






Q学习(Q-learning)路径规划算法。
matlab代码。
智能体与环境交互来更新Q值表。
可以通过窗口界面方便观察交互过程
非4栅格拓展 智能体可以在一个栅格向8个方向拓展。
代码注释详尽,可以方便替换自己的地图。
#路径规划 #强化学习 #Q学习
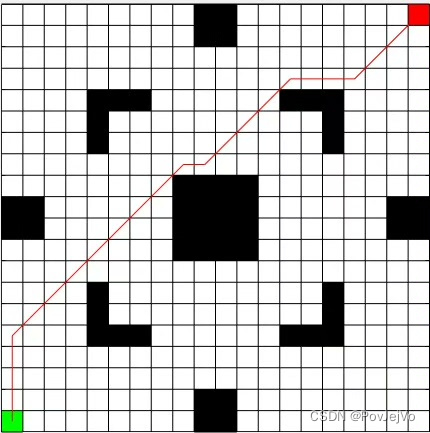
Q学习(Q-learning)是一种经典的路径规划算法,被广泛应用于智能体与环境交互的强化学习任务中。本文将介绍Q学习算法的原理及其在路径规划中的应用,并提供一份基于Matlab实现的代码。
1. 引言
路径规划是指根据起点和终点之间的条件和约束,找到一条最优或次优的路径,以实现有效而安全的导航。强化学习则是一种从环境中学习的方法,智能体通过与环境的交互来不断更新自己的行为策略。Q学习作为强化学习算法的一种,通过建立一个Q值表来指导智能体在不同状态下采取最优的行动。
2. Q学习算法原理
Q学习的核心思想是在智能体与环境的交互中,通过更新Q值表来指导智能体的行动选择。Q值表是一个二维数组,其中行表示智能体的不同状态,列表示智能体可以采取的行动。智能体在每一次交互后,通过观察到的奖励和下一状态的Q值来更新当前状态的Q值。具体的更新公式如下:
Q(s, a) = Q(s, a) + α * (R + γ * maxQ(s', a') - Q(s, a))
其中,Q(s, a)表示在状态s下采取行动a的Q值,α为学习率,R为观察到的奖励,γ为折扣因子,s'为下一状态,a'为在下一状态下的最优行动。通过不断与环境交互并更新Q值表,智能体能够逐步学习到最优的行动策略。
3. 基于Matlab的Q学习路径规划代码
我们提供了一份基于Matlab的Q学习路径规划代码,该代码实现了一个智能体与环境的交互过程,并根据交互结果更新Q值表。代码提供了一个窗口界面,方便用户观察智能体与环境的交互过程。
在代码中,我们使用了非4栅格拓展的方法,智能体可以在一个栅格向8个方向拓展。这样可以增加路径规划的灵活性,使得智能体能够更好地适应各种环境。同时,我们还为代码提供了详尽的注释,方便用户替换自己的地图,并理解代码的运行过程。
4. 结论
本文介绍了Q学习路径规划算法及其在智能体与环境交互中的应用。通过不断更新Q值表,智能体能够学习到最优的行动策略,从而实现有效的路径规划。我们提供了一份基于Matlab的代码,方便用户进行实验和验证。希望本文对读者在路径规划和强化学习方面的研究和应用提供了一定的帮助。
关键词:路径规划、强化学习、Q学习。
相关代码,程序地址:http://lanzoup.cn/745213645550.html















 954
954











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









