









CrossFuse: A novel cross attention mechanism based infrared and visible image fusion approach(2024InfFus)
现有方法存在问题
-
红外和可见光图像之间的相似性差异大,使得从这两种模态中提取互补信息变得困难。
-
多阶段融合方法在处理图像时可能会导致信息丢失,并且通常计算成本较高。
-
设计有效的端到端融合模型面临挑战,需要精心设计的损失函数来优化性能。
-
现有基于Transformer的方法过于侧重于自注意力机制而没有充分探索交叉注意力机制,忽视了增强互补信息的重要性。
本文贡献
-
提出了一种增强多模态特征的交叉注意力机制。
-
展示了一种新颖的混合融合网络,结合了卷积层和注意力机制(包括自注意力和交叉注意力)的优势。
研究方法
网络架构
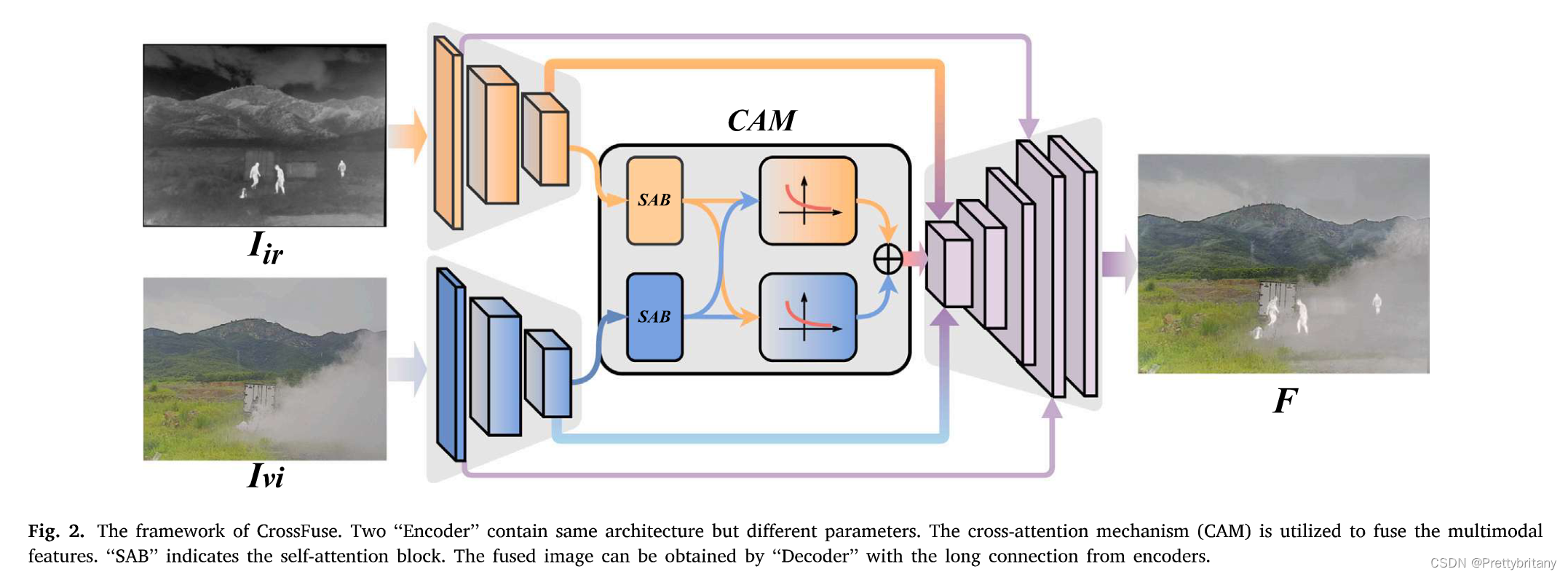
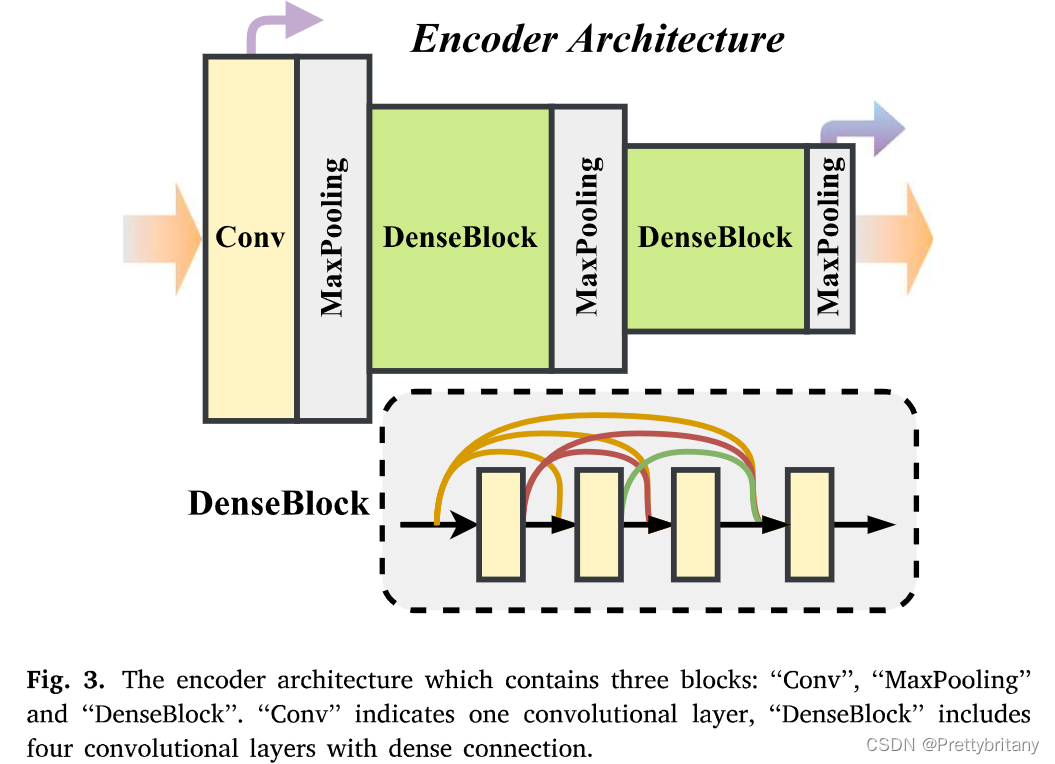
编码器架构
交叉注意力机制
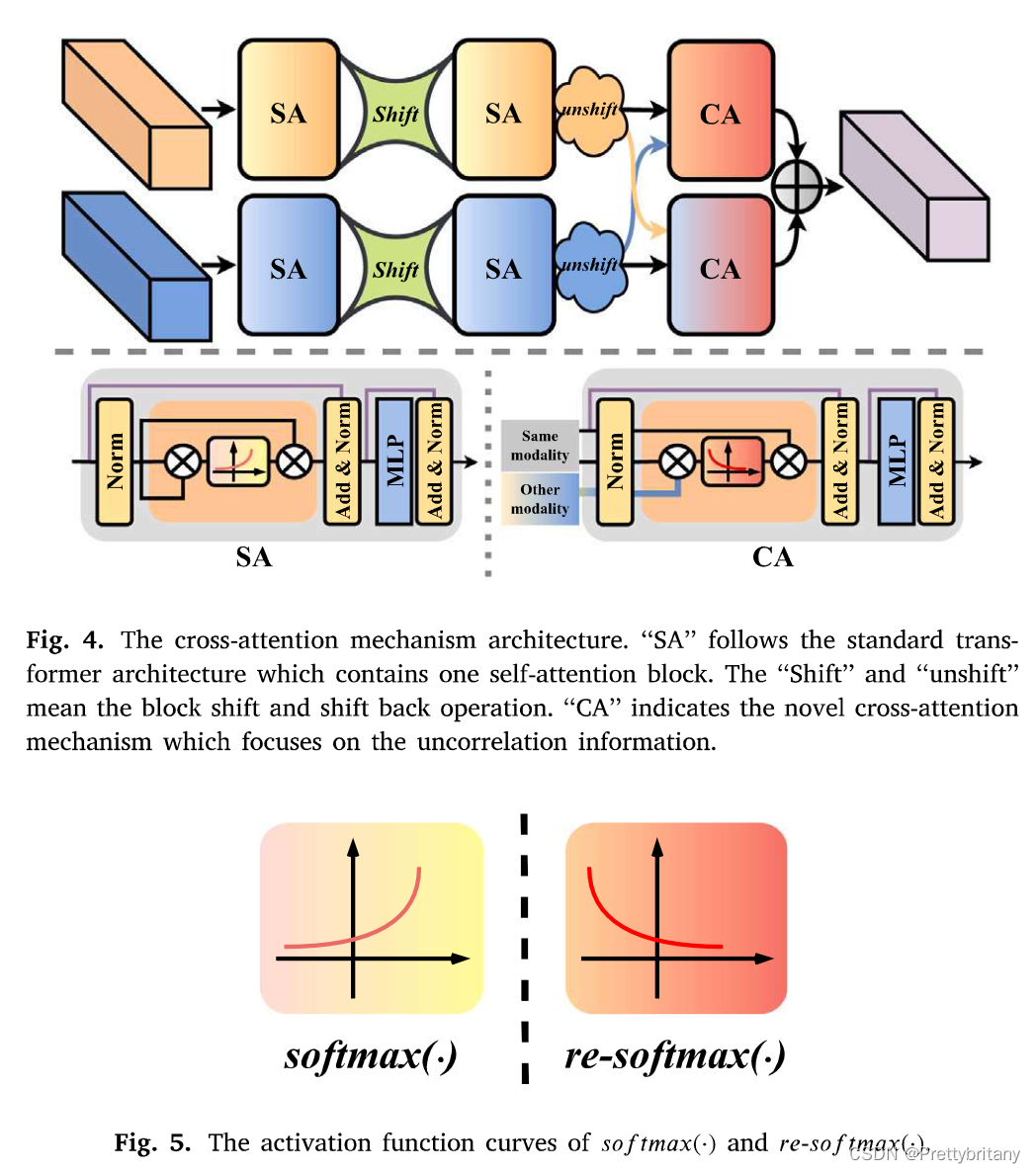
自注意力机制:
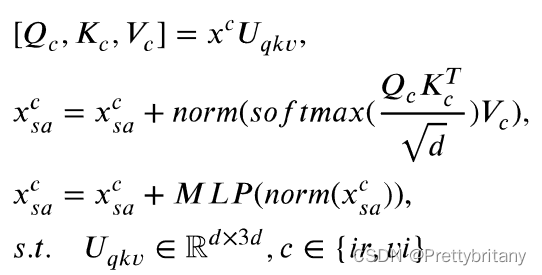
交叉注意力机制:
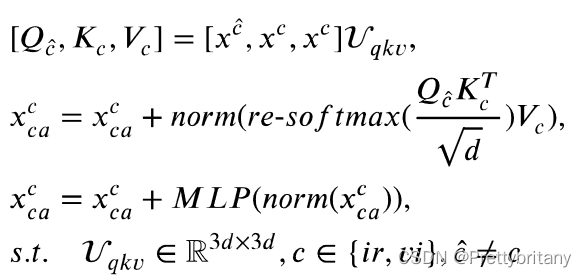
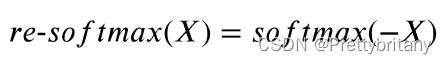
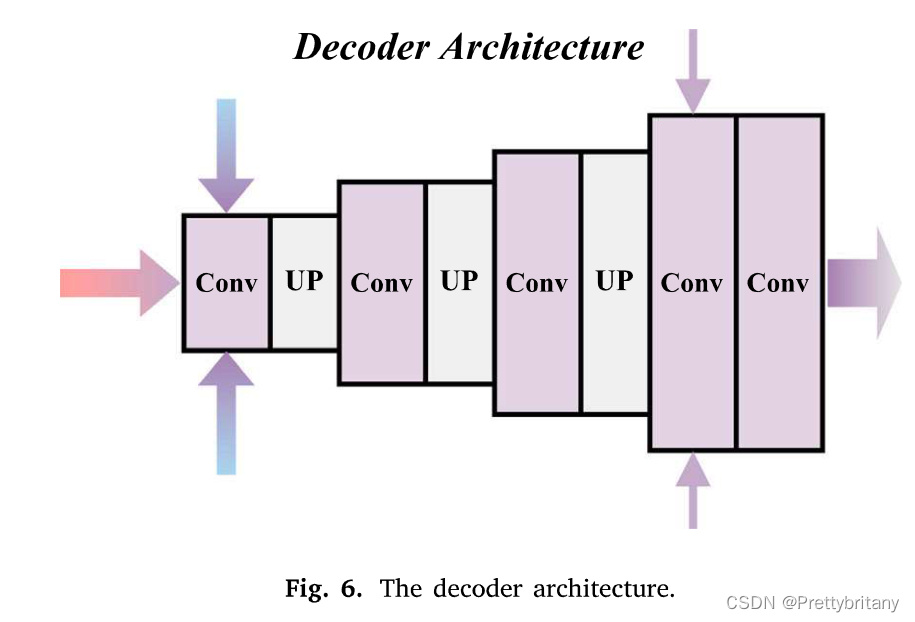
解码器架构

两阶段训练策略
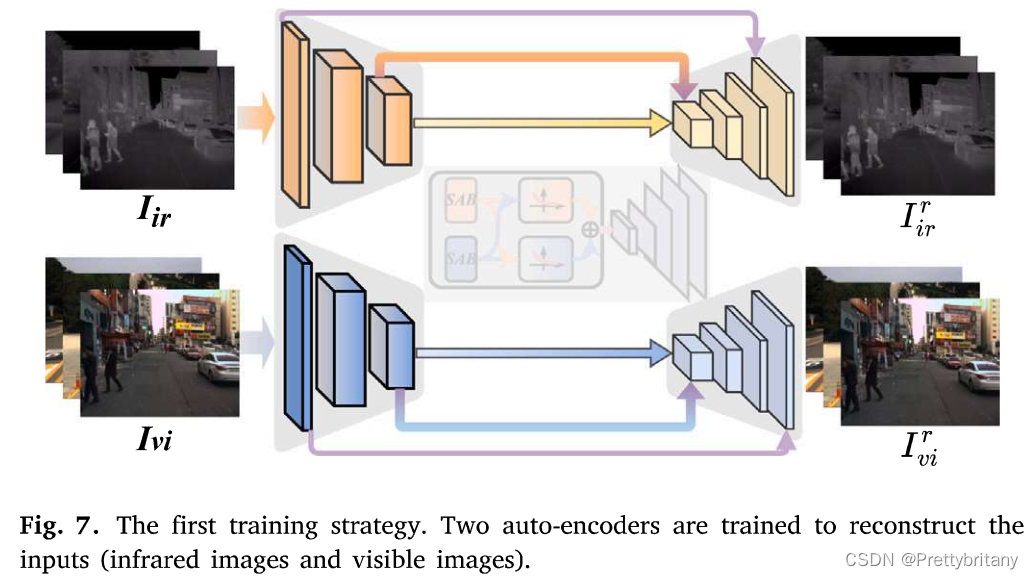
第一阶段:重建(编码器)
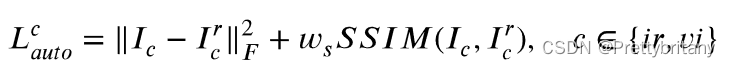
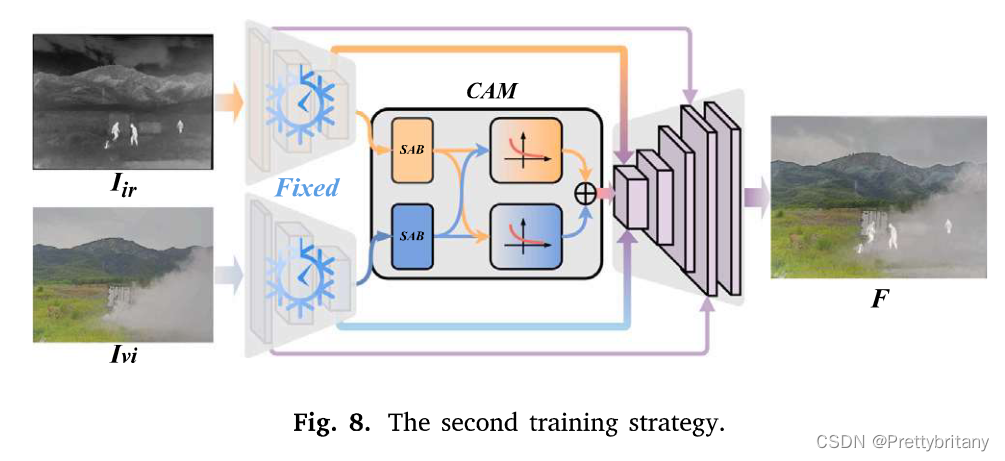
第二阶段:融合(CAM和解码器)
损失函数:
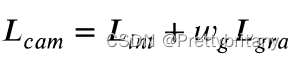
像素强度损失关注图像的照明和轮廓

梯度损失关注细节
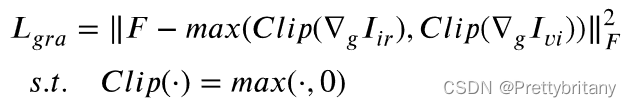
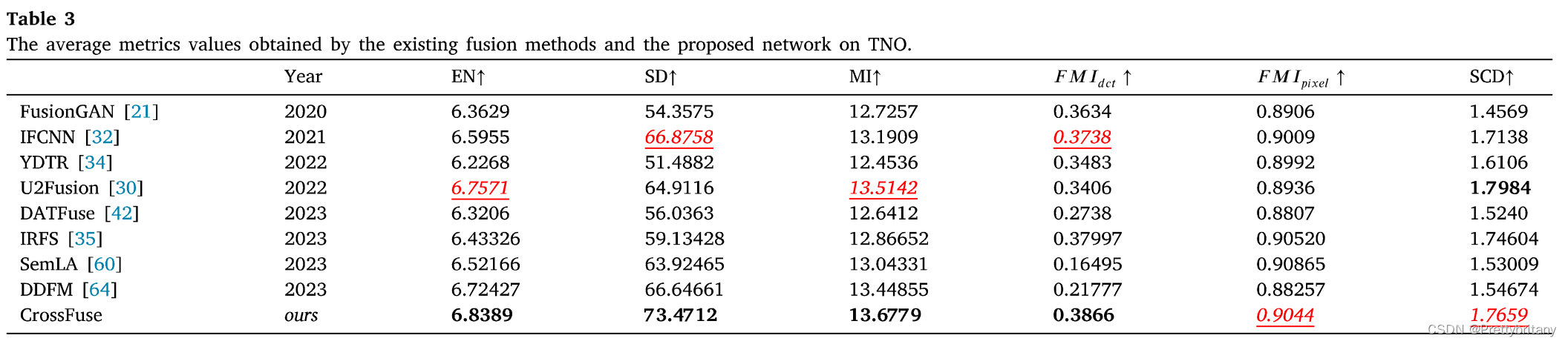
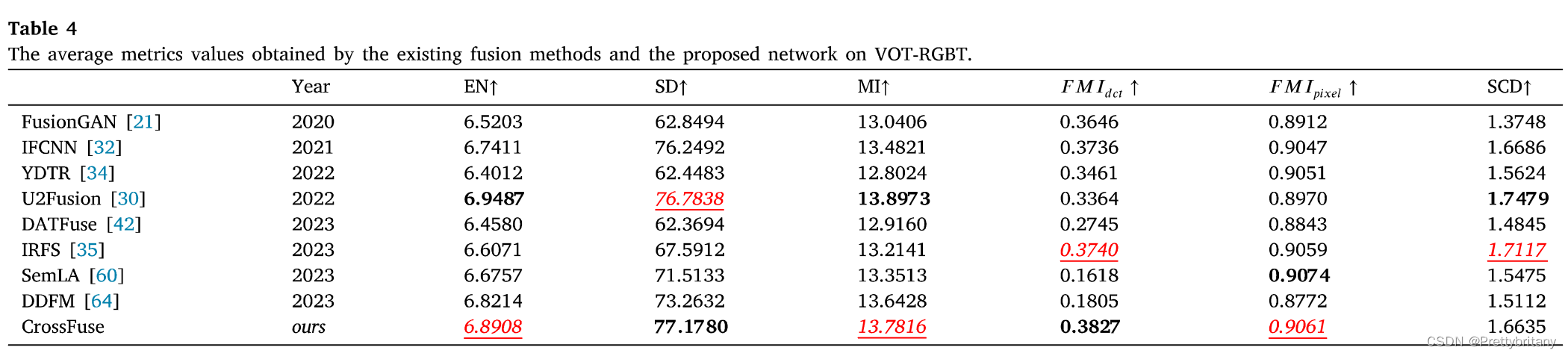
实验结果















 6015
6015

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









