







写在前面
近两年来和几个单位接触下来,发现PCIe还是一个比较常用的,有些难度的案例,主要是涉及面比较广,需要了解逻辑设计、高速总线、Linux和Windows的驱动设计等相关知识。
这篇文章主要针对Xilinx家V6和K7两个系列的PFGA,在Linux和Windows两种系统平台下,基于Xilinx的参考案例XAPP1052的基础上,设计实现了总线主控DMA(Bus Master DMA),透明映像内存空间和中断机制,在实际工程实践中得到了良好的应用,主要应用在光纤PCIe数据采集卡、FPGA加速卡、存储子系统等所有需要和主机进行高速数据交互的场所。这篇博客记录了在学习、开发、调试FPGA和主机之间的PCIe通讯接口的方方面面,记录难免有些差错,有任何事宜,欢迎邮件交流学习,jackxu8#163.com。需要完整设计文件或协助进行二次开发的,也可邮件联系。
第一版本多以开发记录为主,不尽完善,看得人多的话我在逐步完善,尽量讲的更加清楚一下。
PCIe协议基础知识

在高速互连领域中,使用高速差分总线替代并行总线是大势所趋。与单端并行信号(PCI总线)相比,高速差分信号(PCIe总线)可以使用更高的时钟频率,从而使用更少的信号线,完成之前需要许多单端并行数据信号才能达到的总线带宽。
PCI总线使用并行总线结构,在同一条总线上的所有外部设备共享总线带宽,而PCIe总线使用了高速差分总线,并采用端到端的连接方式,因此在每一条PCIe链路中只能连接两个设备。这使得PCIe与PCI总线采用的拓扑结构有所不同。PCIe总线除了在连接方式上与PCI总线不同之外,还使用了一些在网络通信中使用的技术,如支持多种数据路由方式,基于多通路的数据传递方式,和基于报文的数据传送方式,并充分考虑了在数据传送中出现服务质量QoS (Quality of Service)问题。
PCIe总线
| PCIe总线规范 | 总线频率 | 单Lane的峰值带宽 | 编码方式 | 单个Lane带宽 |
| 1.x | 1.25GHz | 2.5GT/s | 8/10b编码 | 250MB/s |
| 2.x | 2.5GHz | 5GT/s | 8/10b编码 | 500MB/s |
| 3.0 | 4GHz | 8GT/s | 128/130b编码 | 1GB/s |
在PCIe总线中,使用GT(Gigatransfer)计算PCIe链路的峰值带宽。GT是在PCIe链路上传递的峰值带宽,其计算公式为 总线频率×数据位宽×2。
按照常理新一代的带宽要比上一代翻倍,PCIe3.0的原始数据传输带宽应该是10GT/s才对而实际却只有8.0GT/s。我们知道,在1.0,2.0标准中,采用的是8b/10b的编码方式,也就是说,每传输8比特有效数据,要附带两比特的校验位,实际要传输10比特数据。因此,有效带宽=原始数据传输带宽*80%。而3.0标准中,使用了更为有效的128b/130b编码方案从而避免20%带宽损失,3.0的浪费带宽仅为1.538%,基本可以忽略不计,因此8GT/s的信号不再仅仅是一个理论数值,它将是一个实在的传输值。
PCIe总线采用了串行连接方式,并使用数据包(Packet)进行数据传输,采用这种结构有效去除了在PCI总线中存在的一些边带信号,如INTx和PME#等信号。在PCIe总线中,数据报文在接收和发送过程中,需要通过多个层次,包括事务层、数据链路层和物理层。PCIe总线的层次结构如下。
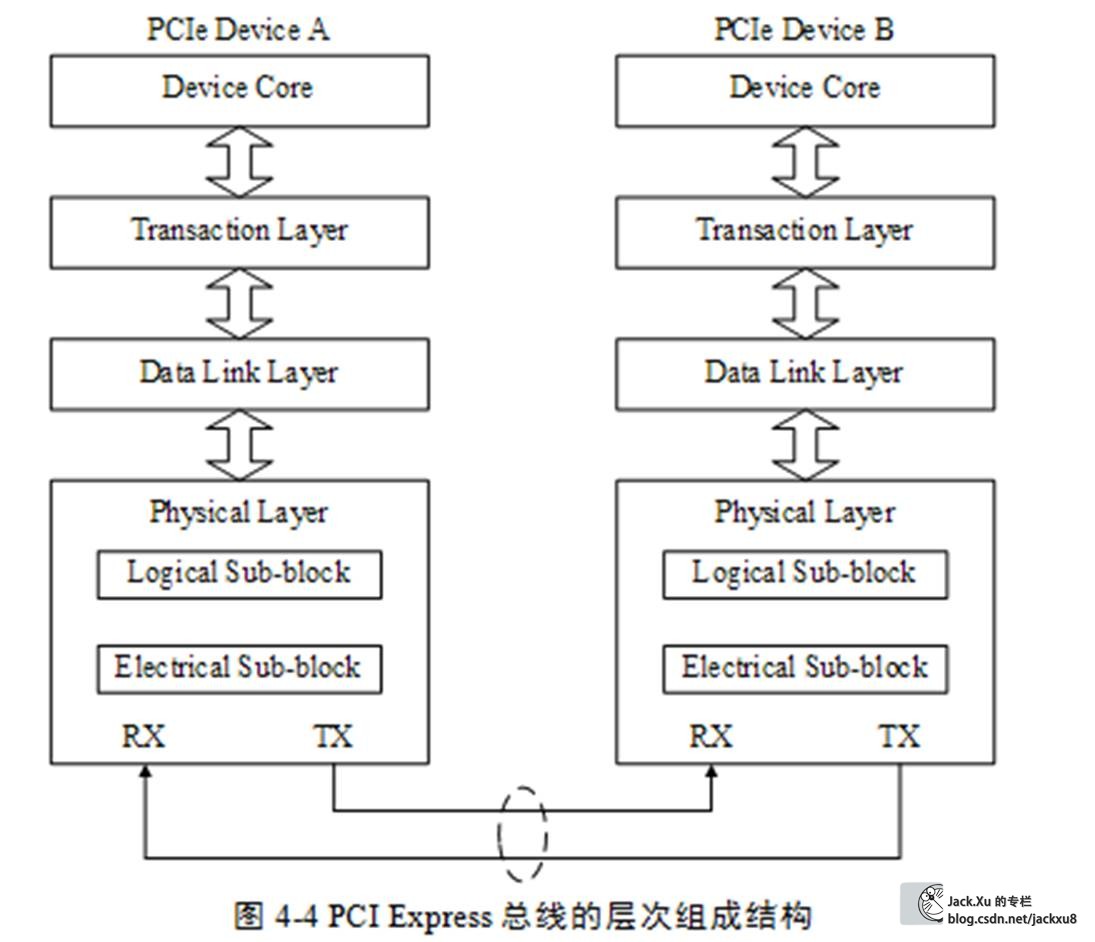
PCIe总线的层次组成结构与网络中的层次结构有类似之处,但是PCIe总线的各个层次都是使用硬件逻辑实现的。在PCIe体系结构中,数据报文首先在设备的核心层(Device Core)中产生,然后再经过该设备的事务层(TransactionLayer)、数据链路层(Data Link Layer)和物理层(Physical Layer),最终发送出去。而接收端的数据也需要通过物理层、数据链路和事务层,并最终到达Device Core。
在PCIe总线层次结构中,事务层最易理解,同时也与系统软件直接相关。
事务层定义了PCIe总线使用总线事务,其中多数总线事务与PCI总线兼容。这些总线事务可以通过Switch等设备传送到其他PCIe设备或者RC,RC也可以使用这些总线事务访问PCIe设备。事务层接收来自PCIe设备核心层的数据,并将其封装为TLP(Transaction Layer Packet)后,发向数据链路层。此外事务层还可以从数据链路层中接收数据报文,然后转发至PCIe设备的核心层。事务层还使用流量控制机制保证PCIe链路的使用效率。
总线信号
在一个处理器系统中,一般提供×16的PCIe插槽,并使用PETp0~15、PETn0~15和PERp0~15、PERn0~15共64根信号线组成32对差分信号,其中16对PETxx信号用于发送链路,另外16对PERxx信号用于接收链路。除此之外PCIe总线还使用了下列辅助信号。
1 PERST#信号
该信号为全局复位信号,由处理器系统提供,处理器系统需要为PCIe插槽和PCIe设备提供该复位信号。PCIe设备使用该信号复位内部逻辑,当该信号有效时,PCIe设备将进行复位操作。PCIe总线定义了多种复位方式,其中Cold Reset和Warm Reset这两种复位方式的实现与该信号有关。
2 REFCLK+和REFCLK-信号
PCIe设备与PCIe插槽都具有REFCLK+和REFCLK-信号,其中PCIe插槽使用这组信号与处理器系统同步。
当PCIe设备作为Add-In卡连接在PCIe插槽时,可以直接使用PCIe插槽提供的REFCLK+和REFCLK-信号,也可以使用独立的参考时钟,只要这个参考时钟在100MHz±300ppm范围内即可。在PCIe设备配置空间的Link Control Register中,含有一个“Common ClockConfiguration”位。当该位为1时,表示该设备与PCIe链路的对端设备使用“同相位”的参考时钟;如果为0,表示该设备与PCIe链路的对端设备使用的参考时钟是异步的。如果主机系统使用用了扩谱时钟,那么最好使用这个参考时钟信号,不要使用自己的晶振产生时钟。
3 WAKE#信号
当PCIe设备进入休眠状态,主电源已经停止供电时,PCIe设备使用该信号向处理器系统提交唤醒请求,使处理器系统重新为该PCIe设备提供主电源Vcc。在PCIe总线中,WAKE#信号是可选的,因此使用WAKE#信号唤醒PCIe设备的机制也是可选的,产生该信号的硬件逻辑必须使用辅助电源Vaux供电。
WAKE#是一个Open Drain信号,一个处理器的所有PCIe设备可以将WAKE#信号进行线与后,统一发送给处理器系统的电源控制器。当某个PCIe设备需要被唤醒时,该设备首先置WAKE#信号有效,然后在经过一段延时之后,处理器系统开始为该设备提供主电源Vcc,并使用PERST#信号对该设备进行复位操作。此时WAKE#信号需要始终保持为低,当主电源Vcc上电完成之后,PERST#信号也将置为无效并结束复位,WAKE#信号也将随之置为无效,结束整个唤醒过程。
配置空间
PCI总线定义了两类配置请求,一个是Type00h配置请求,另一个是Type 01h配置请求。
其中HOST主桥或者PCI桥使用Type 00h配置请求,访问与HOST主桥或者PCI桥直接相连的PCI Agent设备或者PCI桥;而使用Type 01h配置请求,需要至少穿越一个PCI桥,访问没有与其直接相连的PCI Agent设备或者PCI桥。在PCI总线中,只有PCI桥能够接收Type 01h配置请求。Type 01h配置请求不能直接发向最终的PCI Agent设备,而只能由PCI桥将其转换为Type 01h继续发向其他PCI桥,或者转换为Type 00h配置请求发向PCI Agent设备。

基本配置空间
这个基本配置空间共由64个字节组成,其地址范围为0x00~0x3F,这64个字节是所有PCI设备必须支持的。
PCI设备都有独立的配置空间,HOST主桥通过配置读写总线事务访问这段空间。PCI总线规定了三种类型的PCI配置空间,分别是PCI Agent设备使用的配置空间,PCI桥使用的配置空间和Cardbus桥片使用的配置空间。
在PCI设备配置空间中出现的地址都是PCI总线地址,属于PCI总线域地址空间。
在PCI Agent设备的配置空间中包含了许多寄存器,这些寄存器决定了该设备在PCI总线中的使用方法,系统软件只对部分配置寄存器感兴趣。PCI Agent设备使用的Type 00配置空间如下。

在PCI Agent设备配置空间中包含的寄存器如下所示。
(1) DeviceID和Vendor ID寄存器
这两个寄存器的值由PCISIG分配,只读。其中Vendor ID代表PCI设备的生产厂商,而Device ID代表这个厂商所生产的具体设备。如Xilinx公司的K7,其Vendor ID为0x10EE,而Device ID为0x7028。
(5) SubsystemID和Subsystem Vendor ID寄存器
这两个寄存器和DeviceID和Vendor ID类似,也是记录PCI设备的生产厂商和设备名称。但是这两个寄存器和Device ID与Vendor ID寄存器略有不同。下文以一个实例说明Subsystem ID和Subsystem
(6) ExpansionROM base address寄存器
有些PCI设备在处理器还没有运行操作系统之前,就需要完成基本的初始化设置,比如显卡、键盘和硬盘等设备。为了实现这个“预先执行”功能,PCI设备需要提供一段ROM程序,而处理器在初始化过程中将运行这段ROM程序,初始化这些PCI设备。ExpansionROM base address记载这段ROM程序的基地址。
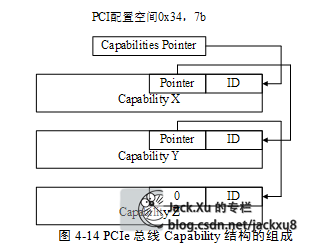
(7) CapabilitiesPointer寄存器
在PCI设备中,该寄存器是可选的,但是在PCIe设备中必须支持这个寄存器,Capabilities Pointer寄存器存放Capabilities寄存器组的基地址,PCI设备使用Capabilities寄存器组存放一些与PCI设备相关的扩展配置信息。
(8) InterruptLine寄存器
这个寄存器是系统软件对PCI设备进行配置时写入的,该寄存器记录当前PCI设备使用的中断向量号,设备驱动程序可以通过这个寄存器,判断当前PCI设备使用处理器系统中的哪个中断向量号,并将驱动程序的中断服务例程注册到操作系统中。
(9) InterruptPin寄存器
这个寄存器保存PCI设备使用的中断引脚,PCI总线提供了四个中断引脚INTA#、INTB#、INTC#和INTD#。InterruptPin寄存器为1时表示使用INTA#引脚向中断控制器提交中断请求,为2表示使用INTB#,为3表示使用INTC#,为4表示使用INTD#。
如果PCI设备只有一个子设备时,该设备只能使用INTA#;如果有多个子设备时,可以使用INTB~D#信号。如果PCI设备不使用这些中断引脚,向处理器提交中断请求时,该寄存器的值必须为0。值得注意的是,虽然在PCIe设备中并不含有INTA~D#信号,但是依然可以使用该寄存器,因为PCIe设备可以使用INTx中断消息,模拟PCI设备的INTA~D#信号。
(10) BaseAddress Register 0~5寄存器
该组寄存器简称为BAR寄存器,BAR寄存器保存PCI设备使用的地址空间的基地址,该基地址保存的是该设备在PCI总线域中的地址。其中每一个设备最多可以有6个基址空间,但多数设备不会使用这么多组地址空间。
在PCI设备复位之后,该寄存器将存放PCI设备需要使用的基址空间大小,这段空间是I/O空间还是存储器空间,如果是存储器空间该空间是否可预取。
系统软件对PCI总线进行配置时,首先获得BAR寄存器中的初始化信息,之后根据处理器系统的配置,将合理的基地址写入相应的BAR寄存器中。系统软件还可以使用该寄存器,获得PCI设备使用的BAR空间的长度,其方法是向BAR寄存器写入0xFFFF-FFFF,之后再读取该寄存器。
处理器访问PCI设备的BAR空间时,需要使用BAR寄存器提供的基地址。值得注意的是,处理器使用存储器域的地址,而BAR寄存器存放PCI总线域的地址。因此处理器系统并不能直接使用“BAR寄存器+偏移”的方式访问PCI设备的寄存器空间,而需要将PCI总线域的地址转换为存储器域的地址。
扩展配置空间
此外PCI/PCI-X和PCIe设备还扩展了0x40~0xFF这段配置空间,在这段空间主要存放一些与MSI或者MSI-X中断机制和电源管理相关的Capability结构。其中所有能够提交中断请求的PCIe设备,必须支持MSI或者MSI-X Capability结构。
PCIe设备还支持0x100~0xFFF这段扩展配置空间。PCIe设备使用的扩展配置空间最大为4KB,在PCIe总线的扩展配置空间中,存放PCIe设备所独有的一些Capability结构,而PCI设备不能使用这段空间。
PCIe总线规范要求其设备必须支持Capabilities结构。在PCI总线的基本配置空间中,包含一个Capabilities Pointer寄存器,该寄存器存放Capabilities结构链表的头指针。在一个PCIe设备中,可能含有多个Capability结构,这些寄存器组成一个链表。一个PCIe设备可以包含多个Capability结构,包括与电源管理相关、与PCIe总线相关的结构、与中断请求相关的Capability结构、PCIe Capability结构和PCIe扩展的Capability结构。
事务层协议
事务层是PCIe总线层次结构的最高层,该层次将接收PCIe设备核心层的数据请求,并将其转换为PCIe总线事务,PCIe总线使用的这些总线事务在TLP头中定义。
在PCIe总线中,Non-Posted总线事务分两部分进行,首先是发送端向接收端提交总线读写请求,之后接收端再向发送端发送完成(Completion)报文。PCIe总线使用Split传送方式处理所有Non-Posted总线事务,存储器读、I/O读写和配置读写这些Non-Posted总线事务都使用Split传送方式。PCIe的事务层还支持流量控制和虚通路管理等一系列特性。
TLP格式
当处理器或者其他PCIe设备访问PCIe设备时,所传送的数据报文首先通过事务层被封装为一个或者多个TLP,之后才能通过PCIe总线的各个层次发送出去。
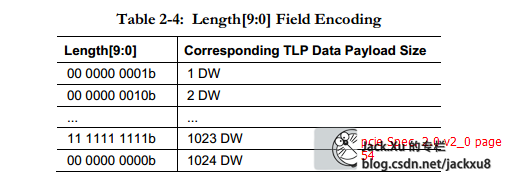
一个完整的TLP由1个或者多个TLP Prefix、TLP头、Data Payload(数据有效负载)和TLP Digest组成。TLP头是TLP最重要的标志,不同的TLP其头的定义并不相同。TLP头包含了当前TLP的总线事务类型、路由信息等一系列信息。在一个TLP中,Data Payload的长度可变,最小为0,最大为1024DW。
TLPDigest是一个可选项, 一个TLP是否需要TLP Digest由TLP头决定。DataPayload也是一个可选项,有些TLP并不需要DataPayload,如存储器读请求、配置和I/O写完成TLP并不需要Data Payload。
TLPPrefix由PCIe V2.1总线规范引入,分为LocalTLP Prefix和EP-EP TLP Prefix两类。其中Local TLP Prefix的主要作用是在PCIe链路的两端传递消息,而EP-EP TLP Prefix的主要作用是在发送设备和接收设备之间传递消息。
TLP头由3个或者4个双字(DW)组成。其中第一个双字中保存通用TLP头,其他字段与通用TLP头的Type字段相关。一个通用TLP头由Fmt、Type、TC、Length等字段组成,如图5‑2所示。
如果存储器读写TLP支持64位地址模式时,TLP头的长度为4DW,否则为3DW。而完成报文的TLP头不含有地址信息,使用的TLP头长度为3DW。
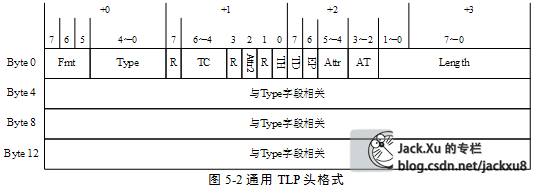
通用TLP头的Fmt字段和Type字段
Fmt和Type字段确认当前TLP使用的总线事务,TLP头的大小是由3个双字还是4个双字组成,当前TLP是否包含有效负载。这里列举一些常用的
| Fmt[2:0] | TLP的格式 |
| 0b000 | TLP大小为3个双字,不带数据。 |
| 0b001 | TLP大小为4个双字,不带数据。 |
| 0b010 | TLP大小为3个双字,带数据。 |
| 0b011 | TLP大小为4个双字,带数据。 |
其中所有读请求TLP都不带数据,而写请求TLP带数据,而其他TLP可能带数据也可能不带数据,如完成报文可能含有数据,也可能仅含有完成标志而并不携带数据。在TLP的Type字段中存放TLP的类型,即PCIe总线支持的总线事务。该字段共由5位组成,这里列举一些常用的
| TLP类型 | Fmt[2:0] | Type[4:0] | 描述 |
| MRd | 0b000 0b001 | 0b0 0000 | 存储器读请求;TLP头大小为3个或者4个双字,不带数据。 |
| MWr | 0b010 0b011 | 0b0 0000 | 存储器写请求;TLP头大小为3个或者4个双字,带数据。 |
| CplD | 0b010 | 0b0 1010 | 带数据的完成报文,TLP头大小为3个双字,包括存储器读、I/O读、配置读和原子操作读完成。 |
PCIe总线的数据报文传送方式与PCI总线数据传送有类似之处。其中存储器写TLP使用Posted方式进行传送,而其他总线事务使用Non-Posted方式。PCIe总线规定所有Non-Posted存储器请求使用Split总线方式进行数据传递。当PCIe设备进行存储器读、I/O读写或者配置读写请求时,首先向目标设备发送数据读写请求TLP,当目标设备收到这些读写请求TLP后,将数据和完成信息通过完成报文(Cpl或者CplD)发送给源设备。
其中存储器读、I/O读和配置读需要使用CplD报文,因为目标设备需要将数据传递给源设备;而I/O写和配置写需要使用Cpl报文,因为目标设备不需要将任何数据传递给源设备,但是需要通知源设备,写操作已经完成,数据已经成功地传递给目标设备。
存储器和配置读写请求TLP
(1) 存储器读请求TLP和读完成TLP
当PCIe主设备,RC或者EP,访问目标设备的存储器空间时,使用Non-Posted总线事务向目标设备发出存储器读请求TLP,目标设备收到这个存储器读请求TLP后,使用存储器读完成TLP,主动向主设备传递数据。当主设备收到目标设备的存储器读完成TLP后,将完成一次存储器读操作。
(2) 存储器写请求TLP
在PCIe总线中,存储器写使用Posted总线事务。PCIe主设备仅使用存储器写请求TLP即可完成存储器写操作,主设备不需要目标设备的回应报文。
(5) 配置读写请求TLP和配置读写完成TLP
从总线事务的角度上看,配置读写请求操作的过程与I/O读写操作的过程类似。配置读写请求TLP都需要配置读写完成作为应答,从而完成一个完成的配置读写操作。
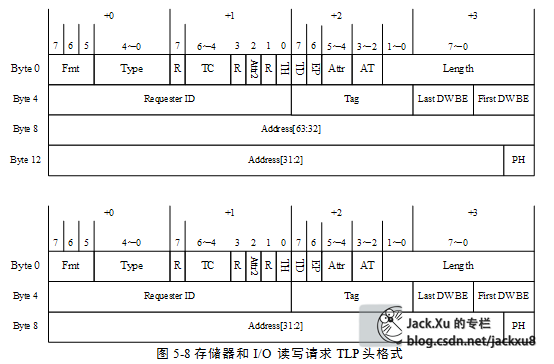
在PCIe总线中,存储器写请求TLP使用Posted数据传送方式。而其他与存储器和I/O相关的报文都使用Split方式进行数据传送,这些请求报文需要完成报文,通知发送端之前的数据请求报文已经被处理完毕。存储器读写请求TLP使用地址路由方式进行数据传递,在这类TLP头中包含Address字段,Address字段具有两种地址格式,分别是32位和64位地址。在存储器读写和I/O读写请求的第3和第4个双字中,存放TLP的32或者64位地址。存储器、I/O和原子操作读写请求使用的TLP头较为类似。
1 Length字段
在存储器读请求TLP中并不包含Data Payload,在该报文中,Length字段表示需要从目标设备数据区域读取的数据长度;而在存储器写TLP中,Length字段表示当前报文的DataPayload长度。Length字段的最小单位为DW。当该字段为n时,表示需要获得的数据长度或者当前报文的数据长度为n个DW,其中0£n£0x3FF。值得注意的是,当n等于0时,表示数据长度为1024个DW。
2 DWBE字段
PCIe总线以字节为基本单位进行数据传递,但是Length字段以DW为最小单位。为此TLP使用Last DW BE和First DW BE这两个字段进行字节使能,使得在一个TLP中,有效数据以字节为单位。
这两个DW BE字段各由4位组成,其中Last DW BE字段的每一位对应数据Payload最后一个双字的字节使能位;而First DW BE字段的每一位对应数据Payload第一个双字的字节使能位。
| Last DW BE | 第3位 | 为1表示数据Payload的最后一个双字的字节3有效 |
| 第2位 | 为1表示数据Payload的最后一个双字的字节2有效 | |
| 第1位 | 为1表示数据Payload的最后一个双字的字节1有效 | |
| 第0位 | 为1表示数据Payload的最后一个双字的字节0有效 | |
| First DW BE | 第3位 | 为1表示数据Payload的第一个双字的字节3有效 |
| 第2位 | 为1表示数据Payload的第一个双字的字节2有效 | |
| 第1位 | 为1表示数据Payload的第一个双字的字节1有效 | |
| 第0位 | 为1表示数据Payload的第一个双字的字节0有效 |
LastDW BE和First DW BE这两个字段的使用规则如下。
· 如果传送的数据长度在一个对界的双字(DW)之内,则Last DW BE字段为0b0000,而First DW BE的对应位置1;如果数据长度超过1DW,Last DW BE字段一定不能为0b0000。PCIe总线使用LastDW BE字段为0b0000表示所传送的数据在一个对界的DW之内。
· 如果传送的数据长度超过1DW,则First DW BE字段至少有一个位使能。不能出现First DW BE为0b0000的情况。
· 如果传送的数据长度大于等于3DW,则在First DW BE和Last DW BE字段中不能出现不连续的置1位。
· 如果传送的数据长度在1DW之内时,在First DW BE字段中允许有不连续的置1位。此时PCIe总线允许在TLP中传送1个DW的第1,3字节或者第0,2字节。
· 如果传送的数据长度为2DW之内时,则First DW BE字段和Last DW BE字段允许有不连续的置1位。
值得注意的是,PCIe总线支持一种特殊的读操作,即“Zero-Length”读请求。此时Length字段的长度为1DW,而First DW BE字段和LastDW BE字段都为0b0000,即所有字节都不使能。此时与这个存储器读请求TLP对应的读完成TLP中不包含有效数据。再次提醒读者注意“Zero-Length”读请求使用的Length字段为1,而不是为0,为0表示需要获得的数据长度为1024个DW。
“Zero-Length”读请求的引入是为了实现“读刷新”操作,该操作的主要目的是为了确保之前使用Posted方式所传送的数据,到达最终的目的地,与“Zero-Length”读对应的读完成报文中不含有负载,从而提高了PCIe链路的利用率。在PCIe总线中,使用Posted方式进行存储器写时,目标设备不需要向主设备发送回应报文,因此主设备并不知道这个存储器写是否已经达到目的地。而主设备可以使用“读刷新”操作,向目标设备进行读操作来保证存储器写最终到达目的地。
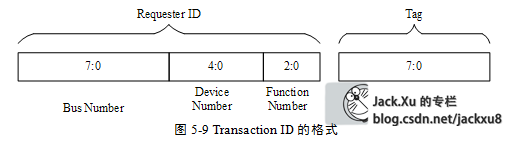
3 RequesterID字段
RequesterID字段包含“生成这个TLP报文”的PCIe设备的总线号(Bus Number)、设备号(Device Number)和功能号(Function Number),其格式如图5‑9所示。对于存储器写请求TLP,Requester ID字段并不是必须的,因为目标设备收到存储器写请求TLP后,不需要完成报文作为应答,因此Requester ID字段对于存储器写请求TLP并没有实际意义。
TLP中与数据负载相关的参数
在PCIe总线中,有些TLP含有Data Payload,如存储器写请求、存储器读完成TLP等。在PCIe总线中,TLP含有的Data Payload大小与Max_Payload_Size、Max_Read_Request_Size和RCB参数相关。
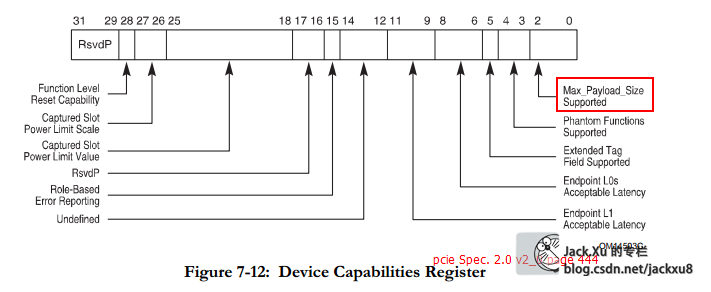
Max_Payload_Size参数
PCIe总线规定在TLP报文中,数据有效负载的最大值为4KB,但是PCIe设备并不一定能够发送这么大的数据报文。PCIe设备含有“Max_Payload_Size”和“Max_Payload_SizeSupported”参数,这两个参数分别在Device Capability寄存器和Device Control寄存器中定义。
“Max_Payload_SizeSupported”参数存放在一个PCIe设备中,TLP有效负载的最大值,该参数由PCIe设备的硬件逻辑确定,系统软件不能改写该参数。而Max_Payload_Size参数存放PCIe设备实际使用的,TLP有效负载的最大值。该参数由PCIe链路两端的设备协商决定,是PCIe设备进行数据传送时,实际使用的参数。
PCIe设备发送数据报文时,使用Max_Payload_Size参数决定TLP的最大有效负载。当PCIe设备的所传送的数据大小超过Max_Payload_Size参数时,这段数据将被分割为多个TLP进行发送。当PCIe设备接收TLP时,该TLP的最大有效负载也不能超过Max_Payload_Size参数,如果接收的TLP,其Length字段超过Max_Payload_Size参数,该PCIe设备将认为该TLP非法。
RC或者EP在发送存储器读完成TLP时,这个存储器读完成TLP的最大Payload也不能超过Max_Payload_Size参数,如果超过该参数,PCIe设备需要发送多个读完成报文。值得注意的是,这些读完成报文需要满足RCB参数的要求,有关RCB参数的详细说明见下文。
在实际应用中,尽管有些PCIe设备的Max_Payload_Size Supported参数可以为256B、512B、1024B或者更高,但是如果PCIe链路的对端设备可以支持的Max_Payload_Size参数为128B时,系统软件将使用对端设备的Max_Payload_Size Supported参数,初始化该设备的Max_Payload_Size参数,即选用PCIe链路两端最小的Max_Payload_Size Supported参数初始化Max_Payload_Size参数。
在多数x86处理器系统的MCH或者ICH中,Max_Payload_SizeSupported参数为128B。这也意味着在x86处理器中,与MCH或者ICH直接相连的PCIe设备进行DMA读写时,数据的有效负载不能超过128B。而在PowerPC处理器系统中,该参数大多为256B。
目前在大多数EP中,Max_Payload_Size Supported参数不大于512B,因为在大多数处理器系统的RC中,Max_Payload_Size Supported参数也不大于512B。因此即便EP支持较大的Max_Payload_SizeSupported参数,并不会提高数据传送效率。
而Max_Payload_Size参数的大小与PCIe链路的传送效率成正比,该参数越大,PCIe链路带宽的利用率越高,该参数越小,PCIe链路带宽的利用率越低。
PCIe总线规范规定,对于实时性要求较高的PCIe设备,Max_Payload_Size参数不应设置过大,因此这个参数有时会低于PCIe链路允许使用的最大值。
Max_Read_Request_Size参数
Max_Read_Request_Size参数由PCIe设备决定,该参数规定了PCIe设备一次能从目标设备读取多少数据。
Max_Read_Request_Size参数在Device Control寄存器中定义。该参数与存储器读请求TLP的Length字段相关,其中Length字段不能大于Max_Read_Request_Size参数。在存储器读请求TLP中,Length字段表示需要从目标设备读取多少数据。
值得注意的是,Max_Read_Request_Size参数与Max_Payload_Size参数间没有直接联系,Max_Payload_Size参数仅与存储器写请求和存储器读完成报文相关。
PCIe总线规定存储器读请求,其读取的数据长度不能超过Max_Read_Request_Size参数,即存储器读TLP中的Length字段不能大于这个参数。如果一次存储器读操作需要读取的数据范围大于Max_Read_Request_Size参数时,该PCIe设备需要向目标设备发送多个存储器读请求TLP。
PCIe总线规定Max_Read_Request_Size参数的最大值为4KB,但是系统软件需要根据硬件特性决定该参数的值。因为PCIe总线规定EP在进行存储器读请求时,需要具有足够大的缓冲接收来自目标设备的数据。
如果一个EP的Max_Read_Request_Size参数被设置为4KB,而且这个EP每发出一个4KB大小存储器读请求时,EP都需要准备一个4KB大小的缓冲[1]。这对于绝大多数EP,这都是一个相当苛刻的条件。为此在实际设计中,一个EP会对Max_Read_Request_Size参数的大小进行限制。
RCB参数
RCB位在Link Control寄存器中定义。RCB位决定了RCB参数的值,在PCIe总线中,RCB参数的大小为64B或者128B,如果一个PCIe设备没有设置RCB的大小[2],则RC的RCB参数缺省值为64B,而其他PCIe设备的RCB参数的缺省值为128B。PCIe总线规定RC的RCB参数的值为64B或者128B,其他PCIe设备的RCB参数为128B。
在PCIe总线中,一个存储器读请求TLP可能收到目标设备发出的多个完成报文后,才能完成一次存储器读操作。因为在PCIe总线中,一个存储器读请求最多可以请求4KB大小的数据报文,而目标设备可能会使用多个存储器读完成TLP才能将数据传递完毕。
当一个EP向RC或者其他EP读取数据时,这个EP首先向RC或者其他EP发送存储器读请求TLP;之后由RC或者其他EP发送存储器读完成TLP,将数据传递给这个EP。
如果存储器读完成报文所传递数据的地址范围没有跨越RCB参数的边界,那么数据发送端只能使用一个存储器完成报文将数据传递给请求方,否则可以使用多个存储器读完成TLP。
假定一个EP向地址范围为0xFFFF-0000~0xFFFF-0010这段区域进行DMA读操作,RC收到这个存储器读请求TLP后,将组织存储器读完成TLP,由于这段区域并没有跨越RCB边界,因此RC只能使用一个存储器读完成TLP完成数据传递。
如果存储器读完成报文所传递数据的地址范围跨越了RCB边界,那么数据发送端(目标设备)可以使用一个或者多个完成报文进行数据传递。数据发送端使用多个存储器读完成报文完成数据传递时,需要遵循以下原则。
· 第一个完成报文所传送的数据,其起始地址与要求的起始地址相同。其结束地址或者为要求的结束地址(使用一个完成报文传递所有数据),或者为RCB参数的整数倍(使用多个完成报文传递数据)。
· 最后一个完成报文的起始地址或者为要求的起始地址(使用一个完成报文传递所有数据),或者为RCB参数的整数倍(使用多个完成报文传递数据)。其结束地址必须为要求的结束地址。
· 中间的完成报文的起始地址和结束地址必须为RCB参数的整数倍。
中断
在PCI总线中,所有需要提交中断请求的设备,必须能够通过INTx引脚提交中断请求,而MSI机制是一个可选机制。而在PCIe总线中,PCIe设备必须支持MSI或者MSI-X中断请求机制,而可以不支持INTx中断消息。在PCIe总线中,MSI和MSI-X中断机制使用存储器写请求TLP向处理器提交中断请求。
不同的处理器对PCIe设备发出的MSI报文的解释并不相同。但是PCIe设备在提交MSI中断请求时,都是向MSI/MSI-X Capability结构中的Message Address的地址写Message Data数据,从而组成一个存储器写TLP,向处理器提交中断请求。
有些PCIe设备还可以支持Legacy中断方式,通过发送Assert_INTx和Deassert_INTx消息报文进行中断请求,即虚拟中断线方式。。但是PCIe总线并不鼓励其设备使用Legacy中断方式,在绝大多数情况下,PCIe设备使用MSI或者MSI/X方式进行中断请求。
PCIe总线提供Legacy中断方式的主要原因是,在PCIe体系结构中,存在许多PCI设备,而这些设备通过PCIe桥连接到PCIe总线中。这些PCI设备可能并不支持MSI/MSI-X中断机制,因此必须使用INTx信号进行中断请求。
当PCIe桥收到PCI设备的INTx信号后,并不能将其直接转换为MSI/MSI-X中断报文,因为PCI设备使用INTx信号进行中断请求的机制与电平触发方式类似,而MSI/MSI-X中断机制与边沿触发方式类似。这两种中断触发方式不能直接进行转换。因此当PCI设备的INTx信号有效时,PCIe桥将该信号转换为Assert_INTx报文,当这些INTx信号无效时,PCIe桥将该信号转换为Deassert_INTx报文。
与Legacy中断方式相比,PCIe设备使用MSI或者MSI-X中断机制,可以消除INTx这个边带信号,而且可以更加合理地处理PCIe总线的“序”。目前绝大多数PCIe设备使用MSI或者MSI-X中断机制提交中断请求。
FPGA设计
博主主要在Xilinx的FPGA上进行设计,好在X家提供了PCIe的IP和,支持到事务层,就不想SATA那么麻烦需要自己从物理层开始写逻辑。本文讲述了从IP核的建立、系统仿真环境的搭建、参考案例的讲解到BMD控制器中各个模块的设计方法。
IP核建立
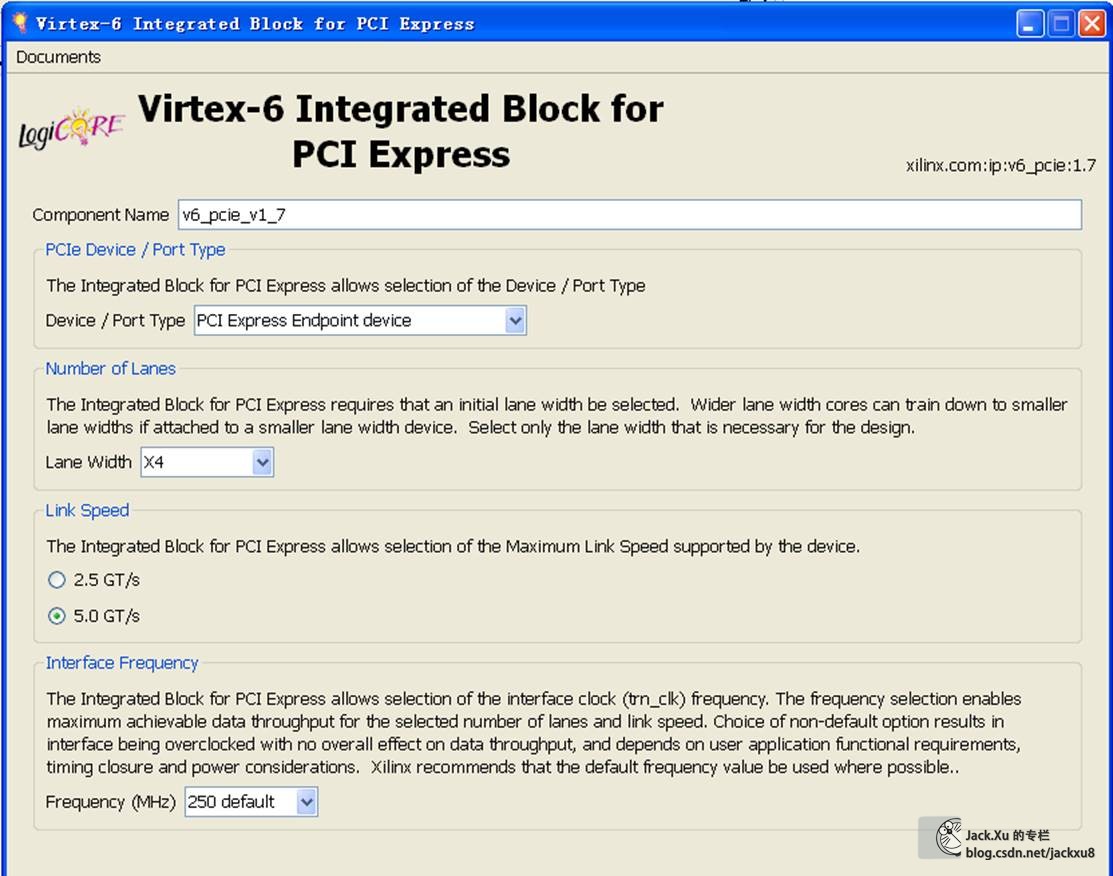
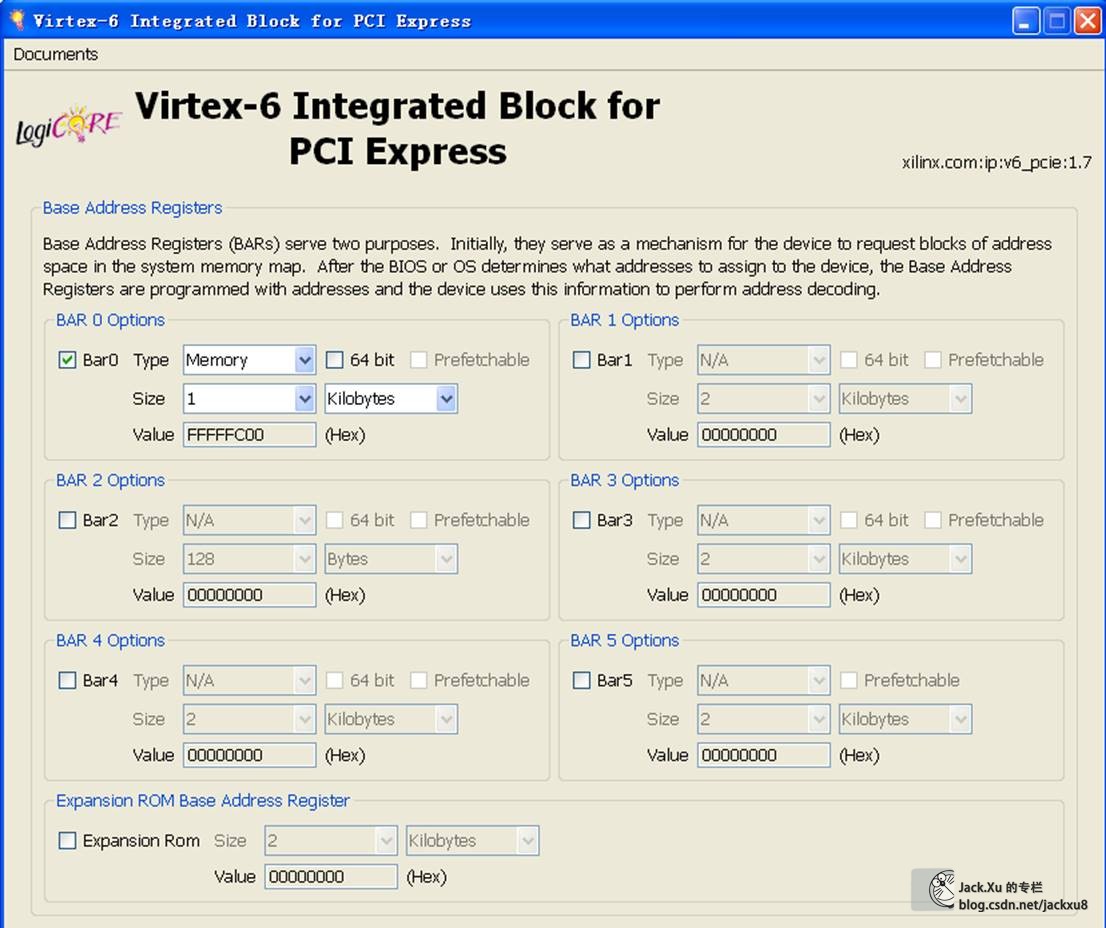
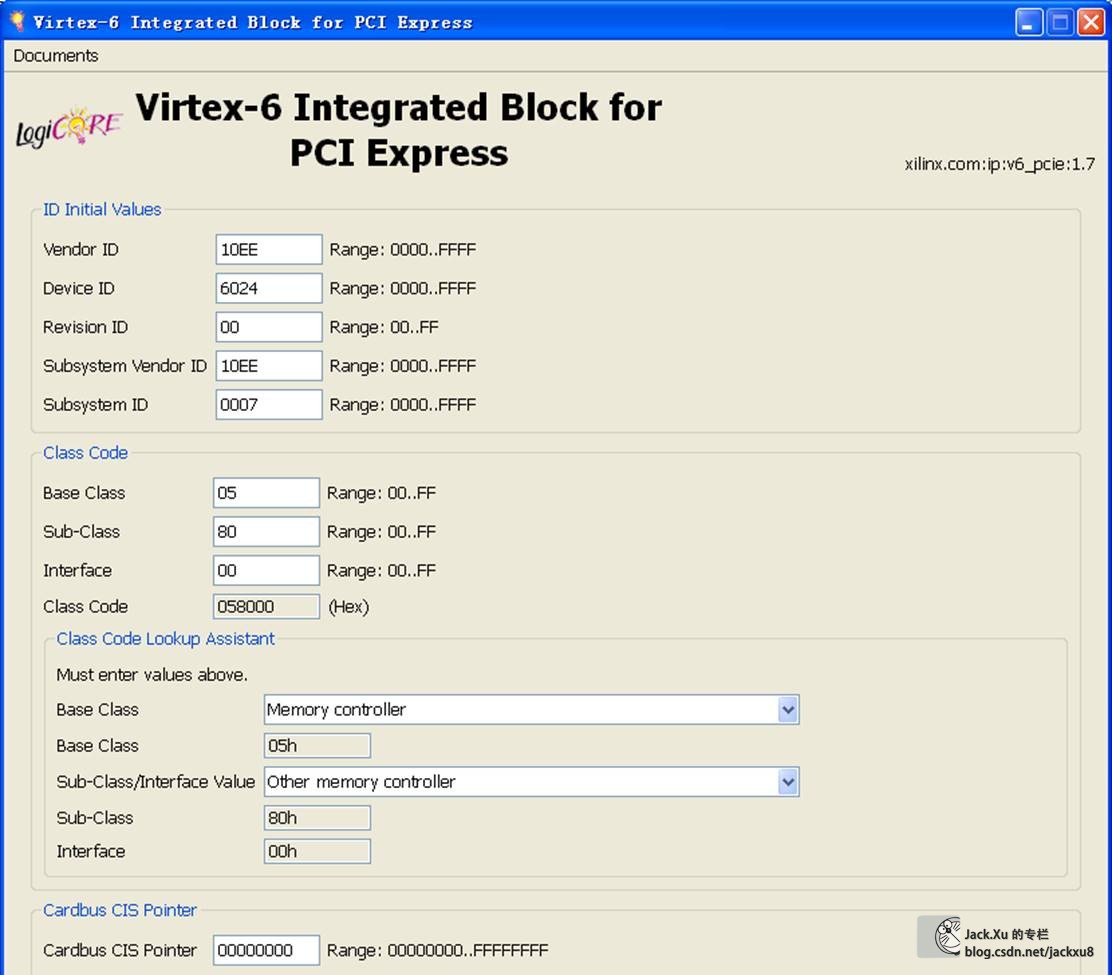
这里V6使用ISE开发,K7使用Vivado开发。核的参数主要是Device Type、Lane Width、Link Speed、Interface Frequency和BAR选项。这个BAR建立BAR0必须要,地址大宇2KB就可以。其他的BAR是不是需要看您喜好。另外,各个ID和驱动安装有关,只要对应上就可以。
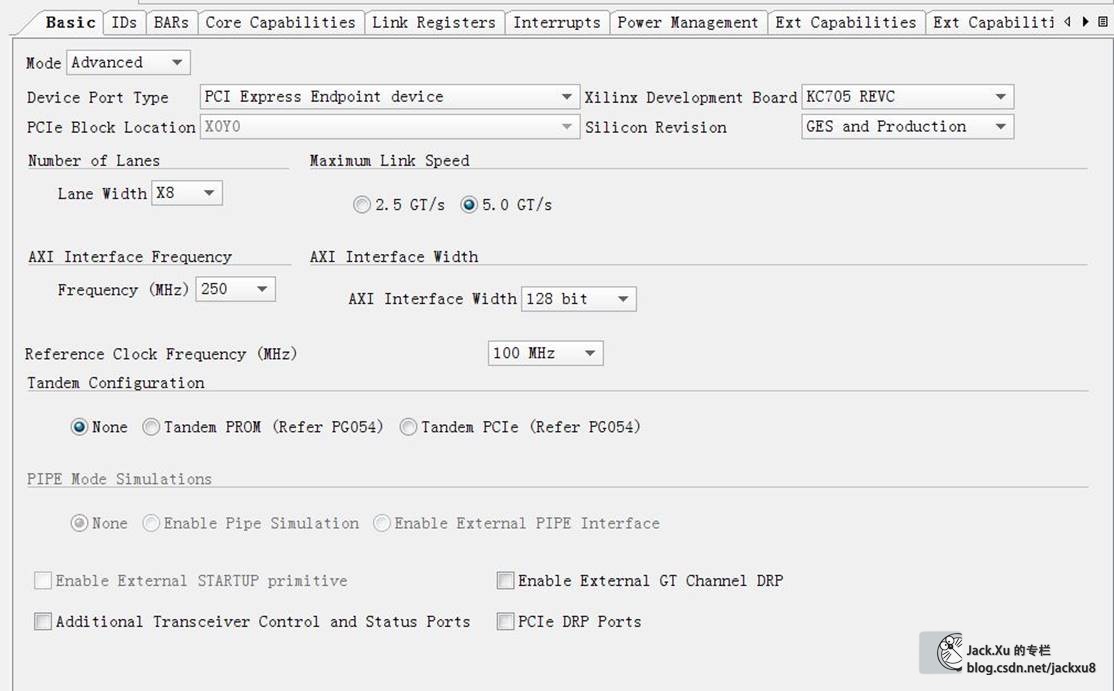
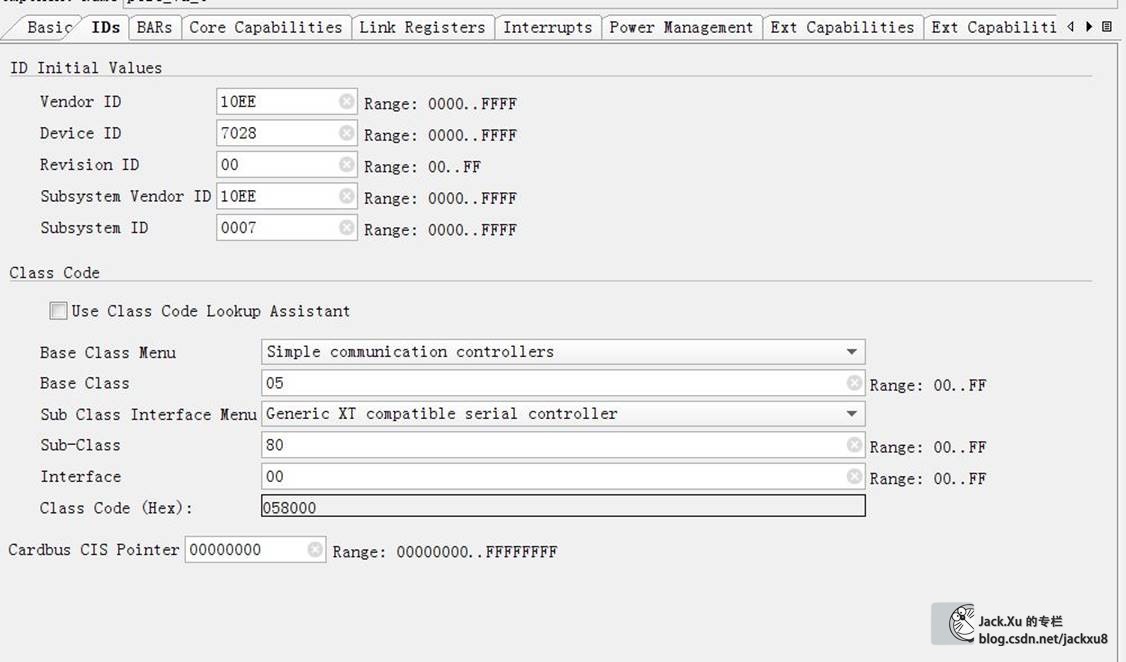
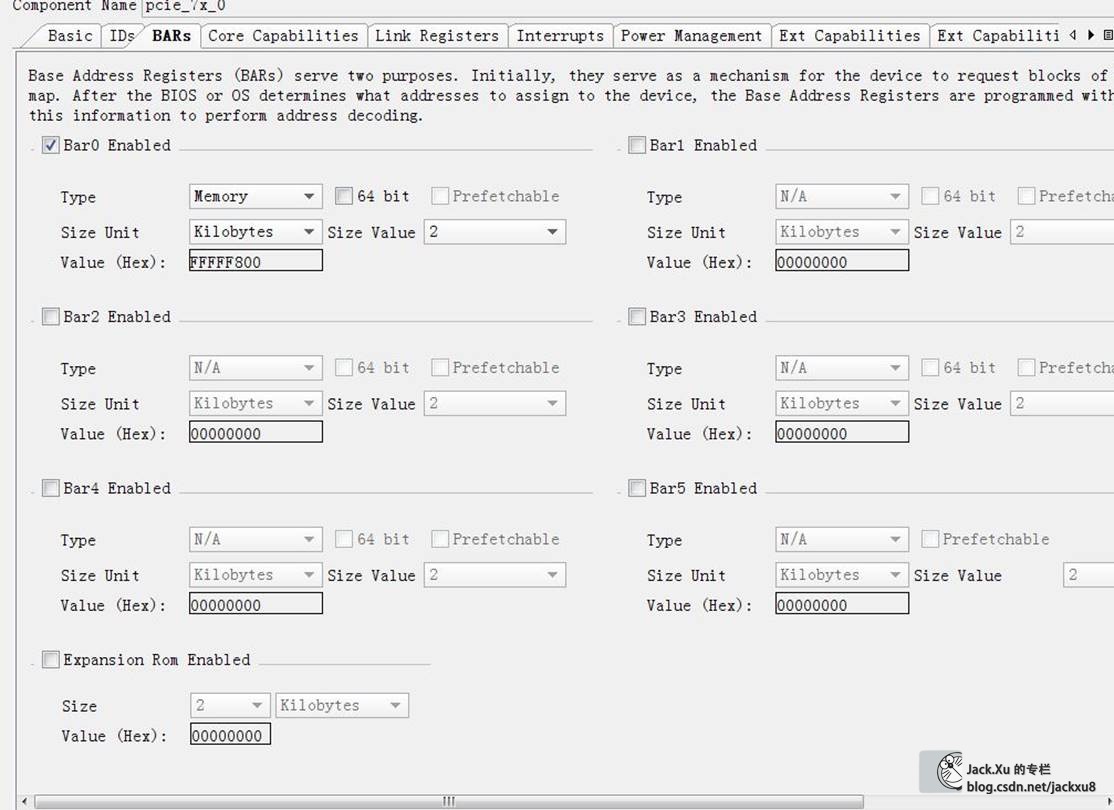

XAPP1052说明
xapp1052是xilinx官方给出的一个有关DMA数据传输的样例,用于PC端和FPGA端之间的DMA数据传输。首先需要说的是,xapp1052并不是一个完整的DMA数据传输的终端硬件设计,这个稍后会有说明。
最新的XAPP1052参考例程为3.3版本,手册在这里,设计文件在这里,下载需要Xilinx账号,我打包放在CSDN上了,可以到这里下载,算是给我贡献一点下载积分吧。
XAPP1052的3.3版本里,对于K7系列以及有一个基于KC705开发板的工程,是在vivado下建立的,使用vivado打开可以直接综合、仿真、测试。
里面包含的BMD的Example和V6系列的稍有差别。包括设计源码、约束和仿真源码。其中,仿真部分的EP是直接例化得设计源码的顶层。
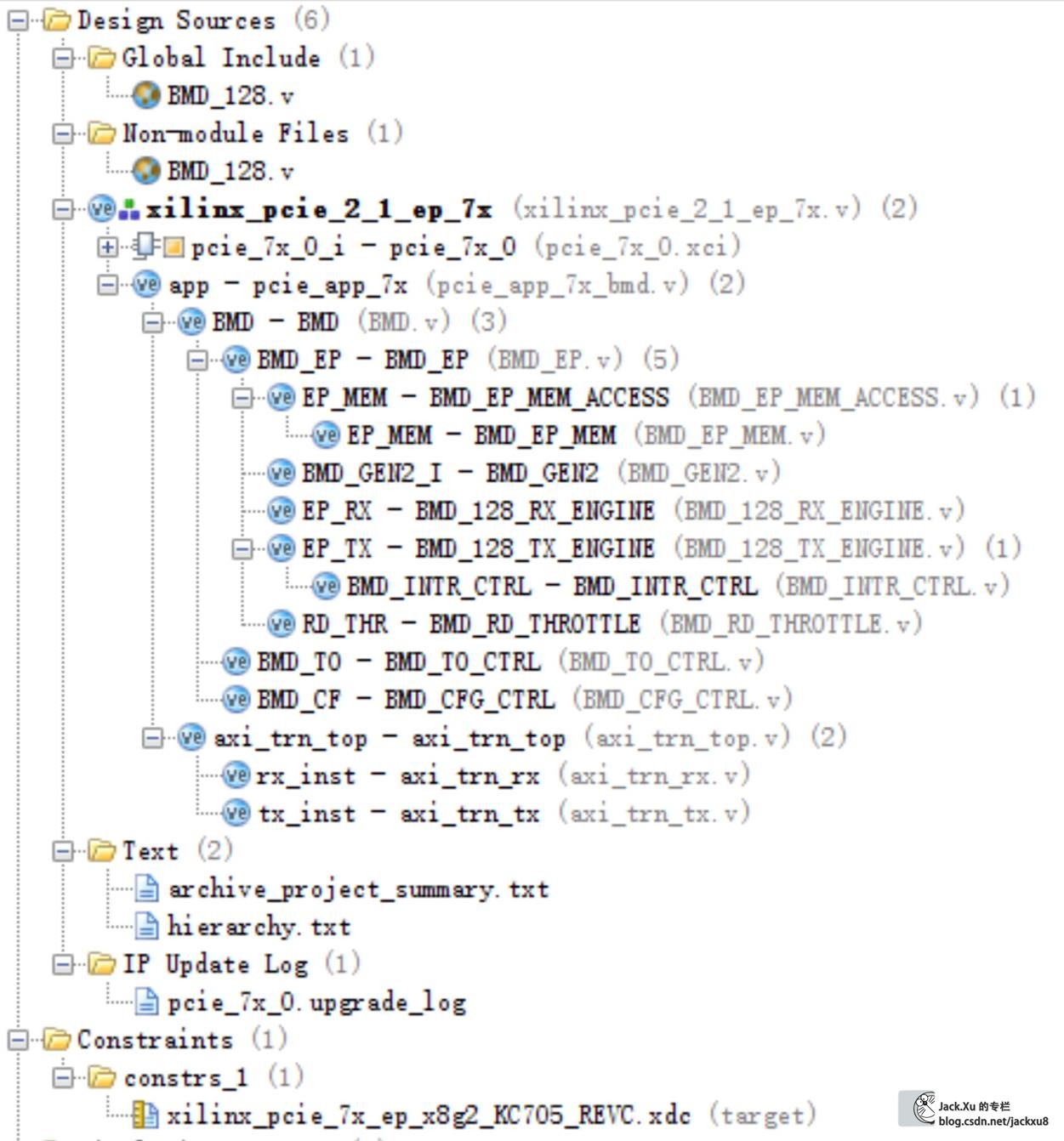
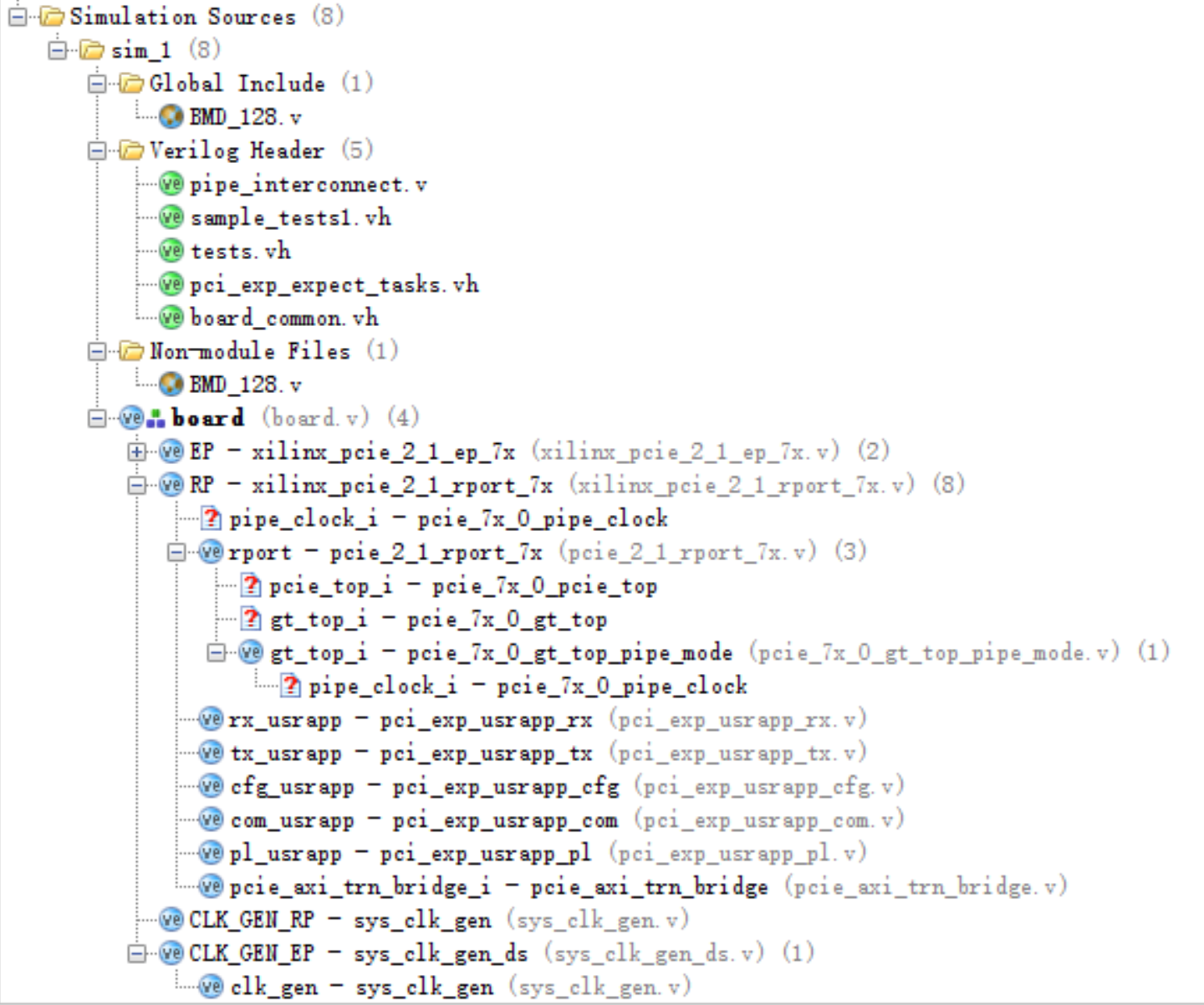
对于使用V6的情况,可以使用XAPP1052 \dma_performance_demo\fpga\implement中的implement_dma.pl脚本自动生成ML605开发板对应的工程。
或者自己搭建工程
..\v6_pcie_v1_7\source全部
..\v6_pcie_v1_7\example_design中的xilinx_pcie_2_0_ep_v6_04_lane_gen2_xc6vlx240t-ff1156-1_ML605.ucf和xilinx_pcie_2_0_ep_v6.v
..\xapp1052\dma_performance_demo\fpga\BMD\common全部
..\xapp1052\dma_performance_demo\fpga\BMD中的BMD_64_RX_ENGINE.v和BMD_64_TX_ENGINE.v和v6_pci_exp_64b_app.v
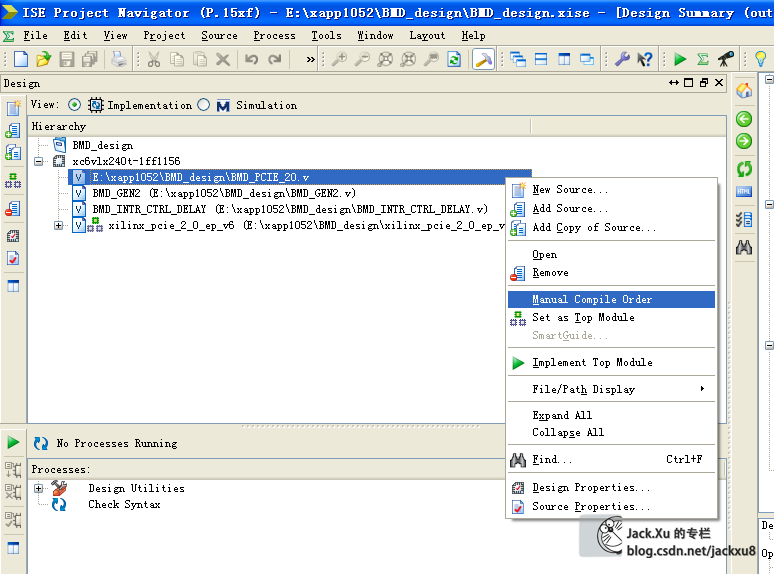
由于工程中使用了全局宏定义,在ISE上支持的不是特别好,在不对的情况下可以使用手动编译顺序
然后编译,由于要先编译BMD_PCIE_20.v,所以右键选择manual compile order,选中所有.v和.ucf文件。
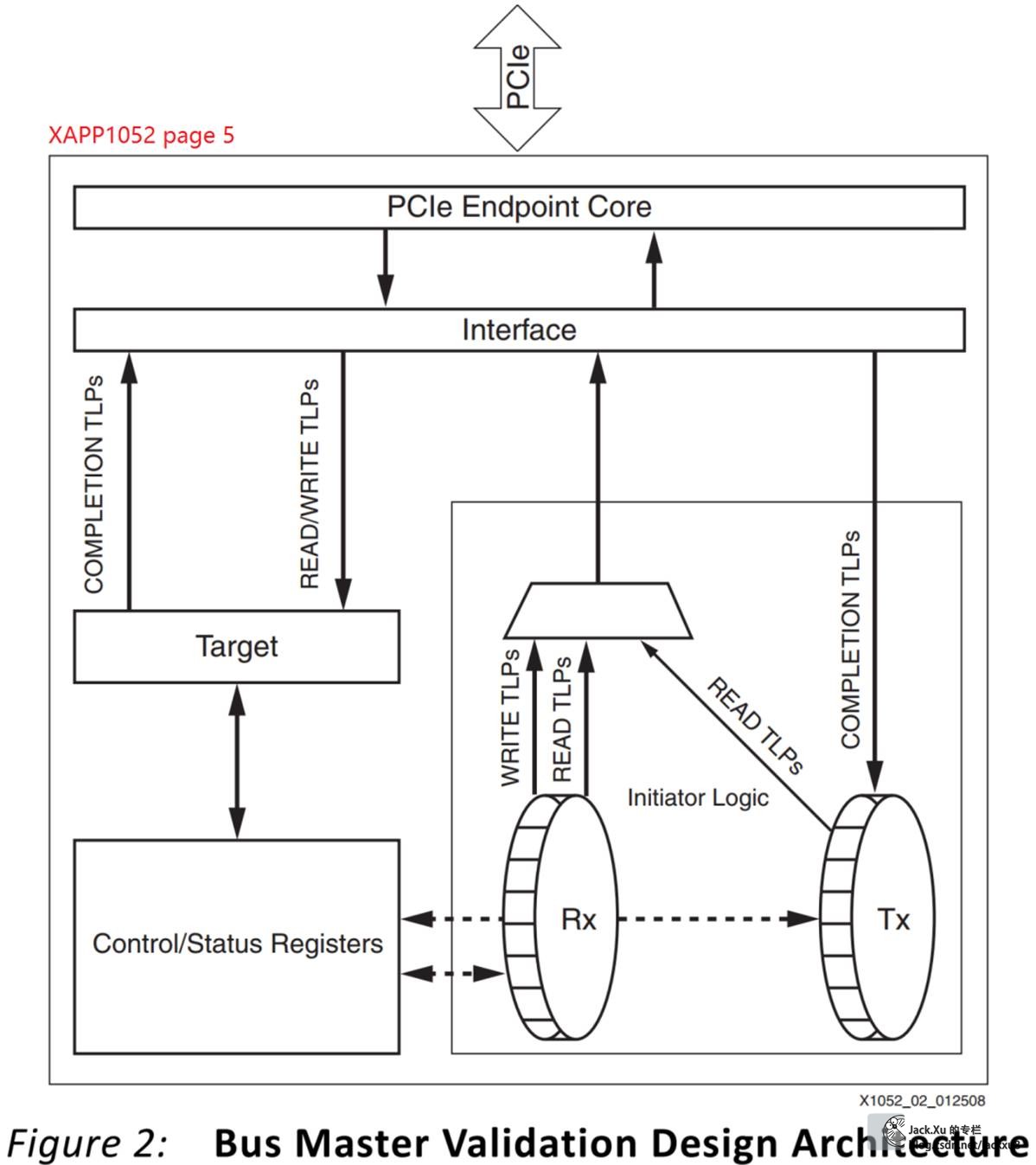
XAPP1052结构
XAPP1052实现了在事务层的总线主控的DMA传输样例,虽然只是提供了收发固定数据的功能,但是为整个事务层的BMD实现提供的良好的参考。
该参考设计的结构如下
pci_exp_64b_app
|
|__BMD
|
|__BMD_EP
| |
| |__BMD_EP_MEM_ACCESS
| | |_BMD_EP_MEM
| |
| |__BMD_RX_ENGINE
| |__BMD_TX_ENGINE
| | |__BMD_INTR_CTRL
| |
| |__BMD_GEN2
| |__BMD_RD_THROTTLE
|
|__BMD_TO_CTRL
|__BMD_CFG_CTRL
其中,
1、TX_ENGINE.v:是产生TLP包的逻辑,包含读TLP请求用于DMA读;写TLP请求用于DMA写;CPLD用于BAR空间读。
2、RX_ENGINE.v:是解析TLP包的逻辑,包含读TLP解析用于BAR空间读、写TLP解析用于BAR空间写、CPLD解析用于DMA读。
这里先简单介绍一下DMA过程:
RT->EPDMA(存储器读):
1、驱动程序向操作系统申请一片物理连续的内存;
2、主机向该地址写入数据;
3、主机将这个内存的物理地址告诉FPGA;
4、FPGA向主机发起读TLP请求—连续发出多个读请求;
5、主机向FPGA返回CPLD包—连续返回多个CPLD;
6、FPGA取出CPLD包中的有效数据;
7、FPGA发送完数据后通过中断等形式通知主机DMA完成;

EP->RTDMA(存储器写):
1、驱动程序向操作系统申请一片物理连续的内存;
2、主机将这个内存的物理地址告诉FPGA;
3、FPGA向主机发起写TLP请求,并将数据放入TLP包中—连续发出多个写请求;
4、FPGA发送完数据后通过中断等形式通知主机DMA完成;
5、主机从内存中获取数据;

系统仿真环境
系统的仿真需要搭建如下一个系统,包括RT(模拟主机端)和我们自己的EP(FPGA)端,并提供相应的时钟和测试激励,系统结构大概如下图所示,只是其中的PIO APP被替换为了咱们的BMD APP
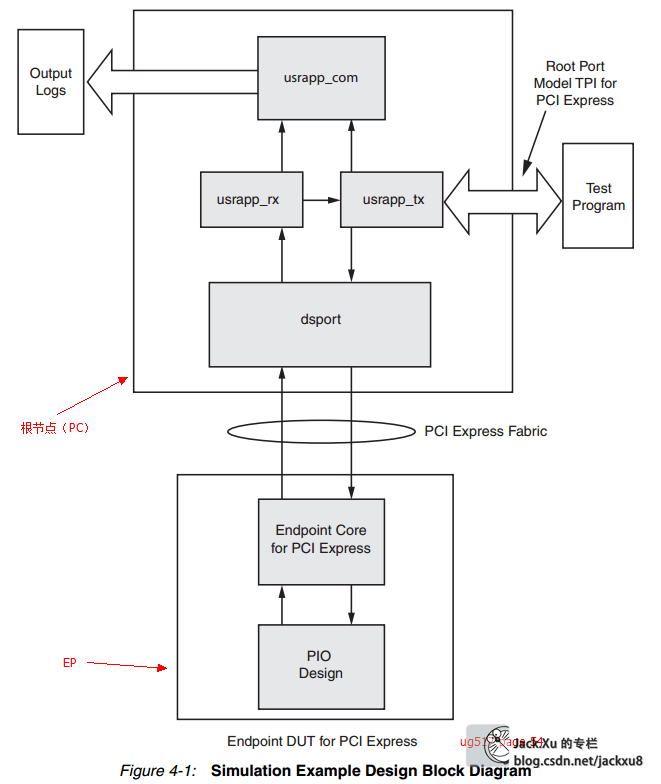
在Vivado下,设置使用Modelsim为仿真工具后,直接使用Vivado的仿真脚本生成功能直接生成的脚本就可以了。

在ISE下,最好是自己书写仿真脚本,注意BMD_PCIE_20.v必须放在最前面编译,完整的仿真脚本可以联系我获取(jackxu8#163.com)。
最后,打开Modelsim软件,更改目录至. . \simulation\functional,输入脚本dosimulate_mti.do 仿真结果如下,

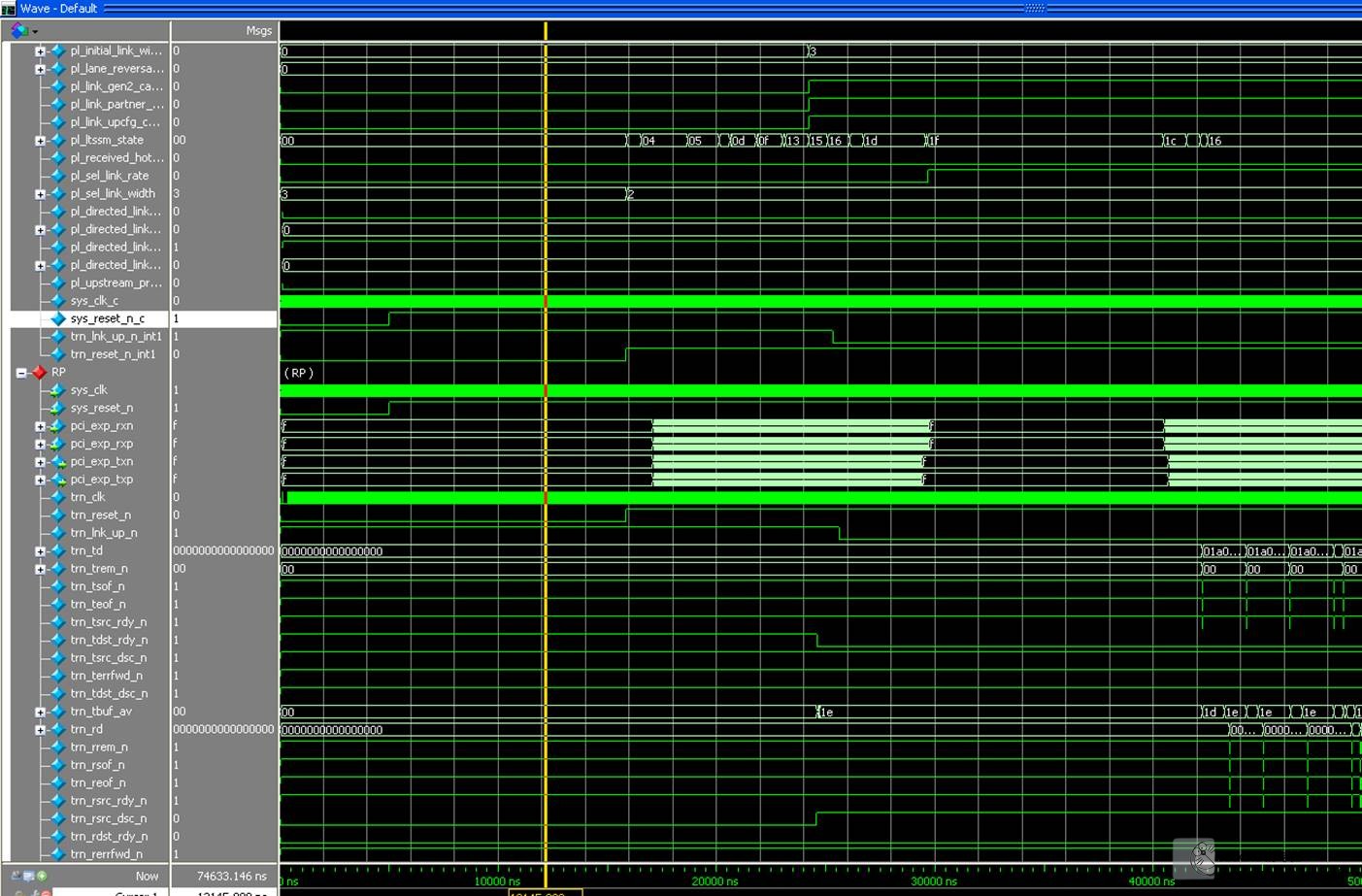
但是XAPP1052没有提供对应的针对DMA的仿真测试脚本,需要我们根据DMA的配置稍后自行书写,详细仿真脚本可以联系我获取(jackxu8#163.com)。
BMD APP设计
万事具备,有了这个环境,我们就可以开始着手修改官方提供的BMD的example,首先这个Example只是用于传输一个固定的pattern,并不能正在的传输用户自己的数据。其次,也不能将接收的数据传输给用户。另外,没有提供用户寄存器和内存传输空间。用户也无法发送自定义的中断。等等这些限制,导致了这个Example只是一个能够用来测试PCIe的DMA传输速度的Example,而不具有实用价值。但是!但是!但是!它提供了很好的基于事务层设计DMA传输的范例,因此,在此基础上修改一个实用的DMA传输控制器将不是什么难事,so, flollow me and make it。
PIO传输
PIO传输就是Programmable IO,通常用于配置寄存器等小数据的传输,一次传输32bit数据。首先需要明确一点,PIO传输都用主机(也就是PC电脑RT端)主动发起,进行一次PIO传输主要需要地址和数据两个参数(TLP包格式参考前面的基础知识)。

那么我们来看一下,这两个参数在BMD的设计中是怎么传递的。
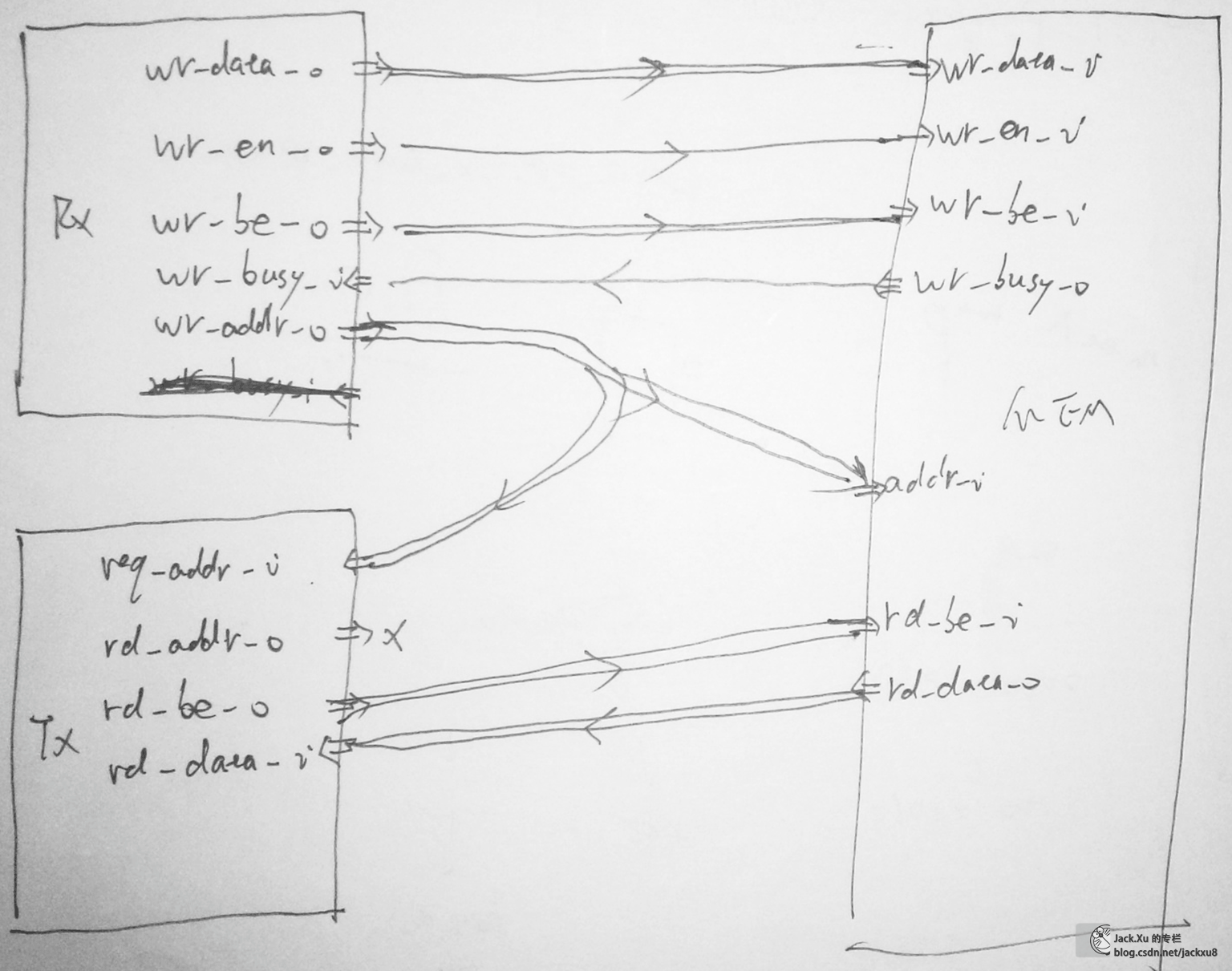
BMD_64_RX_ENGINE.trn_rd[63:0] –> BMD_64_RX_ENGINE.addr_o[10:0]–> BMD_EP.req_addr[10:0] ->BMD_EP_MEM_ACCESS.addr_i[6:0] -> 用于索引寄存器
从这条路径可以看出,BMD接收到RT发过来的地址参数后,将TLP包中解析得到的地址一路送给了BMD_EP_MEM_ACCESS,用来索引对应的寄存器。我们按图索骥,找到BMD_RX_ENGINE.v和BMD_EP_MEM.v中对应的部分,可以发现,不管是存储器写请求(BMD_MEM_WR32_FMT_TYPE)还是存储器读请求(BMD_MEM_RD32_FMT_TYPE)都是RT先发送一个地址下来,索引这个寄存器。

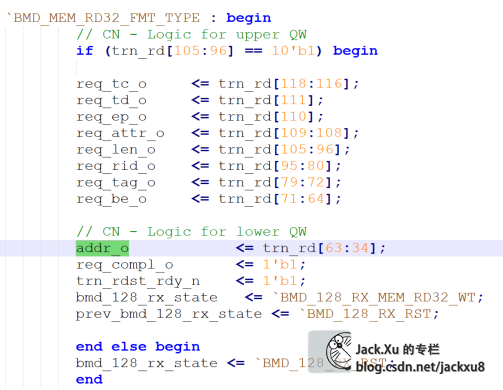
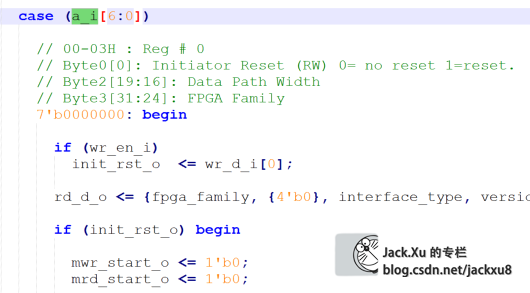
按照这个路子,也就很容易找到数据的传输路径和相应的控制信号了,如上位机写寄存器的数据传输路径如下
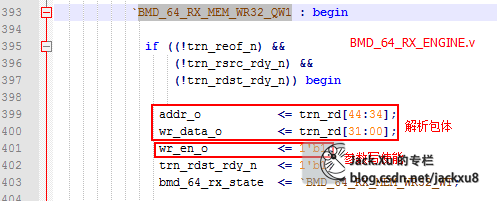
BMD_RX_ENGINE. wr_data_o[31:0] -> BMD_EP_MEM_ACCESS.wr_data_i[31:0]
下面是灵魂画手绘制的容易理解图
存储器读请求
首先我们来看一下存储器读请求
时序
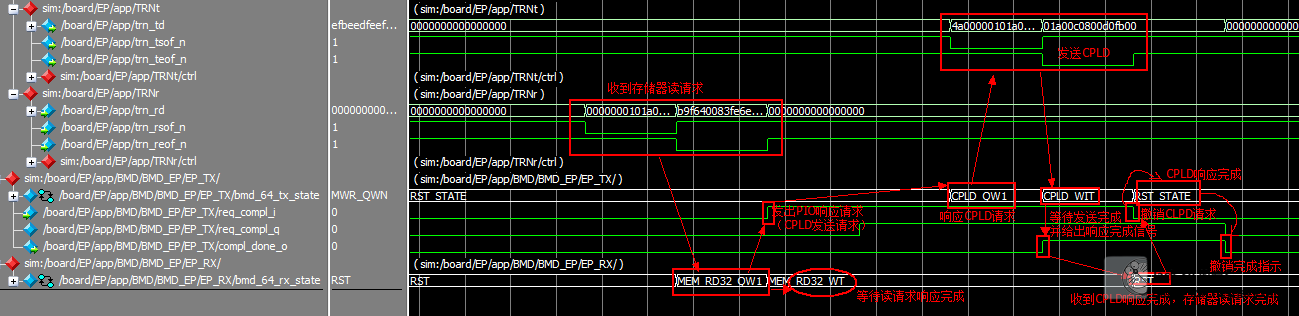
分析
RX_ENGINE
EP_RX模块根据接收trn_rd[62:56]解析包类型
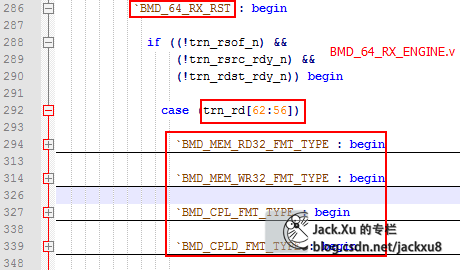
解析包头信息,并跳转到对应的包处理过程
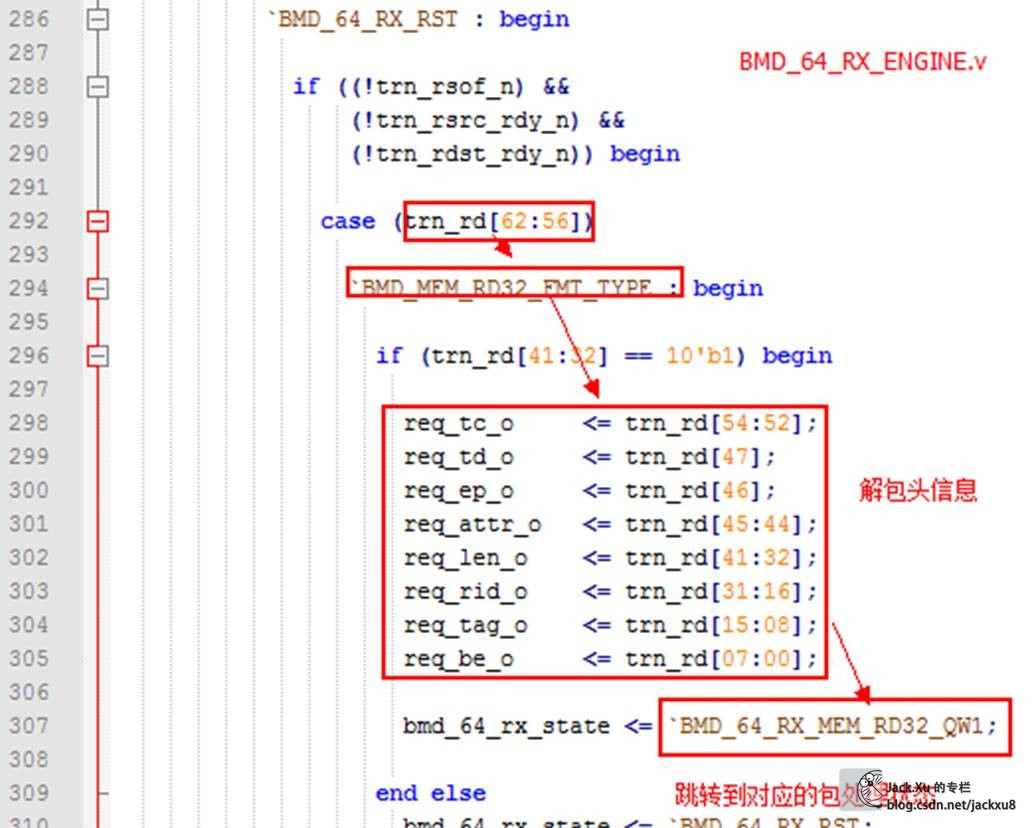
包处理
给出存储器读地址
addr_o -> BMD_EP-> BME_EP_MEM_ACCESS.addr_i -> BMD_EP_MEM. a_i
读出寄存器值
BMD_EP_MEM.rd_d_o->BMD_EP_MEM_ACCESS.mem_rd_data->rd_data_o ->EP_TX. rd_data_i
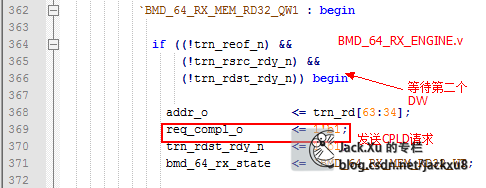
等待CPLD请求响应完成
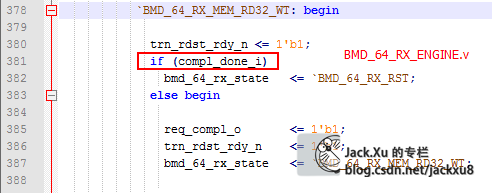
TX_ENGINE
收到CPLD发送请求,根据RX模块发过来的包信息组包头
然后到包体形成状态
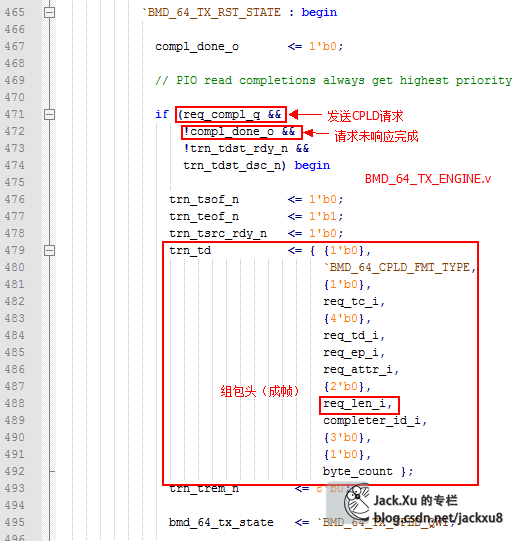
将存储器寄存器值组成包的第二个DW
给出存储器读地址
addr_o -> BMD_EP-> BME_EP_MEM_ACCESS.addr_i -> BMD_EP_MEM. a_i
读出寄存器值
BMD_EP_MEM.rd_d_o->BMD_EP_MEM_ACCESS.mem_rd_data->rd_data_o ->EP_TX. rd_data_i
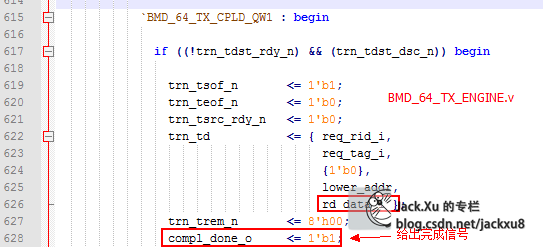
存储器写请求
时序
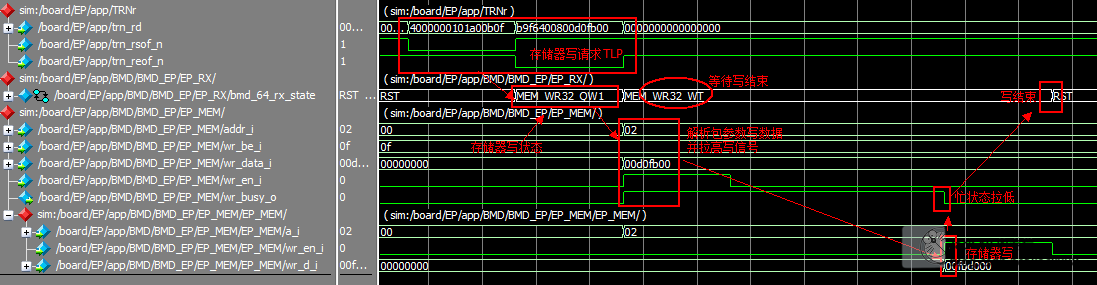
分析
RX_ENGINE
解析包头,并跳转到包体解析状态
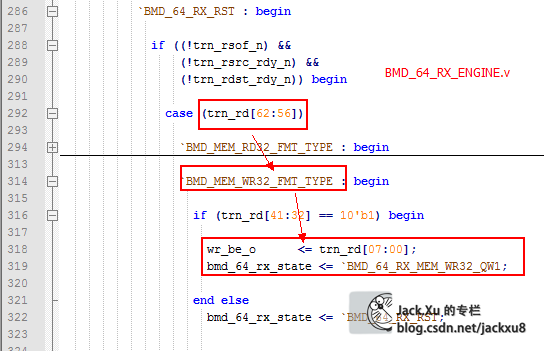
解析包体,获得存储器数据
并产生写使能
EP_RX.wr_en_o -> EP_MEM. wr_en_i
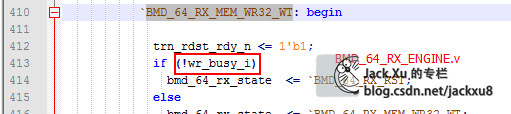
等待存储器忙结束
BMD_EP_MEM_ACCESS
存储器控制遵循读-修改-写过程
时序
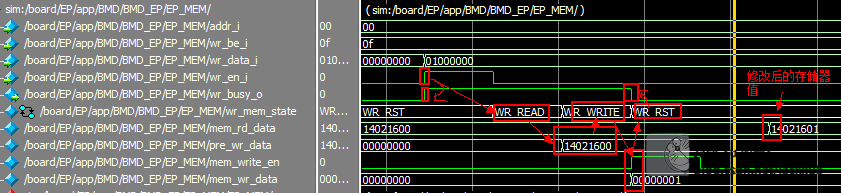
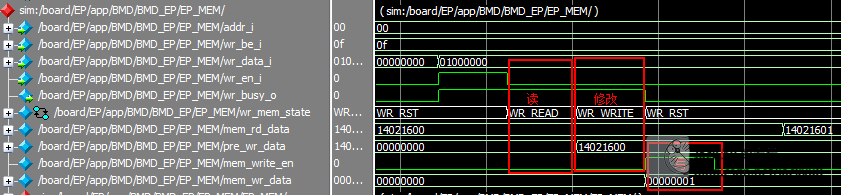
分析
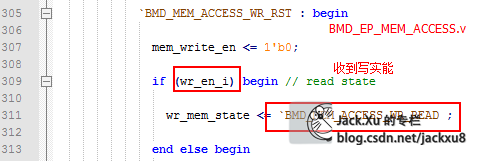
收到写使能,进入写前读状态
拉高存储器忙标志(表示存储器在操作中,非RST状态均在操作中)

读出存储器当前值,预存
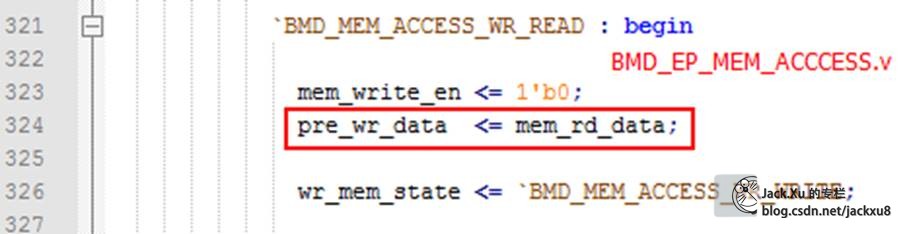
BMD_EP_MEM.rd_d_o -> mem_rd_data
转到修改状态
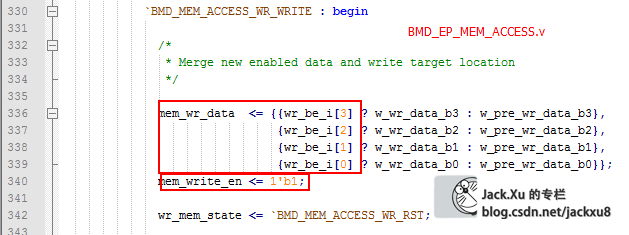
根据be信号(Byte Enable)按Byte修改存储器值
并产生写使能信号
mem_write_en -> BME_EP_MEM.wr_en_i
mem_wr_data -> BME_EP_MEM.wr_d_i
w_wr_data_bx是wr_data_i的Byte划分
w_pre_wr_data_bx是pre_wr_data的Byte划分

cfg_bus_mstr_enable


配置信息流程

配置空间
配置空间总览
PCIe Spec 2.0 v2_0 page 415


Xilinx PCIe core对配置空间寄存器的映射
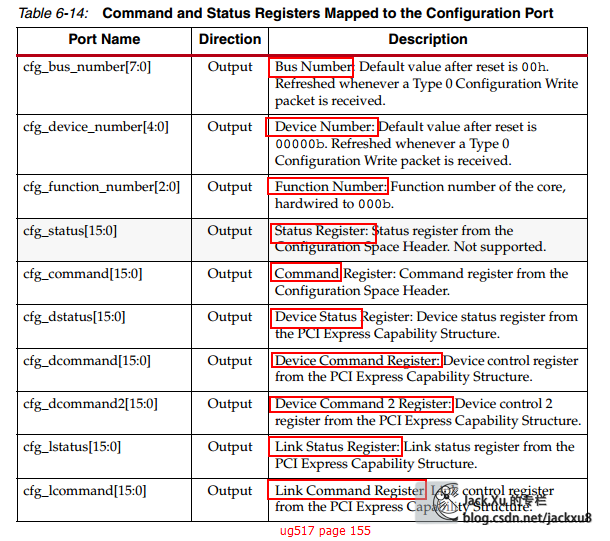
通过Xilinx core配置端口访问配置空间
ug517page162( Accessing Registersthrough the Configuration Port)
地址

使用DW地址
将配置空间地址/4得到cfg端口地址
配置空间地址是byte地址
时序
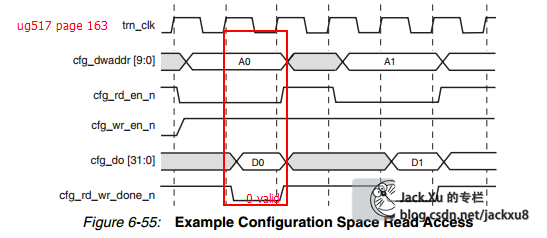
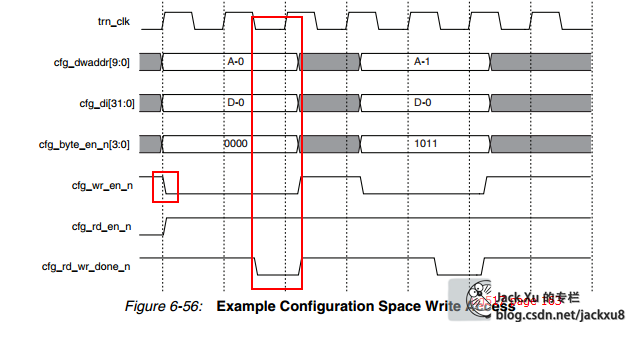
BMD_CFG_CTRL.v



PCIe能力结构体
对应着配置空间的60H~98H
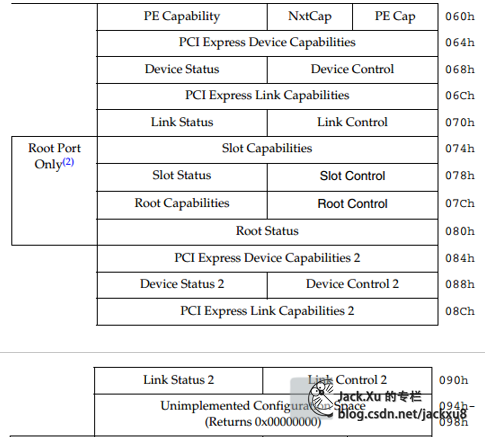
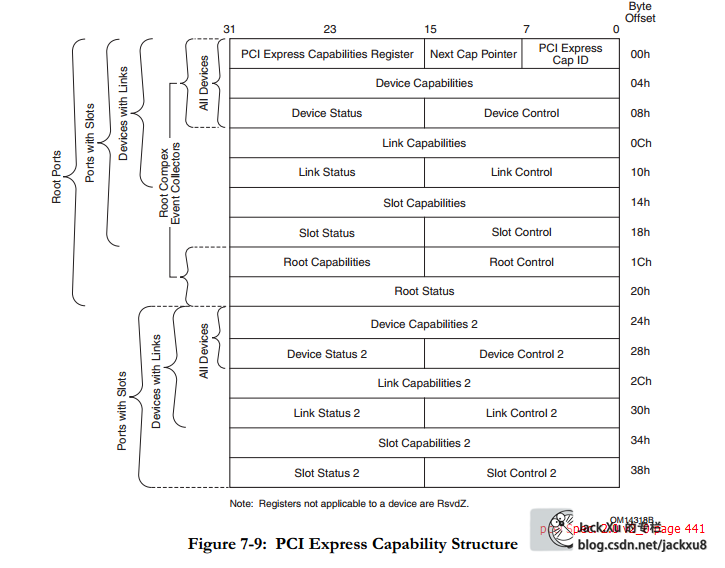
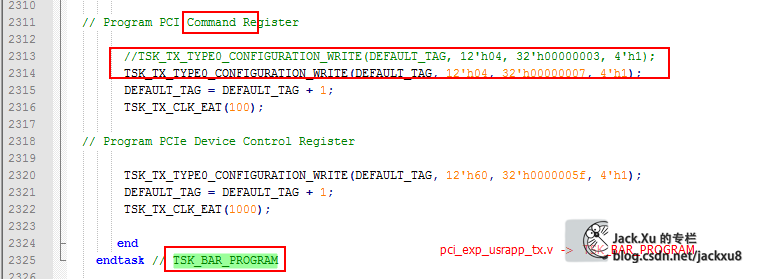
Device Capabilities Register (Offset 04h)
有CORE配置决定
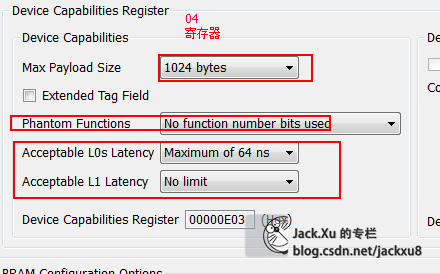


这个值表示这设备的传输能力,由IP核配置
测试
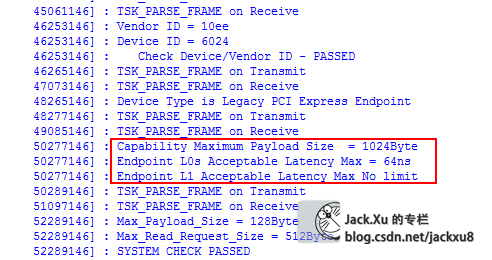
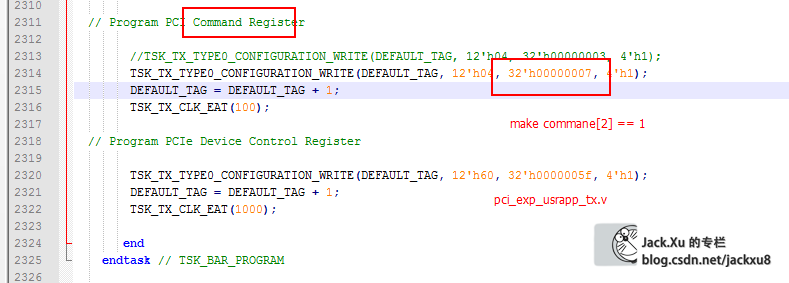
Device Control Register (Offset 08h)
这个寄存器都是可读可写的,用来通过上位机设置硬件设备上的工作能力
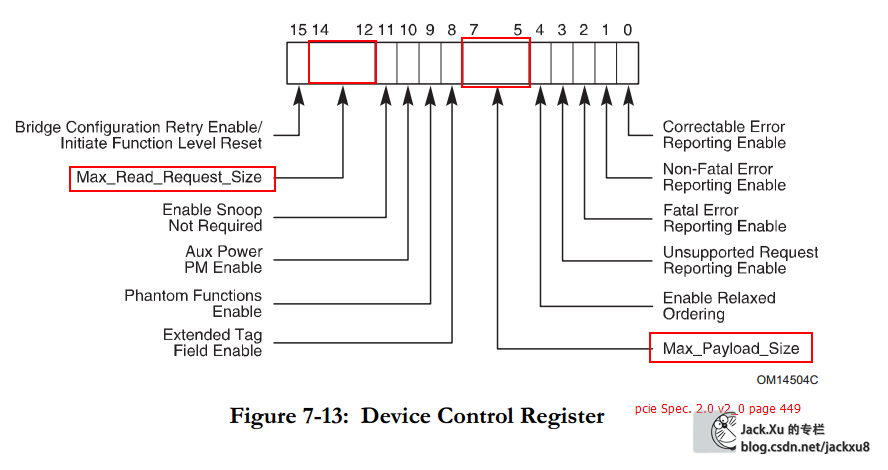


测试
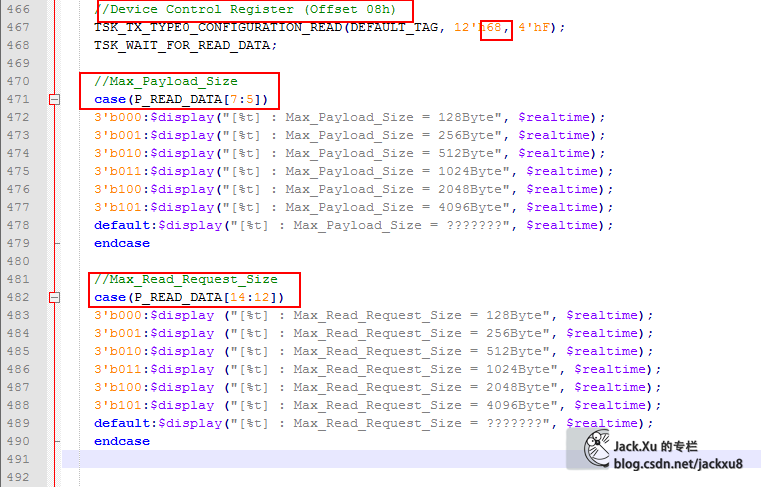
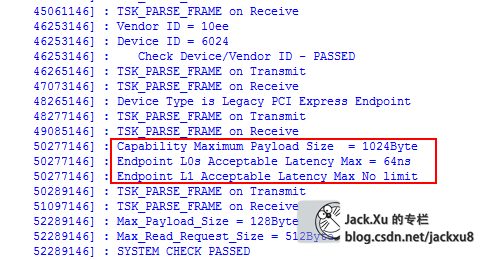
Device Control Register寄存器对应着cfg_dcommand总线



最终传输到40h寄存器
BMD_EP_MEM.v 40H 寄存器
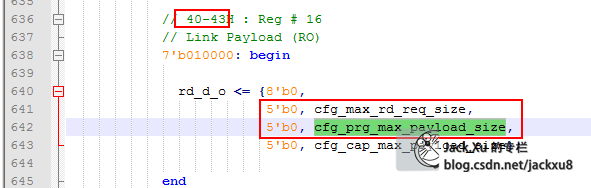

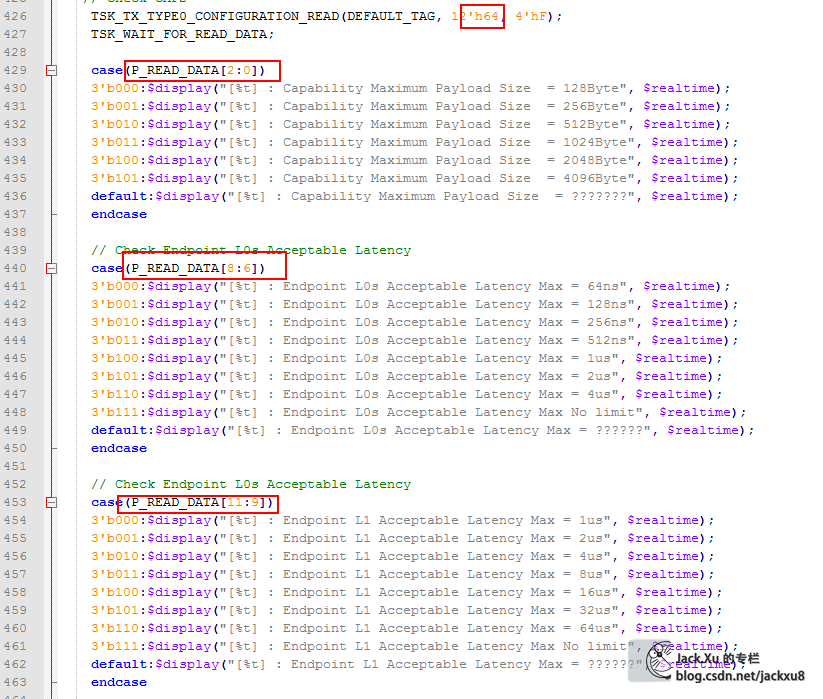
cfg_max_rd_req_size Device Control Register [14:12]
cfg_prg_max_payload_size Device Control Register [7:5]
cfg_cap_max_payload_size Device Capabilities Register [2:0]
帧结构
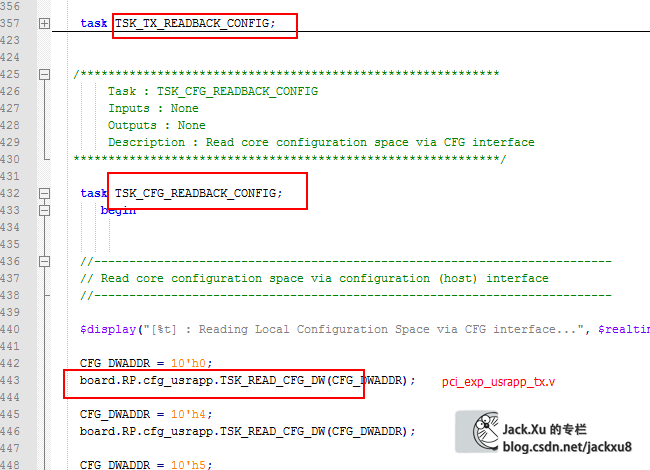
dsport关于配置空间的task
自身配置空间

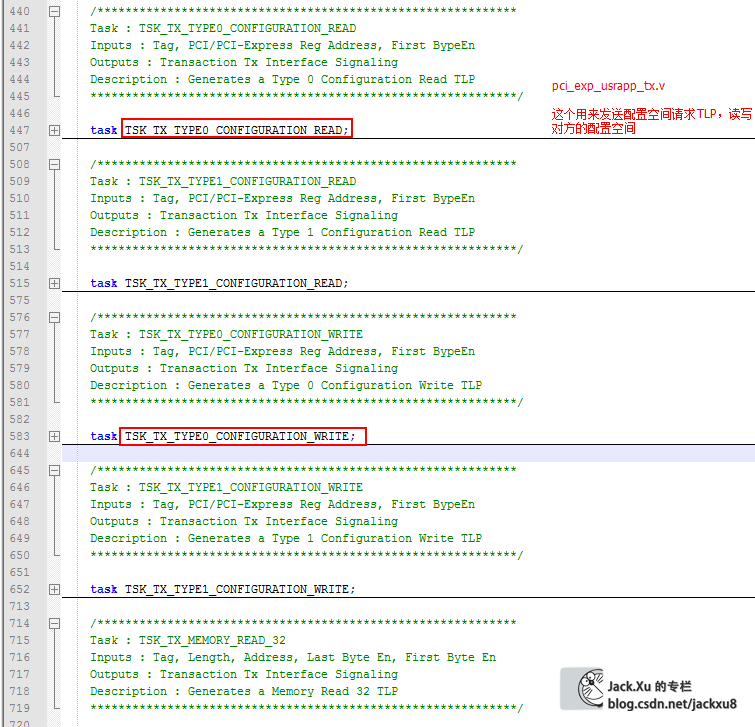
对方配置空间















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









