







项目简介
本项目构建了一个基础的花卉分类识别系统,使用ResNet作为主干网络,旨在能够有效地区分10种不同类别的花卉。该项目不仅包括了模型训练和测试的过程,还提供了线上部署的解决方案,以确保其可以在实际应用中被广泛使用。项目简介
本项目为一个基础的花卉分类识别系统,采用 ResNet作为主干网络,包含模型的训练、测试以及线上部署(提供容器化部署)。

-
List item
-
基于 PyTorch 框架进行模型的训练及测试。
-
模型采用 ONNX 格式部署,采用 ONNX Runtime 进行推理。
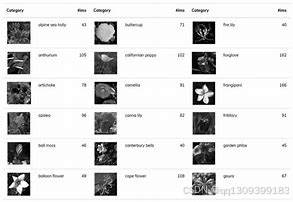
-
基于 Flask 框架实现 Web 接口。
-
使用 Docker 进行容器化部署。
-
训练数据集来自融合了多个数据集并进行了数据清洗,基于预训练模型进行训练,在当前数据集下
准确率超过98%。
技术栈
- 深度学习框架:PyTorch
- 推理引擎:ONNX Runtime
- Web接口实现:Flask框架
- 容器化部署:Docker
数据集与预处理
训练数据集来源,包含了多个公开可用的数据集。为了提高模型的质量和泛化能力,我们对原始数据进行了清洗,移除了不清晰或不符合标准的图片,并对图像进行了标准化处理。此外,为了增加数据的多样性,我们还实施了一系列的数据增强技术,例如随机裁剪、水平翻转、颜色抖动等。这些措施有助于模型在面对各种实际情况时保持较高的准确率。
模型选择与训练
基于ResNet架构,我们的模型首先利用ImageNet上的预训练权重进行了初始化,然后针对花卉分类任务进行了微调。这不仅加快了训练速度,也提高了模型性能。在训练过程中,我们设置了多种超参数,如学习率、批大小、迭代次数等,并通过交叉验证来找到最佳配置。最终,在当前数据集下,模型达到了超过98%的准确率。

使用说明
环境搭建
要运行此项目,您需要安装一系列依赖包。对于推理部署环境,可以通过pip安装以下依赖:
# 推理部署环境依赖
opencv-python~=4.10.0.84
numpy~=1.23.4
Flask~=3.0.3
PyYAML~=6.0
onnxruntime~=1.14.1
如果您计划进行模型训练,则还需要额外安装一些库:
# 训练环境依赖
torch~=2.4.0
torchvision~=0.19.0
onnx~=1.16.2
请注意,使用pip安装opencv-python可能会导致某些依赖缺失的问题;建议使用系统的包管理器(如apt-get或yum)来进行安装。
启动Web服务
项目的默认配置文件位于configs/deploy.yaml,其中定义了诸如推理精度、会话提供者以及花卉名称列表等关键设置。将训练好的模型权重文件放置于inferences/models/目录后,可以通过以下命令启动Web服务:
flask --app inferences.server run --host="0.0.0.0" --port=9500
该Web服务提供了一个简单的API接口,用于接收待识别的花卉图像并返回预测结果。请求方式为POST,携带表单数据格式的图像文件。服务器将以JSON格式响应,包含预测的花卉名称及其置信度得分。
模型训练与评估
如果用户想要使用自己的数据集来训练模型,首先需要准备数据集并调整好模型输出格式。接下来,根据需求修改configs/train.yaml中的参数,比如设备类型、迭代次数、学习率等,之后运行train.py即可开始训练过程。
训练完成后,可以运行eval.py脚本来评估模型在测试集上的表现。默认情况下,评估使用的配置文件为configs/eval.yaml,其中指定了待评估模型路径、批大小等相关信息。
模型推理部署
为了便于部署,我们需要将训练好的PyTorch模型转换成ONNX格式。这一过程相对简单,只需按照官方文档指导操作即可。对于容器化部署,可以利用提供的Dockerfile文件构建镜像,并创建一个容器来运行Web服务:
# 构建镜像
cd FlowerClassify
docker build -t flowerclassify:1.3.0 -f docker/Dockerfile .
# 创建容器并运行
docker run --rm -p 9500:9500 --name flowerclassify flowerclassify:1.3.0
上述步骤仅为示例,具体命令可能因版本更新而有所变化,请参考最新的Docker文档获取最准确的信息。
总结
综上所述,本项目提供了一套完整的解决方案,从模型训练到部署上线,涵盖了所有必要的环节。通过采用先进的深度学习技术和高效的部署策略,我们实现了对10种花卉的有效分类识别。未来的工作方向可以考虑进一步优化模型结构、探索更多的数据增强方法,以及尝试其他类型的神经网络,以期达到更高的识别精度和更广泛的应用范围。同时,随着更多高质量数据的积累和技术的发展,相信这个花卉分类识别系统将会变得越来越强大。


















 1366
1366

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









