







文章目录
之前我们讲到全连接神经网络对一些已经表示成向量的比较简洁的形式是有效的
深度学习修炼(二)全连接神经网络 | Softmax,交叉熵损失函数 优化AdaGrad,RMSProp等 对抗过拟合 全攻略_Qodi的博客-CSDN博客
对于复杂图像等的输入是有很大的局限的,而通过卷积网络就可以实现更好的效果
这篇文章中讲了关于卷积操作及其一些进阶的操作
深度学习修炼(三)卷积操作 | 边界填充、跨步、多输入输出通道、汇聚池化_Qodi的博客-CSDN博客
1 回顾
具体来说,在一个卷积网络中,往往有如下的多个层,他们的功能总结如下
(1)卷积层 Conv
进行特征提取
(2)激活层
非线性操作,往往跟在卷积层后
堆叠卷积层和激活层,不断提取更深的语义特征
(3)池化层 Pooling
对每一个特征响应图独立进行,降低特征响应图每个特征响应图组中每个特征相应图的宽度和高度,减少后续卷积层的参数数量,降低计算资源耗费,进而控制过拟合
一般而言,每pool一层,尺寸下降一倍
同时缩小大小,可以增大卷积核的视野,看到更大的图
(4)全连接层
对卷积网络的特征进行变化分类
2 AlexNet的重要性
今天我们开始看经典的卷积神经网络,感受这些网络的设计思想,进一步感受不同层的作用
首先从AlexNet开始
AlexNet是一种深度卷积神经网络,由Alex Krizhevsky、Ilya Sutskever和Geoffrey Hinton于2012年开发,被广泛认为是深度学习在计算机视觉领域取得突破性进展的重要里程碑之一。在ImageNet大规模数据集上表现取得历史最好成绩。
证明了这种深度网络的可行性!
3 AlexNet解析
3.1 结构

层数统计
计算层数时仅统计卷积层与全连接层
因为池化层和归一化层都是对它们前面卷积层输出的特征图进行后处理,不单独算一层
所以这个网络可以是8层 : 卷积5层+全连接3层
3.1.1 CONV1
卷积核11×11 (用96个卷积核)深度通道变为96 步幅4 填充0
问题1 输入227×227×3 大小的图像,输出特征图个数及尺寸为多少?
(227-11)/4+1=55
所以是 尺寸 55×55
个数 96
问题2 卷积核的深度是多少?
卷积核的深度是由输入通道数决定的,所以是3
问题3 这层要学的参数有多少
(11×11×3+1)× 96 =35K
+1是偏置,每个卷积都有一个偏置参数
给一张图像,输出了96个特征图,也就意味着96种响应信息
之后特征图经过ReLu激活操作,大于0保留,小于0 为0
3.1.2 Max Pool1
池化层移动窗口大小3×3 步长为2
问题1 从卷积层1输入该层后,输出特征图个数及尺寸为多少?
尺寸 (55-3)/2+1=27
通道数不变 96
问题2 该层可学习参数为多少?
学习参数为0,没有参数可以学习!因为他就是按固定的方法采样一下就好
3.1.3 NORM1
局部响应归一化层,较大的值增大,较小的值减小
后来证明这个在深层网络中帮助微小,在后面的网络中基本都去掉了 ,后面就不讲啦
3.1.4 CONV2
卷积核5×5 (用256个卷积核)深度通道变为256 步长1 填充2
问题1 输入27×27×96 大小的特征图组,输出特征图个数及尺寸为多少?
(27-5+2×2)/1+1=27
所以是 尺寸 27×27
个数 256
增加了卷积核的个数,实际增加了卷积核的描述能力
问题2 卷积核的深度是多少?
卷积核的深度是由前面输入通道数决定的,所以96
问题3 这层要学的参数有多少
(5×5×96+1)× 256 =615K
给一张图像,输出了96个特征图,也就意味着96种响应信息
之后特征图经过ReLu激活操作,大于0保留,小于0 为0
3.1.5 Max Pool2
池化层移动窗口大小3×3 步长为2 和第一个池化层一样
问题1 从卷积层2输入该层后,输出特征图个数及尺寸为多少?
尺寸 (27-3)/2+1=13
个数(通道数)不变 256
3.1.6 CONV3 CONV4
这两层都是 卷积核3×3 (用384个卷积核)深度通道变为384 步长1 填充1
问题1 从前面输入该层后,输出特征图个数及尺寸为多少?
两层的尺寸维持不变
(13-3+2×1)+1=13
个数(通道数)维持不变
384
3.1.7 CONV5
这层又把卷积核个数降下来了 卷积核3×3 (用256个卷积核)深度通道变为256 步长1 填充1
问题1 从前面输入该层后,输出特征图个数及尺寸为多少?
两层的尺寸维持不变
(13-3+2×1)+1=13
个数(通道数)降到256
256
3.1.8 Max Pool3
再经过池化层
池化层移动窗口大小3×3 步长为2 和前两个一样
问题1 从前面输入该层后,输出特征图个数及尺寸为多少?
尺寸
(13-3)/2+1=5
通道数 256
得到最终特征响应图组
6×6×256
3.1.9 FC1 FC2 FC3
特征响应图是一个矩阵,但是我们全连接神经网络需要输入一个向量
那好说,我们把矩阵展平成一个长向量 代码中就通过flatten操作实现
向量维度 6×6×256=9216
经过FC1 映射为 4096
经过FC2 映射为 4096
再经过FC3 映射为分类的类别数 如果分类类别是10类就是10,如果是1000,就是1000

3.2 AlexNet使用到的技巧
1 Dropout防止过拟合
2 使用加入动量的小批量梯度下降算法加速了训练过程的收敛
3 采用样本增强,增加训练样本,防止过拟合
4 验证集损失不下降的时候,手动降低10倍学习率
5 集成多个模型,进一步提高概率
单独训练多个模型,每个模型给一个预测,最后把所有预测平均
3.3 可视化
AlexNet卷积层在做什么?
学习一些特征
比如第一层可视化

最后一层可视化
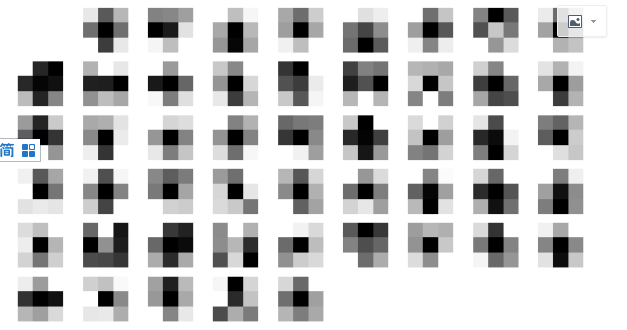
可以发现卷积层学到一些纹理表示,因为很多物体都是通过纹理学习到的
3.4 代码实现模拟
3.4.1 查看每一层输入输出
建立网络,模拟图片输入网络,输出每一层的图片的形状变化
import torch
from torch import nn
net=nn.Sequential(
nn.Conv2d(kernel_size=11,in_channels=3,out_channels=96,stride=4,padding=0),
nn.ReLU(),
nn.MaxPool2d(kernel_size=3,stride=2),
nn.Conv2d(kernel_size=5,in_channels=96,out_channels=256,stride=1,padding=2),
nn.ReLU(),
nn.MaxPool2d(kernel_size=3,stride=2),
nn.Conv2d(kernel_size=3,in_channels=256,out_channels=384,stride=1,padding=1),
nn.ReLU(),
nn.Conv2d(kernel_size=3,in_channels=384,out_channels=384,stride=1,padding=1),
nn.ReLU(),
nn.Conv2d(kernel_size=3,in_channels=384,out_channels=256,stride=1,padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=3,stride=2),
nn.Flatten(),
nn.Linear(9216,4096),
nn.Linear(4096,4096),
nn.Linear(4096,1000)
)
x=torch.randn(1,3,227,227)#模拟一张图片 通道数3 宽 高227
for layer in net:
x=layer(x)
print(layer.__class__.__name__,"输出形状: \t",x.shape)
输出
Conv2d 输出形状: torch.Size([1, 96, 55, 55])
ReLU 输出形状: torch.Size([1, 96, 55, 55])
MaxPool2d 输出形状: torch.Size([1, 96, 27, 27])
Conv2d 输出形状: torch.Size([1, 256, 27, 27])
ReLU 输出形状: torch.Size([1, 256, 27, 27])
MaxPool2d 输出形状: torch.Size([1, 256, 13, 13])
Conv2d 输出形状: torch.Size([1, 384, 13, 13])
ReLU 输出形状: torch.Size([1, 384, 13, 13])
Conv2d 输出形状: torch.Size([1, 384, 13, 13])
ReLU 输出形状: torch.Size([1, 384, 13, 13])
Conv2d 输出形状: torch.Size([1, 256, 13, 13])
ReLU 输出形状: torch.Size([1, 256, 13, 13])
MaxPool2d 输出形状: torch.Size([1, 256, 6, 6])
Flatten 输出形状: torch.Size([1, 9216])
Linear 输出形状: torch.Size([1, 4096])
Linear 输出形状: torch.Size([1, 4096])
Linear 输出形状: torch.Size([1, 1000])
3.4.2 查看每一层参数的形状,参数量
参数只有卷积层和全连接层有,所以在提取参数之前需要进行判断
#查看参数
for i in range(len(list(net.children()))):
print(net[i])
if isinstance(net[i],nn.Conv2d) or isinstance(net[i],nn.Linear):
weight=net[i].weight.data.shape
bias=net[i].bias.data.shape
print("\t 该层权重参数形状",weight)
print("\t 该层偏置参数形状",bias)
num=weight.numel()+bias.numel()
print("\t 该层参数量 ",num)
输出
Conv2d(3, 96, kernel_size=(11, 11), stride=(4, 4))
该层权重参数形状 torch.Size([96, 3, 11, 11])
该层偏置参数形状 torch.Size([96])
该层参数量 34944
ReLU()
MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False)
Conv2d(96, 256, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
该层权重参数形状 torch.Size([256, 96, 5, 5])
该层偏置参数形状 torch.Size([256])
该层参数量 614656
ReLU()
MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False)
Conv2d(256, 384, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
该层权重参数形状 torch.Size([384, 256, 3, 3])
该层偏置参数形状 torch.Size([384])
该层参数量 885120
ReLU()
Conv2d(384, 384, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
该层权重参数形状 torch.Size([384, 384, 3, 3])
该层偏置参数形状 torch.Size([384])
该层参数量 1327488
ReLU()
Conv2d(384, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
该层权重参数形状 torch.Size([256, 384, 3, 3])
该层偏置参数形状 torch.Size([256])
该层参数量 884992
ReLU()
MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False)
Flatten(start_dim=1, end_dim=-1)
Linear(in_features=9216, out_features=4096, bias=True)
该层权重参数形状 torch.Size([4096, 9216])
该层偏置参数形状 torch.Size([4096])
该层参数量 37752832
Linear(in_features=4096, out_features=4096, bias=True)
该层权重参数形状 torch.Size([4096, 4096])
该层偏置参数形状 torch.Size([4096])
该层参数量 16781312
Linear(in_features=4096, out_features=1000, bias=True)
该层权重参数形状 torch.Size([1000, 4096])
该层偏置参数形状 torch.Size([1000])
该层参数量 4097000
3.4.3 快捷计算总的参数量
num=0
for parameter in net.parameters():
num=num+parameter.numel()
print("参数量",num)
输出
参数量 62378344
4 AlexNet的主体贡献
网络结构
1 提出了一种卷积层加全连接层的卷积神经网络结构
训练部分
2 首次使用ReLu函数作为神经网络激活函数
3 首次提出Dropout正则化来控制过拟合
4 使用加入动量的小批量梯度下降算法加速了训练过程的收敛
数据处理
5 使用数据增强极大地抑制了训练过程的拟合
设备部分
6 利用了GPU的并行计算能力,加速了网络的训练与判断
5 AlexNet的改进ZFnet
1 将第一个卷积层的卷积核大小改为了7×7
卷积核越大,感受的信息越粗粒度,卷积核越小,感受的信息越细粒度
刚开始直接用粗粒度的大卷积核会导致丢失很多的细节信息,对后面分类任务有影响
2 将第二,三个卷积层的卷积步长设置为了2
希望这种特征图的分辨率慢慢的降
避免信息损失太快
3 增加了第三,四个卷积层的卷积核个数
作者发现第三四层已经开始有高层概念了
用更多个卷积核,可以学习到更多的组合特征















 848
848











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









