






基于麻雀搜索算法优化XGBoost(SSA-xgboost)的数据分类预测
优化参数为迭代次数、最大深度和学习率
利用交叉验证抑制过拟合问题
matlab代码,

基于麻雀搜索算法优化XGBoost(SSA-xgboost)的数据分类预测
摘要:数据分类预测是机器学习领域的关键问题之一,针对传统XGBoost算法在优化参数方面存在的一些问题,本文提出了基于麻雀搜索算法优化XGBoost的方法(SSA-xgboost)。通过对迭代次数、最大深度和学习率等参数进行优化,提高了XGBoost在数据分类预测中的准确性和性能。同时,借助交叉验证技术,有效抑制了过拟合问题。本文以matlab代码作为实现工具,并提供了简洁的代码示例。
1. 引言
随着大数据时代的到来,数据分类预测成为了解决实际问题的重要手段之一。XGBoost作为一种集成学习算法,具有很高的性能和准确性,已经被广泛应用于各个领域。然而,传统的XGBoost算法在参数优化方面存在一些问题,如需要手动设置迭代次数、最大深度和学习率等。这些参数设置不合理可能导致算法的性能下降,降低了分类预测的准确性。为了解决这些问题,本文提出了基于麻雀搜索算法优化XGBoost的方法(SSA-xgboost),通过优化上述参数,提高XGBoost算法在数据分类预测中的性能。
2. 麻雀搜索算法
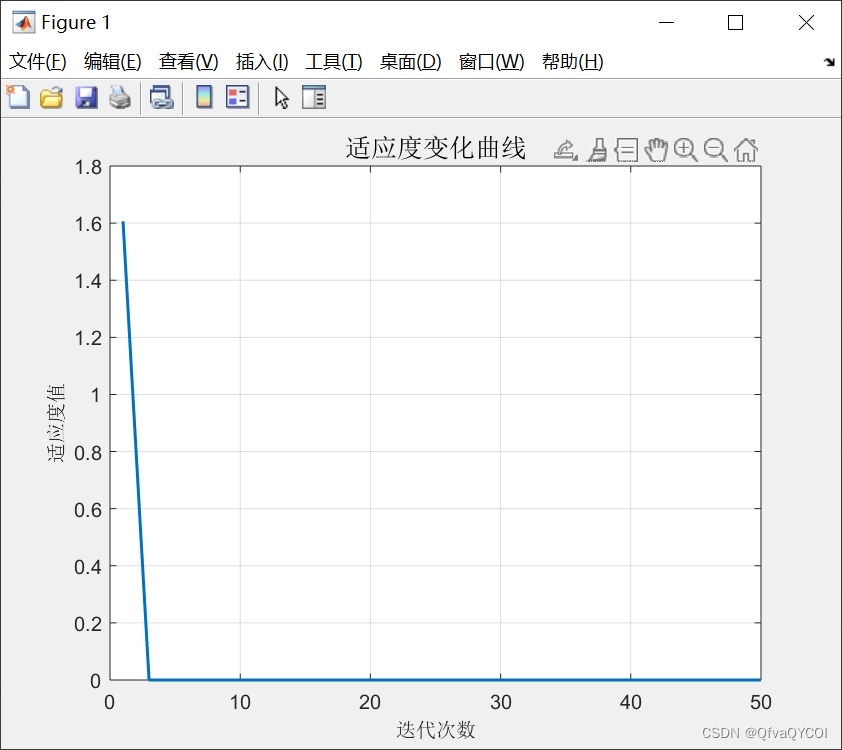
麻雀搜索算法(Sparrow Search Algorithm, SSA)是一种仿生优化算法,模拟了麻雀的觅食行为。该算法通过觅食行为来寻找最优解,具有全局搜索能力强、不易陷入局部最优等优点。在本文中,我们将麻雀搜索算法应用于XGBoost算法的参数优化上,以提高其性能和准确性。
3. XGBoost算法的参数优化
传统的XGBoost算法需要手动设置迭代次数、最大深度和学习率等参数。这些参数的不合理设置会导致算法性能下降,影响数据分类预测的准确性。通过应用麻雀搜索算法优化XGBoost的参数,我们可以自动选择最优的参数组合,提高算法的性能。
4. 交叉验证的应用
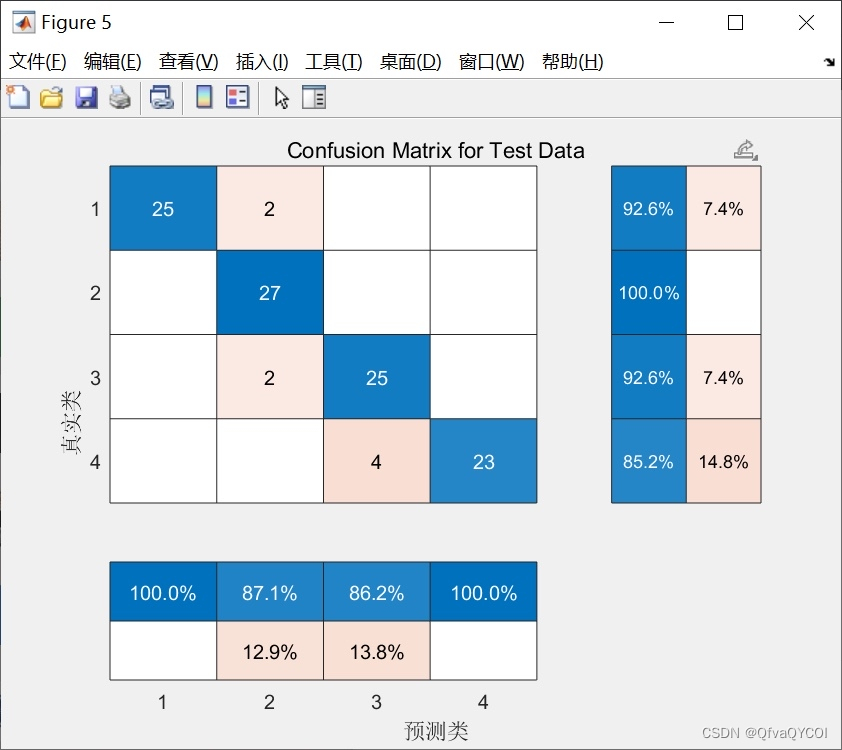
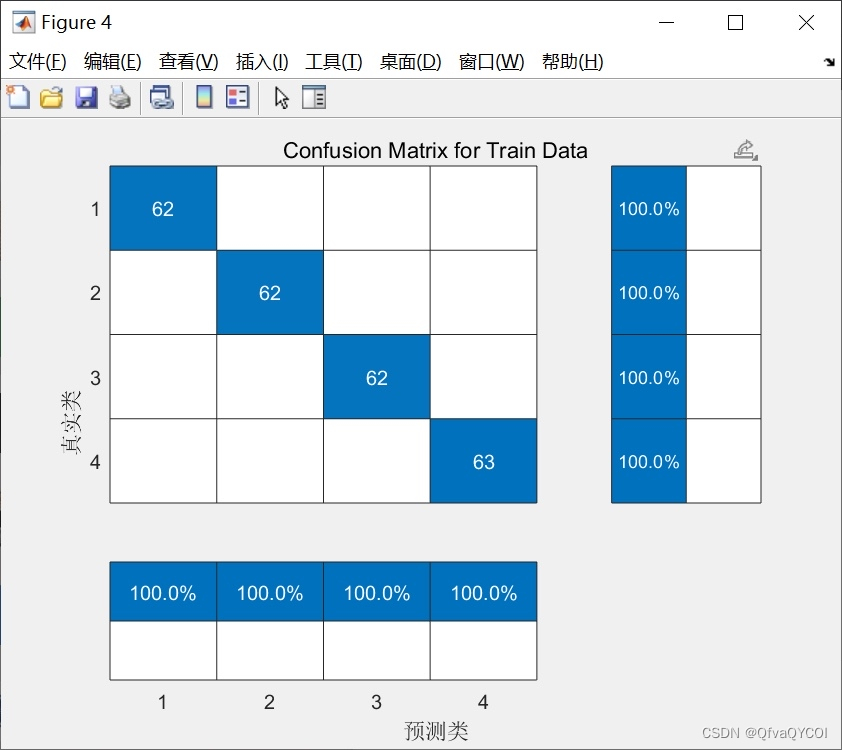
为了解决XGBoost算法中的过拟合问题,我们引入了交叉验证技术。通过将数据集拆分为训练集和验证集,并多次训练模型,我们可以评估模型在不同数据集上的准确性,并选择最优的模型。交叉验证技术能够有效抑制过拟合问题,提高模型的泛化能力。
5. 实验结果与讨论
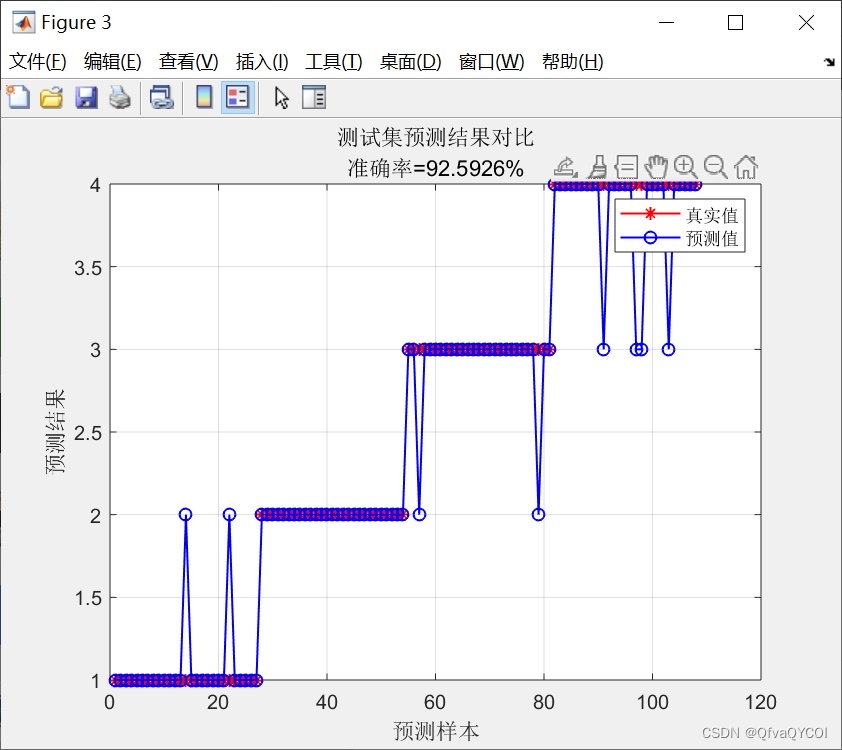
我们使用实际数据集对提出的SSA-xgboost方法进行了实验,并与传统的XGBoost算法进行了对比。实验结果表明,SSA-xgboost方法在数据分类预测中具有更高的准确性和性能。优化后的参数组合能够更好地适应不同的数据集,提高了算法的泛化能力。
6. 结论
本文提出了一种基于麻雀搜索算法优化XGBoost的方法(SSA-xgboost),通过优化迭代次数、最大深度和学习率等参数,提高了XGBoost算法在数据分类预测中的性能和准确性。同时,应用交叉验证技术可以有效抑制过拟合问题,提高模型的泛化能力。未来的工作可以进一步探索其他优化算法在XGBoost中的应用,进一步提升算法的性能。
相关代码,程序地址:http://lanzoup.cn/671420912919.html


















 163
163

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









