






参考链接:EfficientNet网络详解_太阳花的小绿豆的博客-CSDN博客_efficientnet网络结构
大部分内容都是参考上述博客的,这里留个记录,方便以后查找。
文章总体思想:
- 使用神经架构搜索【2】,并从而确定了基础EfficientNet-B0基准。由于搜索网络相同,故搜索出的baseline与MnasNet也类似。但EfficientNet-B0的FLOPS要略大一些。Baseline的主要构建模块是MBConv,此外还添加了squeeze-and-excitation(SE)优化。
- 将(F,L,H,W,C)使用组合系数的形式统一缩放,并在此基础上扩大网络构成EfficientNetB0-B7系列网络。
- 但大范围的搜索虽然可以找到最优模型,但代价太大,为了节省资源作者采取两步走策略构建EfficientNet系列框架(两步走可能得出次优解,但代价小):
1)首先固定住放大倍数不动,,提升可利用资源,搜索对应平衡三维参数点;
2)之后固定三维参数点放大不同的倍数构建EfficientNet系列网络架构。
EfficientNetB7达到当年SOTA,并且推理速度更快,参数量更小(注意,参数数量少并不意味推理速度就快)。
文章逻辑:
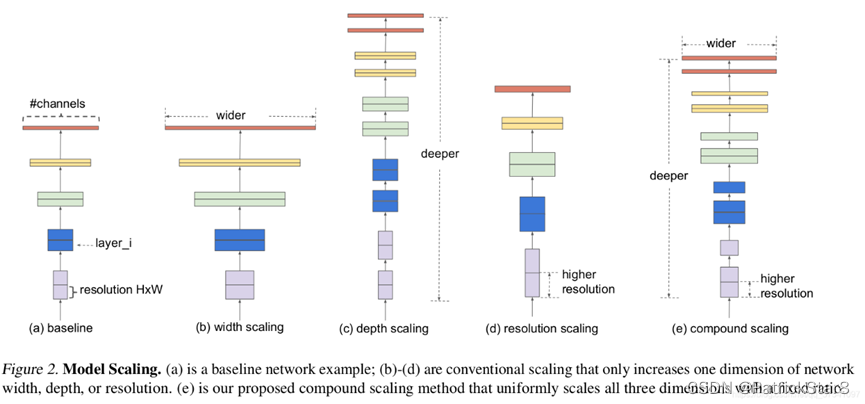
大部分改进网络的方法都会选择增加深度,宽度,分辨率其中的一种或两种。
- 增加网络的深度depth能够得到更加丰富、复杂的特征并且能够很好的应用到其它任务中。但网络的深度过深会面临梯度消失,训练困难的问题。
- 增加网络的width能够获得更高细粒度的特征并且也更容易训练,但对于width很大而深度较浅的网络往往很难学习到更深层次的特征。
- 增加输入网络的图像分辨率能够潜在得获得更高细粒度的特征模板,但对于非常高的输入分辨率,准确率的增益也会减小。并且大分辨率图像会增加计算量。
文章对此分别进行了单独实验。下图展示了在基准EfficientNet-B0上分别增加width、depth以及resolution后得到的统计结果。通过下图可以看出大概在Accuracy达到80%时就趋于饱和了。
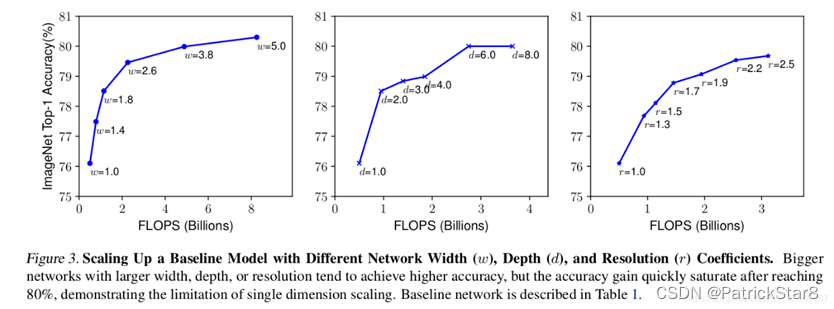
并且从实验结果可推测三者因素是有联系的。因此文章进一步就三者之间存在的关联性进行了验证。从结果可看出三者组合叠加效果更好(红色曲线)。
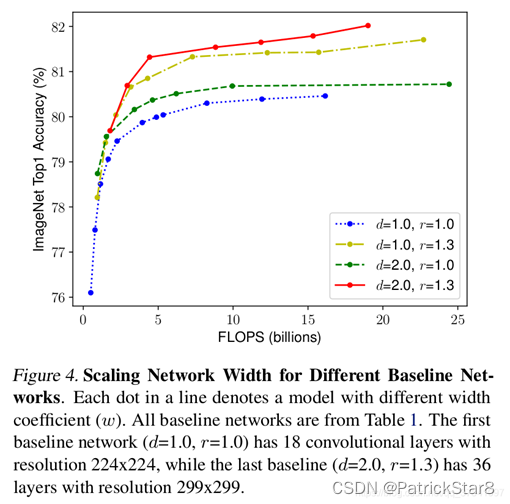
既然三者因素有规律可循,那3维之间什么样的关系最好?是否可以用一个简单的常量组合达到一个表现较好的平衡。基于此想法,通过使用神经架构搜索,(【1】Zoph, B. and Le, Q. V. Neural architecture search with reinforcement learning. ICLR, 2017.【2】Tan, M., Chen, B., Pang, R., Vasudevan, V., Sandler, M., Howard, A., and Le, Q. V. MnasNet: Platform-aware neural architecture search for mobile. CVPR, 2019.)
- 使用与【2】相同的多目标网络搜索架构构建网络baseline,其优化指标使用,(m)表示m模型,T是目标FLOPS,w=-0.07控制ACC,FLOPS的超参数,(【2】优化的指标是延迟)。由于搜索网络相同,故搜索出的baseline与MnasNet也类似。但EfficientNet-B0的FLOPS要略大一些。Baseline的主要构建模块是倒置的MBConv,此外还添加了squeeze-and-excitation优化。
大范围的搜索虽然可以找到最优模型,但代价太大,为了节省资源作者采取两步走策略构建EfficientNet系列框架:
1)首先固定住放大倍数不动,搜索对应平衡三维参数点,
2)之后固定三维参数点放大不同的倍数构建EfficientNet系列网络架构。
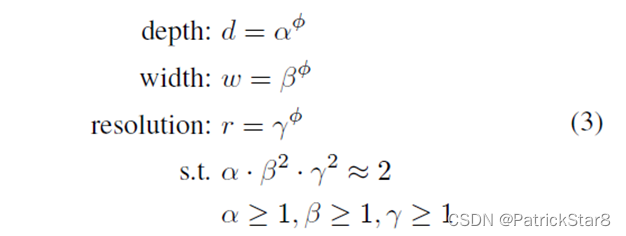
放大倍数固定时,限制三个因素之和为一个常量系数,对于任意一个而言FLOPs相当于增加了 倍。将d , r , w加入到网络运算中,可以得到抽象化后的优化问题(在指定资源限制下),其中s . t .代表限制条件:
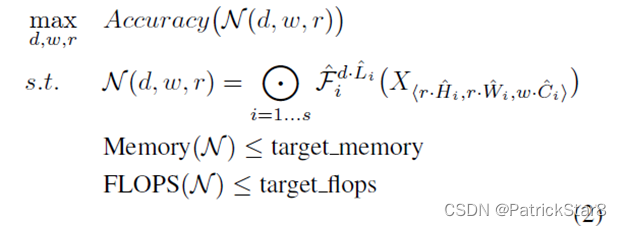



使用与【2】相同的多目标网络搜索架构构建网络baseline,其优化指标使用,(m)表示m模型,T是目标FLOPS,w=-0.07控制ACC,FLOPS的超参数,(【2】)优化的指标是延迟)。由于搜索网络相同,故搜索出的baseline与MnasNet也类似。但EfficientNet-B0的FLOPS要略大一些。Baseline的主要构建模块是倒置的MBConv,此外还添加了squeeze-and-excitation优化。
限制
![]()
时,按小网格搜索法搜索到α=1.2,β=1.1,γ=1.15(当通道取值不为整时,按最近取整原则取整)。基于此构建出了EfficientNet-B0:

表格中每个MBConv后会跟一个数字1或6,这里的1或6就是倍率因子n即MBConv中第一个1x1的卷积层会将输入特征矩阵的channels扩充为n倍,
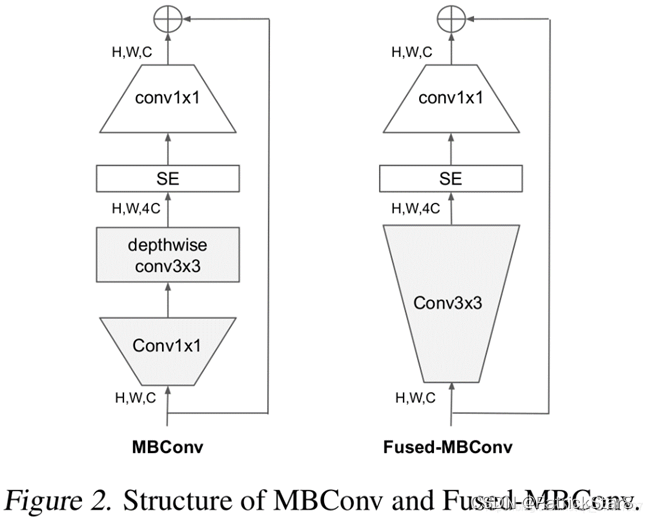

- 关于shortcut连接,仅当输入MBConv结构的特征矩阵与输出的特征矩阵shape相同时才存在。在源码实现中只有使用shortcut的时候才有Dropout层
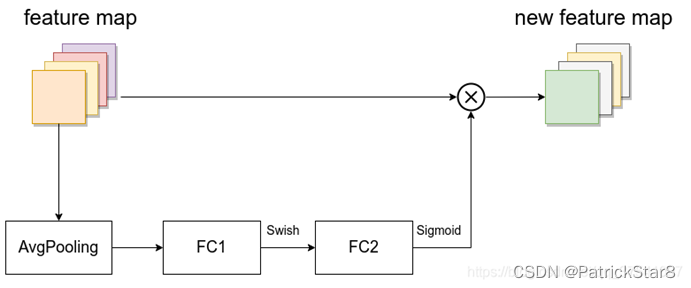
- SE模块如下所示,由一个全局平均池化,两个全连接层组成。第一个全连接层的节点个数是输入该MBConv特征矩阵channels的1/4,且使用Swish激活函数。第二个全连接层的节点个数等于Depthwise Conv层输出的特征矩阵channels,且使用Sigmoid激活函数。
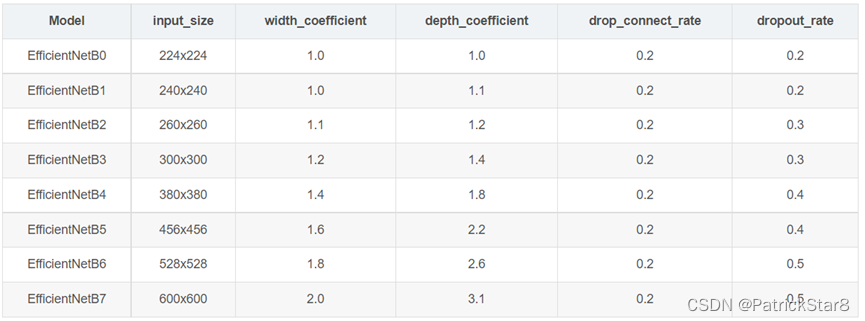
超参数设置:
衰减0.9和动量0.9的RMSProp优化器;batch norm动量 0.99;权重衰减1e-5;初始化学习率0.256,每2.4个epoch衰减0.97;SiLU(Swish-1)激活;AutoAugment;随即深度,生存概率为0.8;dropout线性增长0.2-0.5;使用随机25k训练集中的数据作为minival,并对minival执行early-stopped checkpoint,对比minival权重的准确度和原始验证集权重的准确度。
EfficientNet分类实验结果
数据分析:
数据划分:从train文件夹内随机选取20%图像作为Val,剩余80%作为train
| Total | Train | Val |
| 58389 | 46853 | 11535 |
参数设置:
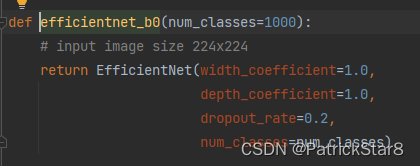
| EfficientNet-B0 | |
| Image_size | 224*224 |
| dropout_rate | 0.2 |
| activation | SiLU(swith) |
| Optimizer | SGD(lr=0.01,动量0.9,衰减1e-4) |
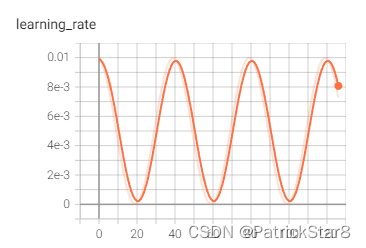
| Learning | CosineAnnealingLR |
| Loss | CrossEntropyLoss |
| BatchNorm | BatchNorm2d(eps=1e-3, momentum=0.1) |
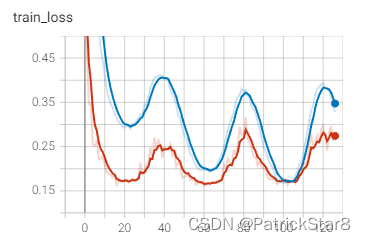
训练结果展示:

测试结果展示:
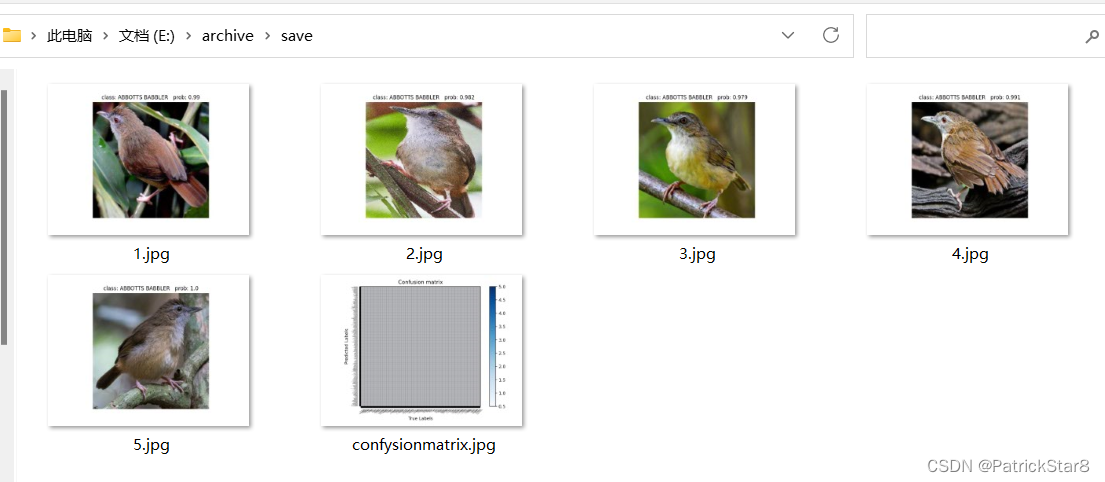
测试ABBOTTS BABBLER一类五张图片,批量测试并统一保存分类结果:
混淆矩阵:
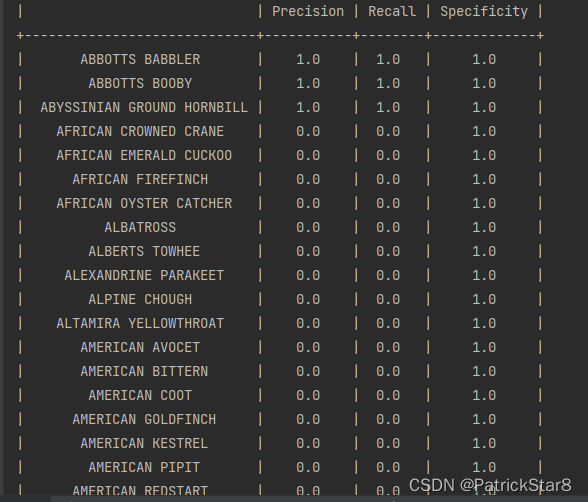
相关测试指标(precision,recall,specificity)















 4823
4823











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









