







前言
在之前我们介绍过EfficientNet(直通车:【轻量化网络系列(6)】EfficientNetV1论文超详细解读(翻译 +学习笔记+代码实现)
【轻量化网络系列(7)】EfficientNetV2论文超详细解读(翻译 +学习笔记+代码实现))
EfficientDet 是继 2019 年推出 EfficientNet 模型之后,Google 人工智能研究小组Tan Mingxing等人为进一步提高目标检测效率,以 EfficientNet 模型和双向特征加权金字塔网络 BiFPN为基础,于2020 年创新推出的新一代目标检测模型,在COCO数据集上吊打其他方法。
学习资料:
- 论文题目:《EfficientDet: Scalable and Efficient Object Detection》(《EfficientDet:可扩展且高效的目标检测》)
- 原文地址:EfficientDet: Scalable and Efficient Object Detection
- 论文提供代码地址:automl/efficientdet at master · google/automl · GitHub
- 第三方提供代码地址:https://github.com/jewelc92/mmdetection/blob/3.x/projects/EfficientDet/efficientdet/bifpn.py
目录
3.2 Cross-Scale Connections—跨尺度连接
3.3 Weighted Feature Fusion—加权特征融合
4.1 EfficientDet Architecture—模型架构
5.1 EfficientDet for Object Detection—用于目标检测的EfficientDet
5.2 EfficientDet for Semantic Segmentation—语义分割的EfficientDet
6.1 Disentangling Backbone and BiFPN—分离主干网络和BiFPN
6.2 BiFPN Cross-Scale Connections—BiFPN跨尺度连接
6.3 Softmax vs Fast Normalized Fusion—Softmax与快速归一化融合

Abstract—摘要
翻译
模型效率在计算机视觉中越来越重要。本文我们系统地研究了目标检测的神经网络框架,并提出了几个有利于提高模型效率的关键的优化点。首先,我们提出了一个加权双向特征金字塔网络(BiFPN),可以又快又简单地实现多特征融合;其次我们提出了一种复合缩放方法,可以同时缩放所有主干网络、特征网络和框预测/类别预测网络的分辨率、深度和宽度。基于这些优化以及更好的主干网络,我们开发了一个新的目标检测网络系列,EfficientDet,虽然现如今资源有限(CPU、GPU处理速度、数据集缺失等吧,自我理解,有误请更正),但性能比其他网络要好。特别对于一阶段网络和单个尺寸,我们EfficientDet-D7在COCO测试集的精度最高,AP为55.1%,参数量为77M,FLOPs为410B,参数量比之前的检测网络小了4-9倍,且FLOPs少了13-42倍。
精读
摘要概述
(1)目前的目标检测,要不追求更准确的检测效果,但是花销很大,要不更有效率,但牺牲了准确性。
(2)本文提出了一种加权的双向金字塔网络 (BiFPN),可以轻松快速地进行多种尺度特征融合。同时提出一种统一缩放分辨率、深度和宽度的复合缩放方法。
(3)本文开发了一个新的目标检测器系列—EfficientDet。COCO测试集上以77M参数和410B FLOPS1达到了最新的55.1 AP。
一、Introduction—简介
翻译
最近几年在目标检测领域取得了巨大的进步,同时SOTA目标检测器也变得越来越昂贵。例如最新的 AmoebaNet-based NAS-FPN检测器需要167M的参数和3045BFLOPS(超过RetinaNet30倍左右)才实现了SOTA的准确率。庞大的模型尺寸和昂贵的计算成本阻碍了它们在许多实际应用中的部署,例如机器人技术和无人驾驶汽车,在这些应用中,模型尺寸和延迟受到很大限制。考虑到这些现实世界中的资源限制,目标检测的模型效率变得越来越重要。
之前已经有许多工作旨在开发更有效的检测器架构,例如一些一阶段(SSD,RetinaNet,yolo系列)和anchor-free(Cornernet,FCOS,CenterNet)以及压缩现有模型。虽然这些方法想要实现更高的效率,它们通常会牺牲准确率。大部分之前的工作只着重于特定或少量资源需求,但是从移动设备到数据中心的各种实际应用程序通常需要不同的资源约束。
一个很自然的问题,是否有可能在各种资源限制条件下构建具有更高准确性和更高效率的可扩展检测结构(例如从3B-300B FLOPS)。这篇文章旨在通过系统地学习各种各样的检测器架构的设计选择。基于一阶段检测器的模板,我们为backbone,特征融合和分类/box网络检验了各种设计选择,并且确定了两个主要挑战:
挑战1:搞笑的多尺度特征融合—自从FPN出现以后,FPN被广泛用到了特征融合当中。最近,PANet,NAS-FPN和一些其他研究为跨尺度特征融合提出了很多网络。虽然在融合不同的输入特征时,大部分以前的工作都没有很大的差别,只是简单的把它们加起来。然而,虽然这些不同的输入特征有着不同的分辨率,我们观察到它们对融合的输出特征有着不同的影响。为了解决这个问题,我们提出了一种简单而且高效的加权双向金字塔网络(BiFPN),引入可学习的权重以学习不同输入特征的重要程度,同时反复应用自上而下和自下而上的多尺度特征融合。
挑战2:模型缩放—虽然之前的工作主要依赖于大的backbone网络或者更大的输入图片尺寸来获得更好的准确率,我们发现在兼顾准确性和效率的同时,扩大特征网络和box/class预测网络也很关键。我们为目标检测器提出了一种复合缩放方法,同时扩大了backbone,特征网络和box/class预测网络的分辨率/深度/宽度。
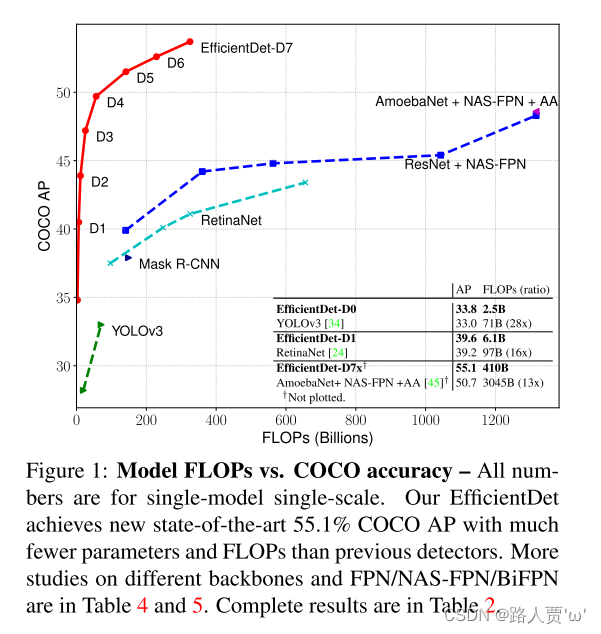
最后我们发现,最近出现的EfficientNets比以前常用的backbone网络有着更高的效率。结合 EfficientNet backbones和我们提出的BiFPN以及复合缩放方法,我们提出了一个新的目标检测器系列—EfficientDet。与以前的物体检测器相比,它以更少的参数和FLOP持续获得更高的精度。图1和图4展示了在COCO数据集上的性能对比。在相似的准确度限制下,EfficientDet用了比YOLOv3少28倍的FLOPS,比RetinaNet少30倍的FLOPS,比最近的NAS-FPN少19倍的FLOPS。在单个模型和单个特使时间范围内,我们的EfficientDet-D7实现了SOTA mAP,52M参数量和326BFLOPS,比之前最好的模型小4倍,FLOPS少9.3倍,准确率仍然高0.3mAP。我们的EfficientDet模型比之前的检测器在GPU上快3.2倍,在CPU上快8.1倍,如图4和表2所示。
我们的贡献如下:
1.我们提出了BiFPN模型,一个可以更加轻松和快速完成多尺度特征融合的双线性特征网络。
2.我们提出了一个新的符合缩放方法,可以同时扩大backbone,特征网络,box/class 预测网络和分辨率。
3.基于BiFPN和复合缩放,我们开发了EfficientDet,即在广泛的资源条件限制下准确率和效率都显著提升的一个新的检测器系列。
精读
挑战1:高效的多尺度特征融合
- 之前的问题: 不同的输入特征的分辨率不同,对融合输出特征的贡献不均
- 解决方法: 本文提出了一个简单而高效的加权双向特征金字塔网络(BiFPN)
- 实现效果: 该网络引入了可学习的权重以了解不同输入特征的重要性,同时反复多尺度特征融合。
挑战2:模型缩放
- 之前的问题: 之前的工作主要依赖于大的backbone网络或者更大的输入图片尺寸来获得更好的准确率
- 解决方法: 本文提出了一种复合缩放方法,并提出了一个新的目标检测器系列—EfficientDet
- 实现效果: 与以前的物体检测器相比,它以更少的参数和FLOP持续获得更高的精度
本文贡献
(1)本文提出了BiFPN模型,一个可以更加轻松和快速完成多尺度特征融合的双线性特征网络。
(2)本文提出了一个新的复合缩放方法,可以同时扩大backbone,特征网络,box/class 预测网络和分辨率。
(3)基于BiFPN和复合缩放,本文开发了EfficientDet,即在广泛的资源条件限制下准确率和效率都显著提升的一个新的检测器系列。
二、Related Work—相关工作
翻译
单阶段检测器:现有的目标检测器主要是根据是否有生成ROI(region-of-interest,感兴趣区域)这一步骤分为二阶段(有)和一阶段(无)检测器。二阶段检测器更灵活、更准确;但通过于先生成的anchor,单阶段检测器更简单、更高效。最近,单阶段检测器因其优点备受关注。本文,我们主要研究一阶段检测器,通过优化的网络架构实现更高的效率和精度。
Model Scaling:为了获得更高的精度,通常使用更大的主干网络(比如,从mobile-size模型和ResNet增大到ResNeXt和AmoebaNet)或者增大输出图像尺寸(比如,从512×512增大到1536×1536)来放大baseline检测器。最近一些研究表明,增大通道尺寸和重复利用特征网络也可以提高精度。这些修改尺寸的方法大多集中在单个或有限的缩放维度上。最近,文献通过组合网络宽度、深度和分辨率,证明了可以大大提高模型效率。本文提出的Compound Scaling方法主要借鉴了文献。
精读
(1)一阶段检测器: 一阶段检测器更简单高效。本文主要遵循一阶段检测器设计,通过优化的网络架构实现更高的效率和更高的精度。
(2)多尺度特征表示:
- 特征金字塔网络(FPN): 提出了一种自上而下的途径来组合多尺度特征。
- PANet : 在FPN的基础上增加了一个额外的自下而上的路径聚合网络。
- STDL : 提出了一种尺度转移模块来利用跨尺度特征。
- M2det: 提出了一种U形模块来融合多尺度特征。
- G-FRNet : 提出了用于控制信息跨特征流动的门单元。
- NAS-FPN: 利用神经体系结构搜索来自动设计特征网络拓扑。
本文方法: 本文以更直观,更原则的方式优化多尺度特征融合。
(3)模型缩放:增加通道大小和重复特征网络可以提高精度。这些缩放方法主要集中在单个或有限的缩放尺度上。 本文受到启发提出的用于对象检测的复合缩放方法。
三、BiFPN
3.1 Problem Formulation—问题阐述
翻译
多尺度特征融合旨在聚集不同分辨率的特征。形式上,给定一个多尺度特征列表Pin(l)=(Pin(l1),Pin(l2),…),其中Pin(li)代表li级的特征,我们的目标是找到可以有效聚合不同特征并输出新特征列表的变换f: Pout = f(Pin).。作为一个具体的例子,图2(a)显示了传统的自上而下的FPN [20]。它采用3-7级输入特征Pin =(Pin(3),… Pin(7)),其中Pin(i)代表输入图像分辨率为1 / 2i的特征水平。 例如,如果输入分辨率为640x640,则Pin(3)代表分辨率为80x80的特征级别3(640/23 = 80),而Pin(7)代表分辨率为5x5的特征级别7。常规FPN以自顶向下的方式聚合多尺度特征:
Pout(7) = Conv(Pin(7))
Pout(6) = Conv(Pin(6)+Resize(Pout(7)))
…
Pout(3) = Conv(Pin(3)+Resize(Pout(4)))
其中Resize通常是用于分辨率匹配的上采样或下采样操作,而Conv通常是用于特征处理的卷积操作。
精读
目标
本文目标是找到可以有效汇总不同特征并输出一系列新特征的变换f
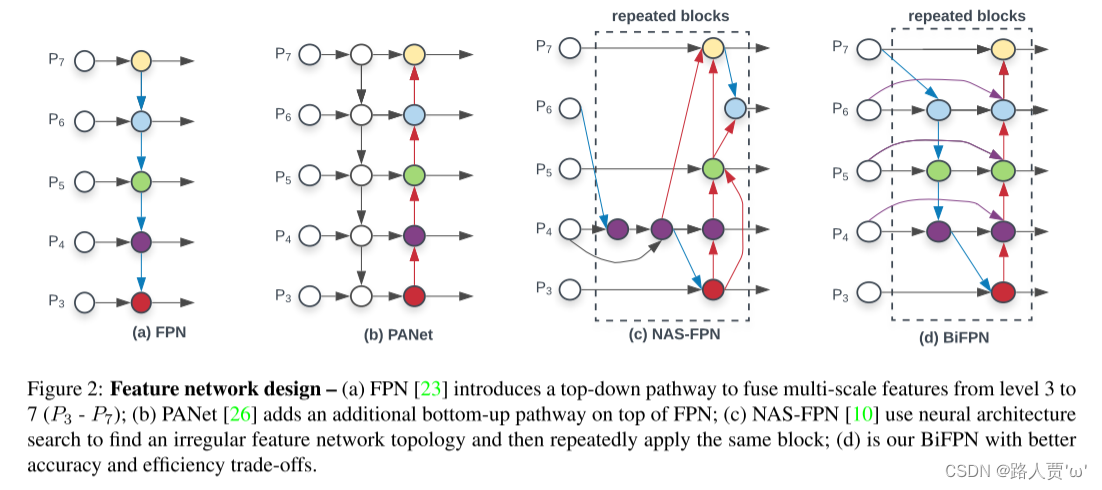
1.图(a)为FPN的结构,传统的自上而下聚合多尺度特征图
常规FPN以自顶向下的方式聚合多尺度特征:

2.图(b)是PANet,是在(a)的基础上改进添加自下而上的结构
3.图(c)是NAS-FPN, 采用了NAS 策略搜索最佳 FPN 结构
4.图(d)就是本论文提出的BiFPN的思想,在PANet的基础上,去掉了只有一个输入边的节点(P3和P7的中间节点),增加了输入节点(左边)到输出节点(右边)的直接跳连,然后和NAS-FPN一样,也是重复叠加了几次这种block。
3.2 Cross-Scale Connections—跨尺度连接
翻译
传统的自上而下的FPN固有地受到单向信息流的限制。为了解决这个问题,PANet [23]添加了一个额外的自下而上的路径聚合网络,如图2(b)所示。进一步研究了跨尺度连接。最近,NAS-FPN [8]使用神经体系结构搜索来搜索更好的跨尺度特征网络拓扑,但是在搜索过程中需要GPU运行数千个小时,并且发现的网络是不规则的并且难以解释或修改,如图2(C)所示。
通过研究这三个网络的性能和效率(表5),我们观察到PANet的精度比FPN和NAS-FPN更好,但是需要更多的参数和计算。为了提高模型效率,本文针对跨尺度连接提出了几种优化方法:首先,我们删除那些只有一个输入边的节点。我们的直觉很简单:如果一个节点只有一个输入边且没有特征融合,那么它将对旨在融合不同特征的特征网络贡献较小。这导致简化了的双向网络。其次,如果原始输入与输出节点处于同一级别,则我们要在它们之间添加一条额外的边,以便在不增加成本的情况下融合更多功能;第三,与PANet [23]不一样,它只有一个自上而下和一个自下而上路径,我们将每个双向(自上而下和自下而上)路径视为一个特征网络层,并重复同一层多次以实现更多高级特征融合。第4.2节将讨论如何使用复合缩放方法来确定不同资源约束的层数。通过这些优化,我们将新特征网络命名为双向特征金字塔网络(BiFPN),如图2和3所示。
精读
本文关于跨尺度连接的思路
(1)移除那些只有一条输入边的节点,这是因为如果一个节点只有一条输入边而没有特征融合,那么它对以融合不同特征为目标的特征网络的贡献就比较小。这可以简化双向网络。
(2)如果原始输入节点和输出节点处于同一水平,就在它们之间增加一条额外的边,以便在不增加太多成本的情况下融合更多的特征。
(3)与PANet只有一条自上而下和一条自下而上的路径不同,BiFPN将每条双向(自上而下&自下而上)路径视为一个特征网络层,并多次重复同一层,以实现更高级别的特征融合。
3.3 Weighted Feature Fusion—加权特征融合
翻译
当融合不同分辨率的特征时,一种常见的方法是首先将它们调整为相同的分辨率,然后将它们相加。金字塔注意力网络[22]引入全局自注意上采样来恢复像素定位,文献[10]展开了进一步研究。以前所有的方法对所有的输入特征一视同仁。然而,我们观察到,由于不同的输入特征的分辨率不同,对输出特征的贡献是不相等的。为了解决这个问题,为每个输入增加一个额外的权重,并让网络学习每个输入特征的重要性。基于此,本文考虑了三种加权融合方法:
Unbounded fusion: 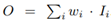 ,其中是一个可学习的权重,可以是标量(对于每个特征而言)、向量(对于每个通道而言)或多维张量(对于每个像素而言)。我们发现,一个特定的尺寸,可以使模型的性能发挥极致,而且与其他方法相比,计算成本最小。然而,由于标量权重是无界的,可能会导致训练过程不稳定。因此,我们采用权值归一化的方法来确定每个权值的取值范围。
,其中是一个可学习的权重,可以是标量(对于每个特征而言)、向量(对于每个通道而言)或多维张量(对于每个像素而言)。我们发现,一个特定的尺寸,可以使模型的性能发挥极致,而且与其他方法相比,计算成本最小。然而,由于标量权重是无界的,可能会导致训练过程不稳定。因此,我们采用权值归一化的方法来确定每个权值的取值范围。
Softmax-based fusion: ![]() 。将softmax应用于每个权重,这样所有权重都被标准为0到1,表示每个输入的重要性。然而,正如我们在第6.3节中的消融研究所示,额外的softmax会降低GPU的运行速度。为了减少额外的延迟开销,进一步提出了一种快速fusion方法。
。将softmax应用于每个权重,这样所有权重都被标准为0到1,表示每个输入的重要性。然而,正如我们在第6.3节中的消融研究所示,额外的softmax会降低GPU的运行速度。为了减少额外的延迟开销,进一步提出了一种快速fusion方法。
Fast normalized fusion:![]() ,其中是通过在每个后应用Relu激活函数得到的取值范围,取值较小,以避免数值不稳定。类似地,每个标准化权重的值的取值范围为(0,1),但是由于这里没有softmax操作,因此效率更高。消融研究表明,这种快速融合方法与基于softmax的融合具有非常相似的学习行为和准确性,而且在GPU上运行速度快了30%(表6)。
,其中是通过在每个后应用Relu激活函数得到的取值范围,取值较小,以避免数值不稳定。类似地,每个标准化权重的值的取值范围为(0,1),但是由于这里没有softmax操作,因此效率更高。消融研究表明,这种快速融合方法与基于softmax的融合具有非常相似的学习行为和准确性,而且在GPU上运行速度快了30%(表6)。
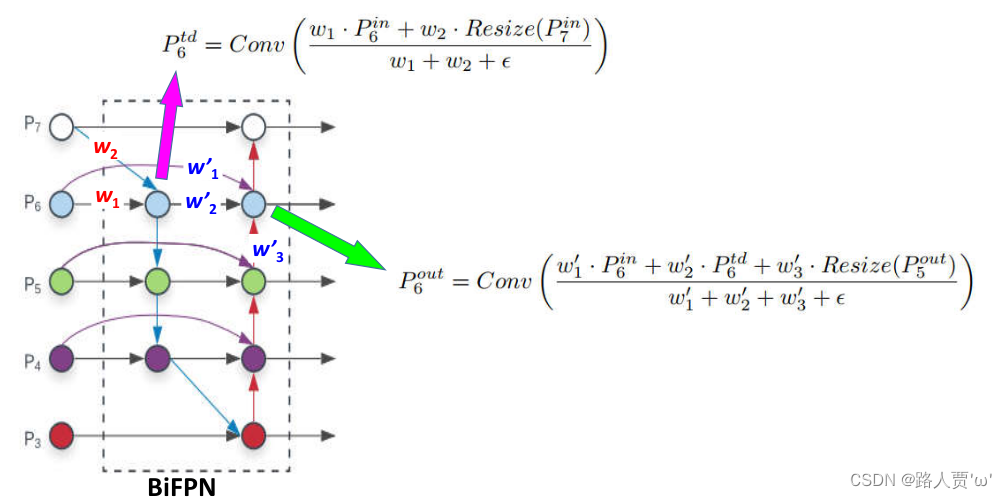
BiFPN集成了双向交叉尺度连接和快速归一化融合。本文描述了BiFPN在6级(efficientdet-d6)的两个融合特征(如图2(d)所示):
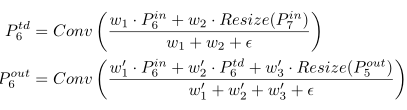
其中,是自上而下中间特征,是自下而上的输出特征。所有其他特征都以类似的方式构造。注意,为了进一步提高效率,我们使用深度可分离卷积[7,37]进行特征融合,并在每次卷积后加入batch normalization和激活函数。
精读
(1)无限融合
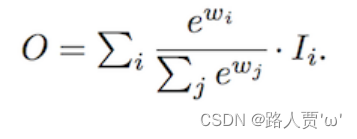
wᵢ是可学习的权重,可以是特征标量也可以是通道矢量,亦或是像素的多维张量。 但是由于这些权重是无界的,因此可能导致训练不稳定。
(2)基于Softmax的融合

如果希望权重值在0-1的有界范围内,最好的办法之一就是通过Softmax将这些值转换为概率分布,其中的概率值代表权重的重要性。但是Softmax的计算成本是高昂的。
(3)快速归一化融合
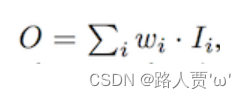
利用Relu,再通过简单的正则化我们就可以将输出权重值控制在在0-1范围内。这种方式相对前两种方式,更加简单和高效, 因此EfficientDet中使用快速归一化融合特征网络。
下图是快速归一化融合的计算路径:
四、EfficientDet
4.1 EfficientDet Architecture—模型架构
翻译
EfficientDet的总体架构如图3所示,基本上借鉴了单级检测器的架构[27,33,23,24]。本文将ImageNet预先训练的EfficientNets作为backbone。BiFPN作为特征网络,它从backbone中提取3-7级特征{P3,P4,P5,P6,P7},并重复应用自上向下和自下而上的双向特征融合。将融合后的特征反馈给class和box网络,分别对目标进行分类和定位。与文献[24]类似,class和box网络权重在所有级别的特征中共享。
精读
图3是不断堆叠BiFPN层的EfficientDet模型
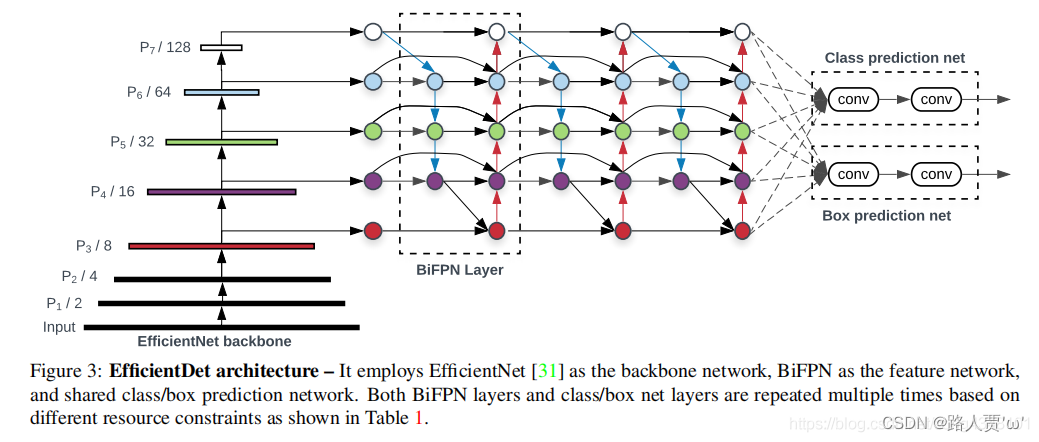
- backbone:EfficientNets
- 特征网络:BiFPN
4.2 Compound Scaling—复合缩放
翻译
为了优化准确率和效率,我们想要构建一个可以满足各种资源限制的模型。这里的关键挑战是如何扩大基准EfficientDet模型。
先前的工作大多通过采用更大的骨干网来扩大基线检测器(例如 ResNeXt和AmoebaNet),使用更大的输入图像或堆叠更多的FPN层。这些模型通常不高效而且仅仅关注一个或者有限的缩放尺寸。最近的工作通过联合扩大网络宽度,深度和输入分辨率的所有维度,在图像分类上显示了卓越的性能。受这些工作的启发,我们为目标检测提供了一个信息复合缩放方法。 只是用一个复合系数 φ来同时扩大backbone,BiFPN,class/box网络和分辨率的所有维度。因此我们使用了一个基于启发式的缩放方法,但仍然遵循共同扩大各个维度的主要思想。
backbone network: 我们重用了EfficientNet-B0到B6相同的宽度/深度缩放系数,因此我们可以轻松地重用其ImageNet预训练的检查点.
BiFPN network: 我们线性增加 BiFPN的深度Dbifpn(#layers),因为深度需要向下取整。对于BiFPN的快读Wbifpn(#channel)和Efficientnet相同。特别的,我们对值{1.2、1.25、1.3、1.35、1.4、1.45}的列表执行网格搜索,然后选择最佳值1.35作为BiFPN宽度缩放因子。最后,BiFPN的宽度和深度由以下方程式缩放:

Box/class prediction network:我们将其宽度固定为与BiFPN相同(例如:Wpred=Wbifpn),但是使用如下公式线性增加其深度(#layer)。
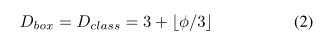
Input image resolution:因为特征level3-7都在BiFPN中被使用,输入的分辨率必须能被27=128整除,所以我们使用如下公式线性增加分辨率。
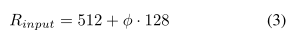
遵循具有不同φ的方程1,2,3,我们开发了 EfficientDet-D0 (φ = 0) to D7 (φ = 7),如Table1所示,这里 D7和D7x有着相同的 BiFPN和head。但是D7使用了更高的分辨率而D7x使用了更大的backbone网络以及多一个特征level(从P3—P8)。值得注意的是,我们的复合缩放是基于启发式的可能不是最优的,但是我们将展示这个简单的缩放方法比起其他的单维度的缩放方法可以更加显著地改进模型的效率,如图6所示。
精读
EfficientDet使用的是EfficientNet-B0到B7作为预训练模型,所以EfficientDet的系数ϕ的选择范围也是0~7。
Backbone network—主干网络
骨干网络采用和EfficientNet B0~B6相同的缩放系数,从而可以使用它们在ImageNet上的预训练模型。
BiFPN network—BiFPN 网络
对于BiFPN的深度 Dbifpn 采用线性变换的方式因为深度需要向下取整。对于宽度 Wbifpn采用指数变换的方式,采用网格搜索确定1.35作为宽度的缩放因子。
完整的缩放公式如下:
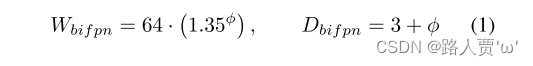
Box/class prediction network—Box/class预测网络
宽度固定为和BiFPN的宽度相等即 Wpred=Wbifpn ,深度按下式进行线性变换
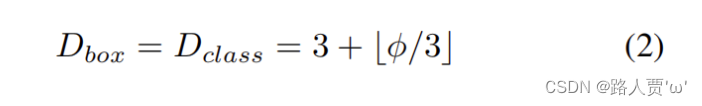
Input image resolution—输入图像分辨率
因为BiFPN中用到了level 3-7的特征,因此输入大小需要能被 2^7=128 除尽,因此输入分辨率按下式进行线性变换
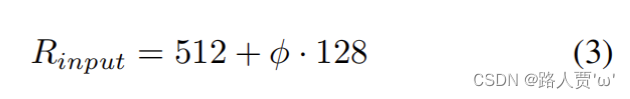
五、Experiments—实验
5.1 EfficientDet for Object Detection—用于目标检测的EfficientDet
翻译
本文的训练集有118K张图像对COCO 2017检测数据集[25]进行测试评估。每个模型的动量值设为0.9、权重衰减设为4e-5,优化函数为SGD。在第一个训练epoch,学习率从0线性增加到0.16,然后使用余弦衰减规则进行退火。每次卷积后加入同步批范数,批范数衰减设为0.99,ε=1e-3。与文献[39]相同,我们使用SiLU(Swish-1)激活函数[8,15,31],以及使用指数移动平均,衰减率为0.9998。我们还采用了常用的focal loss值[24],α=0.25,γ=1.5,纵横比为{1/2,1,2}。在训练过程中,将图片进行水平翻转和缩放抖动[0.1,2.0],即在裁剪前随机将图像缩小到原始大小的0.1倍到2倍之间。我们采用soft-NMS [3]进行评估。对于D0-D6模型,每个模型在32个TPUv3核上训练300个epoch,总batch size为128,但是为了推动包络,在128个TPUv3核上令D7/D7x模型的epoch=600。
EfficientDet与其他目标探测网络的比较结果见表2,在单模型单尺度情况下,测试时间没有增加。我们计算了test-dev(20K张测试图像,不包含ground-truth)和val (5k张验证图像)的准确性。注意,模型性能取决于网络体系结构和训练设置(见附录),但为了简单起见,只使用我们的训练网络搭建RetinaNet,并参考他们论文中的其他模型。一般来说,EfficientDet比以前的检测模型效率更高,模型尺寸小4倍到9倍,并且在精度或资源限制的条件下,FLOPs减小了13倍到42倍。在精度相对较低的情况下,EfficientDet-D0与YOLOv3具有相似的精度,FLOPs减小了28倍。与RetinaNet[24]和Mask RCNN[13]相比,EfficientDet的精度和他们相似,且参数减少了8倍,FLOPs减少了21倍。在高精度的情况下, EfficientDet也始终优于最近研发的目标检测网络[10,45],且参数和FLOPs要少得多。特别是,我们的单模型单尺度EfficientDet-D7x在测试AP 高达55.1,精度提高了4个百分点的 AP,效率减少了7倍FLOPs。
此外,本文还比较了Titan-V FP32、V100GPU FP16和单线程CPU上的推理延迟。注意,我们的V100延迟是端到端的,包括预处理和NMS后处理。图4比较了模型大小和GPU/CPU延迟。为了公平比较,均在设置相同的同一台机器上进行实验。与以前的探测器相比,EfficientDet在GPU上的速度快了4.1倍,在CPU上的速度快了10.8倍,这表明在实际硬件上的操作也是有效的。
精读
实验设
- 数据集: COCO数据集
- 优化器及动量: 动量0.9的SGD优化器
- 权重衰减的值: 4e-5
- 学习率: 先从0线性增加到0.16,然后使用余弦衰减规则进行退火
- 归一化: Synchronized batch norm
- decay: 0.99
- epsilon: 1e-3
- 激活函数: SiLU(swish-1)
- 指数平均移动衰减因子: 0.9998
- 损失函数: focal-loss,(其中 α = 0.25,γ = 1.5,宽高比为{1/2,1,2})
表2将EfficientDet与其他对象检测器进行了比较
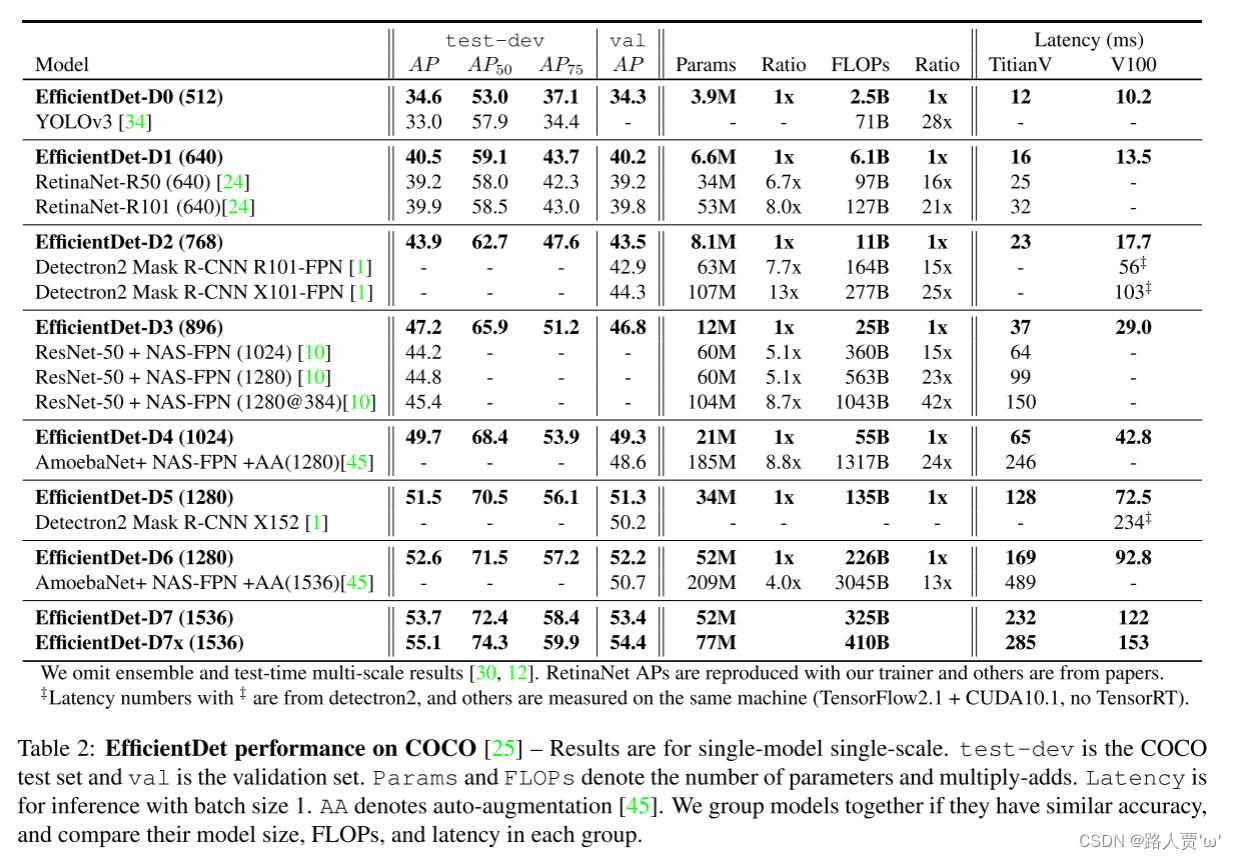
结论:EfficientDet在广泛的精度或资源限制范围内,比以前的检测器具有更高的精度和效率。
图4说明了模型大小,GPU延迟和单线程CPU延迟的比较

结论:与以前的探测器相比,EfficientDet模型在GPU上的速度提高了3.2倍,在CPU上的速度提高了8.1倍。
5.2 EfficientDet for Semantic Segmentation—语义分割的EfficientDet
翻译
尽管我们的EfficientDet模型主要用于对象检测,但我们也对它们在语义分割等其他任务上的性能感兴趣。按照[16],我们修改了EfficientDet模型,以将特征级别{P2,P3,…,P7}保留在BiFPN中,但仅将P2用于最终的每个像素分类。为简单起见,这里我们仅评估基于EfficientDet-D4的模型,该模型使用ImageNet预训练的EfficientNet-B4主干(与ResNet-50相似的大小)。对于BiFPN,我们将通道大小设置为128;对于分类头,我们将通道大小设置为256。 BiFPN和分类头均重复3次。
表3显示了我们的模型与Pascal VOC 2012 [7]上的先前DeepLabV3 + [4]之间的比较。值得注意的是,我们通过合奏,测试时间增加或COCO预训练排除了这些结果。在相同的单模型,单比例设置下,我们的模型比DeepLabV3 +[4]的现有技术提高了1.7%的精度,而FLOP却减少了9.8倍。这些结果表明,EfficientDet在语义分割方面也很有前途。
精读
实验方法
- 使用模型: EfficientDet-D4的模型(该模型使用ImageNet预训练的EfficientNet-B4主干(与ResNet-50相似的大小)。)
- BiFPN: 通道大小设置为128
- 分类头: 将通道大小设置为256
BiFPN和分类头均重复3次
表3显示了模型与Pascal VOC 2012上的先前DeepLabV3 + 之间的比较

结论:模型比DeepLabV3 +的现有技术提高了1.7%的精度,而FLOP却减少了9.8倍。这些结果表明,EfficientDet在语义分割方面也很有前途。
六、Ablation Study—消融研究
6.1 Disentangling Backbone and BiFPN—分离主干网络和BiFPN
翻译
由于EfficientDet同时使用了功能强大的主干网络和新的BiFPN,因此我们想了解它们各自对准确性和效率提高的贡献。表4比较了主干网络和BiFPN的影响。 从使用ResNet-50 [12]主干和自上而下的FPN [20]的RetinaNet检测器[21]开始,我们首先用EfficientNet-B3替换主干,这将使精度提高约3 mAP,而参数和FLOP则略少。 用我们提议的BiFPN进一步替代FPN,我们以更少的参数和FLOP实现了额外的4 mAP增益。 这些结果表明,EfficientNet主干网和BiFPN对我们的最终模型都至关重要。
精读
实验方法
(1)首先用EfficientNet-B3替换主干——精度提高约3 mAP,而参数和FLOP则略少。
(2)用BiFPN进一步替代FPN——精度又额外提高约4 mAP,而参数更少和FLOP。
表4比较了主干网络和BiFPN的影响

结论:EfficientNet主干网和BiFPN对最终模型都至关重要。
6.2 BiFPN Cross-Scale Connections—BiFPN跨尺度连接
翻译
表5显示了图2中列出的具有不同跨尺度连接的特征网络的准确性和模型复杂性。值得注意的是,原始FPN [20]和PANet [23]仅具有一个自上而下或自下而上的流程,但为了公平起见 比较,这里我们将它们重复多次(与BiFPN相同)。对于所有实验,我们使用相同的主干和类/框预测网络,以及相同的训练设置。可以看到,传统的自上而下的FPN固有地受到单向信息流的限制,因此准确性最低。尽管重复的PANet的精度比NAS-FPN [8]略好,但它还需要更多的参数和FLOP。我们的BiFPN具有与重复的PANet相似的精度,但是使用的参数和FLOP少得多。通过附加的加权特征融合,我们的BiFPN可以以更少的参数和FLOP进一步实现最佳精度。
精读
表5显示了图2中列出的具有不同跨尺度连接的特征网络的准确性和模型复杂性
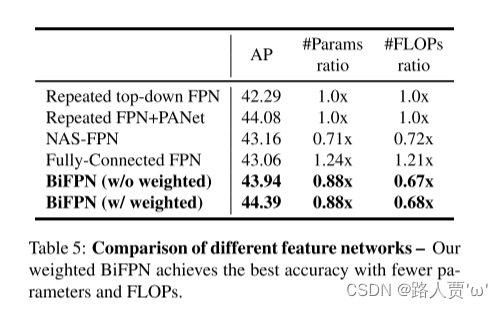
结论:BiFPN具有与重复的PANet相似的精度,但是使用的参数和FLOP少得多。
6.3 Softmax vs Fast Normalized Fusion—Softmax与快速归一化融合
翻译
如第3.3节所述,我们提出了一种快速归一化特征融合方法,以利用昂贵的softmax并保留归一化权重的好处。表6比较了三种具有不同模型尺寸的检测器中的softmax和快速归一化融合方法。如结果所示,我们的快速归一化融合方法达到了与基于softmax的融合相似的准确性,但是在GPU上的运行速度提高了1.26倍至1.31倍。
为了进一步了解基于softmax和快速归一化融合的行为,图5展示了从EfficientDet-D3中的BiFPN层中随机选择的三个特征融合节点的学习权重。值得注意的是,所有输入的归一化权重(例如,对于基于softmax的融合为,对于快速归一化融合为总和为1。有趣的是,归一化后的权重在训练过程中迅速变化,表明不同的特征对特征融合的贡献不均。尽管变化迅速,但我们的快速归一化融合方法对于所有三个节点始终显示出与基于softmax的融合非常相似的学习行为。
精读
表6比较了三种具有不同模型尺寸的检测器中的softmax和快速归一化融合方法
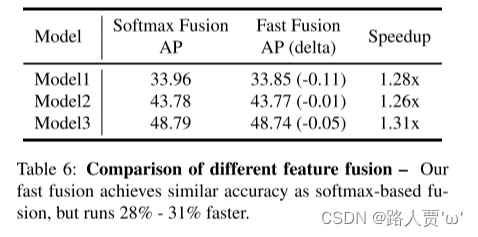
结论:快速归一化融合方法达到了与基于softmax的融合相似的准确性,但是在GPU上的运行速度提高了1.26倍至1.31倍。
图5展示了从EfficientDet-D3中的BiFPN层中随机选择的三个特征融合节点的学习权重
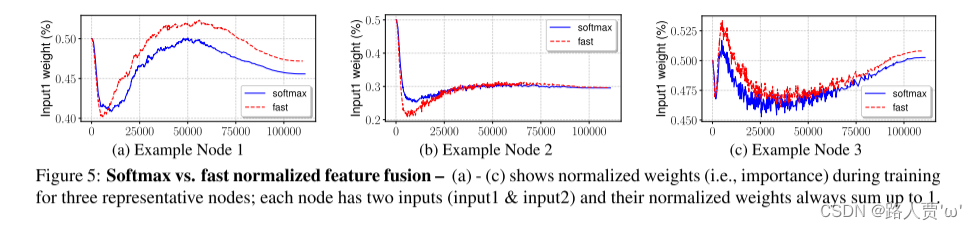
结论:快速归一化融合方法对于所有三个节点始终显示出与基于softmax的融合非常相似的学习行为。
6.4 Compound Scaling—复合缩放
翻译
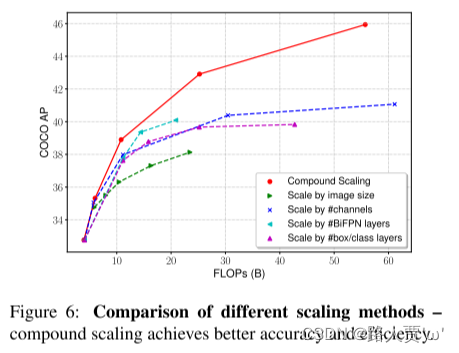
如第4.2节中所述,我们采用复合缩放方法来联合缩放主干,BiFPN和框/类预测网络的深度/宽度/分辨率的所有维度。图6比较了我们的复合缩放比例和其他按比例缩放分辨率/深度/宽度的替代方法。尽管从相同的基线检测器开始,但我们的复合缩放方法比其他方法具有更高的效率,这表明通过更好地平衡不同的体系结构尺寸可以共同缩放。
精读
图6比较了我们的复合缩放比例和其他按比例缩放分辨率/深度/宽度的替代方法。
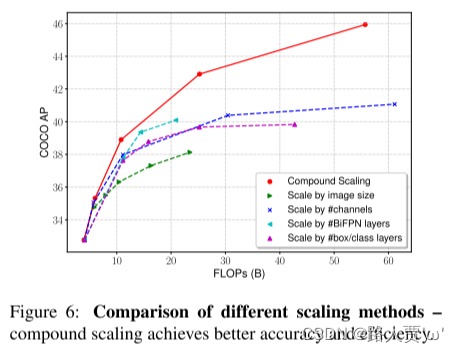
结论:通过更好地平衡不同的体系结构尺寸可以共同缩放。
七、Conclusion—结论
翻译
在本文中,我们系统地研究了用于有效目标检测的网络体系结构设计选择,并提出了加权双向特征网络和自定义复合缩放方法,以提高准确性和效率。基于这些优化,我们开发了一个名为EfficientDet的新检测器系列,该检测器在广泛的资源限制范围内始终比现有技术具有更高的准确性和效率。尤其是,与以前的对象检测和语义分割模型相比,我们扩展后的EfficientDet具有最新的准确性,并且参数和FLOP少得多。
精读
EfficientDet使用了一个高效的backbone,既创造了一个新的多尺度特征融合网络BiFPN,并通过额外的可学习行的加权特征处理,实现了精确度上的提高。
研究成果:
(1)高效特征融合
(2)可适配不同硬件的不同网络结构
(3)高精度参数量
🌟代码实现
# Copyright (c) OpenMMLab. All rights reserved.
# Modified from https://github.com/zylo117/Yet-Another-EfficientDet-Pytorch
from typing import List
import torch
import torch.nn as nn
from mmcv.cnn.bricks import Swish
from mmengine.model import BaseModule
from mmdet.registry import MODELS
from mmdet.utils import MultiConfig, OptConfigType
from .utils import (DepthWiseConvBlock, DownChannelBlock, MaxPool2dSamePadding,
MemoryEfficientSwish)
class BiFPNStage(nn.Module):
'''
in_channels: List[int], input dim for P3, P4, P5
out_channels: int, output dim for P2 - P7
first_time: int, whether is the first bifpnstage
num_outs: int, BiFPN need feature maps num
use_swish: whether use MemoryEfficientSwish
norm_cfg: (:obj:`ConfigDict` or dict, optional): Config dict for
normalization layer.
epsilon: float, hyperparameter in fusion features
'''
def __init__(self,
in_channels: List[int],
out_channels: int,
first_time: bool = False,
apply_bn_for_resampling: bool = True,
conv_bn_act_pattern: bool = False,
use_meswish: bool = True,
norm_cfg: OptConfigType = dict(
type='BN', momentum=1e-2, eps=1e-3),
epsilon: float = 1e-4) -> None:
super().__init__()
assert isinstance(in_channels, list)
self.in_channels = in_channels
self.out_channels = out_channels
self.first_time = first_time
self.apply_bn_for_resampling = apply_bn_for_resampling
self.conv_bn_act_pattern = conv_bn_act_pattern
self.use_meswish = use_meswish
self.norm_cfg = norm_cfg
self.epsilon = epsilon
if self.first_time:
self.p5_down_channel = DownChannelBlock(
self.in_channels[-1],
self.out_channels,
apply_norm=self.apply_bn_for_resampling,
conv_bn_act_pattern=self.conv_bn_act_pattern,
norm_cfg=norm_cfg)
self.p4_down_channel = DownChannelBlock(
self.in_channels[-2],
self.out_channels,
apply_norm=self.apply_bn_for_resampling,
conv_bn_act_pattern=self.conv_bn_act_pattern,
norm_cfg=norm_cfg)
self.p3_down_channel = DownChannelBlock(
self.in_channels[-3],
self.out_channels,
apply_norm=self.apply_bn_for_resampling,
conv_bn_act_pattern=self.conv_bn_act_pattern,
norm_cfg=norm_cfg)
self.p5_to_p6 = nn.Sequential(
DownChannelBlock(
self.in_channels[-1],
self.out_channels,
apply_norm=self.apply_bn_for_resampling,
conv_bn_act_pattern=self.conv_bn_act_pattern,
norm_cfg=norm_cfg), MaxPool2dSamePadding(3, 2))
self.p6_to_p7 = MaxPool2dSamePadding(3, 2)
self.p4_level_connection = DownChannelBlock(
self.in_channels[-2],
self.out_channels,
apply_norm=self.apply_bn_for_resampling,
conv_bn_act_pattern=self.conv_bn_act_pattern,
norm_cfg=norm_cfg)
self.p5_level_connection = DownChannelBlock(
self.in_channels[-1],
self.out_channels,
apply_norm=self.apply_bn_for_resampling,
conv_bn_act_pattern=self.conv_bn_act_pattern,
norm_cfg=norm_cfg)
self.p6_upsample = nn.Upsample(scale_factor=2, mode='nearest')
self.p5_upsample = nn.Upsample(scale_factor=2, mode='nearest')
self.p4_upsample = nn.Upsample(scale_factor=2, mode='nearest')
self.p3_upsample = nn.Upsample(scale_factor=2, mode='nearest')
# bottom to up: feature map down_sample module
self.p4_down_sample = MaxPool2dSamePadding(3, 2)
self.p5_down_sample = MaxPool2dSamePadding(3, 2)
self.p6_down_sample = MaxPool2dSamePadding(3, 2)
self.p7_down_sample = MaxPool2dSamePadding(3, 2)
# Fuse Conv Layers
self.conv6_up = DepthWiseConvBlock(
out_channels,
out_channels,
apply_norm=self.apply_bn_for_resampling,
conv_bn_act_pattern=self.conv_bn_act_pattern,
norm_cfg=norm_cfg)
self.conv5_up = DepthWiseConvBlock(
out_channels,
out_channels,
apply_norm=self.apply_bn_for_resampling,
conv_bn_act_pattern=self.conv_bn_act_pattern,
norm_cfg=norm_cfg)
self.conv4_up = DepthWiseConvBlock(
out_channels,
out_channels,
apply_norm=self.apply_bn_for_resampling,
conv_bn_act_pattern=self.conv_bn_act_pattern,
norm_cfg=norm_cfg)
self.conv3_up = DepthWiseConvBlock(
out_channels,
out_channels,
apply_norm=self.apply_bn_for_resampling,
conv_bn_act_pattern=self.conv_bn_act_pattern,
norm_cfg=norm_cfg)
self.conv4_down = DepthWiseConvBlock(
out_channels,
out_channels,
apply_norm=self.apply_bn_for_resampling,
conv_bn_act_pattern=self.conv_bn_act_pattern,
norm_cfg=norm_cfg)
self.conv5_down = DepthWiseConvBlock(
out_channels,
out_channels,
apply_norm=self.apply_bn_for_resampling,
conv_bn_act_pattern=self.conv_bn_act_pattern,
norm_cfg=norm_cfg)
self.conv6_down = DepthWiseConvBlock(
out_channels,
out_channels,
apply_norm=self.apply_bn_for_resampling,
conv_bn_act_pattern=self.conv_bn_act_pattern,
norm_cfg=norm_cfg)
self.conv7_down = DepthWiseConvBlock(
out_channels,
out_channels,
apply_norm=self.apply_bn_for_resampling,
conv_bn_act_pattern=self.conv_bn_act_pattern,
norm_cfg=norm_cfg)
# weights
self.p6_w1 = nn.Parameter(
torch.ones(2, dtype=torch.float32), requires_grad=True)
self.p6_w1_relu = nn.ReLU()
self.p5_w1 = nn.Parameter(
torch.ones(2, dtype=torch.float32), requires_grad=True)
self.p5_w1_relu = nn.ReLU()
self.p4_w1 = nn.Parameter(
torch.ones(2, dtype=torch.float32), requires_grad=True)
self.p4_w1_relu = nn.ReLU()
self.p3_w1 = nn.Parameter(
torch.ones(2, dtype=torch.float32), requires_grad=True)
self.p3_w1_relu = nn.ReLU()
self.p4_w2 = nn.Parameter(
torch.ones(3, dtype=torch.float32), requires_grad=True)
self.p4_w2_relu = nn.ReLU()
self.p5_w2 = nn.Parameter(
torch.ones(3, dtype=torch.float32), requires_grad=True)
self.p5_w2_relu = nn.ReLU()
self.p6_w2 = nn.Parameter(
torch.ones(3, dtype=torch.float32), requires_grad=True)
self.p6_w2_relu = nn.ReLU()
self.p7_w2 = nn.Parameter(
torch.ones(2, dtype=torch.float32), requires_grad=True)
self.p7_w2_relu = nn.ReLU()
self.swish = MemoryEfficientSwish() if use_meswish else Swish()
def combine(self, x):
if not self.conv_bn_act_pattern:
x = self.swish(x)
return x
def forward(self, x):
if self.first_time:
p3, p4, p5 = x # [(1,40,64,64),(1,112,32,32),(1,320,16,16)]
# build feature map P6
p6_in = self.p5_to_p6(p5) # (1,64,8,8)
# build feature map P7
p7_in = self.p6_to_p7(p6_in) # (1,64,4,4)
p3_in = self.p3_down_channel(p3) # (1,64,64,64)
p4_in = self.p4_down_channel(p4) # (1,64,32,32)
p5_in = self.p5_down_channel(p5) # (1,64,16,16)
else:
p3_in, p4_in, p5_in, p6_in, p7_in = x
# Weights for P6_0 and P7_0 to P6_1
p6_w1 = self.p6_w1_relu(self.p6_w1)
weight = p6_w1 / (torch.sum(p6_w1, dim=0) + self.epsilon)
# Connections for P6_0 and P7_0 to P6_1 respectively
p6_up = self.conv6_up(
self.combine(weight[0] * p6_in +
weight[1] * self.p6_upsample(p7_in))) # (1,64,8,8)
# Weights for P5_0 and P6_1 to P5_1
p5_w1 = self.p5_w1_relu(self.p5_w1)
weight = p5_w1 / (torch.sum(p5_w1, dim=0) + self.epsilon)
# Connections for P5_0 and P6_1 to P5_1 respectively
p5_up = self.conv5_up(
self.combine(weight[0] * p5_in +
weight[1] * self.p5_upsample(p6_up))) # (1,64,16,16)
# Weights for P4_0 and P5_1 to P4_1
p4_w1 = self.p4_w1_relu(self.p4_w1)
weight = p4_w1 / (torch.sum(p4_w1, dim=0) + self.epsilon)
# Connections for P4_0 and P5_1 to P4_1 respectively
p4_up = self.conv4_up(
self.combine(weight[0] * p4_in +
weight[1] * self.p4_upsample(p5_up))) # (1,64,32,32)
# Weights for P3_0 and P4_1 to P3_2
p3_w1 = self.p3_w1_relu(self.p3_w1)
weight = p3_w1 / (torch.sum(p3_w1, dim=0) + self.epsilon)
# Connections for P3_0 and P4_1 to P3_2 respectively
p3_out = self.conv3_up(
self.combine(weight[0] * p3_in +
weight[1] * self.p3_upsample(p4_up))) # (1,64,64,64)
if self.first_time:
# self.p4_level_connection和self.p4_down_channel是一样的,为什么不能直接用上面的p4_in?
p4_in = self.p4_level_connection(p4)
p5_in = self.p5_level_connection(p5)
# Weights for P4_0, P4_1 and P3_2 to P4_2
p4_w2 = self.p4_w2_relu(self.p4_w2)
weight = p4_w2 / (torch.sum(p4_w2, dim=0) + self.epsilon)
# Connections for P4_0, P4_1 and P3_2 to P4_2 respectively
p4_out = self.conv4_down(
self.combine(weight[0] * p4_in + weight[1] * p4_up +
weight[2] * self.p4_down_sample(p3_out))) # (1,64,32,32)
# Weights for P5_0, P5_1 and P4_2 to P5_2
p5_w2 = self.p5_w2_relu(self.p5_w2)
weight = p5_w2 / (torch.sum(p5_w2, dim=0) + self.epsilon)
# Connections for P5_0, P5_1 and P4_2 to P5_2 respectively
p5_out = self.conv5_down(
self.combine(weight[0] * p5_in + weight[1] * p5_up +
weight[2] * self.p5_down_sample(p4_out))) # (1,64,16,16)
# Weights for P6_0, P6_1 and P5_2 to P6_2
p6_w2 = self.p6_w2_relu(self.p6_w2)
weight = p6_w2 / (torch.sum(p6_w2, dim=0) + self.epsilon)
# Connections for P6_0, P6_1 and P5_2 to P6_2 respectively
p6_out = self.conv6_down(
self.combine(weight[0] * p6_in + weight[1] * p6_up +
weight[2] * self.p6_down_sample(p5_out))) # (1,64,8,8)
# Weights for P7_0 and P6_2 to P7_2
p7_w2 = self.p7_w2_relu(self.p7_w2)
weight = p7_w2 / (torch.sum(p7_w2, dim=0) + self.epsilon)
# Connections for P7_0 and P6_2 to P7_2
p7_out = self.conv7_down(
self.combine(weight[0] * p7_in +
weight[1] * self.p7_down_sample(p6_out))) # (1,64,4,4)
return p3_out, p4_out, p5_out, p6_out, p7_out
@MODELS.register_module()
class BiFPN(BaseModule):
'''
num_stages: int, bifpn number of repeats
in_channels: List[int], input dim for P3, P4, P5
out_channels: int, output dim for P2 - P7
start_level: int, Index of input features in backbone
epsilon: float, hyperparameter in fusion features
apply_bn_for_resampling: bool, whether use bn after resampling
conv_bn_act_pattern: bool, whether use conv_bn_act_pattern
use_swish: whether use MemoryEfficientSwish
norm_cfg: (:obj:`ConfigDict` or dict, optional): Config dict for
normalization layer.
init_cfg: MultiConfig: init method
'''
def __init__(self,
num_stages: int,
in_channels: List[int],
out_channels: int,
start_level: int = 0,
epsilon: float = 1e-4,
apply_bn_for_resampling: bool = True,
conv_bn_act_pattern: bool = False,
use_meswish: bool = True,
norm_cfg: OptConfigType = dict(
type='BN', momentum=1e-2, eps=1e-3),
init_cfg: MultiConfig = None) -> None:
super().__init__(init_cfg=init_cfg)
self.start_level = start_level
self.bifpn = nn.Sequential(*[
BiFPNStage(
in_channels=in_channels,
out_channels=out_channels,
first_time=True if _ == 0 else False,
apply_bn_for_resampling=apply_bn_for_resampling,
conv_bn_act_pattern=conv_bn_act_pattern,
use_meswish=use_meswish,
norm_cfg=norm_cfg,
epsilon=epsilon) for _ in range(num_stages)
])
def forward(self, x):
# [(1,40,64,64),(1,112,32,32),(1,320,16,16)]
x = x[self.start_level:]
x = self.bifpn(x)
return x



















 779
779

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











