









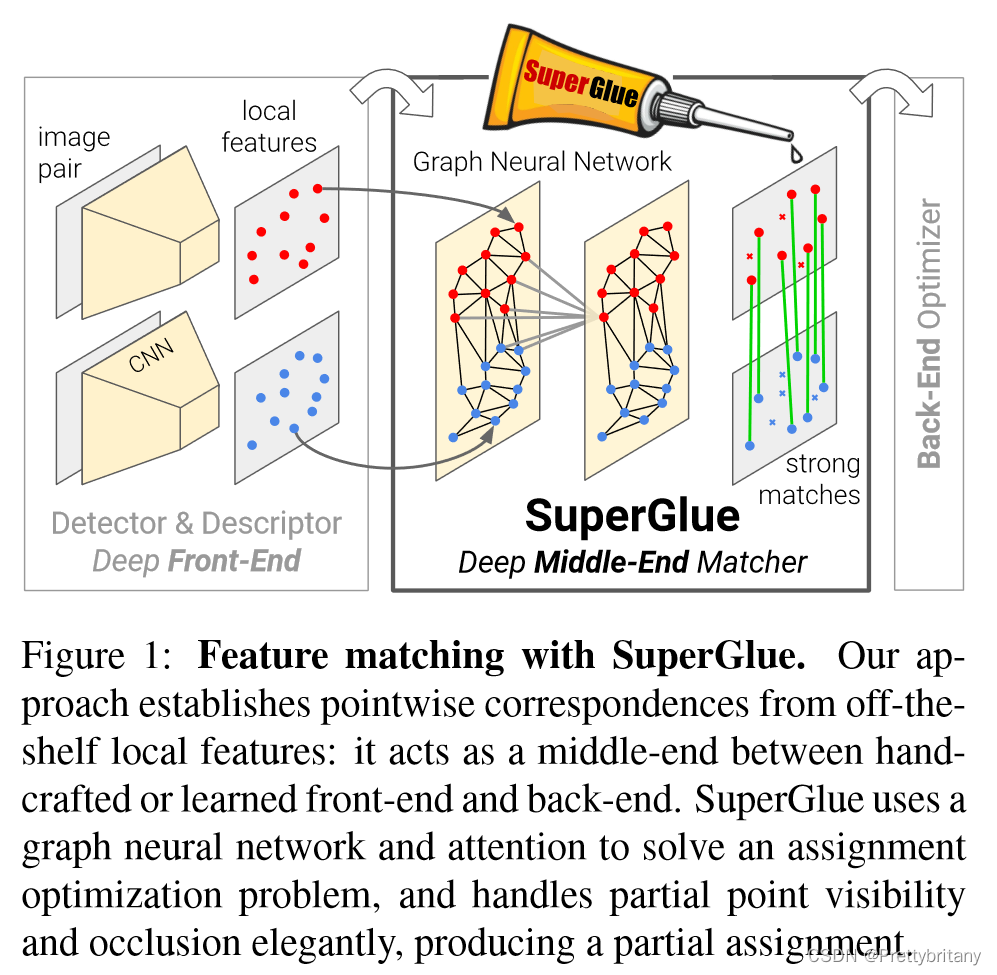
 本文介绍了一种基于图神经网络的SuperGlue方法,用于学习特征匹配,通过解决可微的最优传输问题并利用注意力机制处理3D场景和特征分配。SuperGlue通过端到端训练超越传统方法,在复杂环境中的姿态估计任务上取得最新成果,实现实时匹配并适用于SLAM和SfM系统。
本文介绍了一种基于图神经网络的SuperGlue方法,用于学习特征匹配,通过解决可微的最优传输问题并利用注意力机制处理3D场景和特征分配。SuperGlue通过端到端训练超越传统方法,在复杂环境中的姿态估计任务上取得最新成果,实现实时匹配并适用于SLAM和SfM系统。
SuperGlue:Learning Feature Matching with Graph Neural Networks
论文链接:SuperGlue: Learning Feature Matching With Graph Neural Networks (thecvf.com)
Abstract
This paper introduces SuperGlue, a neural network that matches two sets of local features by jointly finding correspondences and rejecting non-matchable points. Assignments are estimated by solving a differentiable optimal transport problem, whose costs are predicted by a graph neural network. We introduce a flexible context aggregation mechanism based on attention, enabling SuperGlue to reason about the underlying 3D scene and feature assignments jointly. Compared to traditional, hand-designed heuristics, our technique learns priors over geometric transformations and regularities of the 3D world through end-to-end training from image pairs. SuperGlue outperforms other learned approaches and achieves state-of-the-art results on the task of pose estimation in challenging real-world indoor and outdoor environments. The proposed method performs matching in real-time on a modern GPU and can be readily integrated into modern SfM or SLAM systems. The code and trained weights are publicly available at github.com/magicleap/SuperGluePretrainedNetwork.
这篇文章介绍了一种通过同时寻找描述子和拒绝不匹配的特征点来匹配两种局部特征的神经网络。通过求解可微的最优传输问题来估算分配,该问题的代价通过图神经网络来预测。我们介绍了一种灵活的基于注意力机制的上下文聚合机制,使得superglue可以同时推理出底层的3D场景和特征分配。与传统的手工设计的方法相比,我们的技术通过端到端的训练从图片对中学习几何变换和3D世界的规则的先验知识。superglue比其他学习方法表现得更好并且在具有挑战的现实世界的室内和室外环境的姿态估计任务中取得了最好的结果。这个方法可以在GPU上实时匹配并且可以被很容易的集成到到SfM和SLAM系统中去。代码和训练好的权重都在github主页。
1.Introduction
研究背景:
1.找到图片中点的对应在估计3D结构和相机姿态是很重要的,例如在SLAM和SfM这样的几何计算机视觉任务中。
2.这种对应关系通常是通过局部特征点匹配来估计,这一过程叫做数据关联。
3.大型的视点和光照变化、遮挡、模糊以及缺少纹理使得2D到2D数据联系起来非常具有挑战性。
研究方法:
1.提出从预先存在的局部特征中学习匹配过程的神经架构,叫做superglue。作为SLAM任务的中间层。
2.使用GNN预测损失函数的最优解;使用注意力机制同时利用特征点的空间关系和他们的视觉外观。
应用前景:
应用到需要高质量特征对应的多视图几何问题中。

2.Related work
局部特征点匹配
步骤1:寻找特征点;
步骤2:计算视觉描述子;
步骤三:通过NN搜索匹配特征点;
步骤四:滤除不正确的匹配;
步骤五:估计几何变换。
传统方法:
“SIFT [28]”
筛选匹配项::Lowe’s ratio test [28]”
“neighborhood consensus [53, 9, 5, 45]”
寻找变换:“RANSAC [19, 40].”
深度学习方法:
用CNN学习稀疏检测和局部描述子:“[16, 17, 34, 42, 61]” 。
为了提高辨别力,看到更广泛的上下文特征,使用区域特征“[29]” 或者对数极性块“[18].”
通过将匹配项分为内值和外值来滤除匹配项:“[30, 41, 6, 63].”
聚焦于稠密匹配“[43]” 和3D点云“[59],”
不足:依然使用NN搜索来估计,忽略任务结构和视觉信息。
解决不足:我们的方法通过一个端到端的架构同时学习上下文整合、匹配以及滤除。
图匹配
使用GNN。
集合的深度学习
使用注意力机制。
3.The SuperGlue Architecture
Motivation:
在图像配准问题中,有一些现实世界的规律可以被利用。图像对的对应关系必须遵从一些物理约束:
1.一个特征点在其他图像中至多有一个对应点:
2.一些特征点由于遮挡和检测器的故障而不匹配。
提出了SuperGlue来解决优化问题,可以直接从数据中学习先验知识,减少了对领域专家和启发式算法的需求,

Formulation:
描述子d:用CNN(例如superpoint)或者传统描述子(例如SIFT)提取。
位置p:包含图像的坐标以及检测置信度c。
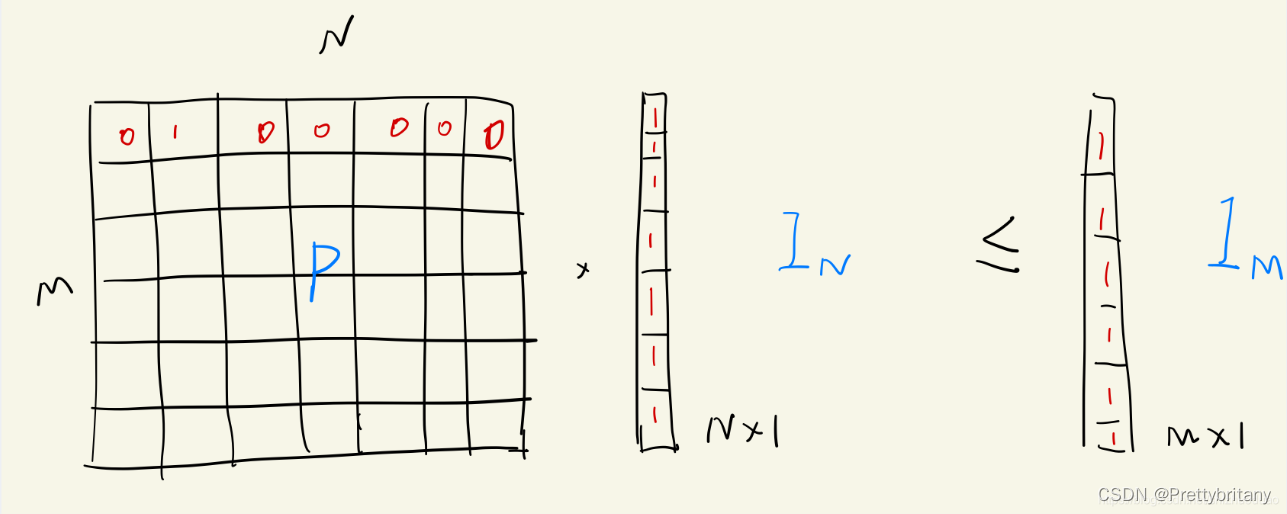
Partial assignment:
为了集成到下游任务中和更好的可解释性,每一个可能的对应关系都需要有一个置信值,于是定义部分软分配矩阵P:
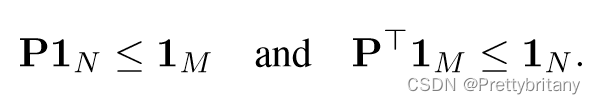
3.1 Attention GNN
这里有个有意思的说法:特征点的位置以及视觉外观能够提高其特异性。另外一个具有启发性的观点是人类在寻找匹配点过程是具有参考价值的。想一下人类是怎样进行特征匹配的,人类通过来回浏览两个图像试探性筛选匹配关键点,并进行来回检查(如果不是匹配的特征,观察一下周围有没有匹配的更好的点,直到找到匹配点/或没有匹配)。上述过程人们通过主动寻找上下文来增加特征点特异性,这样可以排除一些具有奇异性的匹配。本文的核心就是利用基于注意力机制的GNN实现上述过程,即模拟了人类进行特征匹配。
keypoint encoder:
最初的特征表示通过结合视觉特征和位置,用MLP将位置嵌入到更高维度的向量:
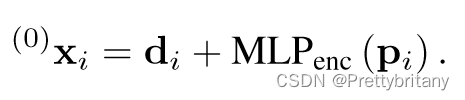
Multiplex GNN:
点:特征点
self edges:在同一张图片中连接特征点与其他所有特征点。
cross edges:连接特征点与其他图片的所有特征点。

Attention Aggregation:
self(cross) edges通过self(cross) attention计算.
attention计算公式:
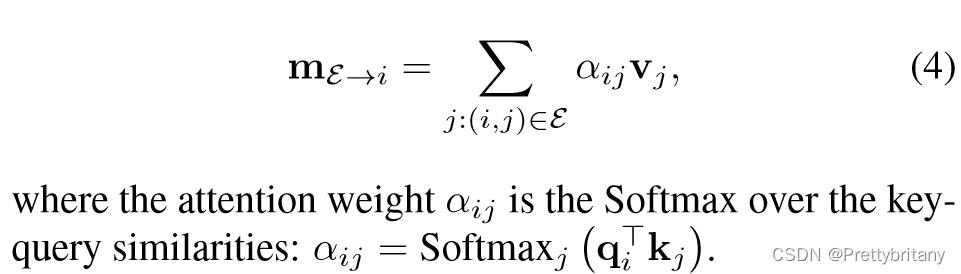

(Sarlin 等, 2020, p. 4941)
3.2 Optimal matching layer

Score Prediction:
求内积作为相似度衡量
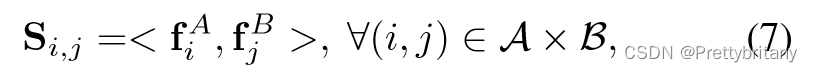
Occlusion and Visibility:
把没有对应匹配特征点的点扔进垃圾桶,滤出错误的匹配点。
Sinkhorn Algorithm:
3.3.Loss
















 1936
1936











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









