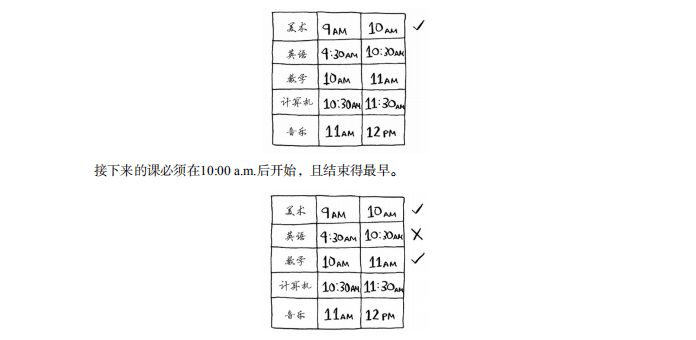
重复这样做就能找出答案!下面来试一试。美术课的结束时间最早,为10:00 a.m.,因此它就是第一堂课。
-
英语课不行,因为它的时间与美术课冲突,但数学课满足条件。最后,计算机课与数学课的时间是冲突的,但音乐课可以。
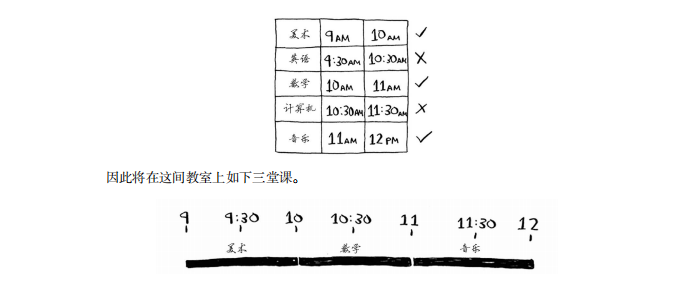
很多人都说,这个算法太容易、太显而易见,肯定不对。但这正是贪婪算法的优点——简单易行!
贪婪算法很简单:每步都采取最优的做法。在这个示例中,你每次都选择结束最早的课。用专业术语说,就是你每步都选择局部最优解,最终得到的就是全局最优解。
贪婪算法–案例
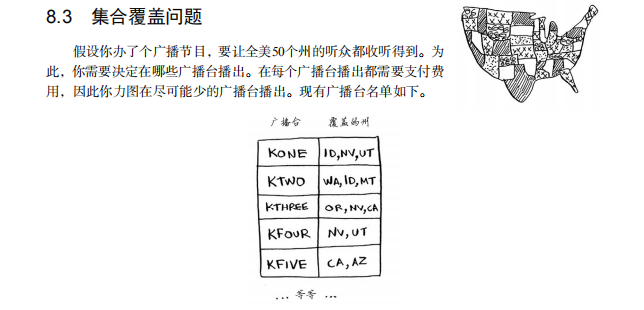
每个广播台都覆盖特定的区域,不同广播台的覆盖区域可能重叠。
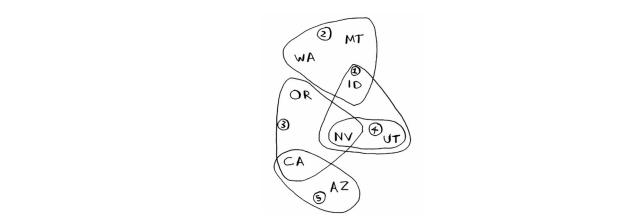
如何找出覆盖全美50个州的最小广播台集合呢?听起来很容易,但其实非常难。具体方法如下。
- (1) 列出每个可能的广播台集合,这被称为幂集(power set)。可能的子集有2n
个。

- (2) 在这些集合中,选出覆盖全美50个州的最小集合。
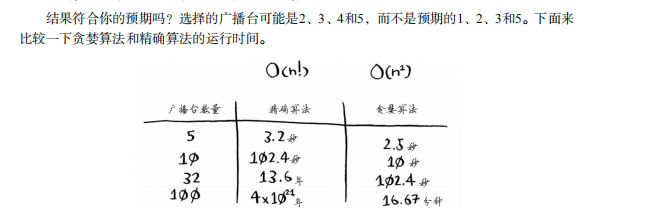
- 问题是计算每个可能的广播台子集需要很长时间。由于可能的集合有2n个,因此运行时间为O(2n)。如果广播台不多,只有5~10个,这是可行的。
- 但如果广播台很多,结果将如何呢?
- 随着广播台的增多,需要的时间将激增。假设你每秒可计算10个子集,所需的时间将如下。

没有任何算法可以足够快地解决这个问题!怎么办呢?
贪婪算法可化解危机!使用下面的贪婪算法可得到非常接近的解。
- (1) 选出这样一个广播台,即它覆盖了最多的未覆盖州。即便这个广播台覆盖了一些已覆盖的州,也没有关系。
- (2) 重复第一步,直到覆盖了所有的州。
- 这是一种近似算法(approximation algorithm)。在获得精确解需要的时间太长时,可使用近似算法。
判断近似算法优劣的标准如下:
- 速度有多快;
- 得到的近似解与最优解的接近程度。
贪婪算法是不错的选择,它们不仅简单,而且通常运行速度很快。在这个例子中,贪婪算法
的运行时间为O(n^2),其中n为广播台数量。
下面是解决这个问题的代码。
state_needed = {'mt', 'wa', 'or', 'id', 'nv', 'ut', 'ca', 'az'} # 需要覆盖的州的集合
stations = {} # 用集合的形式记录广播台清单
stations["kone"] = {"id", "nv", "ut"} # 表示:kone广播台可以覆盖id、nv、ut地区
stations["ktwo"] = {"wa", "id", "mt"} # 表示:ktwo广播台可以覆盖wa、id、mt地区
stations["kthree"] = {"or", "nv", "ca"}
stations["kfour"] = {"nv", "ut"}
stations["kfive"] = {"ca", "az"}
finaly_stations = set() # 最终选择的广播台
while state_needed: # 循环需要覆盖的州的集合,直到覆盖完全,才停止循环
best_station = None # 最合适的广播台
best_states_covered = set() # 记录覆盖的交集地区
for station, states in stations.items(): # 遍历每一个广播台
coverd = state_needed & states # covered包含同时出现在‘需要覆盖’的和‘广播站覆盖’的那些州
if len(coverd) > len(best_states_covered): # 检查该广播台覆盖的州是否比best_states_coverd 多
best_station = station # 如果多,就选择这个station为最合适的广播台
best_states_covered = coverd # 记录这次覆盖的交集地区
state_needed -= coverd # 减少下次需要覆盖的地区
finaly_stations.add(best_station) # 将这个最优广播站添加到finaly_stations集合中
print(finaly_stations)
----------------------
{'kone', 'kfive', 'kthree', 'ktwo'}
运行时间

















 4207
4207

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









