










常说的拒绝推断(Inference methods),通常是指通过数据分析方法修正模型的参数估计偏差。拒绝推断的主要意义是希望修正建模样本和实际全量样本之间的差异,本质上是为了降低模型参数估计的偏差。
拒绝推断场景下有如下三个概念。
- 已知好坏标签(Know Good Bad,KGB)样本:准入模型允许通 过的样本集,已知标签。由KGB样本训练的模型又叫KGB模型。
- 未知标签(Inferred Good Bad,IGB)拒绝样本:准入模型拒绝 的样本集,未知标签。由于IGB样本没有标签,通常不会用于训练模型。在部分方法中可能会生成伪标签,从而参与建模过程。 ·
- 全量(All Good Bad,AGB)样本:包含KGB和IGB两部分的全 量样本集。由该部分数据训练得到的模型又称AGB模型。
一种常见的思路是,直接使用KGB模型在拒绝样本上做预测,并将低分样本(如分数最低的20%样本)认为是负样本,带入模型进行估 计,其余拒绝样本全部视为灰色样本,不予考虑。这种推断方法就叫作硬截断法(Hard Cutoff)。硬截断法假设“逾期”与“放款”之间相互独立。
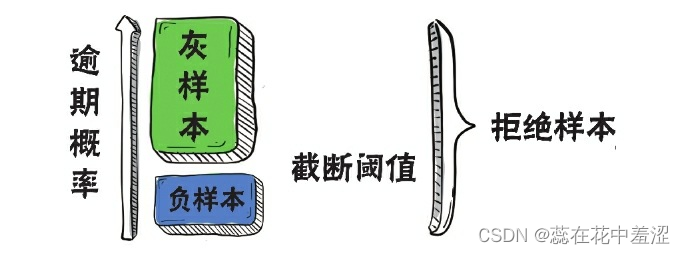
利用KGB模型进行打分,按照逾期概率降序排列,选择截断点 (cut-off)进行截断后,仅将截断点以下的蓝色部分作为负样本带入模 型进行学习,从而修正模型的偏差。 接下来我们通过一个申请评分卡的例子,看看如何在Python中实现基于数据技巧的拒绝推断。
首先加载相关库和数据。

根据KGB数据训练KGB模型。
 简单实现硬截断法。
简单实现硬截断法。

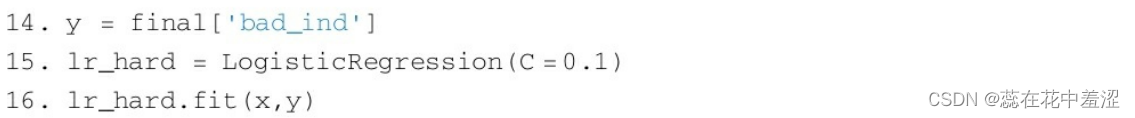
相比于KGB样本,IGB客群的负样本占比更大。低分IGB样本的负样本占比相比于IGB客群也会更大,但仍有部分样本的真实标签应为正样本。在对精度较为敏感的风控系统中,硬截断法显然是不合理的。因此在实际项目中,通常使用多个差异化较大的模型进行交叉筛选,将多模型评分均较低的样本作为负样本。
由差异较大的多个模型组合进行判断,如分别使用逻辑回归模型、决策树模型进行投票或加权平均,可以有效减少误判的概率。















 786
786

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









