







诸神缄默不语-个人CSDN博文目录
cs224w(图机器学习)2021冬季课程学习笔记集合
文章目录
YouTube视频观看地址1 视频观看地址2 视频观看地址3 视频观看地址4
本章主要内容:
本章首先介绍了GNN在实践中遇到的难以应用到大图上的问题,指出了scale up GNN这一课题的研究重要性。
接下来介绍了三种解决这一问题的方法:GraphSAGE模型1的neighbor sampling,Cluster-GCN模型2和简化GNN模型(SGC模型3)。
1. 介绍scale up GNN问题
- 图数据在当代ML研究中应用广泛,在很多领域中都出现了可供研究的大型图数据。
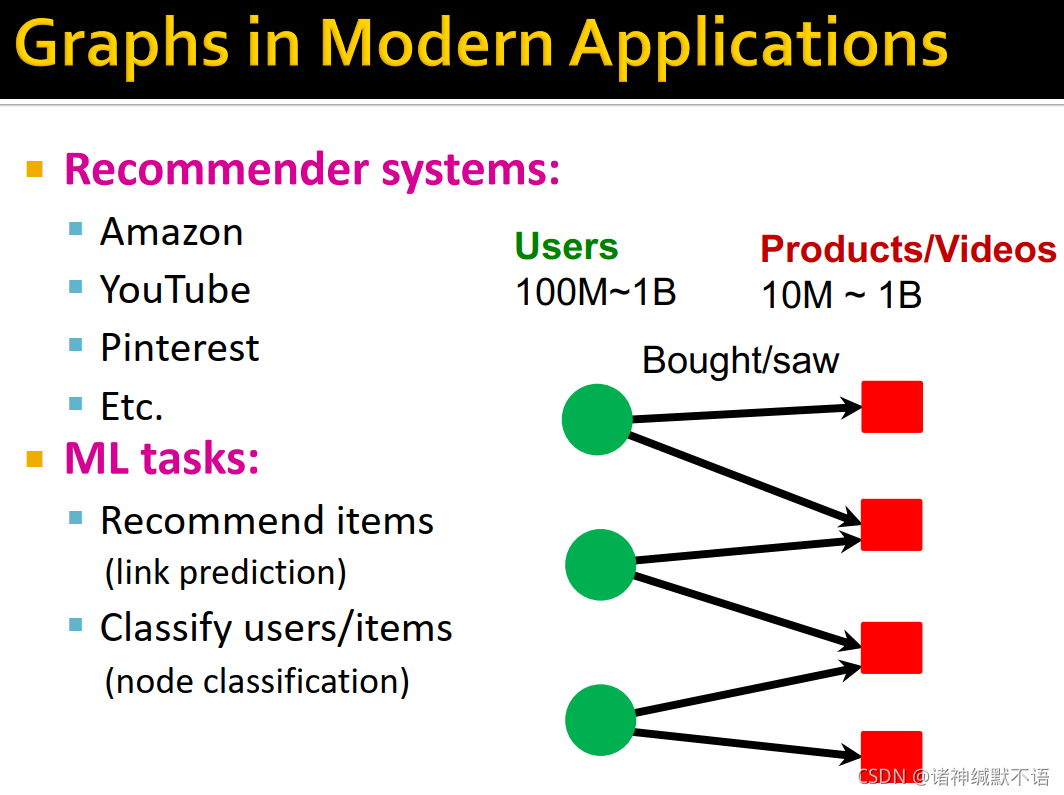
推荐系统,推荐商品(链接预测),分类用户/物品(节点分类):
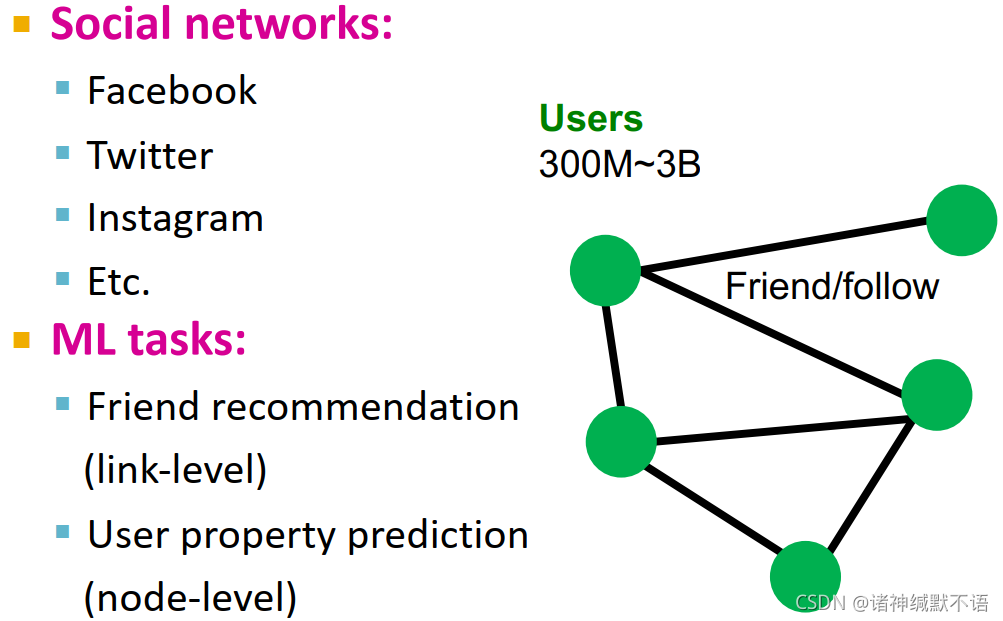
社交网络,好友推荐(边级别),用户属性预测(节点级别):
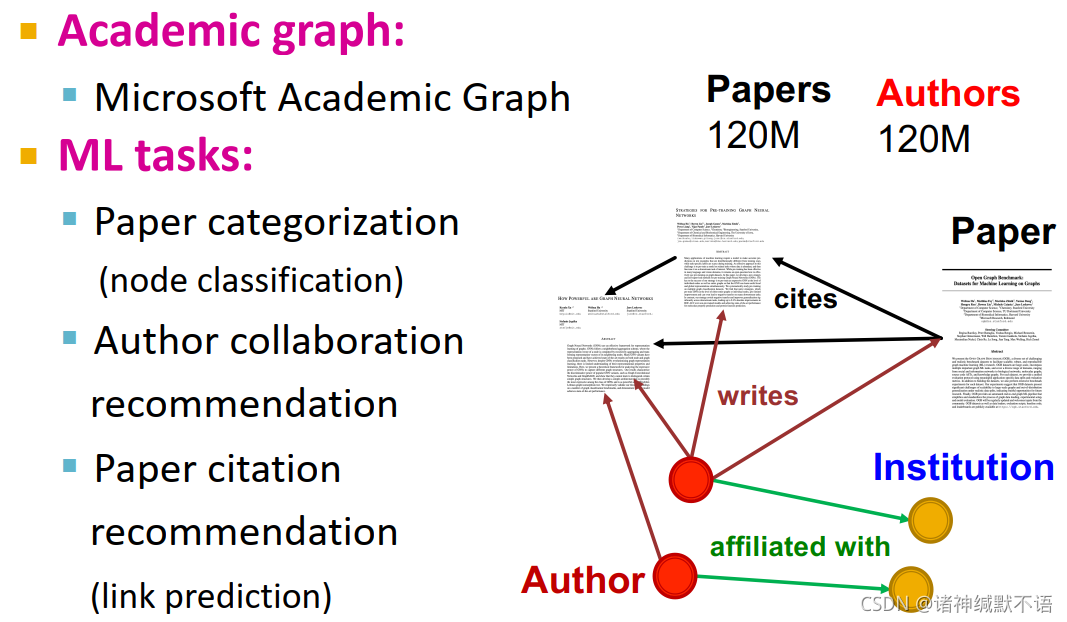
学术图,论文分类(节点分类),作者协作预测、文献引用预测(链接预测):
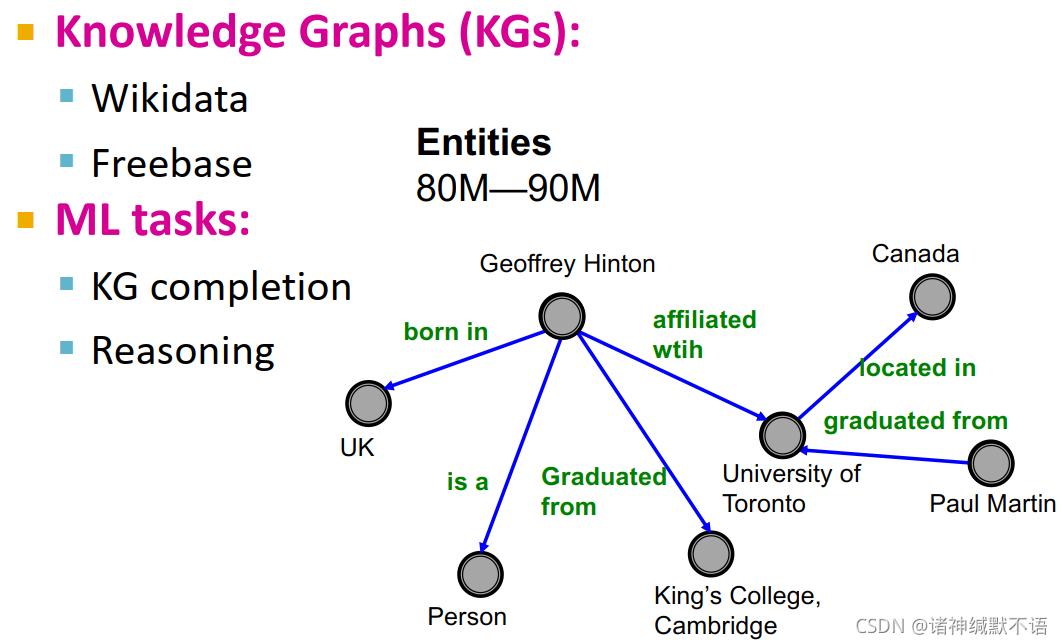
知识图谱(KG),KG completion,推理:
- 这些图的共同点有二:
第一,大规模。节点数从10M到10B,边数从100M到100B。
第二,任务都分为节点级别(用户/物品/论文分类)和边级别(推荐、completion)。
本节课就将介绍如何scale up GNNs到大型图上。

- scale up GNN 的难点在于:
在传统大型数据集上的ML模型的训练方法:
目标:最小化平均损失函数 l ( θ ) = 1 N ∑ i = 1 N − 1 l i ( θ ) \mathcal{l}(\mathbf{\theta})=\dfrac{1}{N}\sum\limits_{i=1}^{N-1}\mathcal{l}_i(\mathbf{\theta}) l(θ)=N1i=1∑N−1li(θ)(其中 θ \mathbf{\theta} θ 是模型参数, l i ( θ ) \mathcal{l}_i(\mathbf{\theta}) li(θ) 是第 i i i 个数据点的损失函数)。
我们使用随机梯度下降stochastic gradient descent(SGD)方法:随机抽样 M M M ( < < N ) (<<N) (<<N) 个数据(mini-batches),计算 M M M 个节点上的 l s u b ( θ ) \mathcal{l}_{sub}(\mathbf{\theta}) lsub(θ),用SGD更新模型: θ ← θ − ∇ l s u b ( θ ) \mathbf{\theta}\leftarrow\mathbf{\theta}-\nabla \mathcal{l}_{sub}(\mathbf{\theta}) θ←θ−∇lsub(θ)

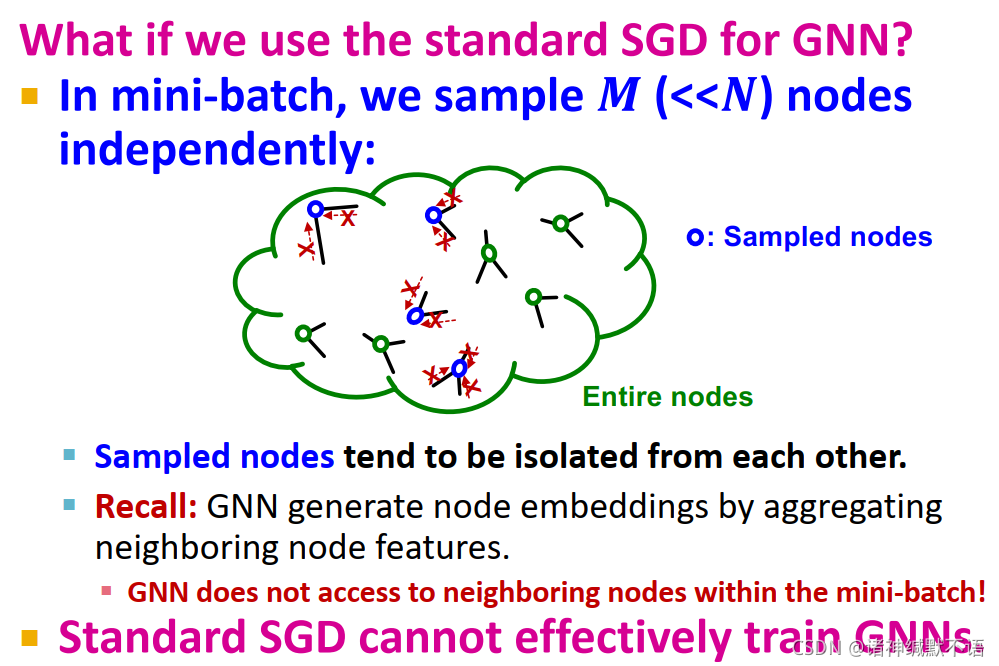
如果我们想直接将标准SGD应用于GNN的话,我们就会遇到问题:
在mini-batch时,我们独立随机抽样 M M M ( < < N ) (<<N) (<<N) 个节点,会出现如图所示的情况,抽样到的节点彼此孤立。由于GNN就是靠聚集邻居特征生成节点嵌入的,在mini-batch中无法获取邻居节点,因此这样的标准SGD无法有效训练GNNs。
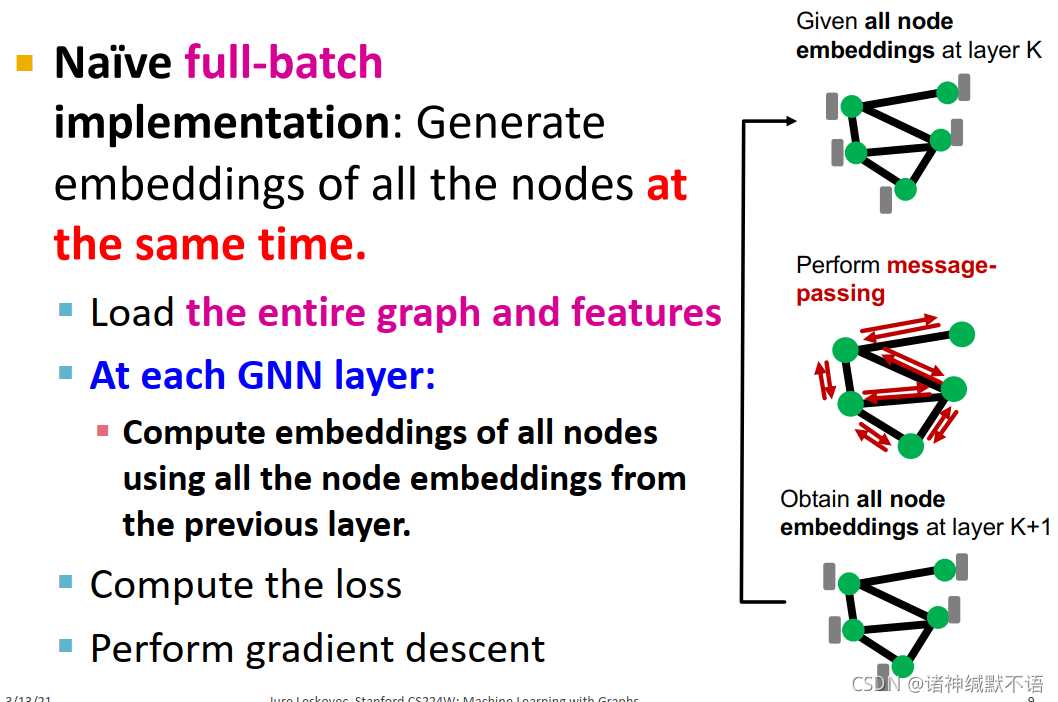
因此我们会使用naïve full-batch:
如图所示,对整张图上的所有节点同时生成嵌入:加载全部的图结构和特征,对每一层GNN用前一层嵌入计算所有节点的嵌入(message-passing),计算损失函数,应用梯度下降来更新参数。
但full-batch应用不适用于大型图,因为我们想要使用GPU来加速训练,但GPU的memory严重受限(仅有10GB-20GB),整个图结构和特征信息无法加载到GPU上。
如图所示,CPU运算慢,memory大(1TB-10TB);GPU运算快,memory受限(10GB-20GB)。

- 本节课我们介绍三种scale up GNN的方法来解决这个问题,这三种方法分为两类:
第一类是在每一mini-batch中在小的子图上运行message-passing,每次只需要把子图加载到GPU上:GraphSAGE的neighbor sampling1 和Cluster-GCN2。
第二类是将GNN简化为特征预处理操作(可以在CPU上有效运行):Simplified GCN3。

2. GraphSAGE Neighbor Sampling: Scaling up GNNs
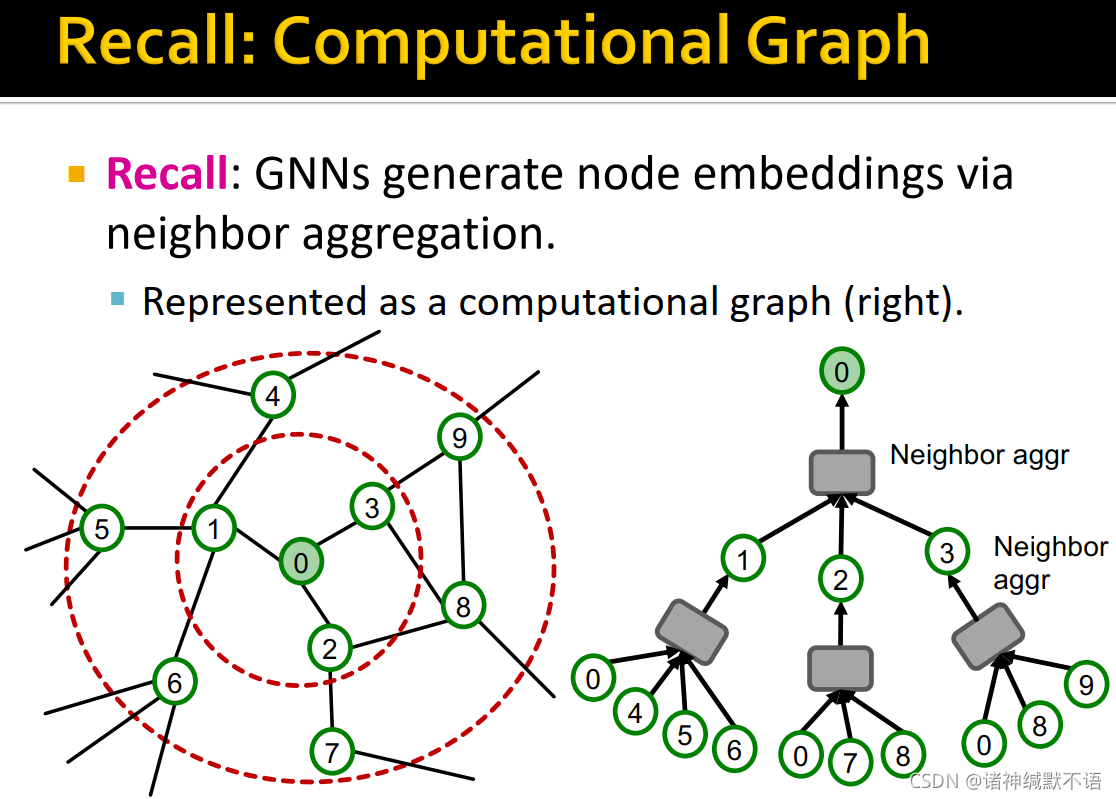
- 计算图
GNN通过聚合邻居生成节点嵌入,表现为计算图的形式(如右图所示):
可以观察到,一个2层GNN对节点0使用2跳邻居结构和特征生成嵌入:
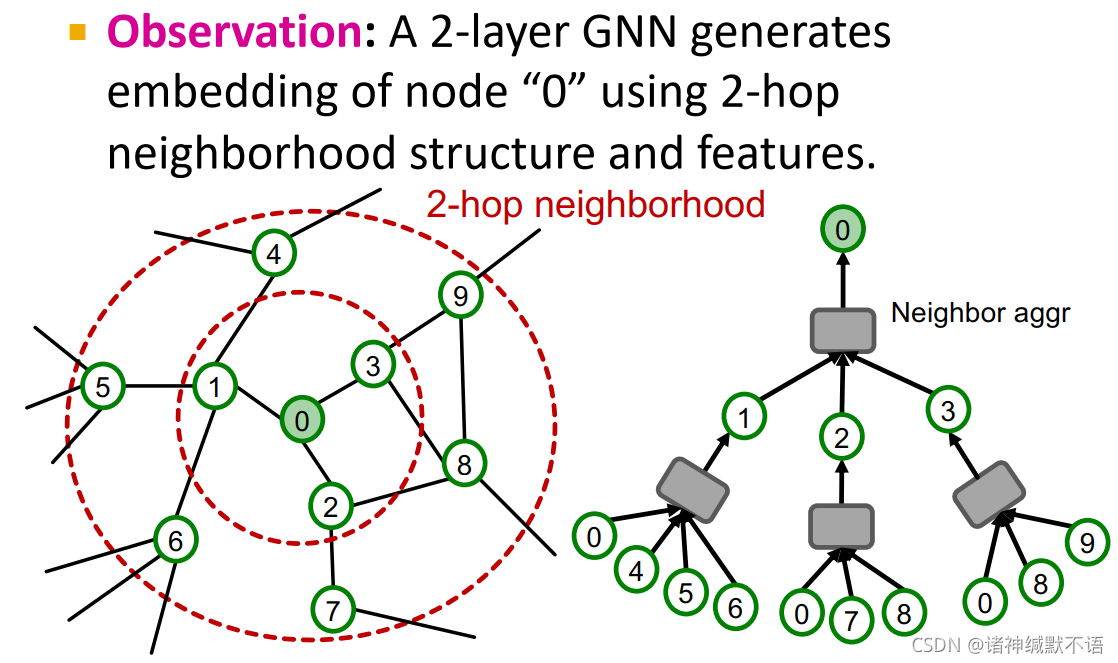
可以泛化得到:K层GNN使用K跳邻居结构和特征生成嵌入。

- 我们发现,为计算单一节点的嵌入,我们只需要其K跳邻居(以之定义计算图)。在一个mini-batch中给定M个不同的节点,我们可以用M个计算图来生成其嵌入(如图所示),这样就可以在GPU上计算了:
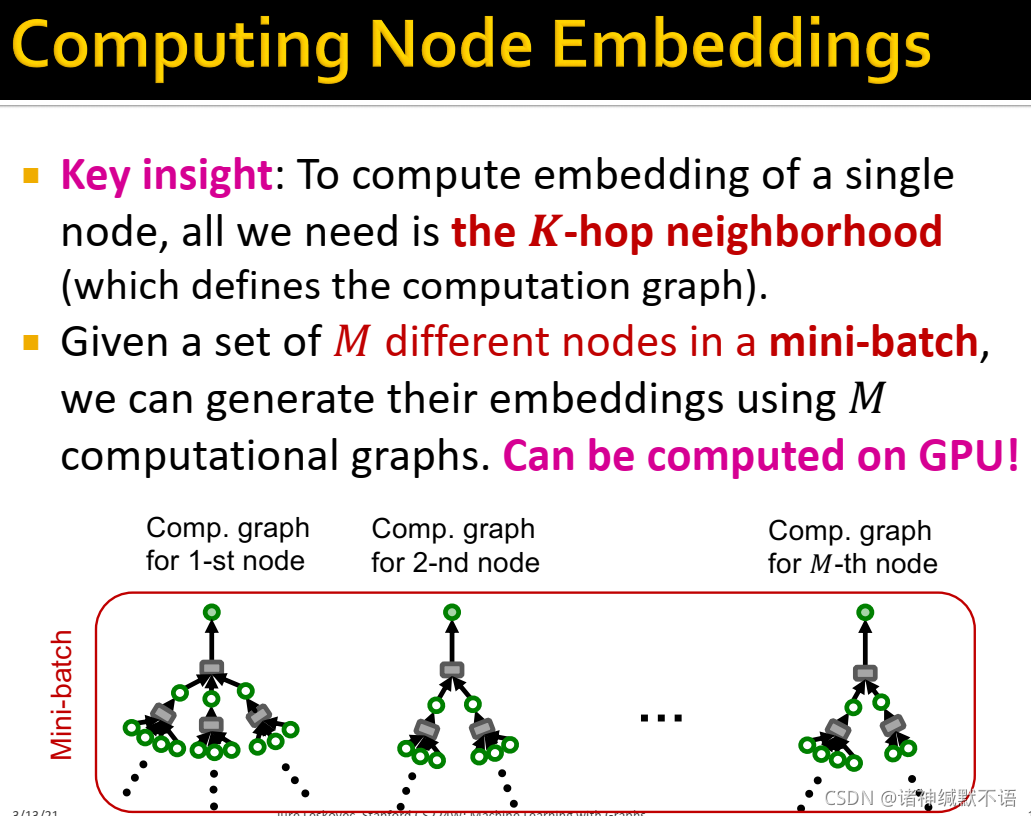
- GNN随机训练
我们现在就可以考虑用SGD策略训练K层GNN:- 随机抽样 M M M ( < < N ) (<<N) (<<N) 个节点
- 对每个被抽样的节点 v v v,获取其K跳邻居,构建计算图,用以生成 v v v 的嵌入。
- 计算 M M M 个节点上的平均损失函数 l s u b ( θ ) \mathcal{l}_{sub}(\mathbf{\theta}) lsub(θ)。
- 用SGD更新模型:
θ
←
θ
−
∇
l
s
u
b
(
θ
)
\mathbf{\theta}\leftarrow\mathbf{\theta}-\nabla \mathcal{l}_{sub}(\mathbf{\theta})
θ←θ−∇lsub(θ)

- 随机训练的问题:
对每个节点,我们都需要获取完整的K跳邻居并将其传入计算图中,我们需要聚合大量信息仅用于计算一个节点嵌入,这样计算开销过大。

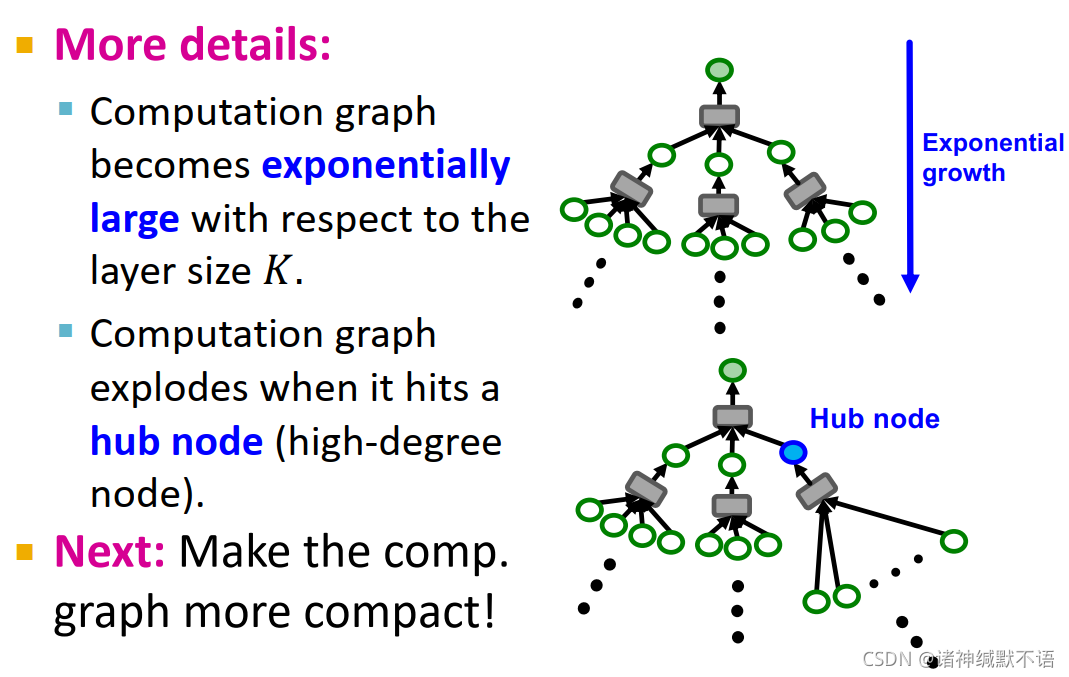
更多细节:
1. 计算图的大小会依层数K指数增长。如右图上面的图所示。
2. 在遇到hub node(度数很高的节点)时计算图会爆炸,但在现实世界的图中往往大多数节点度数较低,少量节点度数极高,就是会存在这种hub node。如右图下面的图所示。
下一步,我们就要让计算图更小。
- neighbor sampling
核心思想:每一跳随机抽样H个邻居,构建计算图。
H=2时示例如图所示,从根节点到叶节点,每个节点抽样2个邻居作为子节点:
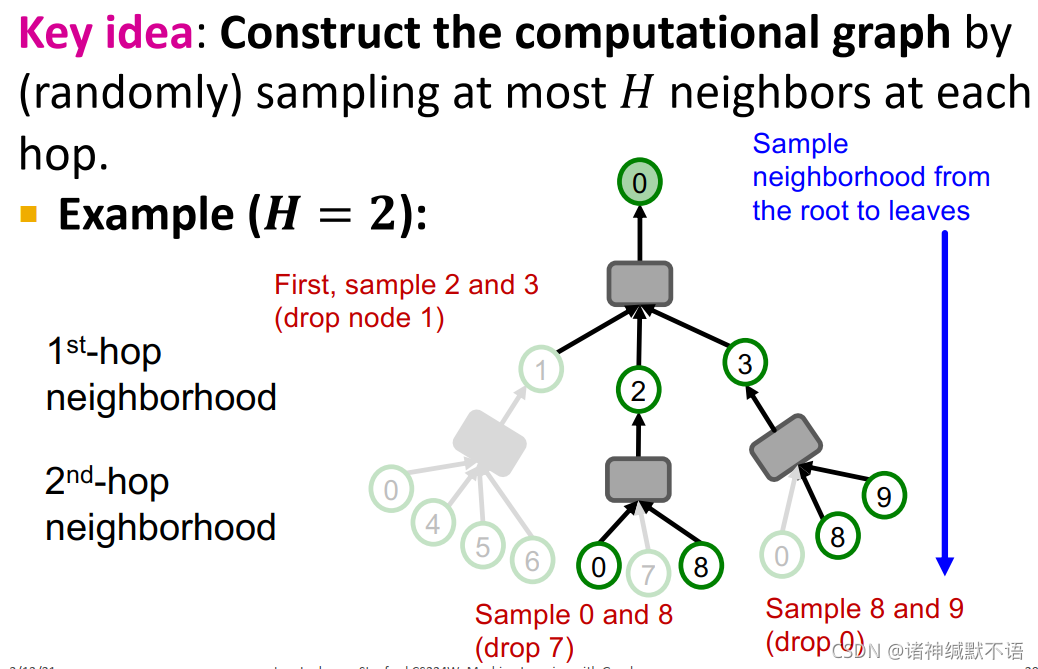
我们可以用这个经剪枝的计算图来更有效地计算节点嵌入。

- 对K层GNN的neighbor sampling:
对每个节点的计算图:对第k(k=1,2,…,K)层,对其k阶邻居随机抽样最多 H k H_k Hk 个节点,构成计算图。如图所示。
K层GNN一个计算图最多有 ∏ k = 1 K H k \prod^K_{k=1}H_k ∏k=1KHk 个叶节点(每一层都抽满)。
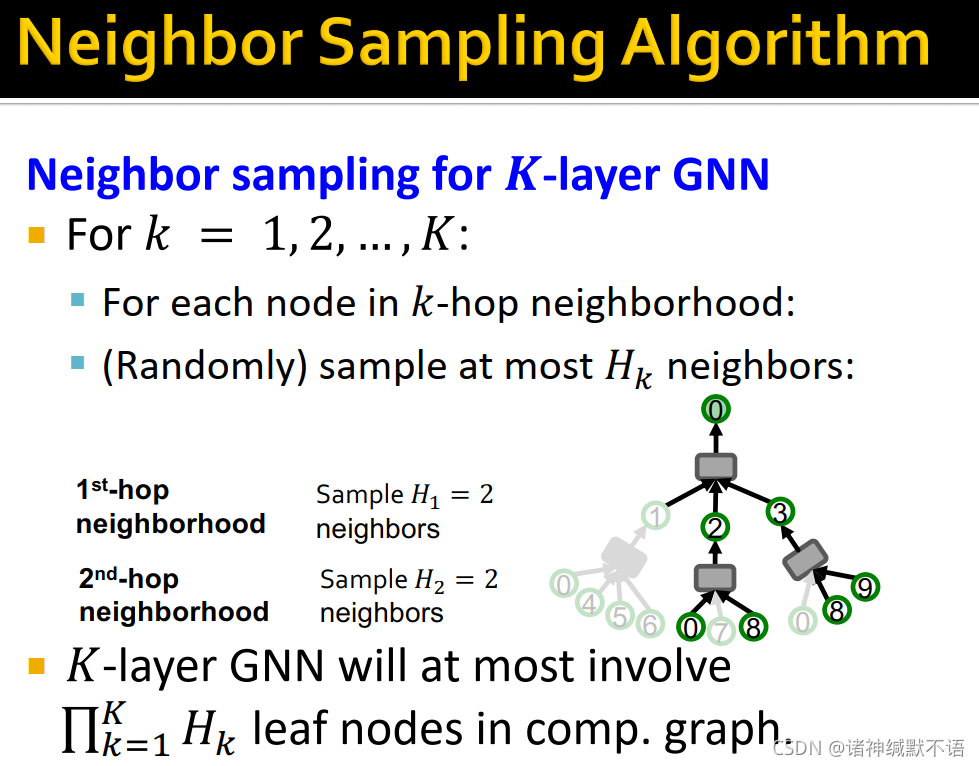
- neighbor sampling注意事项
- 对sampling number H H H 的权衡:小 H H H 会使邻居聚合过程效率更高,但训练过程也会更不稳定(由于邻居聚合过程中variance会更大)。
- 计算用时:即使有了neighbor sampling,计算图的尺寸还是跟GNN层数K呈指数增长。

- 如何抽样节点:
- neighbor sampling总结
- 计算图由每个mini-batch中的每个点构建。
- 在neighbor sampling中,计算图为计算有效性而被剪枝/sub-sampled。此外也有增加模型鲁棒性的效果(因为提升了模型的随机性,有些类似于dropout)。
- 我们用被剪枝的计算图来生成节点嵌入。
- 尽管有了剪枝工作,计算图还是可能会很大,尤其在GNN的message-passing层增多时。这就需要batch size进一步减小(即剪枝更多),这使得结果variance更大、更不可靠。


3. Cluster-GCN: Scaling up GNNs
-
neighbor sampling的问题:
- 计算图的尺寸依GNN层数指数级增长。
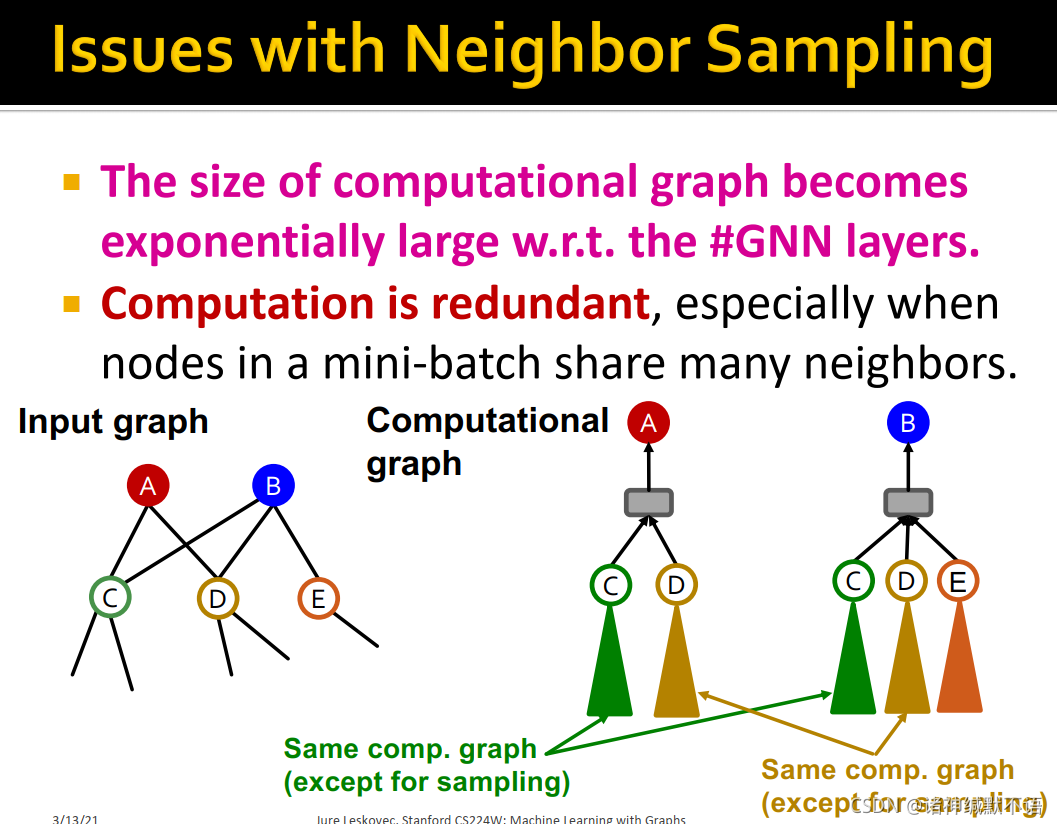
- 计算是冗余的,尤其在mini-batch中的节点有很多共享邻居时:如图所示,A节点和B节点具有同样的邻居C和D,在不考虑抽样的情况下这两个节点将会具有相同的计算图、即相同的节点,但在neighbor sampling的运算中需要分别各计算一次,就做了重复的事。
老师在课上提到HAGs6 这一篇是讲如何不用计算这些冗余嵌入的。当然这篇我也没看,列出来仅供有兴趣的读者参考。
-
在full-batch GNN中,所有节点嵌入都是根据前一层嵌入同时计算出的:
对所有 v ∈ V v\in V v∈V: h v ( l ) = C O M B I N E ( h v ( l − 1 ) , A G G R ( { h u ( l ) } u ∈ N ( v ) ) ) h_v^{(\mathcal{l})}=COMBINE\bigg(h_v^{(\mathcal{l}-1)},AGGR\big(\{h_u^{(\mathcal{l})}\}_{u\in N(v)}\big)\bigg) hv(l)=COMBINE(hv(l−1),AGGR({hu(l)}u∈N(v)))
(其中 h u ( l ) h_u^{(\mathcal{l})} hu(l) 是message环节)
如图所示,对每一层来说,只需要计算2×边数次message(与邻居互相传递一次信息)7;对K层GNN来说,只需要计算2K×边数次message。
GNN整体计算代价依边数和层数线性增长,这是很快的。

-
从full-batch GNN中,我们可以发现,layer-wise的节点嵌入更新可以复用前一层的嵌入,这样就显著减少了neighbor sampling中产生的计算冗余问题。但是,由于GPU memory所限,这种layer-wise的更新方式不适用于大型图。

-
subgraph sampling
核心思想:从整个大型图中抽样出一个小子图,在子图上用GPU运行有效的layer-wise节点嵌入更新。如图所示:

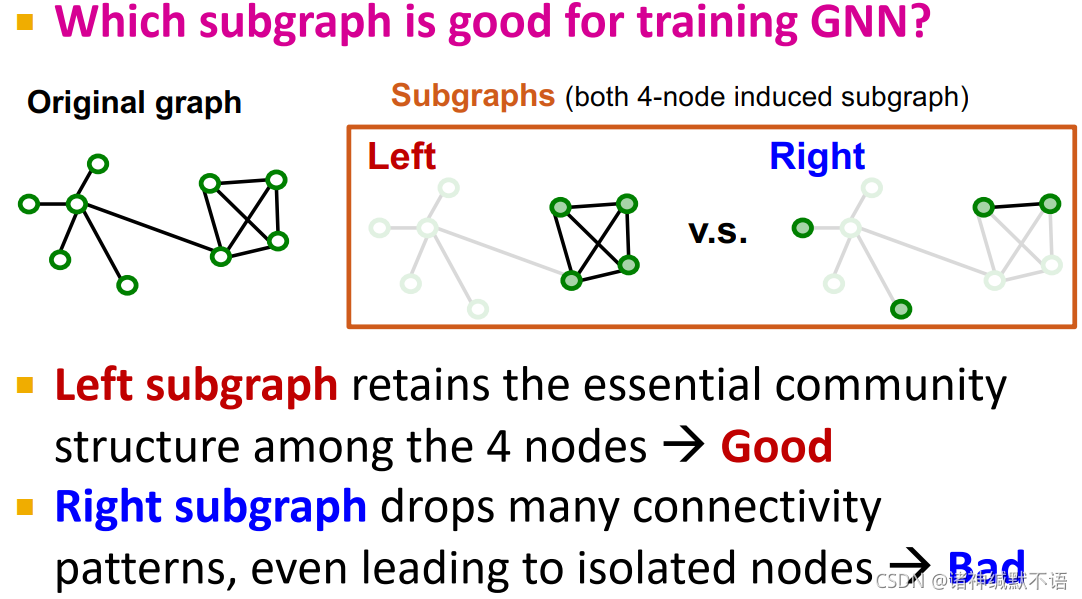
核心问题:什么子图适用于训练GNNs?
我们知道GNN通过边来传递信息,从而更新节点嵌入。因此,子图需要尽量多地保持原图中的边连接结构。通过这种方式,子图上的GNN就可以生成更接近于原图GNN的节点嵌入。

-
subgraph sampling: case study
举例来说,下图中右边的两种子图,左边的子图更适用于训练GNN:保持了必要的社区结构8、边连接模式,没有产生孤立点。
-
利用社区结构
现实世界的图会呈现出社区结构,一个大型图可以被解构为多个小社区。
将一个社区抽样为一个子图,每个子图就能保持必要的原图局部connectivity模式。

-
Cluster-GCN
- overview
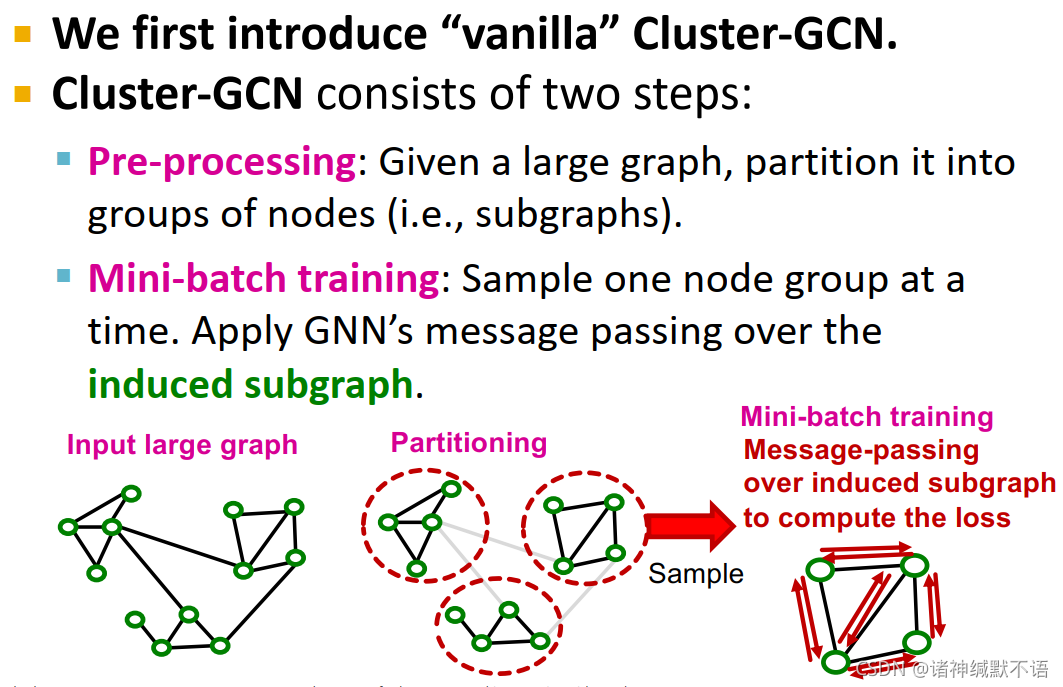
我们首先介绍 vanilla9 Cluster-GCN。
Cluster-GCN分为两步:- pre-processing: 给定一个大型图,将其分割为多个node group(如子图)。
- mini-batch training: 每次抽样一个node group,对其induced subgraph10应用GNN的message passing。
如图所示:
- pre-processing
给定一个大型图 G = ( V , E ) G=(V,E) G=(V,E),将其节点 V V V 分割到 C C C 个组中: V 1 , … , V C V_1,\dots,V_C V1,…,VC
我们可以使用任何scalable的社区发现方法,如Louvain8 或METIS11 方法。
V 1 , … , V C V_1,\dots,V_C V1,…,VC induces C C C 个子图: G 1 , … , G C G_1,\dots,G_C G1,…,GC
(注意:group之间的边不被包含在这些子图中)

- mini-batching training
对每个mini-batch,随机抽样一个node group V C V_C VC,构建induced subgraph G C = ( V C , E C ) G_C=\big(V_C,E_C\big) GC=(VC,EC)
如图所示:

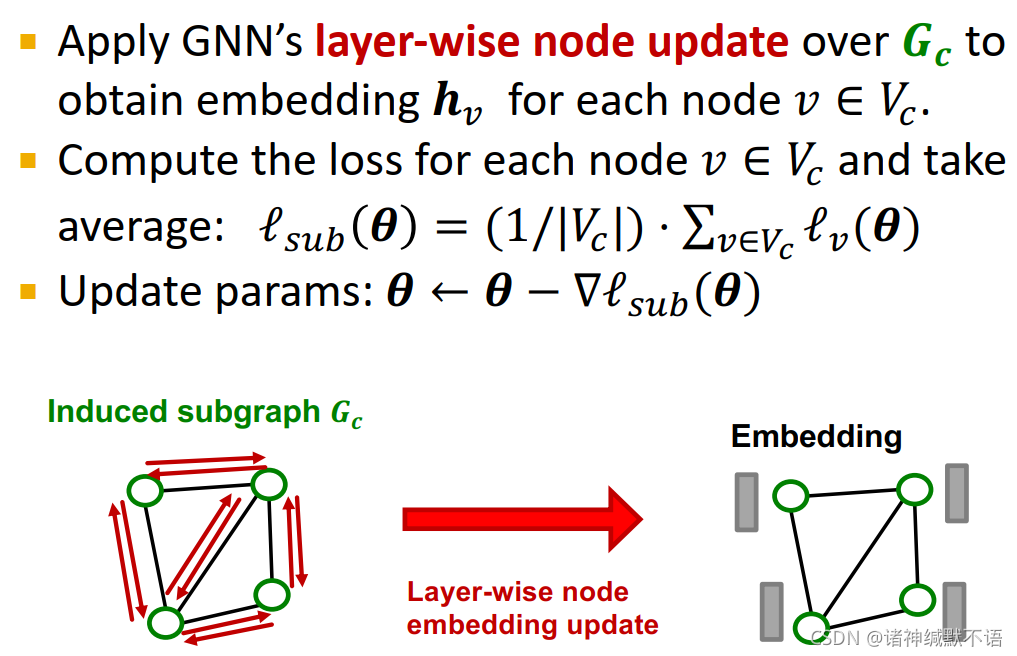
在 G C G_C GC 上应用GNN的layer-wise节点更新,获取所有节点 v ∈ V C v\in V_C v∈VC 的嵌入 h v \mathbf{h}_v hv。
对每个节点求损失函数,对所有节点的损失函数求平均: l s u b ( θ ) = 1 ∣ V C ∣ ⋅ ∑ v ∈ V C l v ( θ ) \mathcal{l}_{sub}(\mathbf{\theta})=\dfrac{1}{|V_C|}\cdot\sum_{v\in V_C}\mathcal{l}_{v}(\mathbf{\theta}) lsub(θ)=∣VC∣1⋅∑v∈VClv(θ)
更新参数: θ ← θ − ∇ l s u b ( θ ) \mathbf{\theta}\leftarrow\mathbf{\theta}-\nabla \mathcal{l}_{sub}(\mathbf{\theta}) θ←θ−∇lsub(θ)
- overview
-
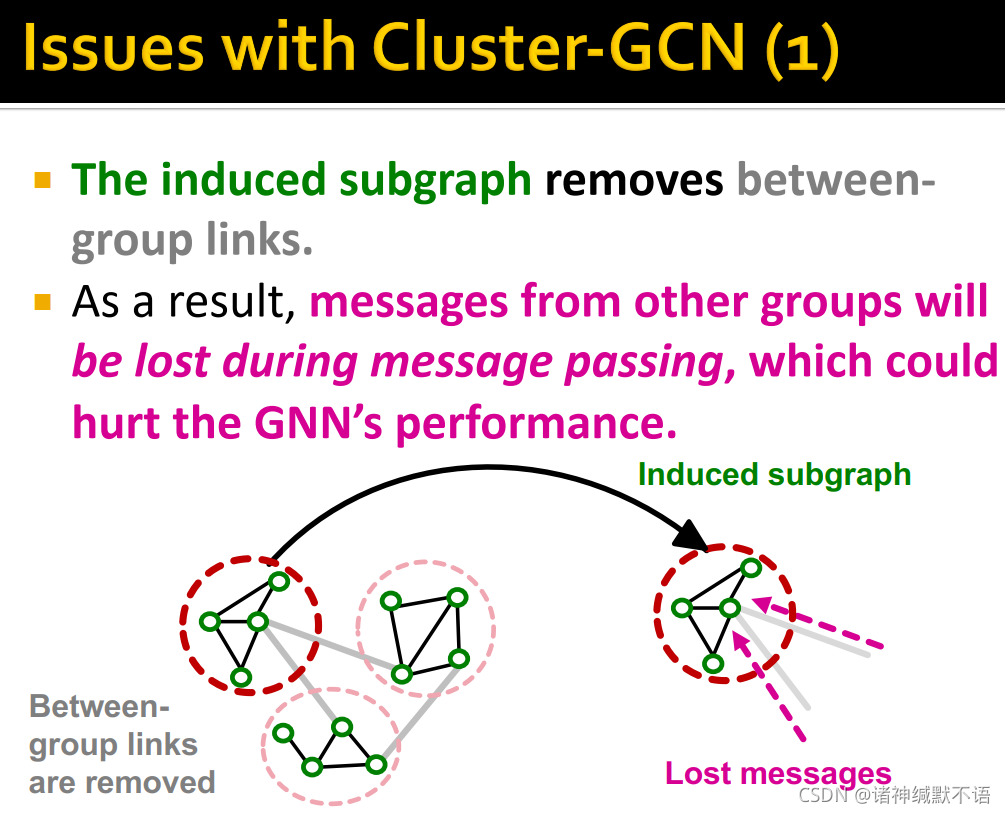
Cluster-GCN的问题
如前文所述得到的induced subgraph移除了组间的链接,这使得其他组对该组的message会在message passing的过程中丢失,这会影响GNN的实现效果。
如图所示:
图社区检测算法会将相似的节点分到一类中,这样被抽样的node group就会倾向于仅包含整个数据的一个很集中的部分。
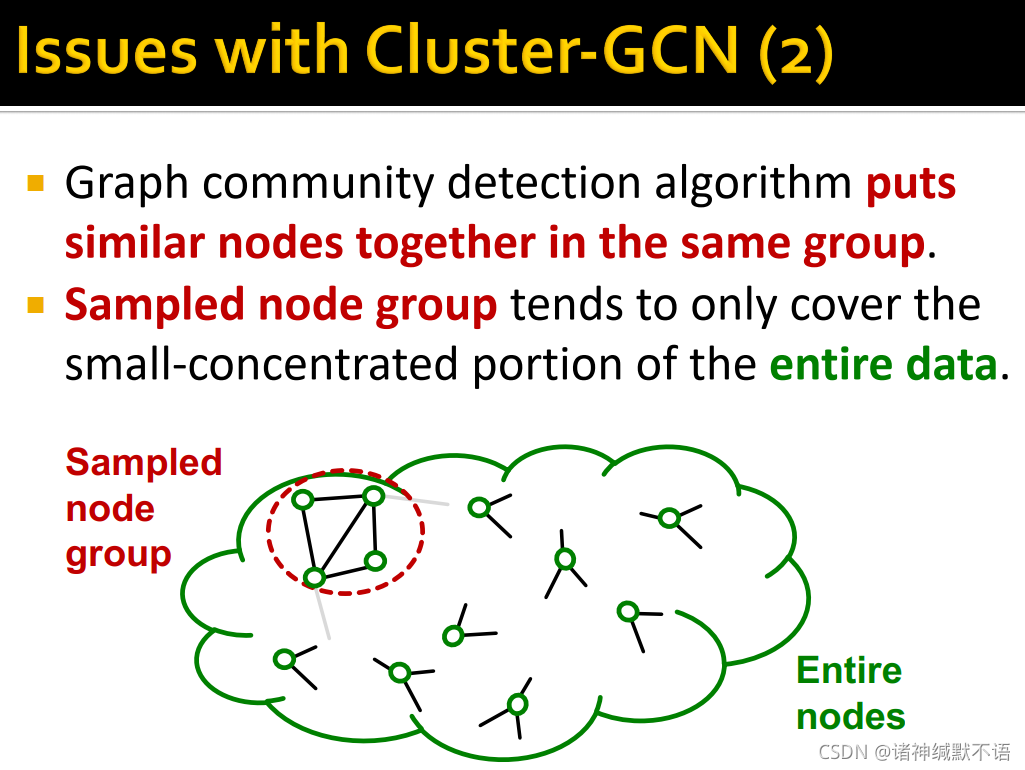
被抽样的节点不够多样化,不够用以表示整个图结构:这样经被抽样节点得到的梯度( 1 ∣ V C ∣ ⋅ ∑ v ∈ V C ∇ l v ( θ ) \dfrac{1}{|V_C|}\cdot\sum_{v\in V_C}\nabla\mathcal{l}_{v}(\mathbf{\theta}) ∣VC∣1⋅∑v∈VC∇lv(θ))就会变得不可靠,会在不同node group上波动剧烈,即variance高。这会让SGD收敛变慢。

-
advanced Cluster-GCN: overview
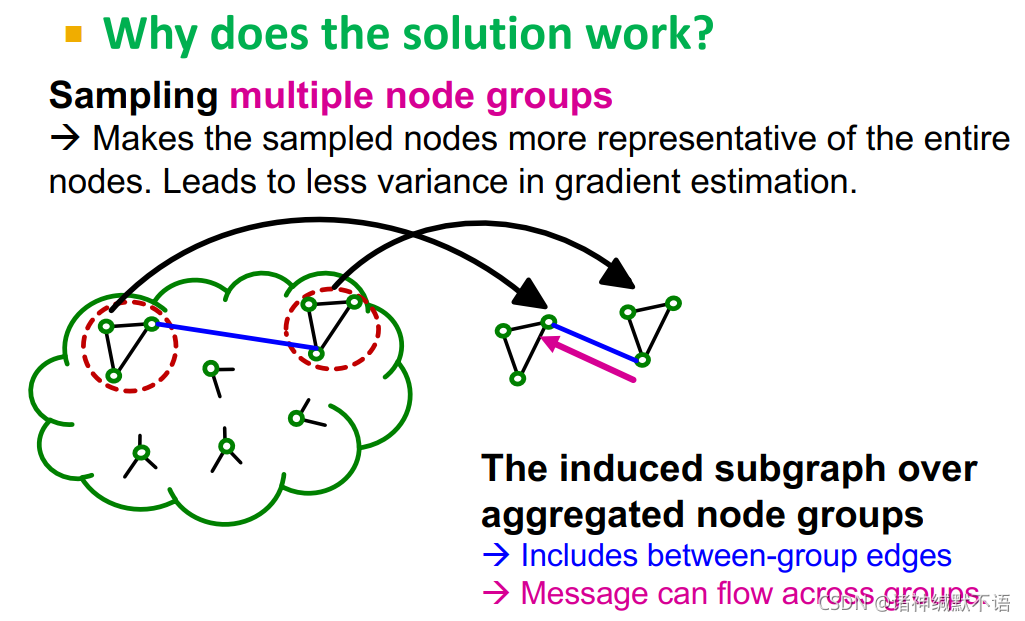
对上述Clutser-GCN问题的解决方案:在每个mini-batch聚合多个node groups.
将图划分为相对来说较小的节点组,在每个mini-batch中:抽样并聚合多个node groups,构建induced subgraph,剩下工作就和vanilla Cluster-GCN相同(计算节点嵌入、计算损失函数、更新参数)。

为什么这一策略有效:
抽样多个node groups可以让被抽样节点更能代表全图节点,在梯度估算时variance更低。
聚合多个node groups的induced subgraph包含了组间的边,message可以在组间流动。
-
advanced Cluster-GCN
与vanilla Cluster-GCN相似,advanced Cluster-GCN分成两步:
第一步:pre-processing
给定一个大型图 G = ( V , E ) G=(V,E) G=(V,E),将其节点 V V V 分割到 C C C 个相对较小的组中: V 1 , … , V C V_1,\dots,V_C V1,…,VC( V 1 , … , V C V_1,\dots,V_C V1,…,VC 需要够小,才能使它们可以多个聚合起来,聚合后的组还是不会过大)

第二步:mini-batch training
对每个mini-batch,随机抽样一组 q q q 个node groups: { V t 1 , … , V t q } ⊂ { V 1 , … , V C } \{V_{t_1},\dots,V_{t_q}\}\subset\{V_1,\dots,V_C\} {Vt1,…,Vtq}⊂{V1,…,VC}
聚合所有被抽样node groups中的节点: V a g g r = V t 1 ∪ ⋯ ∪ V t q V_{aggr}=V_{t_1}\cup\cdots\cup V_{t_q} Vaggr=Vt1∪⋯∪Vtq
提取induced subgraph G a g g r = ( V a g g r , E a g g r ) G_{aggr}=\big(V_{aggr},E_{aggr}\big) Gaggr=(Vaggr,Eaggr)(其中 E a g g r = { ( u , v ) ∣ u , v ∈ V a g g r } E_{aggr}=\{(u,v)|u,v\in V_{aggr}\} Eaggr={(u,v)∣u,v∈Vaggr})
这样 E a g g r E_{aggr} Eaggr 就包含了组间的边。

-
时间复杂度对比
对于用K层GNN生成 M M M ( < < N ) (<<N) (<<N) ( N N N 是节点数)个节点嵌入:
neighbor sampling(每层抽样 H H H 个节点):每个节点的K层计算图的尺寸是 H K H^K HK,M个节点的计算代价就是 M ⋅ H K M\cdot H^K M⋅HK

Cluster-GCN: 对M个节点induced的subgraph运行message passing,子图共包含 M ⋅ D a v g M\cdot D_{avg} M⋅Davg 条边,对子图运行K层message passing的计算代价最多为 K ⋅ M ⋅ D a v g K\cdot M\cdot D_{avg} K⋅M⋅Davg

总结:用K层GNN生成 M M M ( < < N ) (<<N) (<<N) ( N N N 是节点数)个节点嵌入的计算代价为:
neighbor-sampling(每层抽样 H H H 个节点): M ⋅ H K M\cdot H^K M⋅HK
Cluster-GCN: K ⋅ M ⋅ D a v g K\cdot M\cdot D_{avg} K⋅M⋅Davg
假设 H = D a v g 2 H=\dfrac{D_{avg}}{2} H=2Davg,即抽样一半邻居。这样的话,Cluster-GCN(计算代价: 2 M H K 2MHK 2MHK)就会远比neighbor sampling(计算代价: M H K MH^K MHK)更有效,因为Cluster-GCN依K线性增长而非指数增长。
一般我们会让H比 D a v g 2 \dfrac{D_{avg}}{2} 2Davg 大,可能2-3倍平均度数这样。现实中一般GNN都不深(即K小),所以一般用neighbor sampling的很多。

-
Cluster-GCN总结
- Cluster-GCN首先将整体节点分割到小node groups中。
- 在每个mini-batch,抽样多个node groups然后聚合其节点。
- GNN在这些节点的induced subgraph上进行layer-wise的节点嵌入更新。
- Cluster-GCN比neighbor sampling计算效率更高,尤其当GNN层数大时。
- 但Cluster-GCN会导致梯度估计出现系统偏差(由于缺少社区间的边。以及当GNN层数加深时,在原图中是真的可以加深的(增大感受野),但在子图中就不行,加深了会弹回来,是虚假的加深)

4. Scaling up by Simplifying GNNs
-
本节课讲SGC模型,这个模型是通过去除非线性激活函数简化了GCN12模型。原论文3 证明经简化后在benchmark数据集上效果没有怎么变差。Simplified GCN证明是对模型设计很scalable的。

-
mean-pool的GCN:
给定图 G = ( V , E ) G=(V,E) G=(V,E) ,输入节点特征 X v X_v Xv( v ∈ V v\in V v∈V), E E E 包含自环(即对所有节点 v v v,都有 ( v , v ) ∈ E (v,v)\in E (v,v)∈E)。
设置输入节点嵌入为 h v ( 0 ) = X v h_v^{(0)}=X_v hv(0)=Xv
对 k ∈ { 0 , … , K − 1 } k\in\{0,\dots,K-1\} k∈{0,…,K−1} 层:对所有节点 v v v,以如下公式聚合邻居信息: h v ( k + 1 ) = ReLU ( W k ⋅ 1 ∣ N ( v ) ∣ ∑ u ∈ N ( v ) h v ( k ) ) h_v^{(k+1)}=\text{ReLU}\big(\textcolor{pink}{W_k}\cdot\textcolor{blue}{\dfrac{1}{|N(v)|}\sum_{u\in N(v)}h_v^{(k)}}\big) hv(k+1)=ReLU(Wk⋅∣N(v)∣1∑u∈N(v)hv(k))(其中粉色字为经训练得到的参数矩阵,蓝色字部分为mean-pooling)
最终得到节点嵌入: z v = h v ( K ) z_v=h_v^{(K)} zv=hv(K)

-
GCN的矩阵格式
这一张图的解释可以参考我之前写的笔记:cs224w(图机器学习)2021冬季课程学习笔记7 Graph Neural Networks 1: GNN Model_诸神缄默不语的博客-CSDN博客 第三部分序号13。

以下给出了将GCN从向量形式(邻居聚合形式)转换为矩阵形式的公式:
注意GCN用的是re-normalized版本 A ~ = D − 1 / 2 A D − 1 / 2 \tilde{A}=D^{-1/2}AD^{-1/2} A~=D−1/2AD−1/2(这个版本在实证上比 D − 1 / 2 A D^{-1/2}A D−1/2A 效果更好)
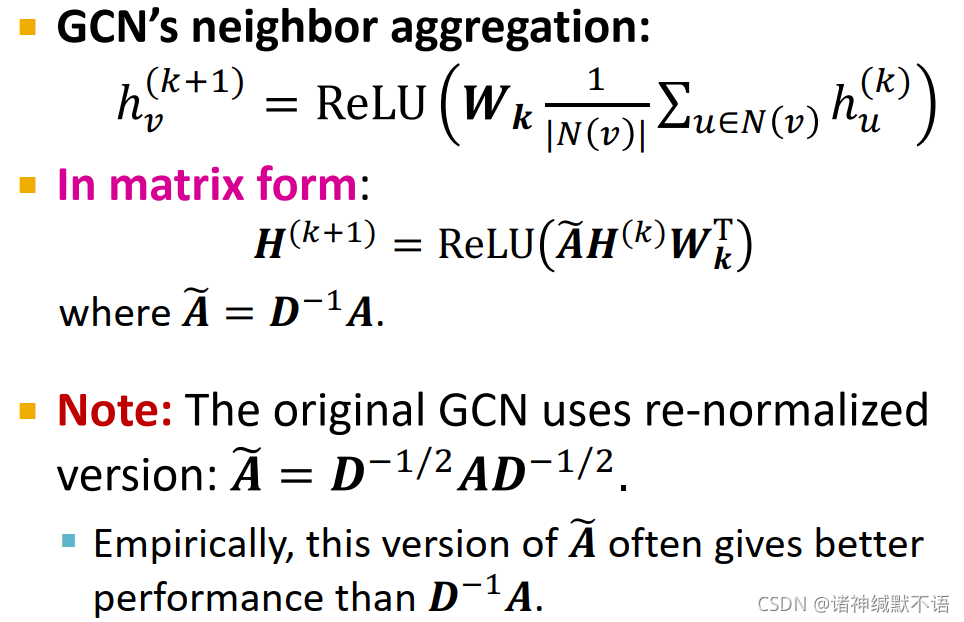
上图中,第一个公式就是GCN以邻居聚合形式进行的定义,第二个公式就是GCN的矩阵形式,其中 W W W 参数从左边移到右边可以考虑一下就因为 H H H 是 h T h^T hT 的堆叠,所以矩阵形式要乘 W W W 的参数的话就要倒到右边并取转置……就,这个把 W W W 脑内拆解一下应该就可以理解。 -
Simplifying GCN
移除掉GCN中的ReLU非线性激活函数,以简化GCN: H ( k + 1 ) = A ~ H ( k ) W k T H^{(k+1)}=\tilde{A}H^{(k)}W_k^T H(k+1)=A~H(k)WkT
经如下图所示(应该还挺直观的)的迭代推理,易知 H ( K ) H^{(K)} H(K) 可以表示为 A ~ K X W T \tilde{A}^KXW^T A~KXWT 的形式。

其中 A ~ K X \tilde{A}^KX A~KX 不含有任何需要训练得到的参数,因此可以被pre-compute。这可以通过一系列稀疏矩阵向量乘法来加速计算过程,即用 A ~ \tilde{A} A~ 左乘 X X X K次。

设 X ~ = A ~ K X \tilde{X}=\tilde{A}^KX X~=A~KX,为一个pre-computed matrix,则simplifie GCN的最终嵌入就是: H ( K ) = X ~ W T H^{(K)}=\tilde{X}W^T H(K)=X~WT
这就是一个对pre-computed matrix的线性转换。
将矩阵形式转换回节点嵌入形式,即得到 h v ( K ) = W X ~ v h_v^{(K)}=W\tilde{X}_v hv(K)=WX~v(其中 X ~ v \tilde{X}_v X~v 是pre-computed节点 v v v 的特征向量),即节点 v v v 的嵌入仅依赖于它自己的pre-processed特征。

X ~ \tilde{X} X~ 计算完成后, M M M 个节点的嵌入就可以以依 M M M 线性增长的时间复杂度来生成:
h v 1 ( K ) = W X ~ v 1 h_{v_1}^{(K)}=W\tilde{X}_{v_1} hv1(K)=WX~v1
h v 2 ( K ) = W X ~ v 2 h_{v_2}^{(K)}=W\tilde{X}_{v_2} hv2(K)=WX~v2
… \dots …
h v M ( K ) = W X ~ v M h_{v_M}^{(K)}=W\tilde{X}_{v_M} hvM(K)=WX~vM

-
Simplified GCN: Summary
Simplified GCN分成两步:- pre-processing step: precompute X ~ = A ~ K X \tilde{X}=\tilde{A}^KX X~=A~KX(可以在CPU上做)
- mini-batch training step:
对每个mini-batch,随机抽样M个节点 { v 1 , v 2 , … , v M } \{v_1,v_2,\dots,v_M\} {v1,v2,…,vM}
计算其嵌入: h v 1 ( K ) = W X ~ v 1 , h v 2 ( K ) = W X ~ v 2 , … , h v M ( K ) = W X ~ v M h_{v_1}^{(K)}=W\tilde{X}_{v_1},h_{v_2}^{(K)}=W\tilde{X}_{v_2},\dots,h_{v_M}^{(K)}=W\tilde{X}_{v_M} hv1(K)=WX~v1,hv2(K)=WX~v2,…,hvM(K)=WX~vM
用该嵌入进行预测,计算M个数据点上的平均损失函数。
应用SGD参数更新。

-
SGC与其他方法的比较
- 与neighbor sampling相比:SGC生成节点嵌入的效率更高(不需要对每个节点构建大计算图)
- 与Cluster-GCN相比:SGC的mini-batch节点可以从整体节点中完全随机地抽样,不需要从几个groups里面抽样。
这样就可以减少训练过程中的SGD variance13。 - 但这个模型的表现力也更低,因为生成节点嵌入的过程中没有非线性。


-
但事实上,在半监督学习节点分类benchmark上,simplified GCN和原始GNNs的表现力几乎相当,这是由于graph homophily14 的存在:
很多节点分类任务的图数据都表现出homophily结构,即有边相连的节点对之间倾向于具有相同的标签。
举例来说,在文献引用网络中的文献分类任务,引用文献往往是同类;在社交网络中给用户推荐电影的任务,社交网络中是朋友关系的用户往往倾向于喜欢相同的电影。
在simplified GCN中,preprocessing阶段是用 A ~ \tilde{A} A~ 左乘 X X X K次,即pre-processed特征是迭代求其邻居节点特征平均值而得到的(如下图三),因此有边相连的节点倾向于有相似的pre-processed特征,这样模型就倾向于将有边相连的节点预测为同一标签,从而很好地对齐了很多节点分类benchmark数据集中的graph homophily性质。




-
simplified GCN: summary
- simplified GCN去除了GCN中的非线性,并将其简化为对节点特征进行的简单pre-processing。
- 得到pre-processed特征后,就可以直接应用scalable mini-batch SGD直接优化参数。
- simplified GCN在节点分类benchmark中表现很好,这是因为特征pre-processing很好地对齐了现实世界预测任务中的graph homophily现象。

可参考我之前写的笔记。
原论文:
Inductive Representation Learning on Large Graphs
Hamilton et al. (2017) ↩︎ ↩︎Cluster-GCN: An Efficient Algorithm for Training Deep and Large Graph Convolutional Networks
Chiang et al. KDD 2019 ↩︎ ↩︎Simplifying Graph Convolutional Networks
Wu et al. ICML 2019 ↩︎ ↩︎ ↩︎可参考我之前写的笔记:cs224w(图机器学习)2021冬季课程学习笔记4 Link Analysis: PageRank (Graph as Matrix)_诸神缄默不语的博客-CSDN博客
具体的关于这个RWR的relevance score感觉可以参考这两篇文:Fast Random Walk with Restart and Its Applications 和 Supervised and extended restart in random walks for ranking and link prediction in networks。我是没有看的啦,我感觉暂时还无此需要。 ↩︎scale free 无尺度网络
其典型特征是在网络中的大部分节点只和很少节点连接,而有极少的节点与非常多的节点连接。
可参考:无尺度网络 - 维基百科,自由的百科全书 ↩︎Redundancy-Free Computation Graphs for Graph Neural Networks ↩︎
这种按照边来计算message的信息的逻辑好像就是PyG那种计算方式的逻辑……但是实话实说我没太搞懂,就是,我能理解吧,差不多能理解,但是具体的还不懂。以后再慢慢看吧。如果读者诸位能搞懂请告诉我一声。 ↩︎
关于社区发现问题,可参考我之前写的博文:cs224w(图机器学习)2021冬季课程学习笔记16 Community Detection in Networks_诸神缄默不语的博客-CSDN博客 ↩︎ ↩︎
vanilla有香子兰香味的; 香草味的; 普通的; 寻常的; 毫无特色的; ↩︎
subgraph, induced subgraph等概念可参考我之前写的笔记:cs224w(图机器学习)2021冬季课程学习笔记15 Frequent Subgraph Mining with GNNs_诸神缄默不语的博客-CSDN博客 ↩︎
A Fast and High Quality Multilevel Scheme for Partitioning Irregular Graphs
Karypis et al. SIAM 1998 ↩︎可参考我之前写的笔记。
原论文:
Semi-Supervised Classification with Graph Convolutional Networks
Kipf & Welling ICLR 2017 ↩︎就这个直观上可以理解为SGD每个mini-batch之间如果差异比较小、就每个mini-batch都能代表整体数据的话,应该就说SGD variance比较低。但是具体来说这个SGD variance是什么,我谷歌了一下感觉还是个比较复杂的话题,还有论文啥的……一时之间搞不懂,以后有缘再看吧。 ↩︎
homophily:据我简单谷歌,homophily应该是一种同类相聚的倾向,一种理论。
其他可以参考我之前写的这篇笔记:
cs224w(图机器学习)2021冬季课程学习笔记6 Message Passing and Node Classification_诸神缄默不语的博客-CSDN博客 ↩︎
















 564
564











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











