







一、什么是大模型?
大模型是指具有数千万甚至数亿参数的深度学习模型。近年来,随着计算机技术和大数据的快速发展,深度学习在各个领域取得了显著的成果,如自然语言处理,图片生成,工业数字化等。为了提高模型的性能,研究者们不断尝试增加模型的参数数量,从而诞生了大模型这一概念。本文讨论的大模型将以平时指向比较多的大语言模型为例来进行相关介绍。
大模型的原理是基于深度学习,它利用大量的数据和计算资源来训练具有大量参数的神经网络模型。通过不断地调整模型参数,使得模型能够在各种任务中取得最佳表现。通常说的大模型的“大”的特点体现在:参数数量庞大、训练数据量大、计算资源需求高等。很多先进的模型由于拥有很“大”的特点,使得模型参数越来越多,泛化性能越来越好,在各种专门的领域输出结果也越来越准确。
一个基本架构,三种形式:
当前流行的大模型的网络架构其实并没有很多新的技术,还是一直沿用当前NLP领域最热门最有效的架构——Transformer结构。相比于传统的循环神经网络(RNN)和长短时记忆网络(LSTM),Transformer具有独特的注意力机制(Attention),这相当于给模型加强理解力,对更重要的词能给予更多关注,同时该机制具有更好的并行性和扩展性,能够处理更长的序列,立马成为NLP领域具有奠基性能力的模型,在各类文本相关的序列任务中取得不错的效果。
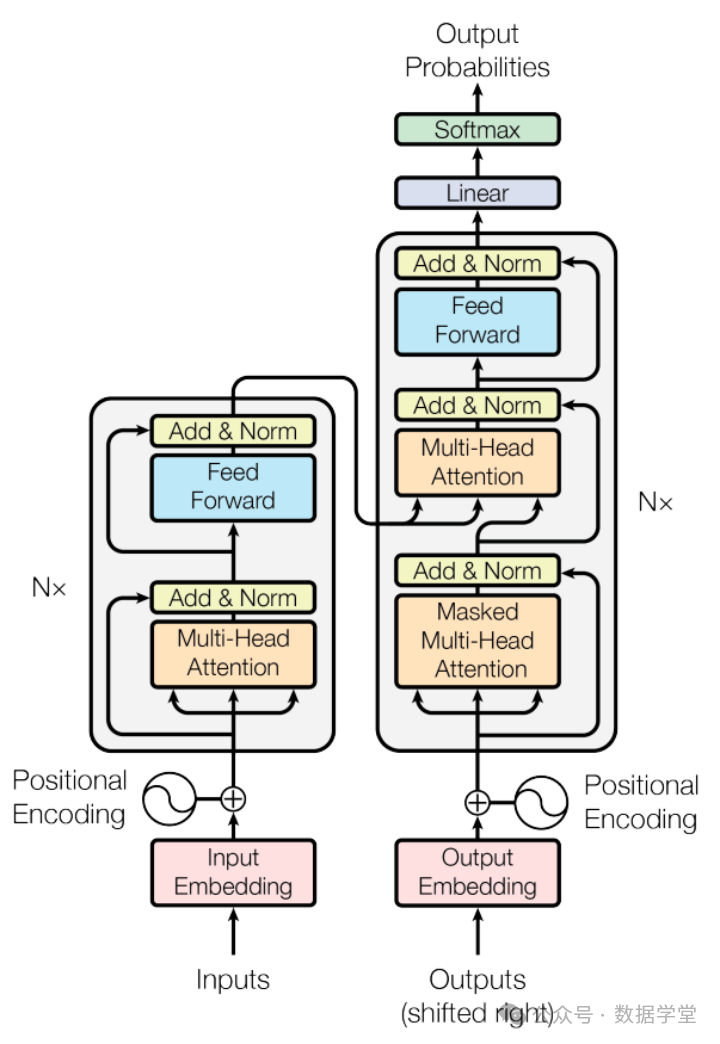
根据这种网络架构的变形,主流的框架可以分为Encoder-Decoder, Encoder-Only和Decoder-Only,其中:
1)Encoder-Only,仅包含编码器部分,主要适用于不需要生成序列的任务,只需要对输入进行编码和处理的单向任务场景,如文本分类、情感分析等,这类代表是BERT相关的模型,例如BERT,RoBERT,ALBERT等
2)Encoder-Decoder,既包含编码器也包含解码器,通常用于序列到序列(Seq2Seq)任务,如机器翻译、对话生成等,这类代表是以Google训出来T5为代表相关大模型。
3)Decoder-Only,仅包含解码器部分,通常用于序列生成任务,如文本生成、机器翻译等。这类结构的模型适用于需要生成序列的任务,可以从输入的编码中生成相应的序列。同时还有一个重要特点是可以进行无监督预训练。在预训练阶段,模型通过大量的无标注数据学习语言的统计模式和语义信息。这种方法可以使得模型具备广泛的语言知识和理解能力。在预训练之后,模型可以进行有监督微调,用于特定的下游任务(如机器翻译、文本生成等)。这类结构的代表也就是我们平时非常熟悉的GPT模型的结构,所有该家族的网络结构都是基于Decoder-Only的形式来逐步演化。
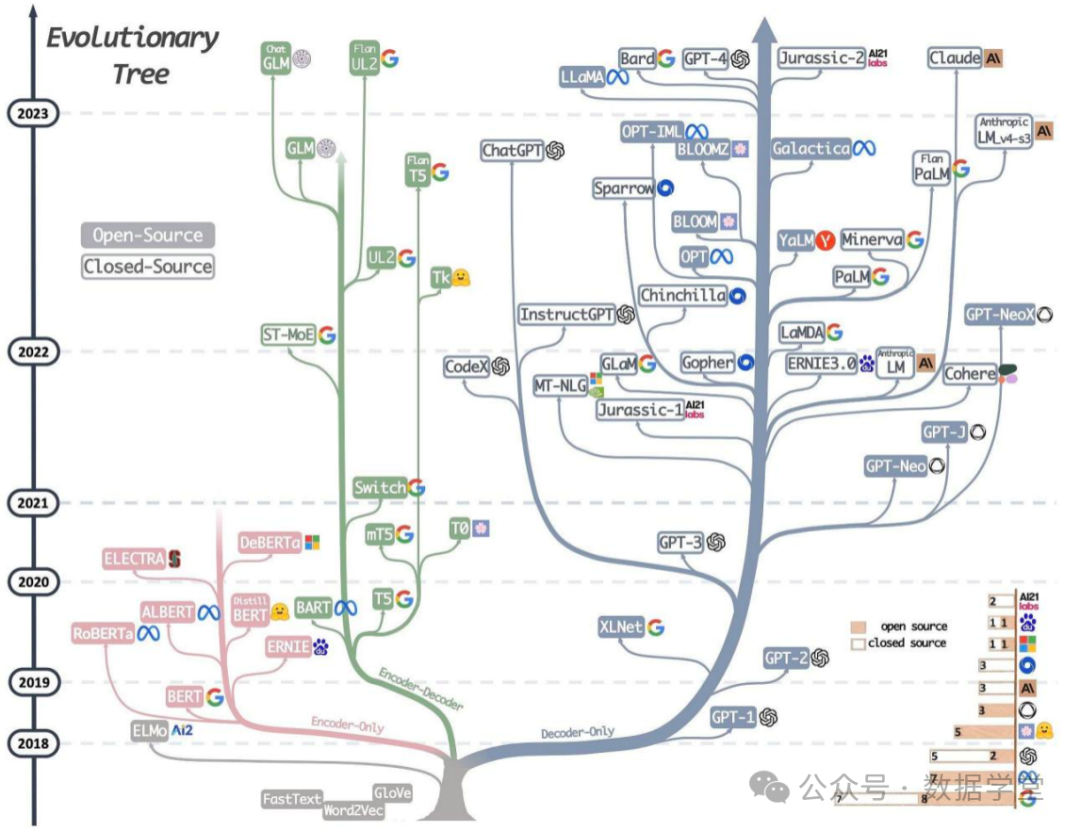
可以看到,很多NLP任务可能可以通过多种网络结果来解决,这也主要是因为NLP领域的任务和数据的多样性和复杂性,以及现代深度学习模型的灵活性和泛化能力,具体哪种结构有效,一般需要根据具体场景和数据,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 439
439

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









