










声明:文章是从本人公众号中复制而来,因此,想最新最快了解各类智能优化算法及其改进的朋友,可关注我的公众号:强盛机器学习,不定期会有很多免费代码分享~
目录
5.利用24年最新的黑翅鸢优化算法BKA实现超参数自动优化:
今天为大家带来一期黑翅鸢算法BKA优化BiTCN-BiGRU-Attention代码,知网和WOS都是搜不到的!完全是作者独家创立的!并且,提供了与未优化的模型对比,可以说是尚未发表的创新点!直接替换Excel数据即可用!
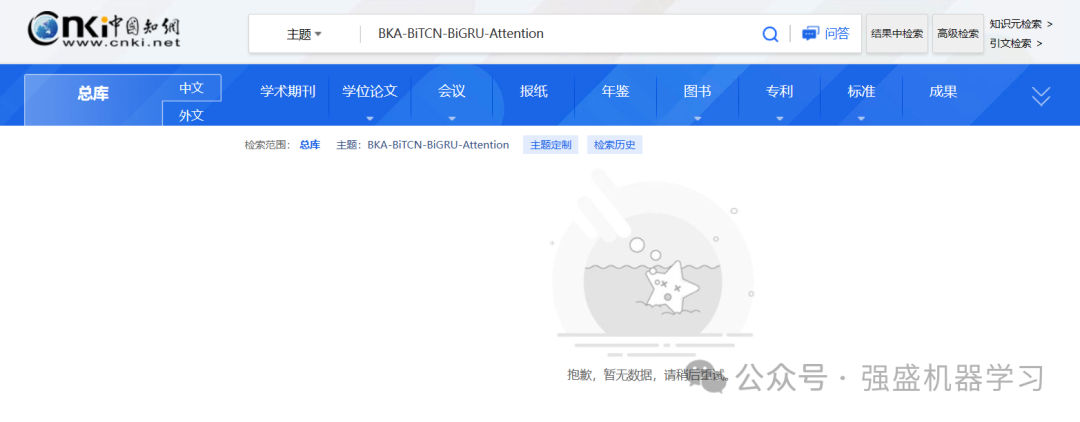
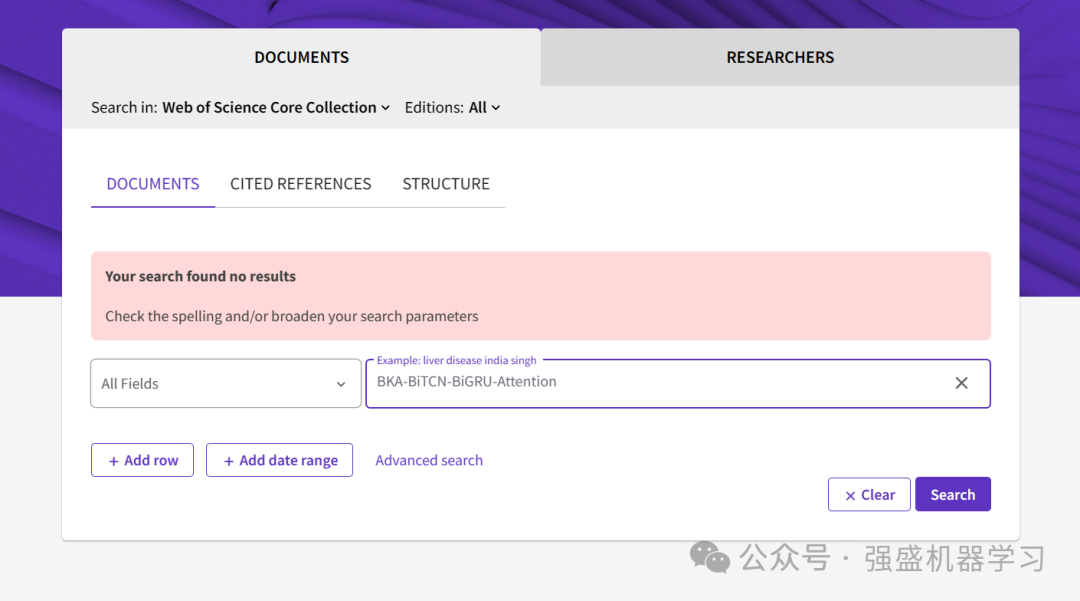
特别需要指出的是,我们在各个学术平台上搜索BKA-BiTCN-BiGRU-Attention,都是完全搜索不到这个模型的!!!不信的可以看下面截图!
知网平台:
WOS平台:
数据介绍
本期采用的数据是经典的多变量时间序列预测数据集,是为了方便大家替换自己的数据集,各个变量采用特征1、特征2…表示,无实际含义,最后一列即为输出。
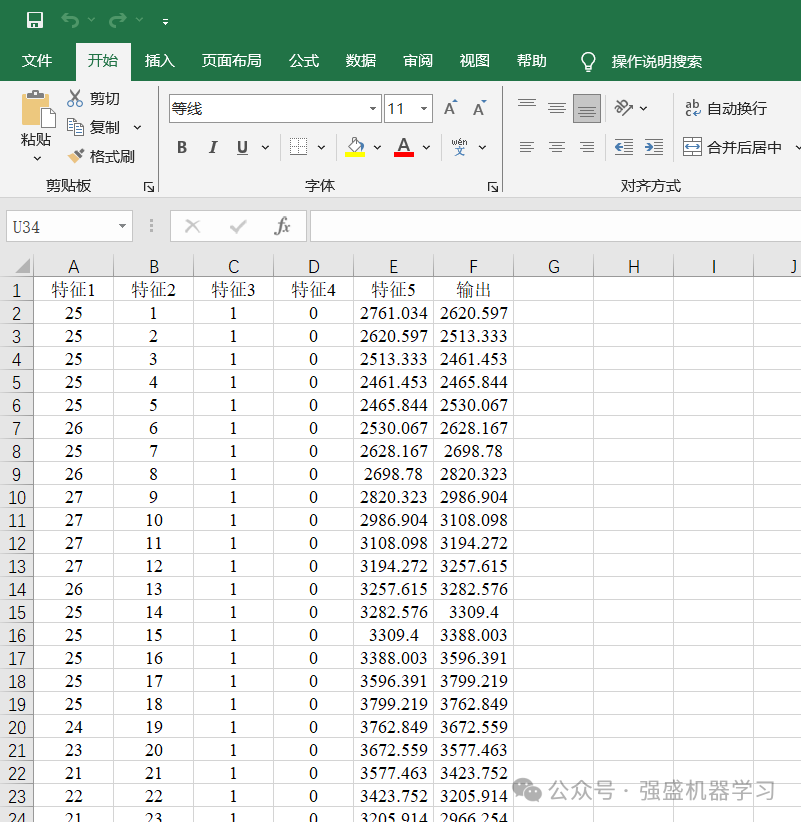
更换自己的数据时,只需最后一列放想要预测的列,其余列放特征即可,无需更改代码,非常方便!
模型介绍
1.BiTCN层
TCN由具有相同输入和输出长度的扩张因果卷积层组成,结合了CNN和RNN的优势。因果卷积的示意图如下图所示:
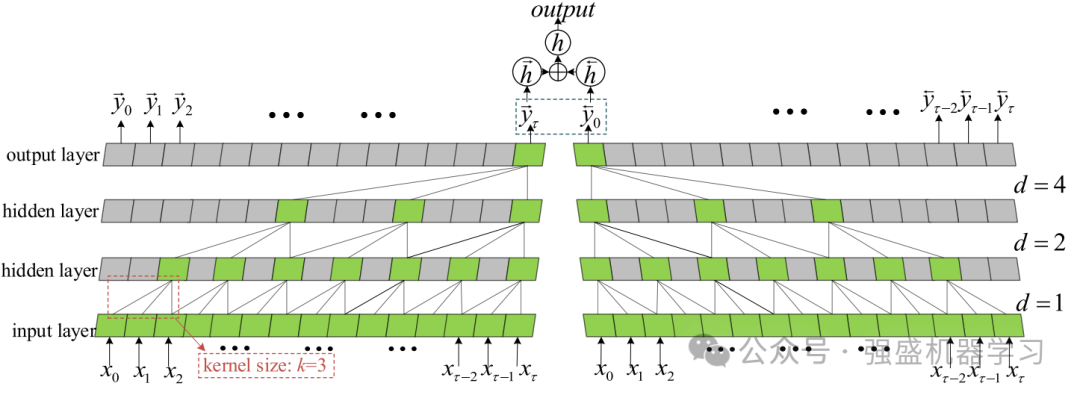
然而,传统的TCN只对输入序列进行正向卷积计算,只提取正向数据特征,忽略了反向中的隐含信息。在输入序列的每一层卷积之后,扩张因子呈指数增长。经过几次卷积,BiTCN获得了更大的接受域。BiTCN接受域的增加带来了梯度消失和收敛缓慢等问题。残差块的引入可以避免这些问题,同时实现对序列的高效特征提取。剩余块如图3所示。因此,采用双向时间卷积结构BiTCN来捕捉前后方向的隐藏特征,以更好地获得序列的长时间依赖性!BiTCN的网络结构如下图所示!非常新颖!
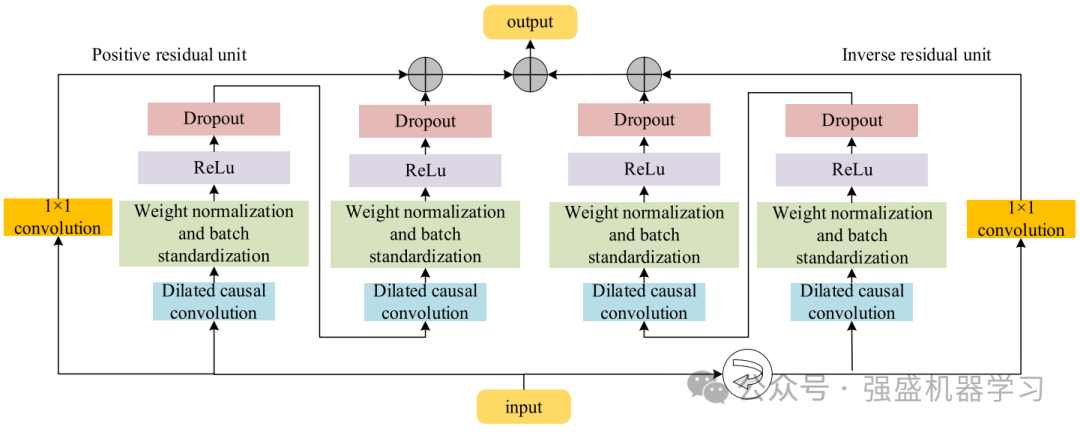
2.BiGRU层
接着,利用BiGRU层来进一步处理BiTCN的输出,通过考虑的前后文信息来提高预测的准确性,进一步提高预测精度!BiGRU通过结合正向和反向两个GRU,增强了模型的记忆能力,使其能够从两个方向学习数据的动态变化。与LSTM相比,GRU结构更简单,参数更少,能够以较低的计算成本实现强大的序列建模能力。
3.Attention机制
本文的注意力机制连接在了BiTCN-BiGRU层的后面,为自注意力机制,具体连接方式可以看后文的网络结构!注意力机制能使模型能够聚焦于序列中最重要的部分,即使在处理长序列时也不会丢失重要信息,这对于提高模型的解释性和性能都有重要意义。通过权重分配,注意力层能够加强模型内部特征之间的相互作用,使得模型能够学习到更加复杂和抽象的特征表示。
4.整体模型结构
以下图片,代码均可以一键运行出图!
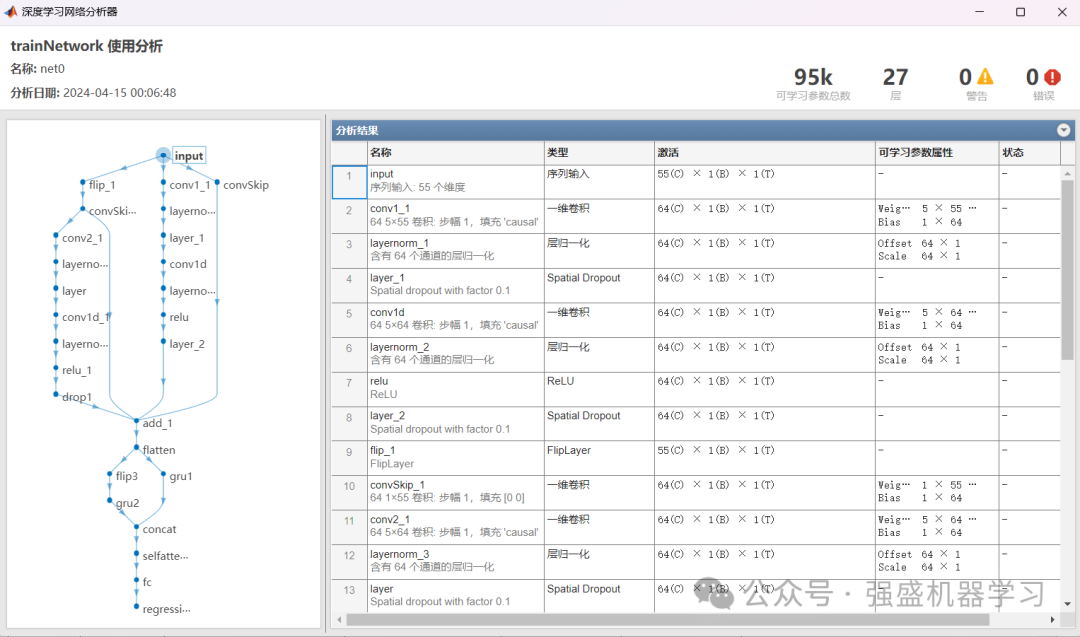
模型流程
最后再介绍一下我们的这个模型是怎么实现的以及它的流程:
1.数据导入:从Excel文件中读取数据,设定最后一列为输出变量,其余列作为特征变量。
2.训练集与测试集划分:按比例划分训练集和测试集。
3.数据归一化:对训练集和测试集的特征和标签进行归一化处理,以提高模型训练效率。
4.建立原始模型:设计未经优化的BiTCN-BiGRU-Attention网络,并保存相应预测结果。
5.优化算法确定超参数:使用黑翅鸢优化算法(BKA)确定BiTCN-BiGRU-Attention模型的最优参数,包括学习率,BiGRU的神经元个数,注意力机制的键值,正则化参数。
6.参数回带:将得到的最优参数回带入BiTCN-BiGRU-Attention中,形成BKA-BiTCN-BiGRU-Attention,即优化后的BiTCN-BiGRU-Attention模型。
7.模型预测:利用训练好的模型对训练集和测试集进行预测,然后对预测结果进行反归一化。
8.性能评估:通过绘制真实值与预测值的对比图、雷达图、柱状图、二维图等,并计算R^2、MAE、RMSE和MAPE等指标,评估模型性能。
创新点
以下这些文字,如果大家需要用这个程序写论文,都是可以直接搬运的!
1. 综合双向时序特征提取
BiTCN组件通过融合正向和反向的时序卷积网络,有效捕获了数据的前后文信息,提供了一种深度且广泛的特征提取方式。不同膨胀因子的使用使得模型能在多个时间尺度上提取特征,这种综合双向和多尺度特征提取的方法在预测中是非常创新的,能够显著提高对复杂模式的识别能力。
2. 强化长短期记忆处理能力
通过将BiGRU集成到模型中,该模型不仅保留了GRU在处理长短期依赖方面的优势,还通过双向处理机制增强了对数据前后文信息的理解。这种结合了双向处理和门控机制的设计,进一步强化了模型处理复杂时间依赖关系的能力。
3. 引入自适应注意力机制
模型通过引入注意力机制,自适应地关注对当前任务最重要的特征,这不仅提高了模型的准确性,还增加了模型对其决策过程的解释性。在BiTCN和BiGRU的基础上加入注意力机制,确保了模型能够在复杂的数据中识别并聚焦于关键信息,是一大创新点。
4. 模型结构的高度整合
该模型的一个关键创新是三种技术的高度整合,形成了一个既能捕捉复杂时间依赖性、又能关注关键信息的强大网络。这种整合不仅使模型在预测和分类任务中表现出色,还保证了较低的计算成本和良好的可解释性。
5.利用24年最新的黑翅鸢优化算法BKA实现超参数自动优化:
黑翅鸢优化算法(Black‑winged kite algorithm, BKA)于2024年3月发表在中科院1区Top SCI期刊《Artificial Intelligence Review》上,该算法刚刚提出,提出时间极短,目前还没有使用该算法的文献,你先用,你就是创新!

BKA算法灵感来源于黑翅鸢迁徙和捕食行为,BKA以其优异的性能证明了其在大部分CEC-2022和CEC-2017测试函数都能够获得最佳性能!
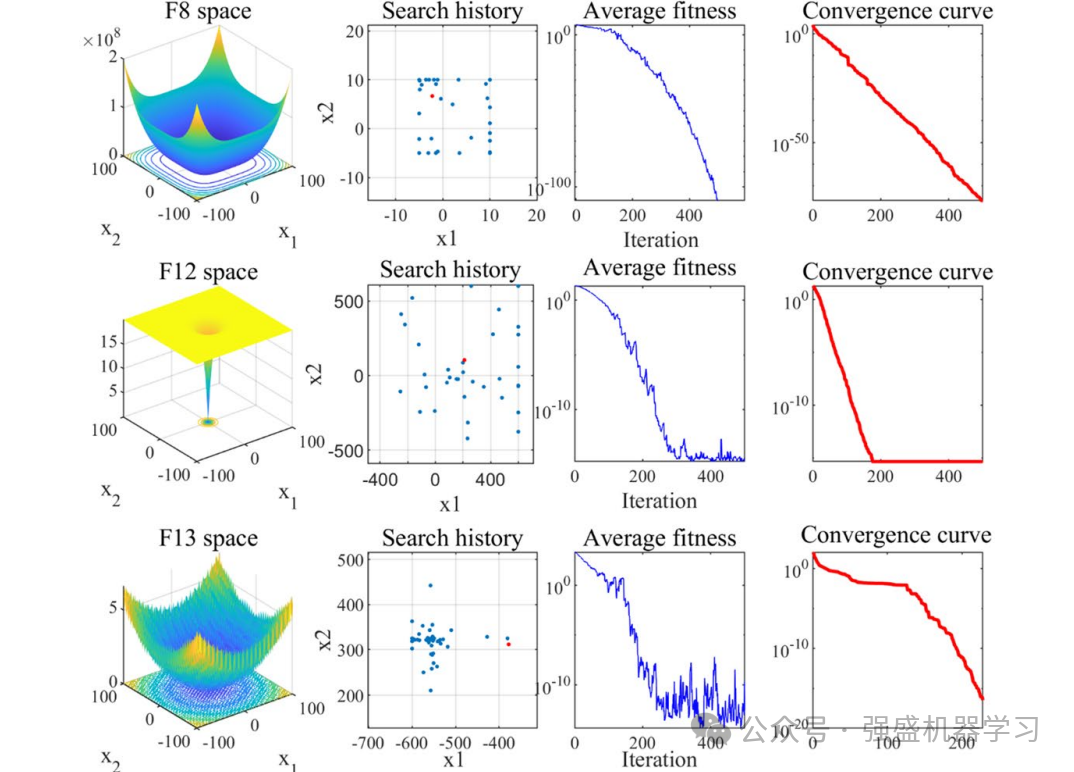
具体原理和测试效果请看这篇推文:
2024年SCI一区新算法-黑翅鸢优化算法(BKA)-公式原理详解与性能测评 Matlab代码免费获取
结果展示
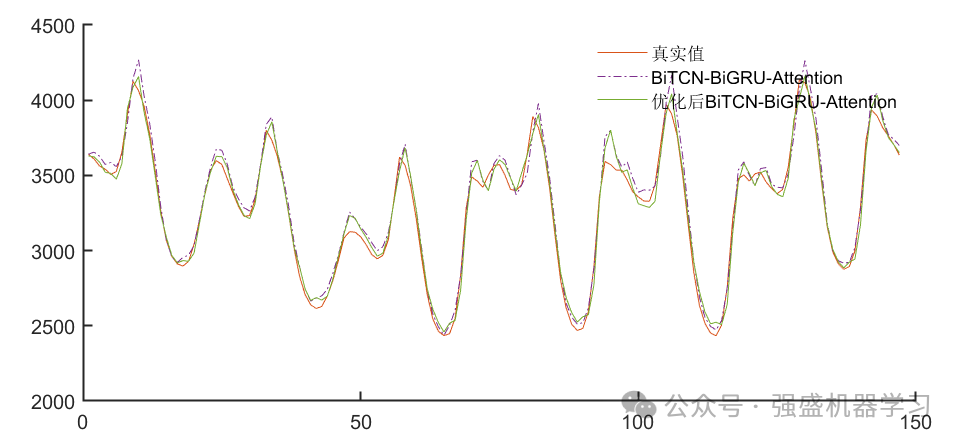

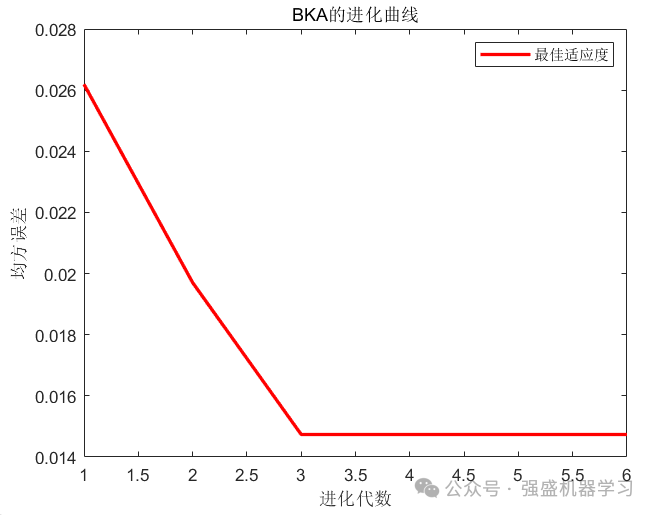
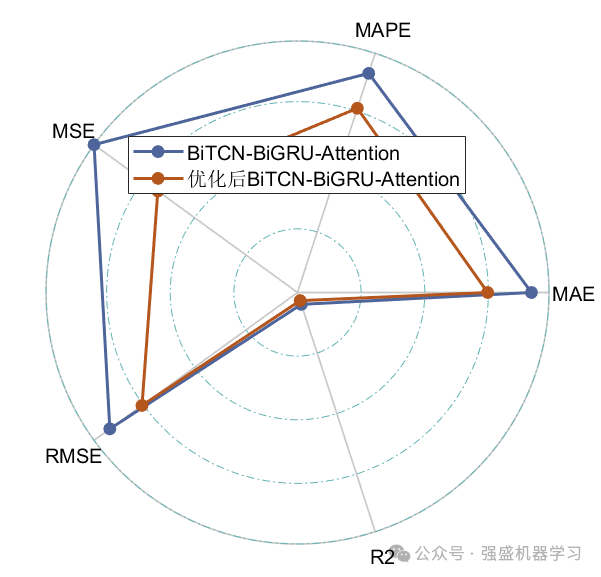

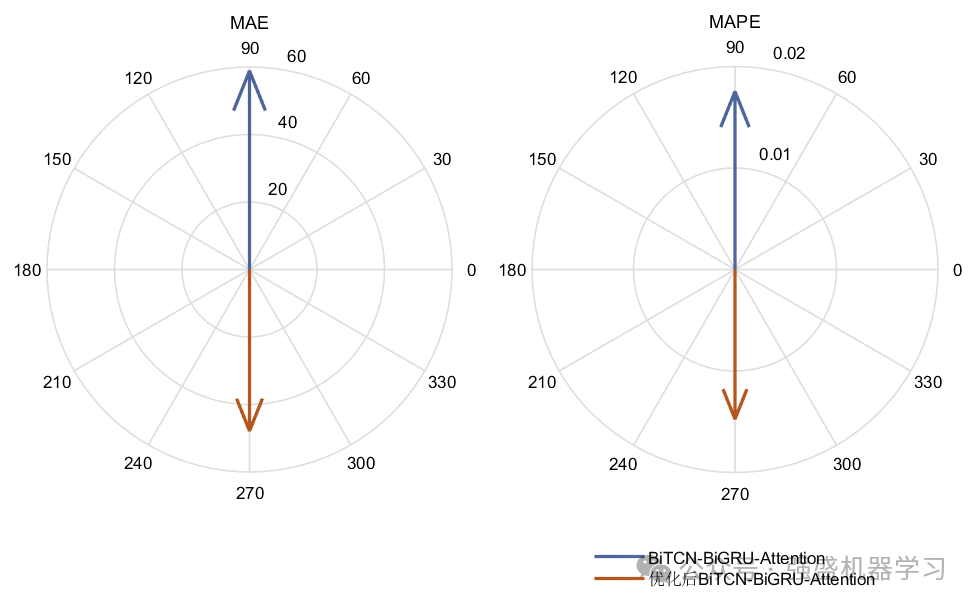

可以看到,优化后的BiTCN-BiGRU-Attention模型精度有了很大的提高,误差明显减小!出的图片也非常美观!需要注意的是,因为MAPE是百分制的,所以值非常小,因此相比于MAE、RMSE指标其值过小而看不出,这是非常正常的!
另外,如果想要预测精度更好,可以增大迭代次数,作者这里因为时间关系只设置了6次,大家在时间充足的情况下迭代10次甚至20次都是可以的!
以上所有图片,作者都已精心整理过代码,都可以一键运行main直接出图,不像其他代码一样需要每个文件运行很多次!
适用平台:Matlab2023及以上,没有的文件夹里已经免费提供安装包,直接下载即可!
部分代码
%% 导入数据
result = xlsread('数据集.xlsx');
%% 数据分析
num_samples = length(result); % 样本个数
kim = 3; % 延时步长(前面多行历史数据作为自变量)
zim = 1; % 跨zim个时间点进行预测
nim = size(result, 2); % 原始数据的特征是数目
%% 划分数据集
for i = 1: num_samples - kim - zim + 1
res(i, :) = [reshape(result(i: i + kim - 1 , :), 1, kim * nim), result(i + kim + zim - 1, :)];
end
%% 数据集分析
outdim = 1; % 最后一列为输出
num_size = 0.9; % 训练集占数据集比例
num_train_s = round(num_size * num_samples); % 训练集样本个数
f_ = size(res, 2) - outdim; % 输入特征长度
%% 划分训练集和测试集
P_train = res(1: num_train_s, 1: f_)';
T_train = res(1: num_train_s, f_ + 1: end)';
M = size(P_train, 2);
P_test = res(num_train_s + 1: end, 1: f_)';
T_test = res(num_train_s + 1: end, f_ + 1: end)';
N = size(P_test, 2);
%% 数据归一化
[p_train, ps_input] = mapminmax(P_train, 0, 1);
p_test = mapminmax('apply', P_test, ps_input);
[t_train, ps_output] = mapminmax(T_train, 0, 1);
t_test = mapminmax('apply', T_test, ps_output);
%% 格式转换
for i = 1 : M
vp_train{i, 1} = p_train(:, i);
vt_train{i, 1} = t_train(:, i);
end
for i = 1 : N
vp_test{i, 1} = p_test(:, i);
vt_test{i, 1} = t_test(:, i);
end
disp('此程序运行较慢,请耐心等待!')
%% 优化算法优化前,构建优化前的BiTCN-BiGRU-Attention模型
numFilters = 64;
filterSize = 5;
dropoutFactor = 0.1;
numBlocks = 1;完整代码
点击下方小卡片,后台回复关键字,不区分大小写:
CXYHF
其他更多需求或想要的代码均可点击下方小卡片后后台私信,看到后会秒回~
更多代码链接:更多代码链接















 414
414

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









