







一:概括
| 贡献 | (一)构建了第一个人工标注的基于对话的关系抽取数据集,并深入研究了基于对话的关系抽取任务与传统关系抽取任务的异同; (二)设计了一个新的会话评价指标,该指标反映了对话中交互通信的及时性; (三)利用标准的基于学习的技术在Dialogre上建立了一组基线关系抽取结果,进一步证明了说话人论据的明确识别在基于对话的关系抽取中的重要性。 | |
| 构建了第一个人工标注的基于对话的关系抽取数据集, | 语料库 表1表2 | 语料库:Friends的完整抄本,该语料库近年来在对话研究中得到了广泛应用(Catizone et al.,2010;Chen and Choi,2016;Chen et al.,2017;Zhou and Choi,2018;Rashid and Blanco,2018;Yang and Choi,2019)。 |
| 标注
|
| |
| 基于对话的关系抽取任务与传统关系抽取任务的异同 | 表1 | |
| (二)设计了一个新的会话评价指标,该指标反映了对话中交互通信的及时性; | 对比传统关系抽取方法,为了鼓励自动方法尽早识别对话中两个参数之间的关系——设计了一个新的会话环境性能评价指标,该指标可以作为标准F1指标(第4.1节)的补充
| |
| (三)利用标准的基于学习的技术在Dialogre上建立了一组基线关系抽取结果,进一步证明了说话人论据的明确识别在基于对话的关系抽取中的重要性。 |  | |
| 模型 |
| |
| 结论 |
| |

| 任务比较 | 基于对话的关系抽取任务 | 传统的关系抽取任务 | 对比以前的工作 |
| 概念 | (实时):应用程序(聊天机器人);需要在交互式会话中第一次提到关系时识别它——需要更快速 | 传统关系抽取方法:阅读完整个文档后才输出一组关系,并且可以自由地依赖于一个关系在整个文本中的多次提及来确认它的存在。 | 大多数以前的工作直接将现有的关系抽取系统应用于对话,而没有明确考虑涉及的说话人 |
| 评价指标 | 为了鼓励自动方法尽早识别对话中两个参数之间的关系——设计了一个新的会话环境性能评价指标,该指标可以作为标准F1指标(第4.1节)的补充 |
表1(上图)
| Dialogre | SF | |
| 数据集比较 | 基于对话的数据集 | 传统的人工标注的关系抽取数据集 |
| Dialogre中47.2%的关系类型源于SF关系类型,其中包含基本真理关系三元组的92.2%的源文件是正式撰写的新闻报道(72.8%)或经过精心编辑的Web文档(19.4%),而其余的文件则来自讨论论坛。新关系类型 | ||
| 参数类型比较 | 基于预定义的SF和Dialogre关系类型,主语应该是per、org或geo-political实体(GPE)类型的实体。 | |
| 大多数关系三元组(96.8%)的主语都是人名。 | 关系三元组(69.7%)的主语都是人名。 | |
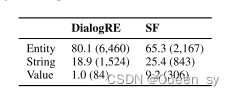
| 粗粒度的对象类型是实体、字符串或值(即数值或日期) | 实体的比例(80.1%) | SF(65.3%) |
 | ||
| 特别是,77.3%的关系三元组的主题是说话人名称,超过90.0%的关系三元组包含至少一个说话人参数。在“对话”中,“以说话者为中心”的关系三元组比例高,而“ORG”和“GPE”论点的比例低, | ||
| 参数距离比较 | 短 | 长 |
| 计算两个参数之间的精确距离 比较 | 在对话中计算两个参数之间的精确距离并不是一件小事,尤其是在包含说话人名称的参数的情况下。且要考虑两种类型的距离。(例如,平均距离和最小距离)。 | |
| 参数对之间的距离的难度 比较 | Dialogre表现出与SF相似的难度水平。即使考虑到最小距离,41.3%的论据被至少7个词分隔,考虑到平均距离,这一比例可以达到96.5%, | SF (Huang et al., 2017)和最近发布的跨句关系提取数据集DocRED中,这一比例分别为46.0%和59.8% |
| 带触发器的参数对之间的平均距离比不带更长 | ||
表2(上图)
| 三元组比较 | Dialogre标注的三元组 | 现有关系三元组 |
| 我们删除了与内容无关的关系类型的三元组。93.8%的关系类型可以映射到我们的关系模式中的36种关系类型中的一种——说明我们用于注释的关系模式能够覆盖百科社区贡献者标记的大部分重要关系类型。 | 一本合作百科全书中收集了2341个与朋友有关的关系三元组,这些关系三元组是由一个贡献者社区总结的。 | |
| 另一方面,对话式中现存的三元组数量相对较少,而我们注释的三元组规模适中,这可能表明会话中的关系抽取信息密度较低(Wang and Liu,2011)。 | ||
| 例如,Dialogre中每个句子平均注释三次仅为0.21,而其他详尽注释的数据集ACE(0.73)和Knowledgenet(Mesquita et al.,2019)(1.44),其中的语料库分别是正式的书面新闻报道和维基百科文章。 |
表3(上图)
二、词语解释
1、Dialogue-Based Relation Extraction
文章提出了第一个基于人类注释的基于对话的关系提取(RE)数据集DialogRE,旨在支持在对话中出现的两个参数之间的关系预测。进一步提供DialogRE作为研究跨句RE的平台,因为大多数事实跨越多个句子。基于对话的RE任务与传统的RE任务之间的异同分析表明,与说话人相关的信息在所提出的任务中起着至关重要的作用。 考虑到对话中沟通的及时性,论文设计了一种新的度量来评估RE方法在会话环境中的性能,并研究了几种具有代表性的RE方法在DialogRE上的性能。实验结果表明,在最佳性能模型上的说话人信息扩展可以在标准和会话评估设置中获得更好的表现。
2、注释触发器
注解了它的触发:对话中连续文本的最小范围(即,跨度),最清楚地表明两个论点之间的关系的存在。1、如果存在多个span可以作为触发器,我们只为每个三元组保留一个;2、对于像PER:TITLE和PER:ALTERNATE NAMES这样的关系类型,很难识别这样的支持上下文,因此我们让它们的触发器为空;3、对于每个关系三元组,如果模式中存在对应的逆关系类型(例如PER:CHILDREN和PER:PARENTS),而触发器保持不变,则注释其逆三元组。
我们还注释了最清楚地表达关系的最小相邻文本跨度;这可能使研究人员能够探索提供细粒度解释和证据语句的关系提取方法。
3.3关于触发器作为注释触发器的讨论在现有关系抽取数据集中很少可用(Aguilar et al.,2014),不同关系类型与触发器存在之间的联系研究不足。 关系类型:在Dialogre中,49.6%的关系三元组都用触发器注释。 我们发现,当(1)争论类型相同,如Per:朋友,(2)涉及强烈的情感(如Per:积极(消极)印象),或(3)关系类型与死亡或出生有关(如GPE:在位出生)时,争论对经常伴随触发因素。 相比之下,两个不同类型的参数(例如,PER:Origin和PER:AGE)之间的关系更有可能被隐含地表达出来,而不是依赖于触发器。 这可能是因为与相同类型的参数相比,这样的参数对之间可能存在的关系更少,这样的参数对之间相对较短的距离可能足以帮助听者正确理解消息。 对于每种关系类型,我们在表2中报告带有触发器的关系三元组的百分比。 参数距离:我们假设触发器的存在可能允许文本中参数对之间有更长的距离,因为它们有助于减少歧义。
3、关注标注关系三元组
(subject, relation type, object),其中至少一个参数是命名实体,认为一个人的讲话不会断,并且这个人的名字作为一个turn
当我们遵循TAC-KBP指南来注释关系类型并设计新类型时,我们使用熟悉此任务的内部注释者(本文的两位作者)。对于实验性注释,注释者A
注释所有剧本中每个场景关系三元组,通过提取最短的连续turns片段,该片段能覆盖该场景中所有带注释的关系三元组和足够支持的上下文来形成对话。在注释过程中会调整准则。如果speaker名称的相应全名或替代名称也出现在同一对话框中,我们更喜欢使用speaker名称(即转弯的第一个单词或短语,后跟冒号)作为speaker相关三元组的一个参数,除了关系PER:ALTERNATE NAMES以外,在该关系中两个提及都应该视为参数,对于一个argument对((subject,object)),可能存在多重关系,我们对其所有实例进行标注,对于每个三元组,我们也同时标注了其trigger(对话中连续文本的最小范围(即跨度),最清楚地表明两个自变量之间存在关系。 如果存在多个跨度可以保存为triggers,但是只保存一个对于每个三元组)。
对于关系类型PER:TITLE and PER:ALTERNATE NAMES等难以辨识其支持的上下文,我们就令trigger为空。对于每个关系三元组,我们标注了其逆三元组(inverse triple)如果模式中存在其对应的逆向关系类型(e.g., PER:CHILDREN and PER:PARENTS),trigger保持不变。
4、模型berts
berts![]() https://blog.csdn.net/Ming_Fan1/article/details/109168016
https://blog.csdn.net/Ming_Fan1/article/details/109168016















 1180
1180











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









