









引言
我做嵌入式的,从开始学python到项目落地花了一个半月
先从学python语法、再搭建yolov10开发环境、接着准备数据、训练数据、模型应用
准备数据从拍摄到训练所需的txt文件用时八个工作日
最小模型训练时间在半天左右
最大模型训练时间在三天左右
m模型训练时间在2.5天左右
有很多坑没有记录,但流程大差不差
环境搭建
环境:
开发环境:
系统环境: Windows 10
开发环境: Miniconda3 + python
1. yolov10
2. opencv + onnxruntime
IDE: vscode + pycham
yolov10:
pytorch 2.3.1
CUDA 12.1
Miniconda3
根据需求 选择对应的 python版本 或 最新版 下载(个人使用的最新版)
官网下载 Miniconda3
下载后安装:
- 可更改 为全部用户安装
- 可更改 安装路径(我的安装路径:D:\ProgramData\miniconda3)
yolov10
视频资料可参考b站某up:
13分钟速通yolov10,使用自己的数据集从环境搭建到模型训练、推理
yolov10项目地址
使用git clone yolov10到本地
git clone https://github.com/THU-MIG/yolov10.git
conda 环境安装yolov10
根据官网提示部署yolov10
conda create -n yolov10 python=3.9
conda activate yolov10
pip install -r requirements.txt #打开这个文件可以换源安装
pip install -e .
切换到 克隆yolov10的本地地址(不切换编译会报错)我已经切换过了
数据下载:
VOC数据集介绍及下载
VOC2012挑战赛数据集官网下载
PS:其他训练数据可在对应yaml文件内找到
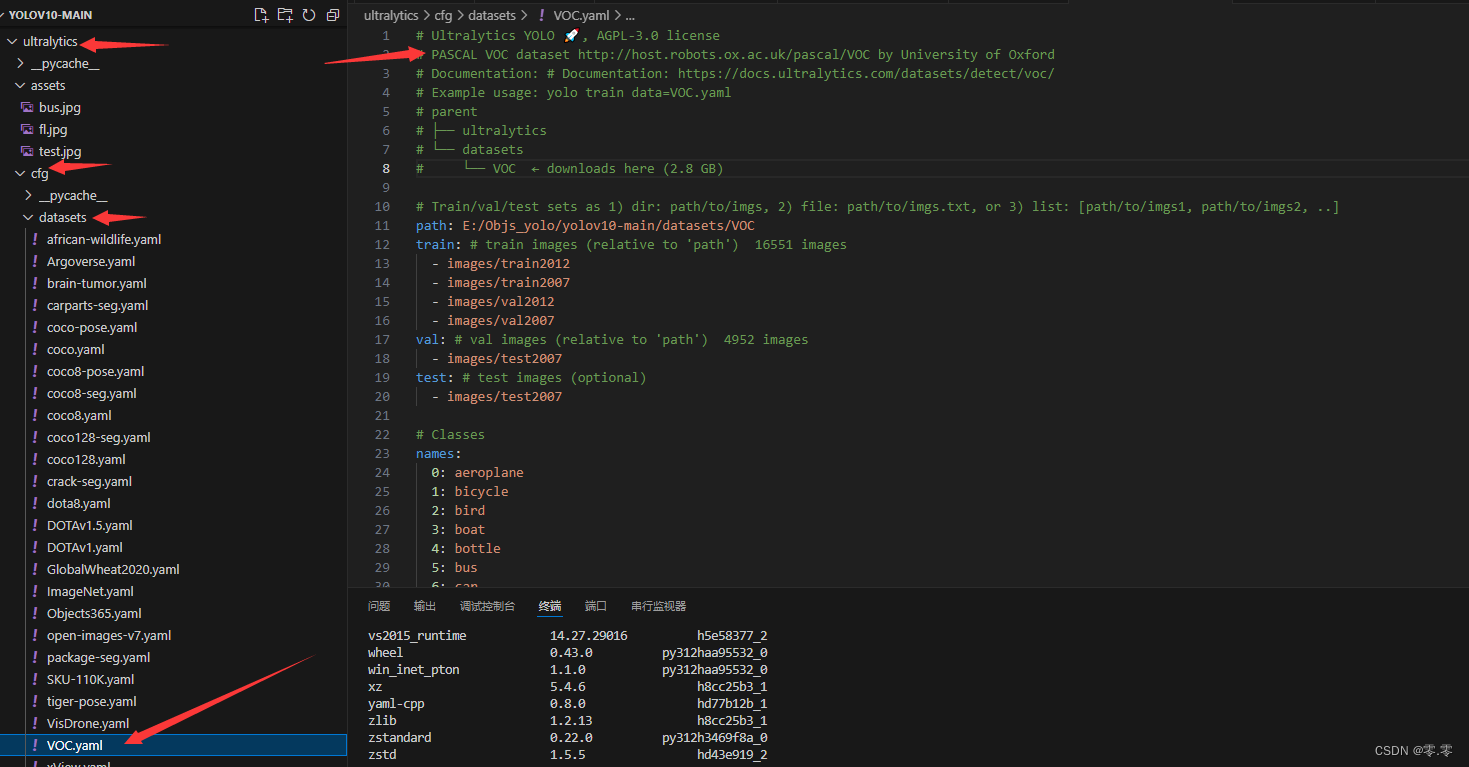
选择所需数据添加到项目,并更改voc路径
训练
# data 选择模型
# model 模型
# epochs 循环训练多少次
# batch 批次 根据显存调节
# imgsz 图片尺寸
# device 默认为 CPU 可改 GPU ; 选择用设备训练
#yolo detect train data=coco.yaml model=yolov10n/s/m/b/l/x.yaml epochs=500 batch=256 imgsz=640 device=0,1,2,3,4,5,6,7
# 用VOC模型训练,使用小模型,循环训练100次,模型输入图像大小640*640,单个设备训练
yolo detect train data=E:\Objs_yolo\yolov10-main\ultralytics\cfg\datasets\VOC.yaml model=yolov10n.yaml epochs=100 batch=32 imgsz=640 device=0

验证
# 这里我是用官方的 yolov10n 模型 voc 测试
# 自己训练的改 model 的地址
yolo val model=E:\Objs_yolo\yolov10-main\yolov10n.pt data=E:\Objs_yolo\yolov10-main\ultralytics\cfg\datasets\VOC.yaml batch=64
训练
准备数据
根据官网的数据结构可以看到需要的数据有原图和训练所需的txt文件,其存放的是准备好要训练的数据
数据标注
- 下载Labelme
转载的下载链接
也可使用其他数据标注软件,感兴趣可自行尝试,本人用的Labelme - 软件使用
可自行百度 - 数据
标注保存后会生成json文件
json转txt
将数据标注的json文件转换到模型训练的txt文件
txt文件格式:label_index, x_center, y_center, w, h
转换代码:
import json
import os
import glob
from tqdm import tqdm
# 你的标签
alables={'label0':0,'label1':1,'label2':2}
def convert_poly_to_rect(coordinateList):
X = [int(coordinateList[2 * i]) for i in range(int(len(coordinateList) / 2))]
Y = [int(coordinateList[2 * i + 1]) for i in range(int(len(coordinateList) / 2))]
Xmax = max(X)
Xmin = min(X)
Ymax = max(Y)
Ymin = min(Y)
flag = False
if (Xmax - Xmin) == 0 or (Ymax - Ymin) == 0:
flag = True
return [Xmin, Ymin, Xmax - Xmin, Ymax - Ymin], flag
def convert_labelme_json_to_txt(json_path, img_path, out_txt_path):
json_list = glob.glob(json_path + '/*.json')
num = len(json_list)
for json_path in tqdm(json_list):
with open(json_path, "r") as f_json:
json_data = json.loads(f_json.read())
infos = json_data['shapes']
if len(infos) == 0:
continue
img_w = json_data['imageWidth']
img_h = json_data['imageHeight']
image_name = json_data['imagePath']
image_path = os.path.join(img_path, image_name)
if not os.path.exists(img_path):
print(img_path, 'is None!')
continue
txt_name = os.path.basename(json_path).split('.')[0] + '.txt'
txt_path = os.path.join(out_txt_path, txt_name)
f = open(txt_path, 'w')
for label in infos:
points = label['points']
if len(points) < 2:
continue
if len(points) == 2:
x1 = points[0][0]
y1 = points[0][1]
x2 = points[1][0]
y2 = points[1][1]
points = [[x1, y1], [x2, y1], [x2, y2], [x1, y2]]
else:
if len(points) < 4:
continue
segmentation = []
for p in points:
segmentation.append(int(p[0]))
segmentation.append(int(p[1]))
bbox, flag = convert_poly_to_rect(list(segmentation))
x1, y1, w, h = bbox
if flag:
continue
x_center = x1 + w / 2
y_center = y1 + h / 2
norm_x = x_center / img_w
norm_y = y_center / img_h
norm_w = w / img_w
norm_h = h / img_h
obj_cls = alables[label['label']]
line = [obj_cls, norm_x, norm_y, norm_w, norm_h]
line = [str(ll) for ll in line]
line = ' '.join(line) + '\n'
f.write(line)
f.close()
if __name__ == "__main__":
# img_path = 'E:/Objs_yolo/yolov10-main/datasets/MyWork/train/images'
# json_path = 'E:/Objs_yolo/yolov10-main/datasets/MyWork/train/labels'
# out_txt_path = 'E:/Objs_yolo/yolov10-main/datasets/MyWork/train/labels'
img_path = 'E:/Objs_yolo/yolov10-main/datasets/MyWork/test/images'
json_path = 'E:/Objs_yolo/yolov10-main/datasets/MyWork/test/labels'
out_txt_path = 'E:/Objs_yolo/yolov10-main/datasets/MyWork/test/labels'
if not os.path.exists(out_txt_path):
os.makedirs(out_txt_path)
convert_labelme_json_to_txt(json_path, img_path, out_txt_path)
数据准备完成
使用GPU训练(CPU训练 可忽略)
- 查看驱动
支持CUDA,如果驱动版本不匹配需要降级或升级
使用命令行查看驱动版本:
nvidia-smi
nvcc -V
以nvcc -V为准,如图:
CUDA Version: 12.5
Cuda compilation tools, release 12.1, V12.1.105

-
查看对应版本
用conda环境安装,2.3.1,选择CUDA使用的版本(若版本不对需重装CUDA驱动或换typorth版本安装)
-
验证
import torch
import torch.nn as nn
num_gpus = 1
# 假设我们有一个简单的模型和数据
class SimpleModel(nn.Module):
def __init__(self):
super(SimpleModel, self).__init__()
self.fc = nn.Linear(10, 2) # 示例:一个全连接层
def forward(self, x):
return self.fc(x)
# 假设数据已经是一个Tensor
data = torch.randn(10, 10) # 示例数据,形状为 [batch_size, features]
# 检查 GPU 是否可用
if torch.cuda.is_available():
num_gpus = torch.cuda.device_count()
device = torch.device(f'cuda:0' if num_gpus == 1 else 'cuda') # 对于多GPU,我们只需指定'cuda'
print(f"Using {num_gpus} GPUs")
else:
device = torch.device('cpu')
print("Using CPU")
# 实例化模型并转移到设备上
model = SimpleModel().to(device)
# 如果有多于一个 GPU,则使用DataParallel
if num_gpus > 1:
model = nn.DataParallel(model)
# 将数据转移到设备上
data = data.to(device)
# 假设的前向传播(示例)
output = model(data)
print(output)
可以看到有一个GPU 位置为0

配置训练文件
- 添加自己要训练的文件:
配置文件路径、设置标签个数和标签字典

- 配置默认文件:
修改轮数到自己项目所需的轮数
修改batch,看主要看GPU或CPU内存大小
修改imgsz,训练是图片统一的大小
修改device,笔记本有块独显,所以索引为1
修改workers,默认可不改,有问题可见小,最低为0

- 训练
# '''
# Description:
# Author: NavyPeng
# Date: 2024-07-08 10:11:10
# LastEditTime: 2024-07-08 10:12:27
# LastEditors: NavyPeng
# '''
# coding:utf-8
from ultralytics import YOLOv10
# 模型配置文件
model_yaml_path = "ultralytics/cfg/models/v10/yolov10m.yaml"
# 数据集配置文件
data_yaml_path = 'ultralytics/cfg/datasets/MyWork.yaml'
# 预训练模型
pre_model_name = 'yolov10m.pt'
if __name__ == '__main__':
# 加载预训练模型
model = YOLOv10(model_yaml_path).load(pre_model_name)
# 训练模型
results = model.train(data=data_yaml_path, epochs=500,batch=8,name='train_M_v10')
- 错误处理
CUDA版本,pytorch版本需要对应
显卡驱动如何升降级自行百度
内存不足需修改batch或imgsz
测试模型
- 图片测试
from ultralytics import YOLOv10
# Load a pretrained YOLOv10n model
model = YOLOv10("runs/detect/train_M_v103/weights/best.pt")
# Perform object detection on an image
# results = model("test1.jpg")
results = model.predict("ultralytics/assets/work1.jpg")
# Display the results
results[0].show()
- 摄像头视频实时测试
安装opencv2
import cv2
from ultralytics import YOLOv10
from cv2 import getTickCount, getTickFrequency
# 加载 YOLO 模型
model = YOLOv10('runs/detect/train_M_v103/weights/best.pt')
# 获取摄像头内容,参数 表示使用默认的摄像头
# 使用的外接摄像头
cap = cv2.VideoCapture(1)
while cap.isOpened():
loop_start = getTickCount()
success, frame = cap.read() # 读取摄像头的一帧图像
if success:
results = model.predict(source=frame) # 对当前帧进行目标检测并显示结果
annotated_frame = results[0].plot()
# 中间放自己的显示程序
loop_time = getTickCount() - loop_start
total_time = loop_time / (getTickFrequency())
FPS = int(1 / total_time)
# 在图像左上角添加FPS文本
fps_text = f"FPS: {FPS:.2f}"
font = cv2.FONT_HERSHEY_SIMPLEX
font_scale = 1
font_thickness = 2
text_color = (0, 255, 0) # 绿色
text_position = (10, 30) # 左上角位置
cv2.putText(annotated_frame, fps_text, text_position, font, font_scale, text_color, font_thickness)
cv2.imshow('img', annotated_frame)
# 通过按下 'q' 键退出循环
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release() # 释放摄像头资源
cv2.destroyAllWindows() # 关闭OpenCV窗口
总结
至此模型已经可以用了,不满意可继续学习修改参数、增加样本数量等方式提高精度
了解了人工智能相关领域、也对其发展有了些了解、将来或许可以自己做些应用















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









