









收藏关注不迷路
前言
在这样的背景和要求之下,在对信息采集技术的工作原理,以及常见的爬虫框架、采集算法进行了深入的学习和研究,在对信息网站的结构特征进行了深刻的分析之后,结合采集对象的特征,将两种算法相结合,设计出了四种采集程序,并基于Soapy框架,采用了中间件技术,开发了动态浏览器标识和代理池。利用MySQL数据库和云平台虚拟化技术,构建了一套可靠性和可行性极高的分布式收集集群,提高了数据收集效率,利用PYQT5实现跨平台的信息发布程序,利用Selenium自动化工具,解决了网站登陆、网站查询以及模拟人工进行数据收集。利用FLASK技术实现了资料收集与管理系统及大屏幕的显示功能。另外,在数据清洗的基础上,通过数据清洗,格式转换,移除和增加对象,以达到数据的一致性。
本文以Python为基础,对外卖数据进行了分析,从而极大地降低了有关产业的资讯工作者的工作强度,为更快、更好、更方便地获得发布资讯,提供了技术支撑。到现在为止,这个系统已经从最初的收集对象,到最近的几百个国际和国内的站点,已经有一年多的时间了,收集到了395万条的数据。
关键词:外卖数据;信息采集;Python
一、项目介绍
本论文的研究目的是为了给采编者提供一套完善、高效的智能信息收集解决方案,并利用一系列的程序设计与开发,为采编者提供一个具备稳定、鲁棒性的信息收集、发布集成平台。本文将以Python为基础,来实现一组分布式收集程序。在此过程中,编辑人员可以通过所收集的网站来确定收集URL和收集的主题词。此外,还可以选择一位对网页设计稍微了解一些的运营人员,去寻找一条通用的收集路径,与此同时,还可以对收集规则及清洗规则进行定制,这样就可以很便利的将收集到的信息进行组合,从而形成一套完整的分布式收集系统。在此基础上,利用云计算的虚拟化技术,结合PYQT接口的构建,以及WEB Flask的构建,实现大规模的收集、清洗、分类、发布。
一个分散的消息收集和发布系统必须具有下列特征:
1.基于S-Crapy开放源代码框架,通过云计算、Python、Mysql等技术,构建一种完全可实现、可操作的开放源代码信息收集系统,帮助记者完成工作任务。采编人员仅需输入所收集到的网址及题目即可迅速启动收集工作并进行信息归类。
2.根据新的数据收集要求,采用云计算技术实现新的收集器的迅速部署。对于资料采集点的改版,更新,采集器可以进行智能响应。同时,系统的维护者也能迅速地更新数据收集系统,使之能够适应不断改变的网络环境。
3.收集程序收集信息时,不会对站点的正常运行造成任何影响,也不会占据太多的网络带宽,当站点出现不提供服务时,收集程序会进行智能处理。
4.收集到的信息,可以利用自动清理过程,去掉冗余的html代码,使其具有一致的格式,并根据话题和关键词,对其进行分类标签。
5.可以在多个平台上一次点击发送该消息。
二、开发环境
开发语言:Python
python框架:Scrapy Flask
软件版本:python3.7/python3.8
数据库:mysql 5.7或更高版本
数据库工具:Navicat11
开发软件:PyCharm/vs code
前端框架:vue.js
————————————————
三、功能介绍
在上述需求分析的基础上,通过深入研究,将系统使用人员划分为信息采集编辑、信息维护编辑、信息发布编辑三个角色。然后根据这个人的工作内容,给出了对应的系统函数。本系统为收集资料输入接口,并对收集资料进行维护。具体内容有:网站名称,网站首页,网站主域名,栏目名称,栏目页面 URL,分配爬虫标志,是否开启采集的录入和维护。在图2-5中可以看到。

图2-5信息采集编辑功能图
该系统还给出了 Xpath的保存接口,以及获取的参数的调节接口。主要内容有:网站名称,主要域名,清单获取方法,清单关键字,清单页字段 XPL路径,详细页字段 XPL路径,是否打开测试,本地存储路径,以及是否输入重复参数及如何保存等。在图2-6中可以看到。该系统为用户提供了一个消息发布的接口。具体内容有:当日下载量、当日发布量、昨日下载量、昨日发布量、待处理信息以及显示信息详情、同步发布等。在图2至7中可以看到。
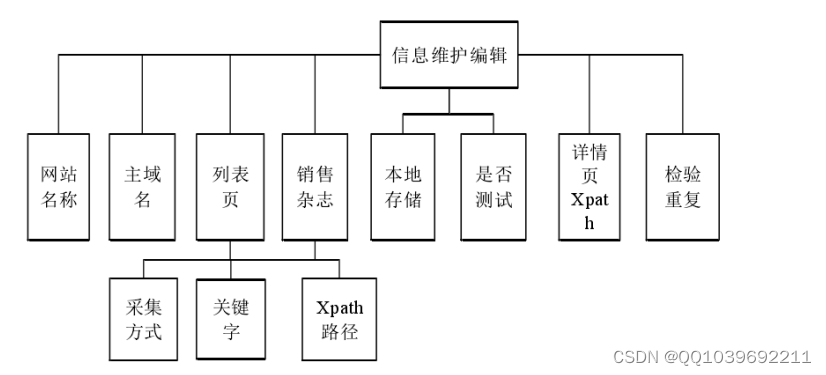
图2-6信息维护编辑功能图
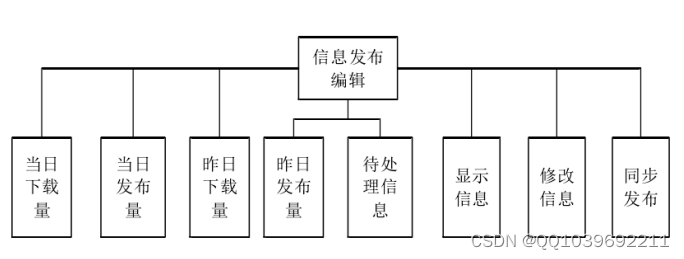
图2-7信息发布编辑功能图
四、核心代码
部分代码:
def users_login(request):
if request.method in ["POST", "GET"]:
msg = {'code': normal_code, "msg": mes.normal_code}
req_dict = request.session.get("req_dict")
if req_dict.get('role')!=None:
del req_dict['role']
datas = users.getbyparams(users, users, req_dict)
if not datas:
msg['code'] = password_error_code
msg['msg'] = mes.password_error_code
return JsonResponse(msg)
req_dict['id'] = datas[0].get('id')
return Auth.authenticate(Auth, users, req_dict)
def users_register(request):
if request.method in ["POST", "GET"]:
msg = {'code': normal_code, "msg": mes.normal_code}
req_dict = request.session.get("req_dict")
error = users.createbyreq(users, users, req_dict)
if error != None:
msg['code'] = crud_error_code
msg['msg'] = error
return JsonResponse(msg)
def users_session(request):
'''
'''
if request.method in ["POST", "GET"]:
msg = {"code": normal_code,"msg":mes.normal_code, "data": {}}
req_dict = {"id": request.session.get('params').get("id")}
msg['data'] = users.getbyparams(users, users, req_dict)[0]
return JsonResponse(msg)
def users_logout(request):
if request.method in ["POST", "GET"]:
msg = {
"msg": "退出成功",
"code": 0
}
return JsonResponse(msg)
def users_page(request):
'''
'''
if request.method in ["POST", "GET"]:
msg = {"code": normal_code, "msg": mes.normal_code,
"data": {"currPage": 1, "totalPage": 1, "total": 1, "pageSize": 10, "list": []}}
req_dict = request.session.get("req_dict")
tablename = request.session.get("tablename")
try:
__hasMessage__ = users.__hasMessage__
except:
__hasMessage__ = None
if __hasMessage__ and __hasMessage__ != "否":
if tablename != "users":
req_dict["userid"] = request.session.get("params").get("id")
if tablename == "users":
msg['data']['list'], msg['data']['currPage'], msg['data']['totalPage'], msg['data']['total'], \
msg['data']['pageSize'] = users.page(users, users, req_dict)
else:
msg['data']['list'], msg['data']['currPage'], msg['data']['totalPage'], msg['data']['total'], \
msg['data']['pageSize'] = [],1,0,0,10
return JsonResponse(msg)
五、效果图
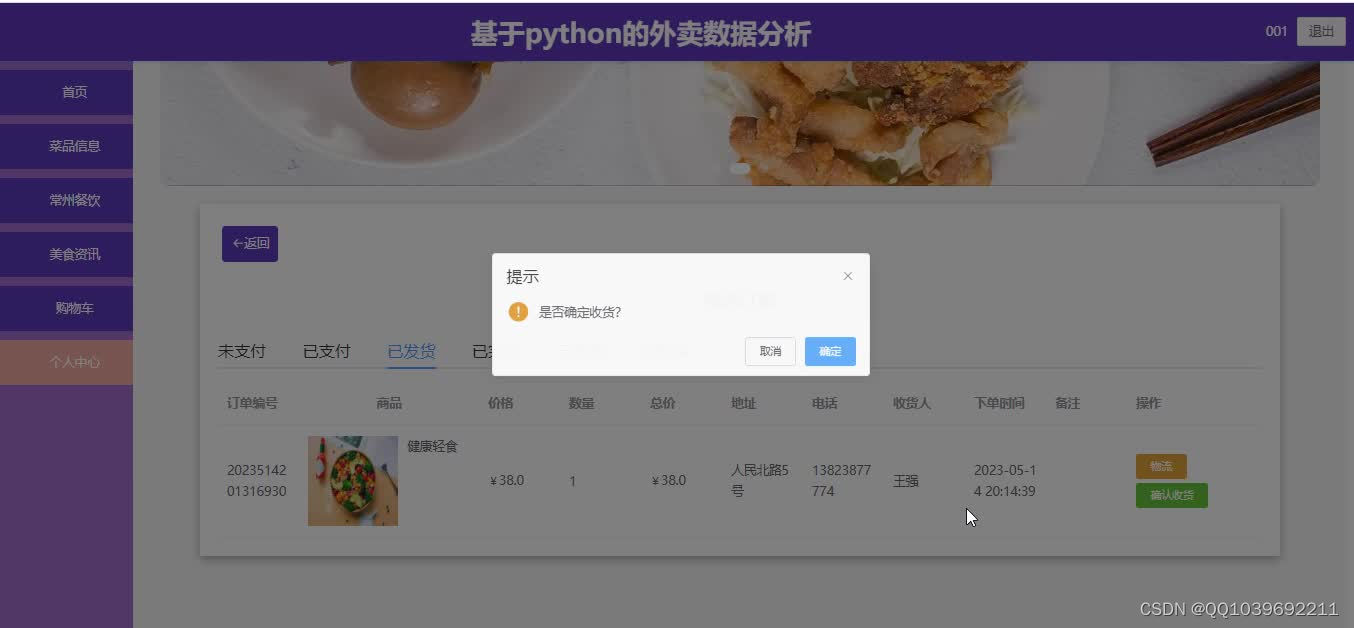
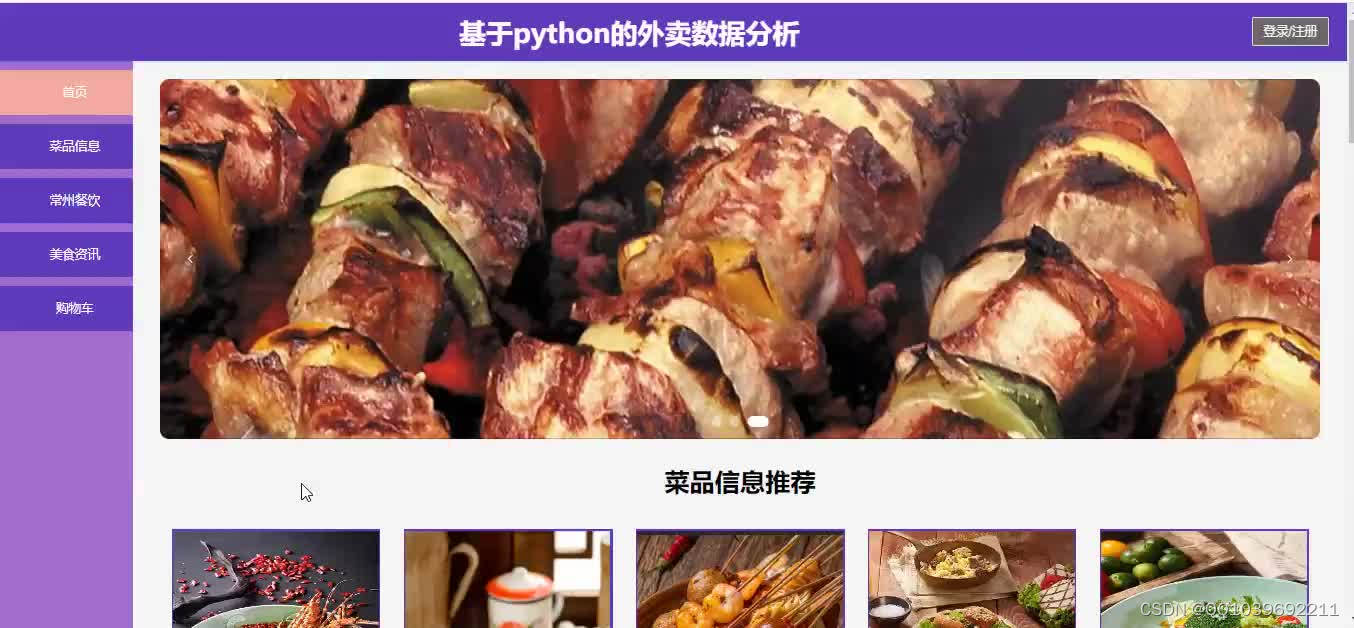
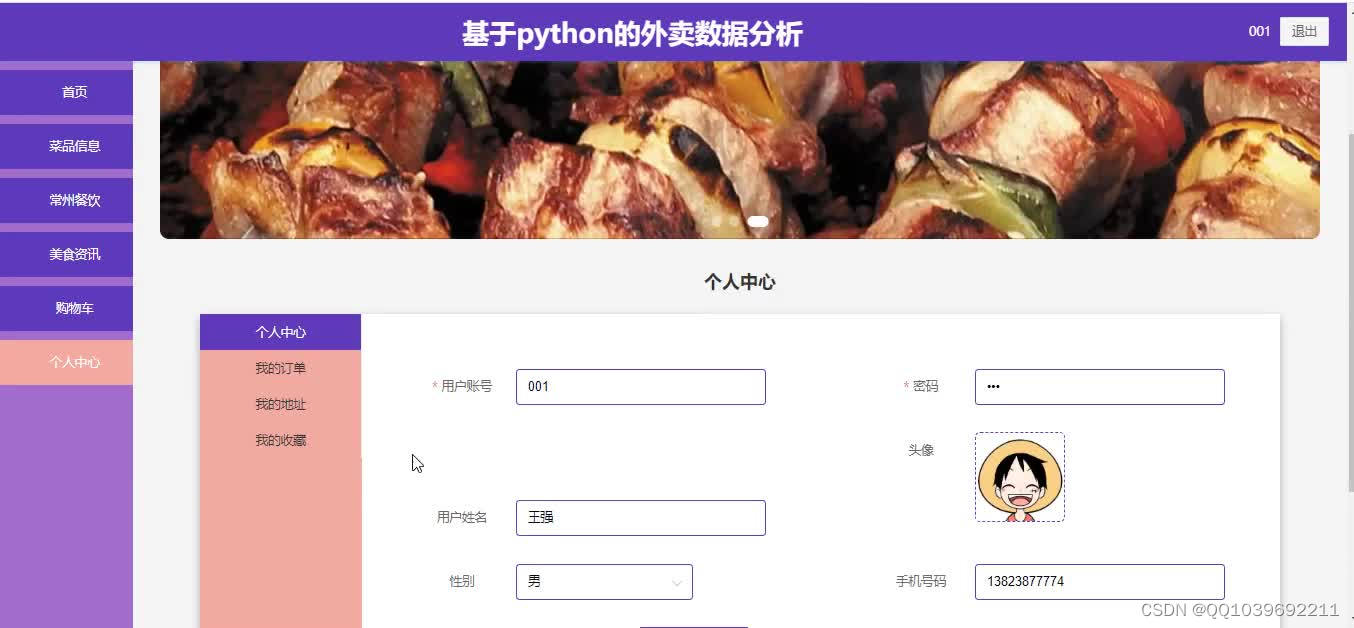

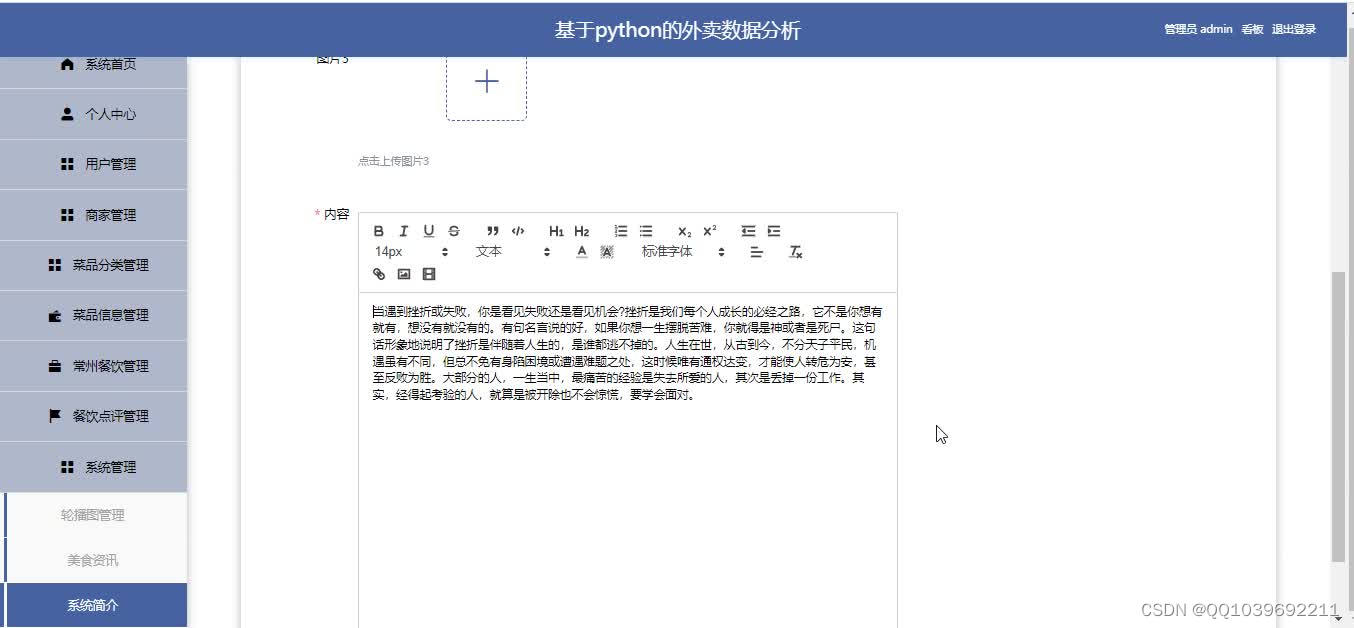
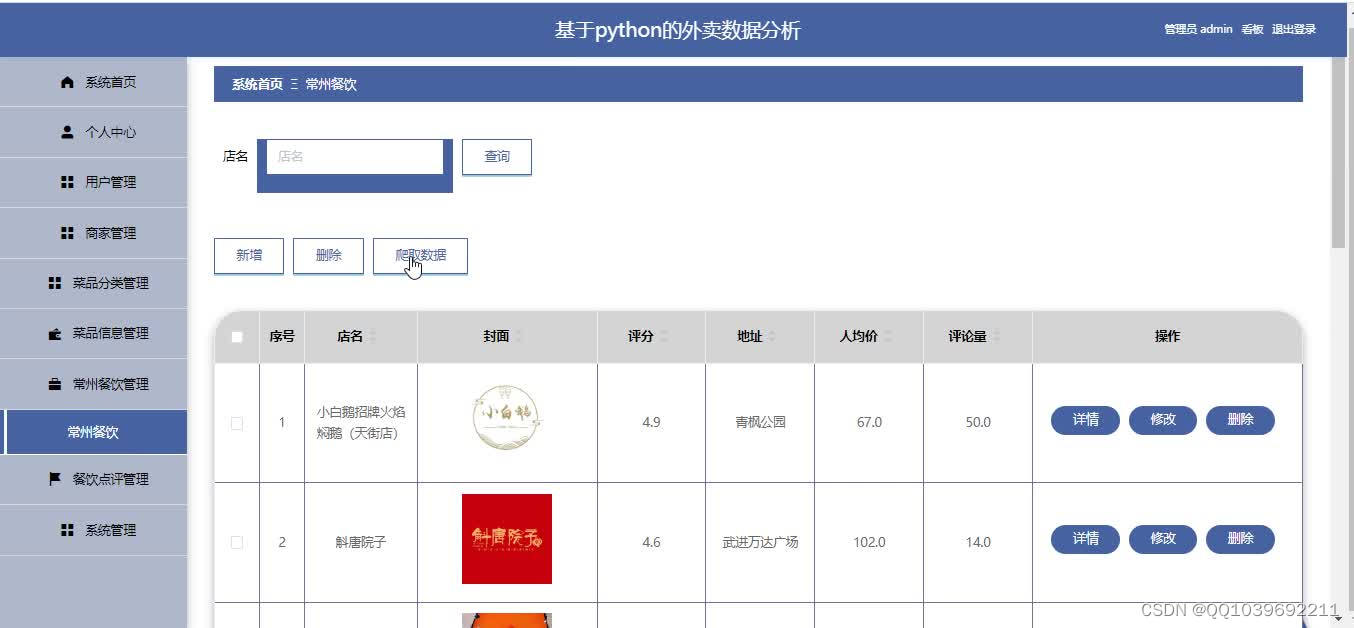
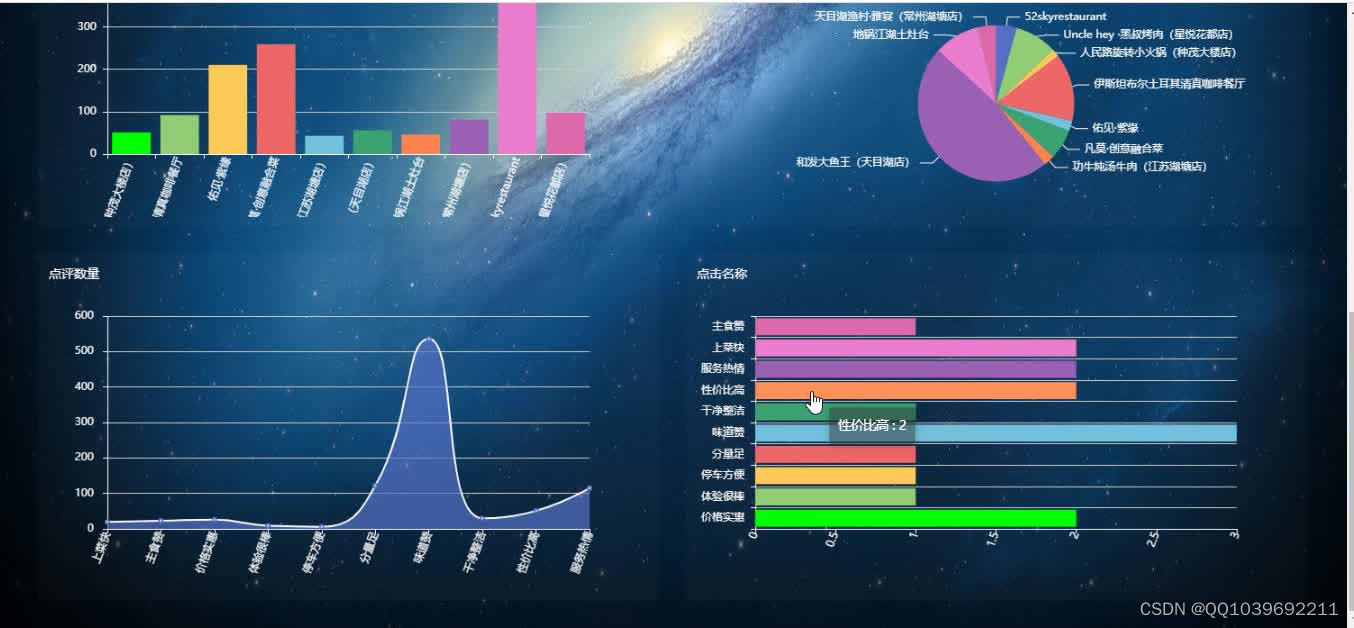
六、总结
本文首先对本项目产生的背景和当前的技术现状进行了简单的描述,然后明确了研究的目的,并与当前几款比较主流的自动化搜集工具进行了对比,最后得出了如下五条有待解决的问题:(1)智能的URL收集。(2)在此基础上,提出了一个新的解决方案,并给出了一个新的解决方案。(3)智能地在收集时进行标记的选取。(4)对收集的结果进行智能的格式统一。(5)对收集到的数据进行智能化的信息分类。为了实现该系统,并解决与之有关的问题,同时也为了方便后续的升级,该系统将Python用作开发语言,将Mysql数据库用作主存储数据库,并将Hbase用作备用存储。
该系统通过对网络中的深度搜索和对话题搜索进行了改善,从而使URL的智能搜索得到了较好的解决;利用云计算的虚拟化技术,以及软件与软件相分离的体系结构,使该体系能够迅速地进行配置和扩充;采用Python软件编程的灵活度以及开放源码的宽泛特性,使其对标记进行了半智能性的选取,并对其进行了智能的格式化;但是,现在这个系统还不能做到真正意义上的智能分类,它只能够利用已经定义好的话题词来进行有针对性的分类。
六、文章目录
目录
1 绪论 1
1.1 研究背景及意义 1
1.2 技术现状 2
1.3 研究目标 2
2 技术基础与系统需求 4
2.1信息采集技术 4
2.1.1网络爬虫 4
2.1.2 Python与Scrapy框架 4
2.1.3分布式部署 5
2.1.4 解析库和Selenium 6
2.1.5 PhantomJS 7
2.2数据存储 7
2.2.1 MySQL 7
2.2.2 HBase 8
2.3超融合数据中心 8
2.4 Flask 9
2.5 PYQT5 10
2.6总体需求 10
2.6.1信息采集编辑分析 10
2.6.2信息运维编辑分析 12
2.6.3 链接清洗 12
2.6.4信息发布编辑分析 14
2.6.5其他分析 14
2.6.6总体需求 15
2.7系统功能图 15
3 系统实现与部署 17
3.1系统实现总述 17
3.2管理程序实现 17
3.3发布程序实现 19
3.4 系统部署 19
3.4.1 运行环境部署 20
3.4.2 数据库部署 21
3.5 其他部署 21
3.5.1 定时运行部署 21
3.5.2 分布式部署 21
4 外卖平台数据分析 22
4.1 研究思路及方法 22
4.1.1 研究思路 22
4.1.2 研究方法 22
4.1.3 模型评估的方法 22
4.1.4 预测中的误差 23
4.1.5 模型评估的指标 23
4.1.6 数据采集 24
4.2 模型的验证 25
4.3 数据分析 27
4.3.1 商家订餐量 27
4.3.2 订餐用户分析 27
4.3.3 发现外卖餐馆的核心用户 27
4.3.4 进行商圈竞争对手的分析 27
4.3.5用户评价文本分析 28
4.3.6订餐时间分析 29
4.3.7百度外卖数据价值 29
总结 30
参考文献 31
致谢 32
















 417
417











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











