










论文阅读
感谢p导
EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks
本文主要工作是提出了一个在三个维度上(图像分辨率R、网络深度D、channel的宽度W)的合理scale方法。
在之前的一些论文中,基本都是通过改变上述3个参数中的一个来提升网络的性能。通过增加网络深度,例如block的堆叠;增加网络宽度,增加每层feature map的channel个数;增加图像的分辨率以求获得更多的信息,让网络能得到更多的特征从而从这三个维度上来提升精度
而这篇论文就是同时来探索这三个参数的影响,并使用NAS得到了一个baseline模型EfficientNetB0,通过同时调整这三个参数,得到了一系列的EfficientNet

例如上图,(a)就是baseline网络,在本文中的baseline是通过NAS得到的,(b)是增加宽度,也就是每层的channel个数,©是增加深度也就是增加每个stage的layers,(d)是增加分辨率,也就是每层的featuremap的size,(e)是本文提出的混合scale method,来以恒定比例进行scale up

上图为EfficientNet和其他网络的比较,可以看出EfficientNet在同等FLOPs下比其他网络更加有效
scale up深度是我们经常使用的方法用来提高精度。我们在scale up深度的时候,可能会碰到很多问题,比如梯度消失,我们可以使用skip connection和Batch normalization来解决这个问题
如果我们scale up 模型的宽度的话,在每层会得到更多fine-grained feature,但是如果我们只处理宽度这个维度的话,很浅的网络是无法处理更高层的features
如果我们scale up 模型的深度的话,会在一个比例之后达到瓶颈期
因此我们需要Compound scaling


如果我们只是随便的对三个维度进行任意的组合scale up,带来的cost与acc的提升可能是不匹配的,也就是比带来的准确率的提升更多的cost

我们需要在三个维度中达到一个平衡,因此作者提出了一个方法。
使用了一个混合因子ϕ 去统一的缩放width,depth,resolution参数,具体的计算公式如下,其中. s.t代表限制条件
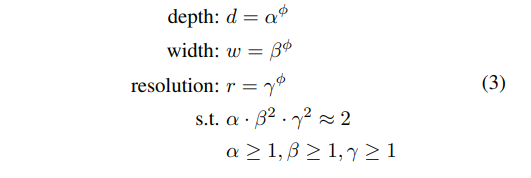
FLOPs(理论计算量)与depth的关系是:当depth翻倍,FLOPs也翻倍。
FLOPs与width的关系是:当width翻倍(即channal翻倍),FLOPs会翻4倍
FLOPs与resolution的关系是:当resolution翻倍,FLOPs也会翻4倍

接下来作者在基准网络EfficientNetB07上使用NAS来搜索α , β , γ 这三个参数,主要分为两个step:
首先固定ϕ 去探寻最佳的三个参数,之后固定三个参数,探索ϕ ,

作者也说,如果在比较大的模型上去搜寻三个参数的话,可能会达到更好的performance,但是搜索成本过于expensive。所以就只在small baseline网络上进行搜寻了一次

B0的网络结构,就是使用了MBConv的结构,进行堆叠,在其中添加了SE模块,第一个MBstage的升维系数为1,所以不需要MBConv中的第一个conv 1x1 ,MBConv中使用的激活函数为Swish,在模块中的最后一个conv 1x1没有使用激活函数

MBConv结构
下图为P导绘制的图博客链接

代码实现
model
import math
import copy
import torch
import torch.nn as nn
from torch import Tensor
from functools import partial
import torch.nn.functional as F
from typing import Callable, Optional, OrderedDict
# 将输入的ch 调整到最近的divisor倍
def _make_divisible(ch, divisor=8, min_ch=None):
if min_ch is None:
min_ch = divisor
new_ch = max(min_ch, int(ch + divisor / 2) // divisor * divisor)
# Make sure that round down does not go down by more than 10%.
if new_ch < 0.9 * ch:
new_ch += divisor
return new_ch
# 继承nn.Sequential的话,不需要写对应的forward,如果需要重写也是可以的
# Conv+BN+Ac
class ConvBnActivation(nn.Sequential):
# group来控制是否使用DW卷积
def __init__(self,
in_channels: int,
out_channels: int,
kernel_size: int = 3,
stride: int = 1,
groups: int = 1,
norm_layer: Optional[Callable[..., nn.Module]] = None,
activation_layer: Optional[Callable[..., nn.Module]] = None):
padding = (kernel_size-1)//2
if norm_layer is None:
norm_layer = nn.BatchNorm2d
if activation_layer is None:
activation_layer = nn.SiLU # Swish激活函数 ,torch>1.7
super(ConvBnActivation, self).__init__(nn.Conv2d(
in_channels=in_channels,
out_channels=out_channels,
kernel_size=kernel_size,
stride=stride,
padding=padding,
groups=groups,
bias=False),
norm_layer(out_channels),
activation_layer()
)
# Se注意力模块
class SqueezeExcitation(nn.Module):
def __init__(self,
in_channels: int,
expand_channels: int,
squeeze_factor: int = 4):
super(SqueezeExcitation, self).__init__()
squeeze_c = in_channels//squeeze_factor
self.fc1 = nn.Conv2d(expand_channels, squeeze_c, 1)
self.ac1 = nn.SiLU()
self.fc2 = nn.Conv2d(squeeze_c, expand_channels, 1)
self.ac2 = nn.Sigmoid()
def forward(self, x: Tensor) -> Tensor:
scale = F.adaptive_avg_pool2d(x, output_size=(1, 1))
scale = self.fc1(scale)
scale = self.ac1(scale)
scale = self.fc2(scale)
scale = self.ac2(scale)
return scale*x
# MbConv模块的config
class InvertedResidualConfig:
def __init__(self,
kernel_size: int, # 3 or 5 Dw卷积的kernel大小
in_channels: int,
out_channels: int,
expanded_ratio: int, # 1 or6 倒置瓶颈层的第一个conv 1x1的升维倍数
stride: int, # 1 or 2 Dw卷积的步距
use_SE: bool, # True 该网络中都是True
drop_rate: float, # 最后一个dropout层
index: str, # 1a ,2a, 2b,...当前模块的位置名称
width_coefficient: float # 宽度方向的倍率因子
):
self.in_channels = self.adjust_channels(in_channels, width_coefficient)
self.kernel_size = kernel_size
self.expanded_channels = self.in_channels*expanded_ratio
self.out_channels = self.adjust_channels(
out_channels, width_coefficient)
self.use_SE = use_SE
self.stride = stride
self.drop_rate = drop_rate
self.index = index
@staticmethod
def adjust_channels(channels: int, width_coefficient: float):
return _make_divisible(channels*width_coefficient, 8)
# MbConv模块的搭建
class InvertedResidual(nn.Module):
def __init__(self,
config: InvertedResidualConfig,
norm_layer: Callable[..., nn.Module]):
super(InvertedResidual, self).__init__()
if config.stride not in [1, 2]:
raise ValueError('illegal stride value.')
self.use_res_connect = (
config.stride == 1 and config.in_channels == config.out_channels)
layers = OrderedDict()
activation_layer = nn.SiLU
# expand,第一个的expand系数为1,是不需要第一个Conv1x1的,就不需要update该层
if config.expanded_channels != config.in_channels:
layers.update({'expand_conv': ConvBnActivation(
config.in_channels,
config.expanded_channels,
kernel_size=1,
norm_layer=norm_layer,
activation_layer=activation_layer)})
# 第二个dw卷积
layers.update({'dw_conv': ConvBnActivation(
config.expanded_channels,
config.expanded_channels,
kernel_size=config.kernel_size,
groups=config.expanded_channels,
norm_layer=norm_layer,
activation_layer=activation_layer)})
# SE注意力模块
if config.use_SE:
layers.update({"se": SqueezeExcitation(
config.in_channels, config.expanded_channels)})
# 第三个pw卷积
layers.update({'project_conv': ConvBnActivation(
config.expanded_channels,
config.out_channels,
kernel_size=1,
norm_layer=norm_layer,
activation_layer=nn.Identity # 最后一个1x1的conv是不需要激活函数的,使用nn.Identity即可
)})
self.block = nn.Sequential(layers)
self.out_channels = config.out_channels
self.is_stride = config.stride > 1
# 只有在使用shortcut连接时才使用dropout层
if self.use_res_connect and config.drop_rate > 0:
self.dropout = nn.Dropout2d(p=config.drop_rate, inplace=True)
else:
self.dropout = nn.Identity()
def forward(self, x: Tensor) -> Tensor:
result = self.block(x)
result = self.dropout(result)
if self.use_res_connect:
result += x
return result
class EfficientNet(nn.Module):
def __init__(self,
width_coefficient: float,
depth_coefficient: float,
num_classes: int = 1000,
dropout_ratio: float = 0.2, # 最后一层的dropout
drop_connect_ratio: float = 0.2, # MB模块的Dropout
block: Optional[Callable[..., nn.Module]] = None,
norm_layer: Optional[Callable[..., nn.Module]] = None
):
super(EfficientNet, self).__init__()
# EfficientNetB0的默认配置
# kernel_size ,in_channels,out_channels,expand_ratio,stride,use_SE,dropout_ratio,repeat
default_config = [[3, 32, 16, 1, 1, True, drop_connect_ratio, 1],
[3, 16, 24, 6, 2, True, drop_connect_ratio, 2],
[5, 24, 40, 6, 2, True, drop_connect_ratio, 2],
[3, 40, 80, 6, 2, True, drop_connect_ratio, 3],
[5, 80, 112, 6, 1, True, drop_connect_ratio, 3],
[5, 112, 192, 6, 2, True, drop_connect_ratio, 4],
[3, 192, 320, 6, 1, True, drop_connect_ratio, 1]]
def round_repeats(repeats):
# 每个stage的重复次数与depth_coefficient也有关系,不针对第一个MB
return int(math.ceil(depth_coefficient*repeats))
if block is None:
block = InvertedResidual
if norm_layer is None:
norm_layer = partial(nn.BatchNorm2d, eps=1e-3, momentum=0.1)
adjust_channels = partial(
InvertedResidualConfig.adjust_channels, width_coefficient=width_coefficient)
bneck_conf = partial(InvertedResidualConfig,
width_coefficient=width_coefficient)
b = 0
num_blocks = float(sum(round_repeats(i[-1]) for i in default_config))
inverted_residual_setting = []
for stage, args in enumerate(default_config):
config = copy.copy(args)
# 取出每个阶段的MB个数 repeat
for i in range(round_repeats(config.pop(-1))):
if i > 0:
config[-3] = 1
config[1] = config[2]
config[-1] *= b/num_blocks # dropout是随着堆叠MB个数慢慢增长到Dropout=0.2
index = str(stage+1)+chr(i+97)
inverted_residual_setting.append(bneck_conf(*config, index))
b += 1
layers = OrderedDict()
layers.update({"stem_conv": ConvBnActivation(in_channels=3, out_channels=adjust_channels(
32), kernel_size=3, stride=2, norm_layer=norm_layer)})
for config in inverted_residual_setting:
layers.update(
{config.index: block(config=config, norm_layer=norm_layer)})
last_conv_in_channels = inverted_residual_setting[-1].out_channels
last_conv_out_channels = adjust_channels(1280)
layers.update({'top': ConvBnActivation(in_channels=last_conv_in_channels,
out_channels=last_conv_out_channels, kernel_size=1, norm_layer=norm_layer)})
self.features = nn.Sequential(layers)
self.avgpool = nn.AdaptiveAvgPool2d(1)
classifier = []
if dropout_ratio > 0:
classifier.append(nn.Dropout(p=dropout_ratio, inplace=True))
classifier.append(nn.Linear(last_conv_out_channels, num_classes))
self.clasifier = nn.Sequential(*classifier)
for m in self.modules():
if isinstance(m,nn.Conv2d):
nn.init.kaiming_normal_(m.weight,mode='fan_out')
if m.bias is not None:
nn.init.zeros_(m.bias)
elif isinstance(m,nn.BatchNorm2d):
nn.init.ones_(m.weight)
nn.init.zeros_(m.bias)
elif isinstance(m,nn.Linear):
nn.init.normal_(m.weight,0,0.01)
nn.init.zeros_(m.bias)
def forward(self, x: Tensor) -> Tensor:
x = self.features(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.classifier(x)
return x
def efficientnet_b0(num_classes=1000):
# input image size 224x224
return EfficientNet(width_coefficient=1.0,
depth_coefficient=1.0,
dropout_ratio=0.2,
num_classes=num_classes)
def efficientnet_b1(num_classes=1000):
# input image size 240x240
return EfficientNet(width_coefficient=1.0,
depth_coefficient=1.1,
dropout_ratio=0.2,
num_classes=num_classes)
def efficientnet_b2(num_classes=1000):
# input image size 260x260
return EfficientNet(width_coefficient=1.1,
depth_coefficient=1.2,
dropout_ratio=0.3,
num_classes=num_classes)
def efficientnet_b3(num_classes=1000):
# input image size 300x300
return EfficientNet(width_coefficient=1.2,
depth_coefficient=1.4,
dropout_ratio=0.3,
num_classes=num_classes)
def efficientnet_b4(num_classes=1000):
# input image size 380x380
return EfficientNet(width_coefficient=1.4,
depth_coefficient=1.8,
dropout_ratio=0.4,
num_classes=num_classes)
def efficientnet_b5(num_classes=1000):
# input image size 456x456
return EfficientNet(width_coefficient=1.6,
depth_coefficient=2.2,
dropout_ratio=0.4,
num_classes=num_classes)
def efficientnet_b6(num_classes=1000):
# input image size 528x528
return EfficientNet(width_coefficient=1.8,
depth_coefficient=2.6,
dropout_ratio=0.5,
num_classes=num_classes)
def efficientnet_b7(num_classes=1000):
# input image size 600x600
return EfficientNet(width_coefficient=2.0,
depth_coefficient=3.1,
dropout_ratio=0.5,
num_classes=num_classes)
train
import os
import math
import argparse
from tqdm import tqdm
import sys
import torch
import torch.optim as optim
from torchvision import transforms
from torchvision import datasets
import torch.optim.lr_scheduler as lr_scheduler
from model_v1 import efficientnet_b0 as create_model
def main(args):
device = torch.device(args.device if torch.cuda.is_available() else "cpu")
print(args)
batch_size = args.batch_size
nw = min([os.cpu_count(), batch_size if batch_size > 1 else 0, 8]) # number of workers
print('Using {} dataloader workers every process'.format(nw))
if os.path.exists("./weights") is False:
os.makedirs("./weights")
img_size = {"B0": 224,
"B1": 240,
"B2": 260,
"B3": 300,
"B4": 380,
"B5": 456,
"B6": 528,
"B7": 600}
num_model = "B0"
data_transform = {
"train": transforms.Compose([transforms.RandomResizedCrop(img_size[num_model]),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])]),
"val": transforms.Compose([transforms.Resize(img_size[num_model]),
transforms.CenterCrop(img_size[num_model]),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])}
train_dataset = datasets.ImageFolder(root=os.path.join(args.data_path, "train"),
transform=data_transform["train"])
val_dataset = datasets.ImageFolder(root=os.path.join(args.data_path, "val"),
transform=data_transform["val"])
train_loader = torch.utils.data.DataLoader(train_dataset,
batch_size=batch_size,
shuffle=True,
num_workers=nw,
)
val_loader = torch.utils.data.DataLoader(val_dataset,
batch_size=batch_size,
shuffle=False,
num_workers=nw,
)
val_num = len(val_dataset)
train_num = len(train_dataset)
print("using {} images for training, {} images for validation.".format(train_num,
val_num))
# 如果存在预训练权重则载入
model = create_model(num_classes=args.num_classes).to(device)
if args.weights != "":
if os.path.exists(args.weights):
weights_dict = torch.load(args.weights, map_location=device)
load_weights_dict = {k: v for k, v in weights_dict.items()
if model.state_dict()[k].numel() == v.numel()}
print(model.load_state_dict(load_weights_dict, strict=False))
else:
raise FileNotFoundError("not found weights file: {}".format(args.weights))
# 是否冻结权重
if args.freeze_layers:
for name, para in model.named_parameters():
# 除最后一个卷积层和全连接层外,其他权重全部冻结
if ("features.top" not in name) and ("classifier" not in name):
para.requires_grad_(False)
else:
print("training {}".format(name))
pg = [p for p in model.parameters() if p.requires_grad]
optimizer = optim.SGD(pg, lr=args.lr, momentum=0.9, weight_decay=1E-4)
lf = lambda x: ((1 + math.cos(x * math.pi / args.epochs)) / 2) * (1 - args.lrf) + args.lrf # cosine
scheduler = lr_scheduler.LambdaLR(optimizer, lr_lambda=lf)
loss_function = torch.nn.CrossEntropyLoss()
for epoch in range(args.epochs):
# train
model.train()
mean_loss = torch.zeros(1).to(device)
optimizer.zero_grad()
train_bar = tqdm(train_loader)
for step, data in enumerate(train_bar):
images, labels = data
pred = model(images.to(device))
loss = loss_function(pred, labels.to(device))
loss.backward()
mean_loss = (mean_loss * step + loss.detach()) / (step + 1) # update mean losses
train_bar.desc = "[epoch {}] mean loss {}".format(epoch, round(mean_loss.item(), 3))
if not torch.isfinite(loss):
print('WARNING: non-finite loss, ending training ', loss)
sys.exit(1)
optimizer.step()
optimizer.zero_grad()
scheduler.step()#调整lr
model.eval()
with torch.no_grad():
# 验证样本总个数
total_num = len(val_loader.dataset)
# 用于存储预测正确的样本个数
sum_num = torch.zeros(1).to(device)
data_loader = tqdm(val_loader)
for step, data in enumerate(data_loader):
images, labels = data
pred = model(images.to(device))
pred = torch.max(pred, dim=1)[1]
sum_num += torch.eq(pred, labels.to(device)).sum()
acc=sum_num.item() / total_num
print("[epoch {}] accuracy: {}".format(epoch, round(acc, 3)))
tags = ["loss", "accuracy", "learning_rate"]
torch.save(model.state_dict(), "./weights/model-{}.pth".format(epoch))
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--num_classes', type=int, default=5)
parser.add_argument('--epochs', type=int, default=30)
parser.add_argument('--batch_size', type=int, default=128)
parser.add_argument('--lr', type=float, default=0.01)
parser.add_argument('--lrf', type=float, default=0.01)
# 数据集所在根目录
# http://download.tensorflow.org/example_images/flower_photos.tgz
parser.add_argument('--data-path', type=str,
default="../dataset/flower_data")
# download model weights
# 链接: https://pan.baidu.com/s/1ouX0UmjCsmSx3ZrqXbowjw 密码: 090i
parser.add_argument('--weights', type=str, default='./efficientnetb0.pth',
help='initial weights path')
parser.add_argument('--freeze-layers', type=bool, default=False)
parser.add_argument('--device', default='cuda:0', help='device id (i.e. 0 or 0,1 or cpu)')
opt = parser.parse_args()
main(opt)
predict
import os
import json
import torch
from PIL import Image
from torchvision import transforms
import matplotlib.pyplot as plt
from model import efficientnet_b0 as create_model
def main():
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
img_size = {"B0": 224,
"B1": 240,
"B2": 260,
"B3": 300,
"B4": 380,
"B5": 456,
"B6": 528,
"B7": 600}
num_model = "B0"
data_transform = transforms.Compose(
[transforms.Resize(img_size[num_model]),
transforms.CenterCrop(img_size[num_model]),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])
# load image
img_path = "../tulip.jpg"
assert os.path.exists(img_path), "file: '{}' dose not exist.".format(img_path)
img = Image.open(img_path)
plt.imshow(img)
# [N, C, H, W]
img = data_transform(img)
# expand batch dimension
img = torch.unsqueeze(img, dim=0)
# read class_indict
json_path = './class_indices.json'
assert os.path.exists(json_path), "file: '{}' dose not exist.".format(json_path)
json_file = open(json_path, "r")
class_indict = json.load(json_file)
# create model
model = create_model(num_classes=5).to(device)
# load model weights
model_weight_path = "./weights/model-29.pth"
model.load_state_dict(torch.load(model_weight_path, map_location=device))
model.eval()
with torch.no_grad():
# predict class
output = torch.squeeze(model(img.to(device))).cpu()
predict = torch.softmax(output, dim=0)
predict_cla = torch.argmax(predict).numpy()
print_res = "class: {} prob: {:.3}".format(class_indict[str(predict_cla)],
predict[predict_cla].numpy())
plt.title(print_res)
print(print_res)
plt.show()
if __name__ == '__main__':
main()
实验结果
这个卡跑不动,然后就没跑实验















 932
932











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









