







挖掘建模分:分类与预测、聚类分析、关联规则、时序模式等模型。
分类与预测是预测问题的两种主要类型,分类主要是:预测分类标号(离散属性);预测主要是:建立连续值函数模型,预测给定自变量对应的因变量的值。
1.分类与预测
1.1 实现过程
(1)分类
分类是构造一个分类模型,输入样本属性值,输出对应类别,将每个样本映射到预先定义好的类别。
分类模型,建立在已有类标记的数据集上,因此,属于“有监督学习”
(2)预测
预测,指建立两种或两种以上变量间相互依赖的函数模型,进行预测或控制
(3)实现过程
分类算法:
a:学习步,通过归纳分析训练样本集建立分类模型得到分类规则;
b:分类步,先用已知的测试样本集,评估分类规则的准确率
预测模型:
a:通过训练集建立预测属性的函数模型
b:在模型通过检验后进行预测或控制
1.2 常用分类与预测算法
| 算法名称 | 算法描述 |
| 回归分析 | 回归分析,确定预测属性与其他变量间相互依赖的定量关系。包括:线性回归、非线性回归、Logistic回归、岭回归、主成分回归、偏最小二乘回归等模型 |
| 决策树 | 决策树采用自顶向下的递归方式,在内部节点进行属性值比较,并根据不同的属性值从该节点向下分支,最终得到的叶节点是学习划分的类 |
| 人工神经网络 | 人工神经网络是一种模仿大脑神经网络结构和功能而建立的信息处理系统,表示神经网络的输入与输出变量之间关系的模型 |
| 贝叶斯网络 | 贝叶斯网络又称信度网络,是Bayes方法的扩展,是目前不确定知识表达和推理领域最有效的理论模型之一 |
| 支持向量机 | 支持向量机是一种通过某种非线性映射,把低维的非线性可分转化为高维的线性可分,在高维空间进行线性分析的算法 |
1.3 回归分析
| 回归模型名称 | 适用条件 | 算法描述 |
| 线性回归 | 因变量与自变量是线性关系 | 对一个或多个自变量和因变量间的线性关系进行建模,可用最小二乘法求解模型系数 |
| 非线性回归 | 因变量与自变量间不都是线性关系 | 对一个或多个自变量和因变量间的非线性关系进行建模。若非线性关系可通过简单的函数变换转化成线性关系,用线性回归的思想求解,若不能转化,用非线性最小二乘法求解 |
| Logistic回归 | 因变量一般有1和0(是、否)两种取值 | 广义线性回归模型的特例,利用Logistic函数将因变量的取值范围控制在0、1之间,表示取值为1的概率 |
| 岭回归 | 参与建模的自变量间具有多重共线性 | 是一种改进最小二乘估计的方法 |
| 主成分回归 | 参与建模的自变量间具有多重共线性 | 主成分回归是根据主成分分析的思想提出的,是对最小二乘法的改进,它是参数估计的一种有偏估计。可消除自变量间的多重共线性 |
1.4 决策树
决策树是一种树状结构,它的每一个叶节点对应着一个分类,非叶节点对应着在某个属性上的划分,根据样本在该属性不同取值将其划分为若干个子集。
决策树构造的核心问题:在每一步如何选择适当的属性对样本做拆分。
决策树处理过程:对分类问题,应从已知类标记的训练样本中学习并构造出决策树,自上而下,分开进行解决。
| 决策树算法 | 算法描述 |
| ID3算法 | 核心:在决策树的各级节点上,使用信息增益方法作为属性的选择标准,来帮助确定生成每个节点时所应采用的合适属性。 |
| C4.5算法 | C4.5决策树生成算法相对于ID3算法的重要改进:使用信息增益率来选择节点属性。C4.5可客服ID3算法的不足:ID3算法只适用于离散的描述属性,而C4.5算法既能处理离散的描述属性,也可处理连续的描述属性 |
| CART算法 | CART决策树是一种非参数分类和回归方法,通过构建树、修剪树、评估树来构造一个二叉树。当终结点是连续变量时,该树为回归树;当终结点是分类变量,该树为分类树 |
1.5 人工神经网络
人工神经网络:模拟生物神经网络进行信息处理的一种数学模型。
人工神经网络的学习也称为训练,指的是:神经网络在受到外部环境的刺激下调整神经网络的参数,使神经网络以一种新的方式对外部环境做出反应的一个过程。
分类预测时,人工神经网络主要使用有指导的学习方式,即根据给定的训练样本调整人工神经网络参数使网络输出接近于已知的样本类标记或其他形式的因变量。
分类预测时,常用的算法是:误差校正学习算法
误差校正算法,根据神经网络的输出误差对神经元的连接强度进行修正,属于有指导学习。
设神经网络中神经元i作为输入,神经元j为输出神经元,它们的连接权值为wij,则对权值的修正为△wij=ηδjYi,其中η为学习率,δj=Tj-Yj为j的偏差,即输出神经元j的实际输出和教师信号之差。
神经网络训练是否完成通过误差函数E衡量。当误差函数小于某个设定值时,停止神经网络训练。
误差函数计算:
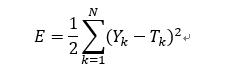
,N为训练样本个数。
人工神经网络算法
| 算法名称 | 算法描述 |
| BP神经网络 | 一种按误差逆传播算法训练的多层前馈网络,学习算法是:误差校正学习算法 |
| LM神经网络 | 基于梯度下降法和 |
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









