







声明:文章是从本人公众号中复制而来,因此,想最新最快了解各类智能优化算法及其改进的朋友,可关注我的公众号:强盛机器学习,不定期会有很多免费代码分享~
目录
梦境优化算法(Dream Optimization Algorithm, DOA)是一种新型的元启发式算法(智能优化算法),灵感来源于人类梦境的启发。该算法结合了一个基本的记忆策略,一个遗忘和补充策略,以平衡探索和利用,值得一试!该成果由Yifan Lang于2025年3月发表在SCI一区Top期刊《Computer Methods in Applied Mechanics and Engineering》上!

由于发表时间较短,谷歌学术上还没人引用!你先用,你就是创新!

原理简介
灵感:在有做梦经历的快速眼动睡眠期间,低频脑电波的功率降低,而高频脑电波的功率增加,这表明在做梦经历期间大脑的神经兴奋更大
一、初始化
与其他MAs类似,在初始化阶段,DOA首先在搜索空间内生成一个随机种群作为初始种群,从而开始算法的优化过程。初始总体的计算公式如下:
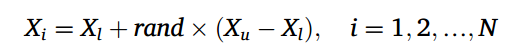
式中,N为个体数,即种群大小;Xi是种群中的第i个个体;Xl和Xu分别表示搜索空间的下边界和上边界;rand是一个dim维向量,每个维度是0到1之间的随机数。
二、勘探阶段
在勘探阶段(迭代计数从0到Td),我们首先根据记忆能力的差异将群体分为5组,每组中的个体更新如下:将每次迭代视为一次做梦行为,通过不断执行该行为,寻求最优解和最优值。在每次做梦之前,每组中的所有人都被展示了之前最好的梦(即之前迭代中最好的个体)。由于个体在做梦时随机地忘记了部分信息(即某些维度的信息,称为遗忘维度),因此只有遗忘维度中的位置被更新。各组记忆能力的不同意味着遗忘维度的数量不同,用参数k1、k2、k3、k4、k5表示。因此,首先将每个个体的位置重置为之前迭代中该组中最佳个体的位置,然后从Dim维度中随机选择kq维度,记为K1,K2,…,Kkq,并更新这些维度中的位置,其中q = 1,2,3,4,5表示组号。在每次迭代中,从第1个个体到第n个个体依次执行更新。具体更新方法和公式如以下几个步骤。
2.1 记忆策略
对于q组的个体,他们可以在做梦前记住小组中最优秀个体的位置信息,将自己的位置信息重置为小组中最优秀个体的位置信息:
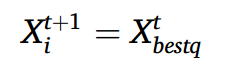
2.2 遗忘和补充策略
遗忘和补充策略结合了全局和局部搜索功能。该策略遵循记忆策略,允许个体在遗忘维度中遗忘和自我组织位置信息。更新公式如下:
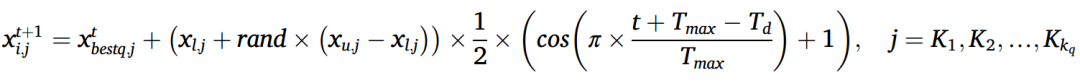
2.3 梦境分享策略
DOA中的梦境共享策略增强了局部最优解的逃逸能力。该策略与遗忘和补充策略并行运行,遵循记忆策略,允许个体在遗忘维度随机从其他个体获取位置信息。更新公式如下:
式中xt+1 i,j表示第i个个体在迭代t+1时在第j维的位置;m是每个维度更新在[1,N]范围内随机选择的自然数。
三、开发阶段
在开发阶段(从Td到Tmax的迭代计数),不再执行分组。在每次做梦之前,从之前的迭代中得到的最好的梦(即,从之前的迭代中得到的最好的个体)被展示给所有的人。然后,更新每个个体在遗忘维度中的位置。总体中所有个体具有相同数量的遗忘维度,记为kr。从D维度中随机选择kr遗忘维度,记为K1,K2,…,Kkr,并更新这些维度中的位置。更新公式如下:
3.1 记忆策略
其中Xt+ 1i代表第t+1次迭代时的第i个个体,Xt代表第t次迭代时整体中最优个体。
3.2 遗忘和补充策略
式中xt+1(i,j)表示第i个个体在迭代t+1时在第j维的位置;Xtbestj表示在迭代t代时的最佳位置。Xlj和xuj分别是第j维搜索空间的下界和上界;Rand是0到1之间的随机数;t为当前迭代次数,Tmax为算法的最大迭代次数。
四、参数设置
经过大量的数值实验,考虑到算法的稳定性和适用性,我们将DOA参数设置为:
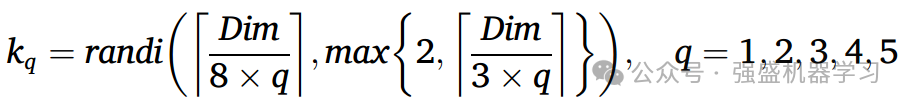
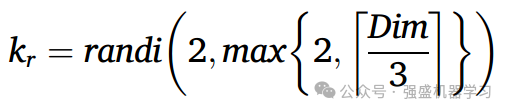
其中Td表示探索阶段的最大迭代次数,Tmax表示总最大迭代次数;randi(a, b)表示在a ~ b范围内选择的随机整数。kq表示探索阶段q组的遗忘维度数,Dim表示问题维度。式中,randi(a, b)表示在a ~ b范围内选择的随机整数。kr表示开发阶段遗忘维度的个数,Dim表示问题维度。参数u用于调整探索阶段遗忘补充策略与梦境分享策略之间的比例。当rand < u时,执行遗忘补充策略;否则,就执行梦境分享策略。设u = 0.9。
五、边界处理方法
对于不同维数的优化问题,我们采用了两种不同的边界条件处理方法。
第一种方法适用于Dim≤15的问题。由于这些问题的维数较小,局部最优值相对较少,因此采用传统的随机方法更新超出搜索边界的点,如下图所示:
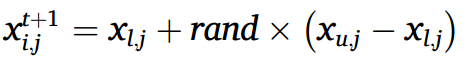
第二种方法是针对Dim>15的问题。这些问题的维度更大,更复杂,有更多的局部最优,需要增强全局优化能力和逃避局部最优的能力。因此,对于这类高维问题中超过边界条件的agent点,我们采用类似于开发阶段梦境共享策略的方法进行重新更新,如下所示:

式中xt+1(i,j)表示第i个个体在迭代t+1时在第j维的位置;m是一个在[1,N]范围内的随机自然数,每次更新时m与i不同。
算法伪代码
为了使大家更好地理解,这边给出作者算法的伪代码,非常清晰!

如果实在看不懂,不用担心,可以看下源代码,再结合上文公式理解就一目了然了!
性能测评
原文作者在CEC2017, CEC2019, CEC2022测试函数上进行定量分析,并应用在在8个工程约束优化问题和光伏电池模型参数优化中,将DOA与27种算法进行比较。结果表明,DOA算法在收敛性、先进性、稳定性、适应性、鲁棒性、显著性和可靠性等方面优于所有竞争对手。
这边为了方便大家对比与理解,采用23个标准测试函数,即CEC2005,设置种群数量为30,迭代次数为1000,和经典的正余弦优化算法SCA进行对比!这边展示其中5个测试函数的图,其余十几个测试函数大家可以自行切换尝试!
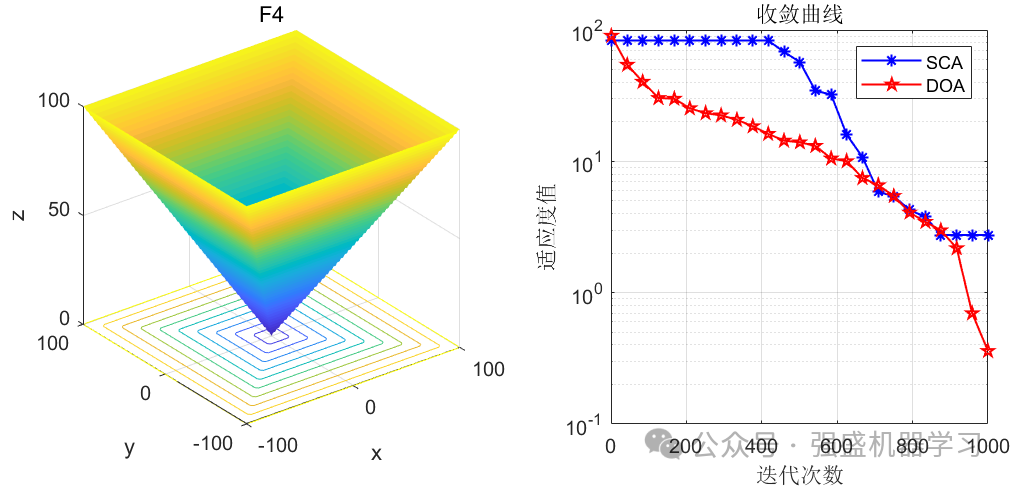
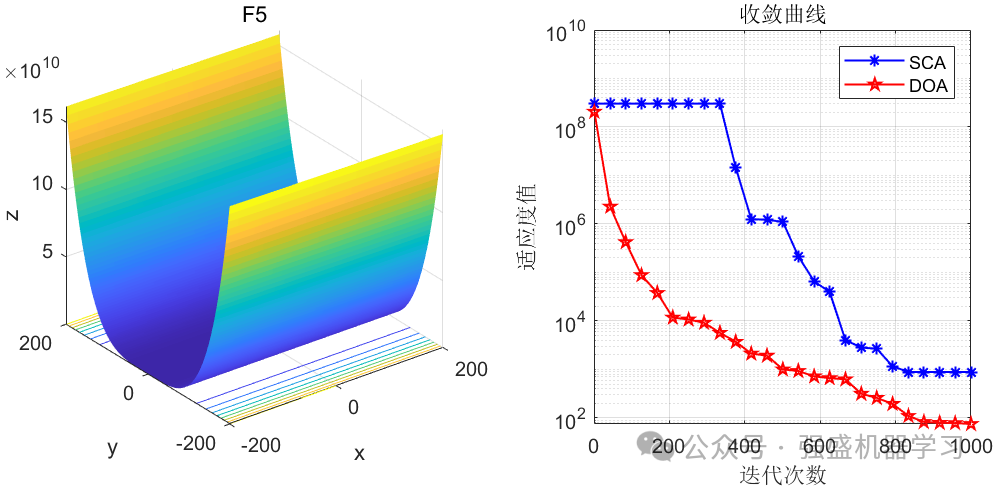
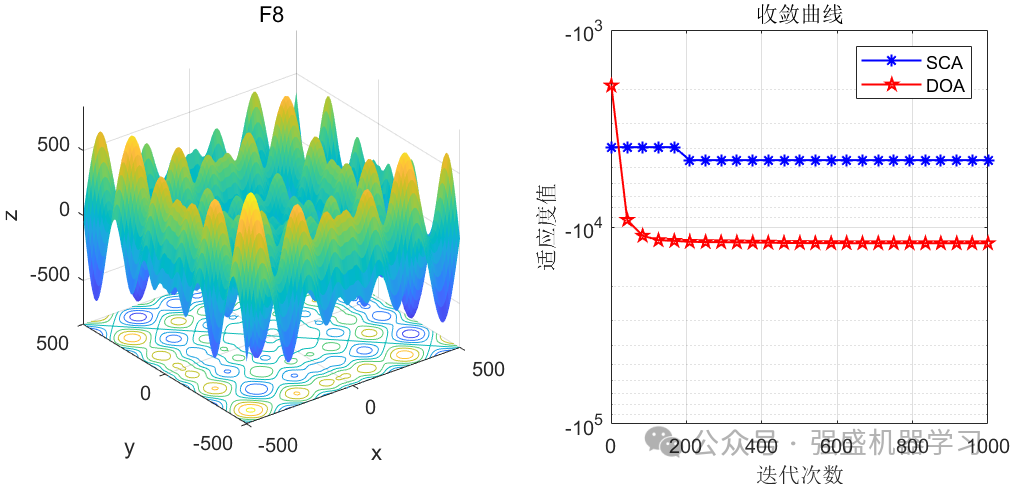
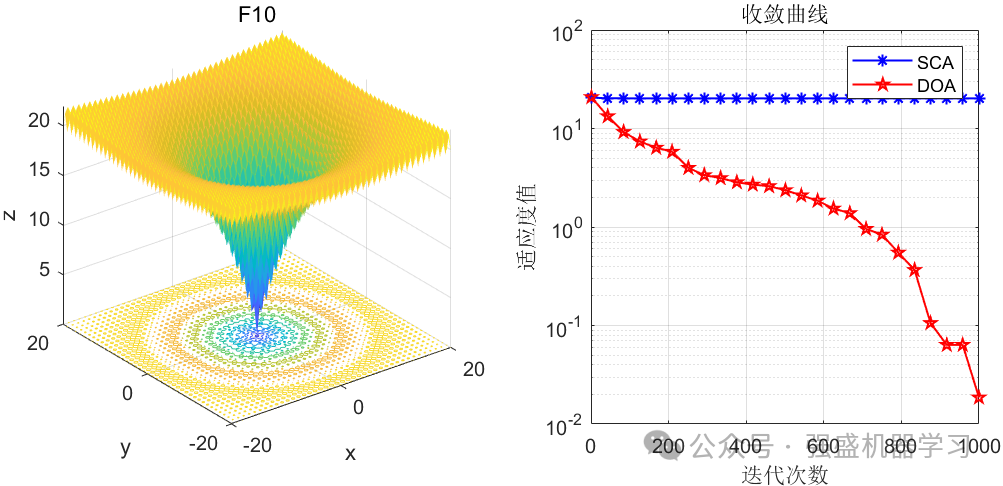
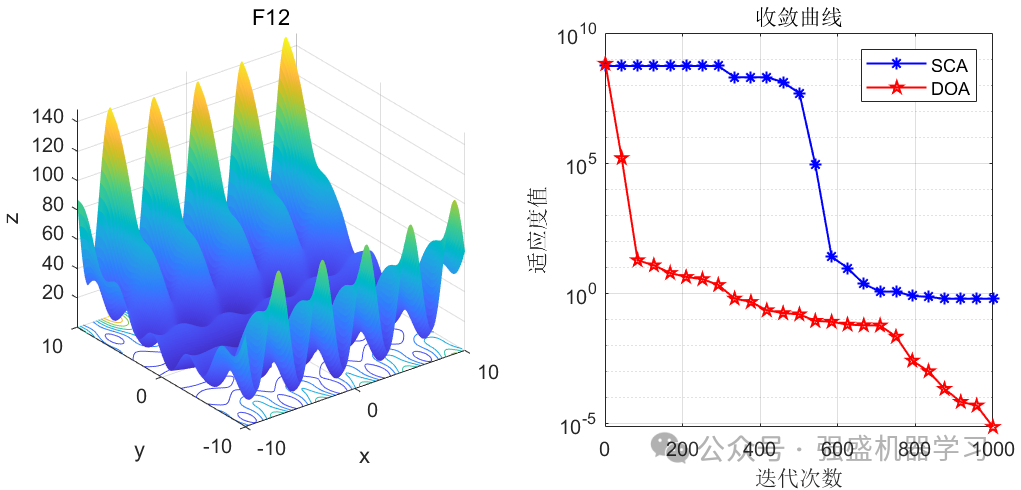
可以看到,这个算法在大部分函数上均优于经典的正余弦优化算法算法,说明该算法性能还是比较不错的!大家应用到各类预测、优化问题中也是一个不错的选择~
参考文献
[1]Lang Y, Gao Y. Dream Optimization Algorithm (DOA): A novel metaheuristic optimization algorithm inspired by human dreams and its applications to real-world engineering problems[J]. Computer Methods in Applied Mechanics and Engineering, 2025, 436: 117718.
完整代码
如果需要免费获得图中的完整测试代码,只需点击下方小卡片,再后台回复关键字,不区分大小写:
DOA
也可点击下方小卡片,再后台回复个人需求(比如DOA-Transformer)定制以下DOA算法优化模型(看到秒回):
1.回归/时序/分类预测类:SVM、RVM、LSSVM、ELM、KELM、HKELM、DELM、RELM、DHKELM、RF、SAE、LSTM、BiLSTM、GRU、BiGRU、PNN、CNN、BP、XGBoost、TCN、BiTCN、ESN、Transformer等等均可~
2.组合预测类:CNN/TCN/BiTCN/DBN/Transformer/Adaboost结合SVM、RVM、ELM、LSTM、BiLSTM、GRU、BiGRU、Attention机制类等均可(可任意搭配非常新颖)~
3.分解类:EMD、EEMD、VMD、REMD、FEEMD、TVFEMD、CEEMDAN、ICEEMDAN、SVMD、FMD等分解模型均可~
4.路径规划类:机器人路径规划、无人机三维路径规划、冷链物流路径优化、VRPTW路径优化等等~
5.优化类:光伏电池参数辨识优化、光伏MPPT控制、储能容量配置优化、微电网优化、PID参数整定优化、无线传感器覆盖优化、图像分割、故障诊断等等均可~~
6.原创改进优化算法(适合需要创新的同学):原创改进2025年的梦境优化算法SFOA以及班翠鸟PKO、蜣螂DBO等任意优化算法均可,保证测试函数效果,一般可直接核心!

















 801
801

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









