






B站UP:霹雳吧啦Wz
课程合集链接:1.1 卷积神经网络基础_哔哩哔哩_bilibili
代码参考B站UP:霹雳吧啦Wz的《深度学习-图像分类篇章》视频,代码根据个人编程习惯及本人自用数据集进行少量改动,欢迎大佬们批评指正。
1 网络结构

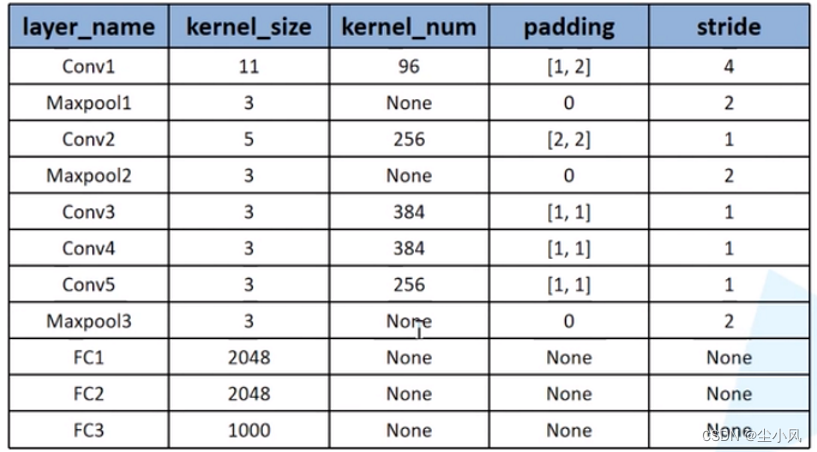
2 代码实现
2.1 模型构建
import torch
class Model(torch.nn.Module):
def __init__(self, num_classes): # 传入所需分类的类别数,也就是最后一个全连接层所需要输出的channel
super(Model, self).__init__()
# 用torch.nn.Sequential方法将网络打包成一个模块,精简代码,不需要每一步都写成self.conv1 = ...的格式了
self.features = torch.nn.Sequential( # 定义卷积层提取图像特征
# 计算output的size的计算公式:(input_size-kernel_size+padding)/stride + 1
torch.nn.Conv2d(3, 48, kernel_size=11, padding=2, stride=4), # input(3, 244, 244) output(48, 55, 55)
torch.nn.ReLU(inplace=True), # 直接修改覆盖原值,节省运算内存
torch.nn.MaxPool2d(kernel_size=3, padding=0, stride=2), # input(48, 55, 55) output(48, 27, 27)
torch.nn.Conv2d(48, 128, kernel_size=5, padding=2, stride=1), # input(48, 27, 27) output(128, 27, 27)
torch.nn.ReLU(inplace=True),
torch.nn.MaxPool2d(kernel_size=3, padding=0, stride=2), # input(128, 27, 27) output(128, 13, 13)
torch.nn.Conv2d(128, 192, kernel_size=3, padding=1, stride=1), # input(128, 13, 13) output(192, 13, 13)
torch.nn.ReLU(inplace=True),
torch.nn.Conv2d(192, 192, kernel_size=3, padding=1, stride=1), # input(192, 13, 13) output(192, 13, 13)
torch.nn.ReLU(inplace=True),
torch.nn.Conv2d(192, 128, kernel_size=3, padding=1, stride=1), # input(192, 13, 13) output(128, 13, 13)
torch.nn.ReLU(inplace=True),
torch.nn.MaxPool2d(kernel_size=3, padding=0, stride=2), # input(128, 13, 13) output(128, 6, 6)
)
self.classifier = torch.nn.Sequential(
# 定义全连接层图像分类
# dropout随机失活神经元,默认比例0.5,一般加在全连接层防止过拟合 提升模型泛化能力。卷积层一般很少加,因为卷积参数少,不易过拟合
torch.nn.Dropout(0.5),
torch.nn.Linear(128*6*6, 2048) ,
torch.nn.ReLU(inplace=True),
torch.nn.Dropout(0.5),
torch.nn.Linear(2048, 2048),
torch.nn.ReLU(inplace=True),
torch.nn.Dropout(0.5),
torch.nn.Linear(2048, num_classes),
)
def forward(self, x):
x = self.features(x)
x = torch.flatten(x, start_dim=1) # (batch_size, c , H, W)即从通道c开始对x进行展平
x = self.classifier(x)
return x2.2 模型训练
import torch
import numpy as np
import matplotlib.pyplot as plt
from torchvision import transforms
from torchvision import datasets
from torch.utils.data import DataLoader
from Alexnet_model import Model
import json
import os
import time
# 数据预处理
# 对训练集的预处理多了随机裁剪和水平翻转这两个步骤,可以起到扩充数据集的作用,增强模型泛化能力
# 详细解释见:https://blog.csdn.net/see_you_yu/article/details/106722787
batch_size = 64
transform = {
"train":transforms.Compose([transforms.RandomResizedCrop(224), # 对图像进行随机裁剪,之后缩放得到指定大小的尺寸
transforms.RandomHorizontalFlip(p=0.5), # 按照指定概率对图像进行水平翻转
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]),
"test":transforms.Compose([transforms.Resize((224, 224)), # 将图片变成指定大小,如果Resize(224)意思是将图片短边变成224,长边跟着短边进行缩放,缩放后图片的长宽比相较于原图不变
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
}
# 导入、加载训练集
# 获取图像数据集的路径
# data_root = os.path.abspath(os.path.join(os.getcwd(), "../.."))
'''
os.getcwd()作用是:获取当前这个py文件的工作路径字符串;
os.path.join作用是:将前后的路径字符串连接起来,并用正确格式的路径分隔符
这里../代表返回上一层目录,../..即代表返回上上层目录,由于教学视频当中Alexnet_model.py文件的上上层目录和dataset文件夹同级目录,所以要返回上上级目录,
但是在我使用时候,Alexnet_model的上级目录和dataset文件夹同级,所以只需要取../
os.path.abspath作用是:取绝对目录
'''
data_root = os.path.abspath(os.path.join(os.getcwd(), "../"))
image_path = data_root + "/dataset/flower_data/"
# 导入训练集并进行预处理
train_dataset = datasets.ImageFolder(root=image_path + "/train", transform=transform["train"])
train_num = len(train_dataset)
# 按batch_size分批次加载训练集
train_loader = DataLoader(dataset=train_dataset, batch_size=batch_size, shuffle=True)
# 导入测试集并进行预处理
test_dataset = datasets.ImageFolder(root=image_path + "/test", transform=transform["test"])
test_num = len(test_dataset)
# 加载验证集
test_loader = torch.utils.data.DataLoader(dataset=test_dataset, batch_size=batch_size, shuffle=True)
# 存储 索引:标签 的字典
# 为了方便在predict时读取信息,将 索引:标签 存入到一个json文件中
# 字典,类别:索引 {'daisy':0, 'dandelion':1, 'roses':2, 'sunflower':3, 'tulips':4}
flower_list = train_dataset.class_to_idx
# 将 flower_list 中的 key 和 index 调换位置
cla_dict = dict((index, key) for key, index in flower_list.items())
# 将 cla_dict 写入 json 文件中
json_str = json.dumps(cla_dict, indent=4) # 把python对象转换成json对象
with open('class_indices.json', 'w') as json_file:
json_file.write(json_str) # 把结果写入名为class_indices.json的json文件
model = Model(num_classes=5)
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.002)
# 训练过程
'''
训练过程中需要注意:
model.eval():不启用BatchNormalization和Dropout。此时pytorch会自动把BN和Dropout固定住,不会取平均,而是用训练好的值。不然的话,一旦test的batch_size过小,很容易就会因BN层导致模型performance损失较大;
model.train():启用BatchNormalization和Dropout。在模型测试阶段使用model.train() 让model变成训练模式,此时 dropout和batch normalization的操作在训练中起到防止网络过拟合的问题。
因此,在使用PyTorch进行训练和测试时一定要记得把实例化的model指定train/eval。
'''
loss_list = []
accuracy_list = []
best_acc = 0
for epoch in range(10):
model.train()
loss_sum = 0
time_start = time.perf_counter() # 对训练的每一个epoch计时
for i, (inputs, targets) in enumerate(train_loader):
outputs = model(inputs)
loss = criterion(outputs, targets)
loss_list.append(loss.item())
loss_sum += loss.item()
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 打印训练进度
rate = (i+1)/len(train_loader)
a = "*" * int(rate * 50)
b = "-" * int((1-rate) * 50)
print("\rtrain loss:{:.3f}%[{}->{}]{:.3f}".format(int(rate*100), a, b, loss), end="")
print()
print("%f s" % (time.perf_counter()-time_start) )
########################### 测试过程 ########################
model.eval()
total = 0
correct = 0
with torch.no_grad():
for (images, labels) in test_loader:
y_pred = model(images)
# predicted的输出其实是总样本数/batch_size个tensor,每个tensor里面是1*64(batch_size)的数组,64个样本每个样本对应一个数字,等于是从outputs的每个样本的1*5(类别数)的数组中找到最大值,返回的数字就是这个最大值的下标
_, predicted = torch.max(y_pred.data, dim=1) # dim = 1 列是第0个维度,行是第1个维度
total += labels.size(0) # 取labels.size的第0个元素,即batch_size
correct += (predicted == labels).sum().item()
# 保存准确率最高的那次网络参数
if correct/total > best_acc:
best_acc = correct/total
torch.save(model.state_dict(), "Alexnet.pth")
accuracy_list.append(correct/total)
print("[epoch %d] train_loss:%.3f test_accuracy:%.3f" % (epoch+1, loss_sum/(i+1), correct/total) )
print("Finished Training")
plt.subplot(121)
plt.plot(range(len(loss_list)), loss_list)
plt.xlabel("step")
plt.ylabel("loss")
plt.subplot(122)
plt.plot(range(epoch+1), accuracy_list)
plt.xlabel("epoch")
plt.ylabel("accuracy")
plt.show()2.3 模型预测
import torch
from Alexnet_model import Model
from PIL import Image
from torchvision import transforms
import matplotlib.pyplot as plt
import json
# 预处理
transform = transforms.Compose(
[transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
# 导入要测试的图像(自己找的,不在数据集中),放在源文件目录下
img = Image.open("玫瑰.jpg")
plt.imshow(img) # 通过PIL或者numpy导入的图片格式一般都是[H, W, C](高度、宽度、通道)
img = transform(img) # 通过transform转换成[C, H, W]
# 对数据增加一个维数为1的新维度,因为tensor的参数是[batch, channel, height, width]
img = torch.unsqueeze(img, dim=0)
try:
json_file = open('./class_indices.json', 'r')
class_indict = json.load(json_file)
except Exception as e:
print(e)
exit(-1)
# create model
model = Model(num_classes=5)
# 加载训练好的权重文件
model.load_state_dict(torch.load("Alexnet.pth"))
# 关闭 Dropout
model.eval()
with torch.no_grad():
# 预测分类
#output = torch.squeeze(model(img))
# 将输出压缩,即压缩掉 batch 这个维度
# 如果这样去做,print(predict)输出的就是一个一维数组的tensorflow,所以后面的dim=1应该改成dim=0
# 最后输出的predict[0][predict_cla].item()直接写成predict[predict_cla].item()就行
output = model(img)
predict = torch.softmax(output, dim=1)
print(predict)
predict_cla = torch.argmax(predict).numpy() # argmax返回最大值的索引
print(predict_cla)
print(class_indict[str(predict_cla)], predict[0][predict_cla].item()) # 通过输出的predict我们可以看出predict是一个二维数组形式的tensor,所以需要写成predict[0][predict_cla]
plt.show()













 1150
1150











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









