









Rethinking the necessity of image fusion in high-level vision tasks: A practical infrared and visible image fusion network based on progressive semantic injection and scene fidelity
模型概述
整体框架
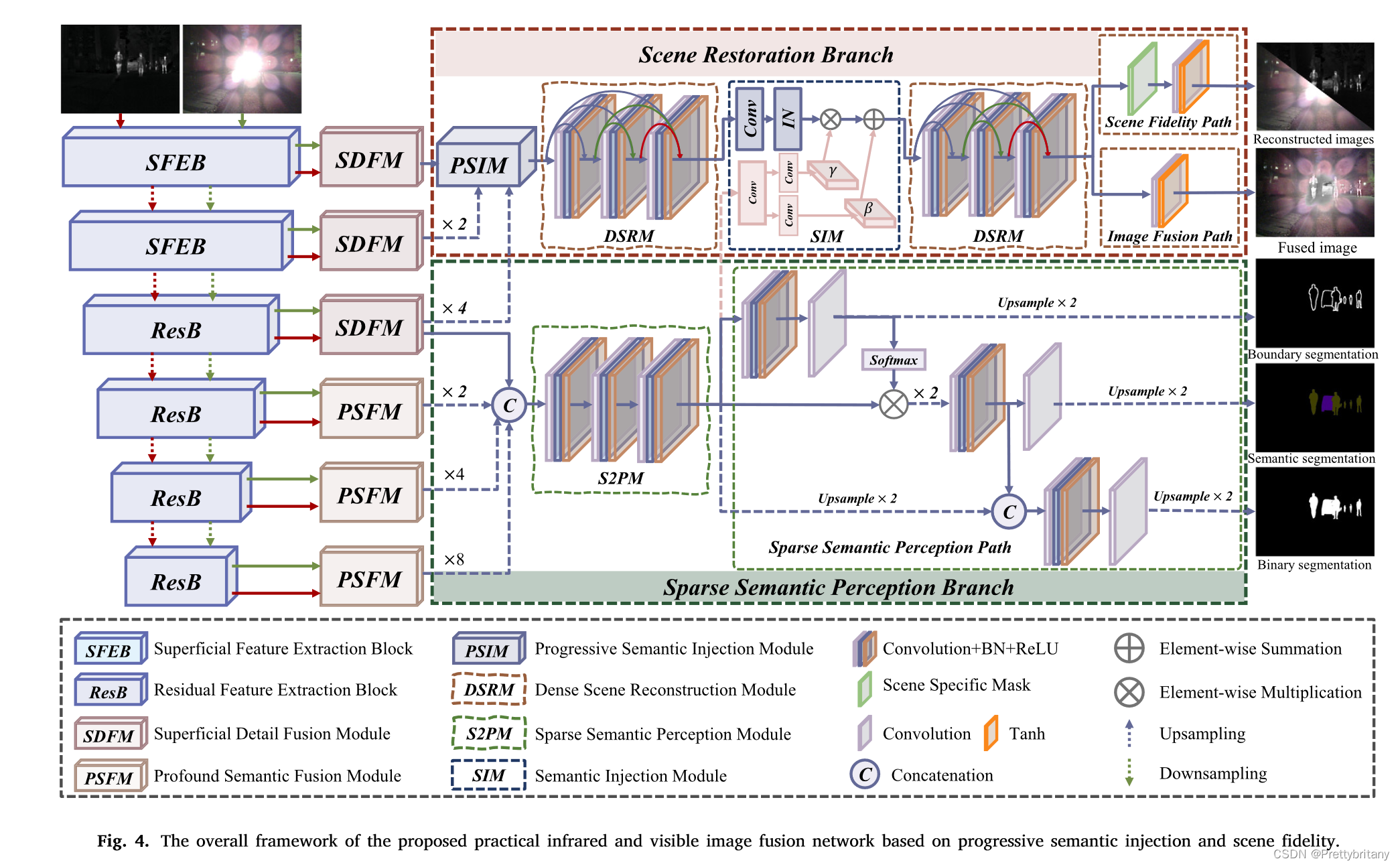
场景恢复分支旨在重建红外图像̂Iir和可见光图像̂Ivi,以及合成融合图像If;稀疏语义感知分支负责预测边界分割结果Ibd、语义分割结果Ise和二值分割结果Ibi。
为了在语义感知分支和场景恢复分支之间轻松注入语义特征,我们期望共享这两个分支之间的特征提取网络。然而,场景恢复分支需要保持高分辨率特征以保留细节,而高级视觉任务需要降采样来提取足够的语义特征并捕捉整体结构。这两个要求之间的矛盾阻碍了我们使用现有的骨干作为特征提取网络。因此,我们选择将ResNet作为基本特征提取网络,并设计了两个表层特征提取块(SFEB)来替换ResNet的第一层。
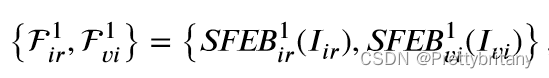
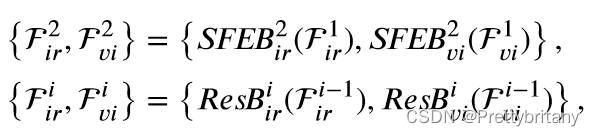
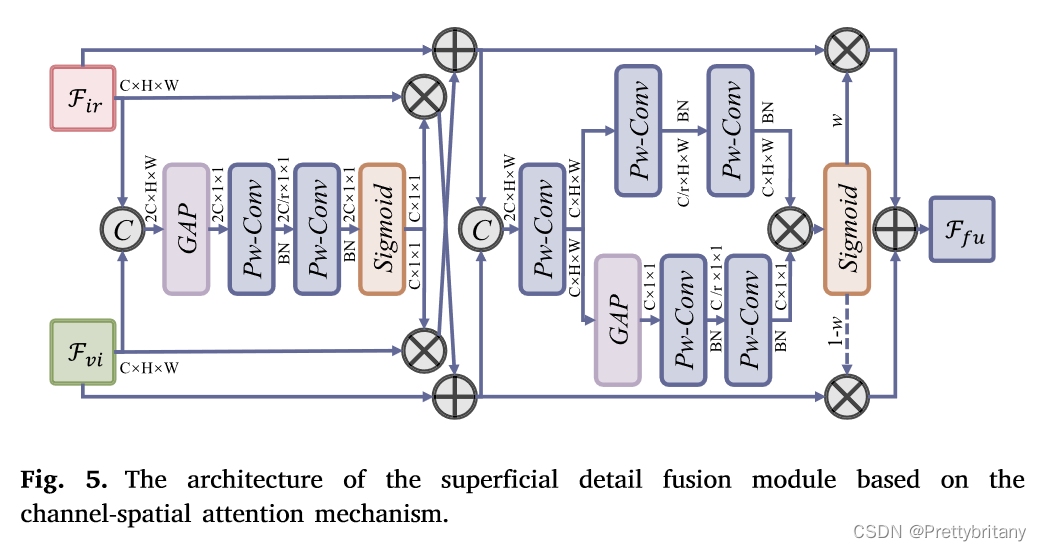
浅层细节融合模块(SDFM)
考虑到浅层特征包含丰富的细节和结构信息,我们提出了一种基于通道空间注意机制的浅层细节融合模块(SDFM)来集成浅层特征:
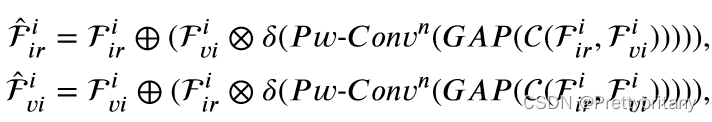
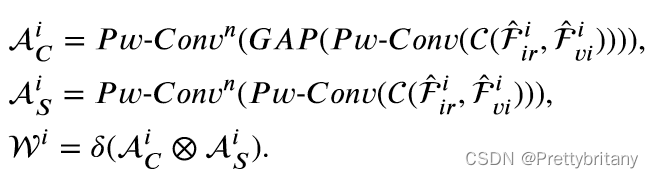
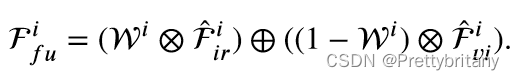
深度语义融合模块(PSFM)
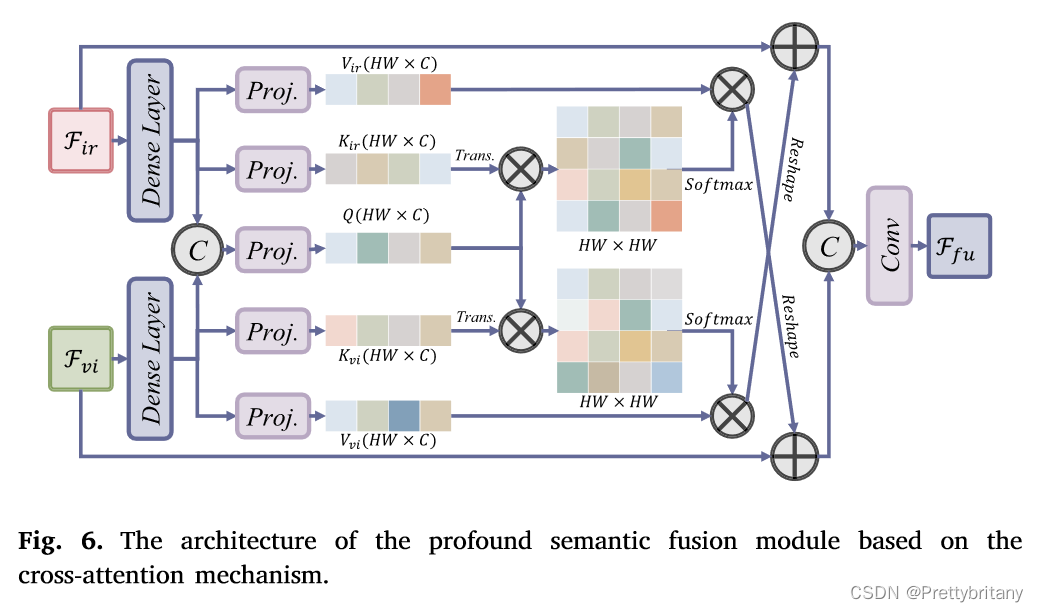
鉴于高级视觉任务通常需要丰富的上下文信息来进行全面理解,我们开发了一种基于交叉注意力的深度语义融合模块(PSFM)来集成深层特征:
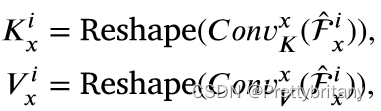
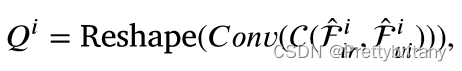


语义感知分支
因为场景恢复分支需要从语义感知分支中吸收语义特征。更具体地说,表面特征包含大量的低级信息,即详细信息,这可能会对高级视觉任务的性能产生负面影响[66]。因此,我们的稀疏语义感知分支仅利用深层特征和最后的浅层特征来预测边界、语义和二元分割结果。这些特征首先经过卷积和上采样操作,然后在通道维度中连接起来,如下所示:
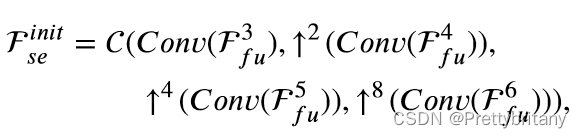
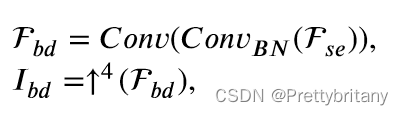

渐进式语义注入模块(PSIM)
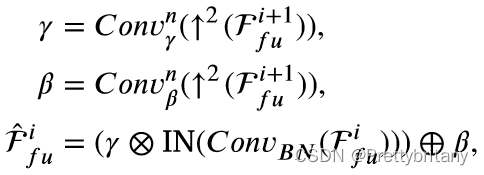
场景恢复分支(DSRM)
损失函数
融合损失
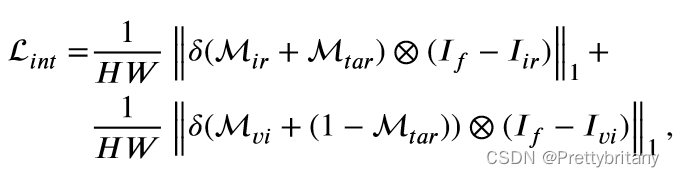
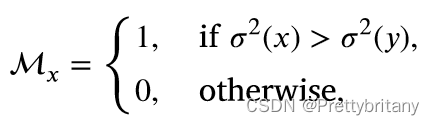
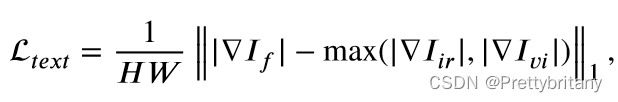
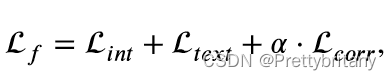
辅助损耗
场景保真度损失

总损失:
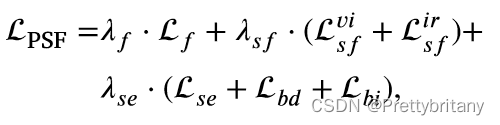















 2330
2330











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









