






基于规则指导的知识图谱推理协作代理学习

摘要
基于 行走模型 是通过在提供可解释决策的同时实现良好的性能,在知识图(KG)推理中显示了其优势。
然而,KG在行走过程中提供的稀疏信号通常不足以指导复杂的基于行走的强化学习(Reinforcement learning RL)模型。
行走(walk)模型
是一种用于学习图形嵌入(graph embedding)的方法,图形嵌入是将图形中的节点映射到低维向量空间中的过程。走路模型通过模拟在图形中“走路”来学习节点之间的关系,从而为每个节点分配一个嵌入向量。这些嵌入向量可以用于许多图形分析任务,如节点分类、链路预测和社区检测等。
在走路模型中,我们首先选择一个起始节点,然后从该节点开始在图形中随机游走。在每一步中,我们根据一定的概率选择一个相邻的节点,并将其添加到我们的“走路路径”中。最终,我们得到了一个包含许多节点的路径。我们可以使用这些路径来学习节点之间的关系,并将每个节点映射到一个嵌入向量。
另一种方法是使用传统的符号方法(例如,规则推理),这种方法取得了良好的性能,但由于符号表示的复杂性,很难推广。
在本文中,我们提出了RuleGuider,它利用基于符号的方法生成的高质量规则 来为基于行走的代理提供奖励监督。
在基准数据集上的实验表明,RuleGuider在不损失可解释性的情况下提高了基于行走的模型的性能。
介绍
虽然知识图谱在自然语言处理应用中被广泛采用,但阻碍其使用的一个主要瓶颈是 数据稀疏, 导致了对KG完成(或推理)的广泛研究。许多关于KG推理任务的传统方法都是基于逻辑规则的。这些方法被称为基于符号的方法。尽管它们表现出了良好的性能,但它们本质上受到给定规则的关联关系的表示和可推广性的限制。
在知识图谱中,数据稀疏通常指的是图中存在很多实体、属性或关系没有被完整地收录或描述的情况。具体来说,数据稀疏可能表现为以下两种情况:
实体或属性缺失:知识图谱中可能存在很多实体或属性没有被完整地描述或收录,例如某些实体的属性值缺失、某些实体本身没有被收录等情况。
关系缺失:知识图谱中可能存在很多实体之间的关系没有被完整地描述或收录,例如某些实体之间的关系没有被标注、某些关系类型没有被收录等情况。
为了改善这种限制,基于嵌入的方法被提出了。他们学习实体和关系的分布式表示,并使用表示进行预测。尽管它们有着卓越的性能,但却无法做出人性化的诠释。
为了提高解释性,最近的许多研究使用强化学习(RL)技术将任务表述为 多跳推理 问题,称为基于行走的方法。这些方法的一个主要问题是奖励函数。一个“命中与否”的奖励过于稀疏,而使用基于嵌入的距离测量的成形奖励可能并不总是产生理想的路径。
多跳推理(multi-hop reasoning)
是一种常见的人工智能技术,用于通过多步推理来回答自然语言问题。在多跳推理中,系统需要从给定的文本中推导出一系列逻辑关系,以回答问题。
例如,考虑以下问题:“谁是美国第一位总统?”为了回答这个问题,系统可能需要进行以下多跳推理:
美国有总统。
第一位总统是谁?
第一位总统是乔治·华盛顿。
在这个例子中,系统需要通过多步推理才能回答问题,因为问题的答案不直接在原始文本中给出。
在本文中,我们提出了RuleGuider,借助符号规则来解决上述基于步行的方法中的奖励问题。
我们希望在不失去可解释性的情况下提高基于步行的方法的性能。
RuleGuider由一个基于符号的模型(用于获取逻辑规则)和一个基于行走的代理(用于在规则的指导下获得搜索路径)。
我们还介绍了一种方法用于分离行走代理,以提高效率。
我们在不丧失可解释性的情况下,通过实验证明了我们模型的有效性。
问题和准备工作
在本节中回顾了KG推理任务。我们还描述了RuleGuider中使用的基于符号和基于行走的方法。
问题公式
一个三元组事实的KG表示为G={(ei,r,ej)}∈ε × R × ε。ε和R分别是一组实体和关系。
给出一个查询(es,rq,?),其中es是一个主体实体,rq是一个查询关系,这个只是推理任务是要找到一组对象实体Eo,就像(es,rq,eo),其中eo∈Eo,是G中缺少一个事实的三元组。我们将查询(es,rq,?)作为尾部查询,将(?,rq,eo)作为首部查询。为了与大多数现有工作一致,在这篇文章里我们值讨论尾部查询。
基于符号的方法
以前的一些方法从KG挖掘 Horn规则 ,并通过建立这些规则来预测遗漏的事实。
一种新的方法AnyBURL表现出与最先进的基于嵌入的方法相当的性能。它首先通过从G中采样路径来挖掘规则,然后通过将查询与规则匹配来进行预测。
规则形式如下:
r(X,Y)<—b1(X,A2)∩…∩bn(An,Y),其中大写字母表示变量。
一个规则头部被表示为r(…),一个规则体由通式联合表示为b1(…),…,bn(…)。r(ci,cj)与事实三元组(ci,r,cj)等价。
然而,这些方法有局限性。例如,从不同的KGs中挖掘出的规则可能具有不同的质量,这使得推理者很难选择规则。图1显示了这种差异。规则是根据预测目标实体的准确性进行排序的。WN18RR的顶级规则比FB15K-237的规则更有价值。
Horn规则由一个头部和一个可选的正体(也称为身体)组成,其中头部是一个单一的谓词,而正体则由多个谓词和它们的参数组成。
Horn规则的一般形式如下:
p(X1, X2, …, Xn) :- q1(X1, X2, …, Xn), q2(X1, X2, …, Xn), …, qm(X1, X2, …, Xn)
其中,p(X1, X2, …, Xn)是一个单一的谓词,表示规则的头部;q1(X1, X2, …, Xn), q2(X1, X2, …, Xn), …, qm(X1, X2, …, Xn)是多个谓词和它们的参数,表示规则的正体。
该规则表示如果q1(X1, X2, …, Xn), q2(X1, X2, …, Xn), …, qm(X1, X2, …, Xn)同时成立,则p(X1, X2, …, Xn)也成立。
Horn规则有以下几种形式:
形如 A → B 的规则,其中A和B均为谓词,表示如果A成立,则B也成立。这种规则也称为蕴含规则或条件规则。
形如 A ∧ B → C 的规则,其中A、B和C均为谓词,表示如果A和B同时成立,则C也成立。这种规则也称为合取规则或交集规则。
形如 ¬A ∧ B ∧ C → D 的规则,其中A、B、C和D均为谓词,表示如果A不成立且B和C同时成立,则D成立。这种规则也称为否定合取规则。
基于游走的方法
给定一个查询(es,rq,?),基于行走的方法训练一个RL代理来找一条从es到描述对象实体eo路径也就是查询关系r。在t步骤中,当前状态被表示成一个元组st=( et,(es,rq) ),其中et是当前实体。然后代理从可能的操作(At={ ( r’,e’ ) | (et,r’,e’)∈G})中采样要访问的下一个关系-实体对。
RuleGuider
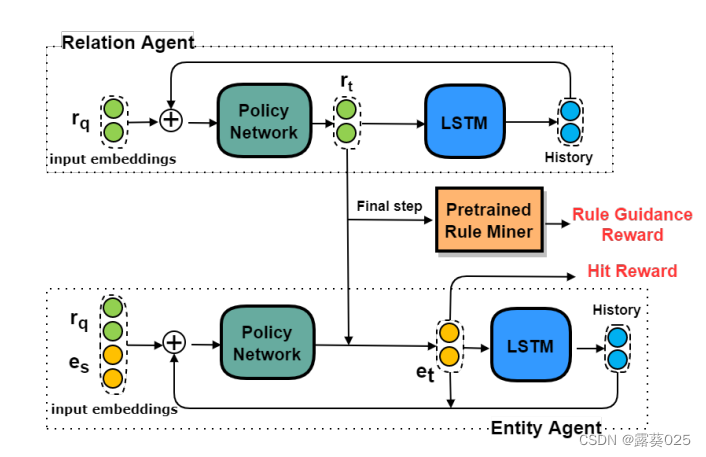
RuleGuider包括一个基于符号的方法(称为规则挖掘器),以及一个基于行走的方法(称为代理)。
规则挖掘器首先挖掘逻辑规则,代理遍历KG,以学习在规则指导下(通过奖励)推理路径的概率分布。当代理交替地穿过关系和实体时,我们建议将主体分为两个子主体:关系代理 和 实体代理。
在分离之后,搜索空间被显著地修剪。如图。
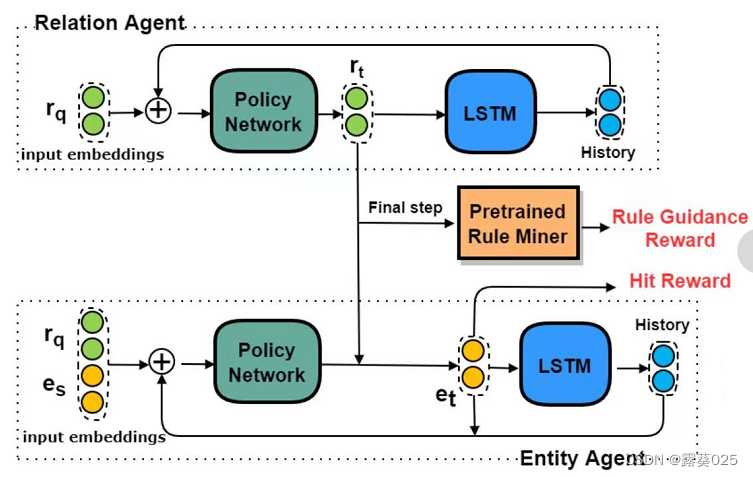
关系和实体代理相互作用以生成路径。在每个步骤中,实体代理首先从有效实体中选择一个实体。然后,关系代理基于所选实体对关系进行采样。在最后一步,他们根据最后的选择获得命中奖励,并根据所选路径从布雷前集合中获得规则指导奖励。
模型架构
关系代理
在第t跳中(t=1,…,T,T是跳数),关系代理选择一个 单一关系(single relation) rt,这是当前实体(et-1)的相关关系,其中e0=es。
给定一个查询(es,rq,?)和一组规则R,这个过程可以被构造为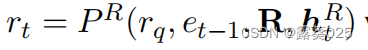 其中htR是 关系历史 。
其中htR是 关系历史 。
关系代理首先过滤掉规则中头部与rq不同的部分,然后关系代理首从剩余规则体中的第t个原子 中选择rt,即在规则模式中的bt(…)。
原子是指一个谓词和它的参数组成的语句,用于表示实体之间的关系。
由于规则挖掘器提供了规则的置信度分数,我们首先使用RL技术来使用分数对关系代理进行预训练。在训练过程中,关系代理运用预训练的策略,并通过 利用嵌入提供的语义信息(semantic information provided by embedding) 来不断调整分布。换句话说,关系代理既利用了预先挖掘规则的置信度,也利用了 embedding shaped hit rewards(基于嵌入向量的奖励) 。
在知识图谱中,single relation指的是一个实体与另一个实体之间只存在一个关系,也称为单一关系。
例如,如果在一个人物关系的知识图谱中,存在一个实体A表示"小明",另一个实体B表示"小红",并且它们之间只有一个关系"朋友",那么这个关系就是一个single relation。
relation history(关系历史)
是指一个实体与其他实体之间的关系变化历史记录。
知识推理中用于分析和推断实体之间的关系变化和演化。
在知识图谱中,实体之间的关系是动态变化的,因此了解关系的变化和演化对于推理和预测实体之间的关系非常重要。
关系历史可以通过记录实体之间的关系变化信息来构建。在知识图谱中,通常使用三元组(subject, predicate, object)来表示实体之间的关系,可以通过记录这些三元组的变化信息来构建关系历史。
semantic information provided by embedding(由嵌入提供的语义信息)
通常指的是通过将实体、关系和属性等信息映射到向量空间中,得到的向量表示所包含的语义信息。
具体来说,知识图谱中的实体、关系和属性等信息通常是以三元组(subject, predicate, object)的形式表示的。通过将这些三元组中的实体、关系和属性等信息映射到向量空间中,可以得到每个实体、关系和属性的向量表示,称为嵌入向量。这些嵌入向量可以通过神经网络等模型进行学习得到,每个嵌入向量的维度通常是事先设定好的。
由嵌入提供的语义信息通常指的是,通过这些嵌入向量所包含的关于实体、关系和属性等信息的语义信息。这些语义信息可以通过向量之间的距离、相似度等方式进行计算和应用,用于解决一些知识图谱中的任务,如实体识别、关系抽取、链接预测等。
embedding shaped hit rewards(基于嵌入向量的奖励)
通常指的是一种基于嵌入向量的知识图谱链接预测算法中的奖励机制。
具体来说,这种奖励机制通常用于链接预测任务中,即预测两个实体之间是否存在某种关系或属性。在这个任务中,嵌入向量通常用于表示实体和关系等信息。当预测的链接与实际链接相同时,算法会给予奖励,而当预测的链接与实际链接不同时,则会给予惩罚。
在embedding shaped hit rewards中,奖励的形状和大小取决于嵌入向量之间的相似度。如果预测的链接与实际链接之间的距离越小,则奖励越大;反之,如果距离越大,则惩罚越大。
实体代理
在t跳中,实体代理产生基于es,rq和实体历史htE生成所有候选实体的分布。
给出当前关系rt,这一过程可以被表示为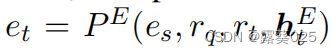 。
。
实体代理从所有与rt有关的实体选择一个实体。在这种方式下,实体和关系代理能够独立地推理。
在实验中,我们还试图让实体代理基于关系代理修剪的实体空间生成分布。通过这种方式,实体代理接收选定的关系,并可以利用关系代理的信息。然而,实体空间可能非常小,很难学习。这会降低实体代理的效率,尤其是对大而密集的KG。
policy Network(策略网络)
关系代理的搜索策略通过 嵌入 r q r_q rq和 h t R h_t^R htR来参数化 的。
嵌入 r q r_q rq和 h t R h_t^R htR来参数化
通常指的是一种将关系和实体等信息通过嵌入向量进行表示,并用向量之间的运算来进行推理的方法。
具体来说,嵌入 r q r_q rq和 h t R h_t^R htR来参数化的方法通常用于知识图谱中的链接预测和关系抽取等任务中。在这些任务中,模型需要根据已有的实体和关系等信息,预测新的实体和关系之间的联系。为了表示实体和关系等信息,可以将它们通过嵌入向量进行表示,得到 r q r_q rq和 h t R h_t^R htR的嵌入向量。
使用LSTM对关系历史进行编码:


模型学习
我们通过让前面提到的两个代理从特定的实体开始,在固定的跳数中遍历KG来训练模型。代理在最后一步获得奖励。
奖励设计
在给定查询的情况下,关系代理首选指向正确对象实体的路径。因此,给出一个关系路径,我们根据从规则挖掘器中检索到的置信度来给予奖励,称为规则指导奖励Rr。
我们还添加了拉普拉斯平滑pc = 5,来给最终Rr的置信度得分。
除了Rr,代理还将会接收一个命中奖励Rh,如果预测的三元组ε=(es,rq,eT)∈G时,Rh为1。否则我们使用ε的嵌入来测量奖励。Rh=
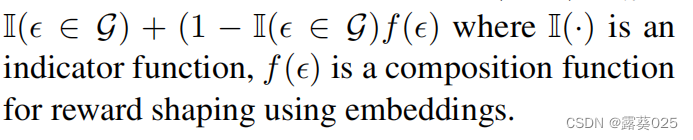
indicator function(指示函数)
通常用于表示某个实体是否具有某个属性或与某个实体存在某种关系等情况。
具体来说,对于一个实体e和一个属性P,其指示函数 I P ( e ) I_P(e) IP(e)定义为:
I P ( e ) = 1 , I_P(e) = 1, IP(e)=1,当实体e具有属性P时;
I P ( e ) = 0 , I_P(e) = 0, IP(e)=0,当实体e不具有属性P时。
类似地,对于一个关系R和两个实体e1和e2,其指示函数 I R ( e 1 , e 2 ) I_R(e1, e2) IR(e1,e2)定义为:
I R ( e 1 , e 2 ) = 1 , I_R(e1, e2) = 1, IR(e1,e2)=1,当实体e1和e2之间存在关系R时;
I R ( e 1 , e 2 ) = 0 , I_R(e1, e2) = 0, IR(e1,e2)=0,当实体e1和e2之间不存在关系R时。
训练过程
我们分四个阶段训练模型。
1) 使用基于嵌入的方法训练关系和实体嵌入。
2) 应用规则挖掘器来检索规则及其相关的置信度分数。
3) 通过 冻结实体代理(Freezing the entity agent) 并要求关系代理采样路径来预训练关系代理。我们只使用规则挖掘器来评估路径,并基于预先挖掘的置信度得分来计算Rr。
4) 联合训练关系和实体代理利用嵌入来计算Rh。最终用常数因子λ奖励R包括Rr和Rh: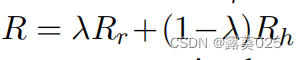
使用REINFORCE算法对两个代理的策略网络进行训练,以使R最大化。
"Freezing the entity agent"是指在知识图谱中的某些任务中,将实体的嵌入向量固定住,不再对其进行训练或更新。这种做法可以使得模型在处理实体相关的任务时,更加稳定和可靠,从而取得更好的效果。
REINFORCE算法
是一种基于策略梯度的强化学习算法,用于学习在某个环境中如何采取最优的动作,以获得最大的奖励或回报。
具体来说,REINFORCE算法通过学习一个策略函数,将当前状态映射到采取不同动作的概率分布上。在每个时刻,根据策略函数的输出,选择一个动作,并在环境中执行该动作,获得奖励或回报。根据获得的奖励或回报,可以计算出动作的梯度,从而对策略函数进行调整和更新。
EINFORCE算法的主要步骤如下:
1.初始化策略函数的参数。
2.在每个时刻t,根据当前状态 s t s_t st,使用策略函数计算出采取不同动作的概率分布,并根据概率分布选择一个动作a_t。
3.在环境中执行动作 a t a_t at,获得奖励或回报 r t r_t rt。
4.根据获得的奖励或回报,计算出动作 a t a_t at的梯度 ∇ l o g π ( a t ∣ s t ) ∇logπ(a_t|s_t) ∇logπ(at∣st),其中π表示策略函数。
5.根据梯度更新策略函数的参数,使得策略函数能够更好地预测最优的动作。
重复步骤2-5,直到达到预定的训练轮数或达到一定的收敛条件。
实验
在三个数据集上比较RuleGuider和其他的方法。
实验设置
数据集
三个数据集:FB15K-237、WN18RR、NELL-995
超参数
我们设置所有嵌入大小为200。每一个历史编码器是具有隐藏状态维度为200的一个3层LSTM。我们使用任意的BURL作为规则挖掘器,并将置信度得分的起点值设为0.15.其他超参数在附录中展示。
实验结果
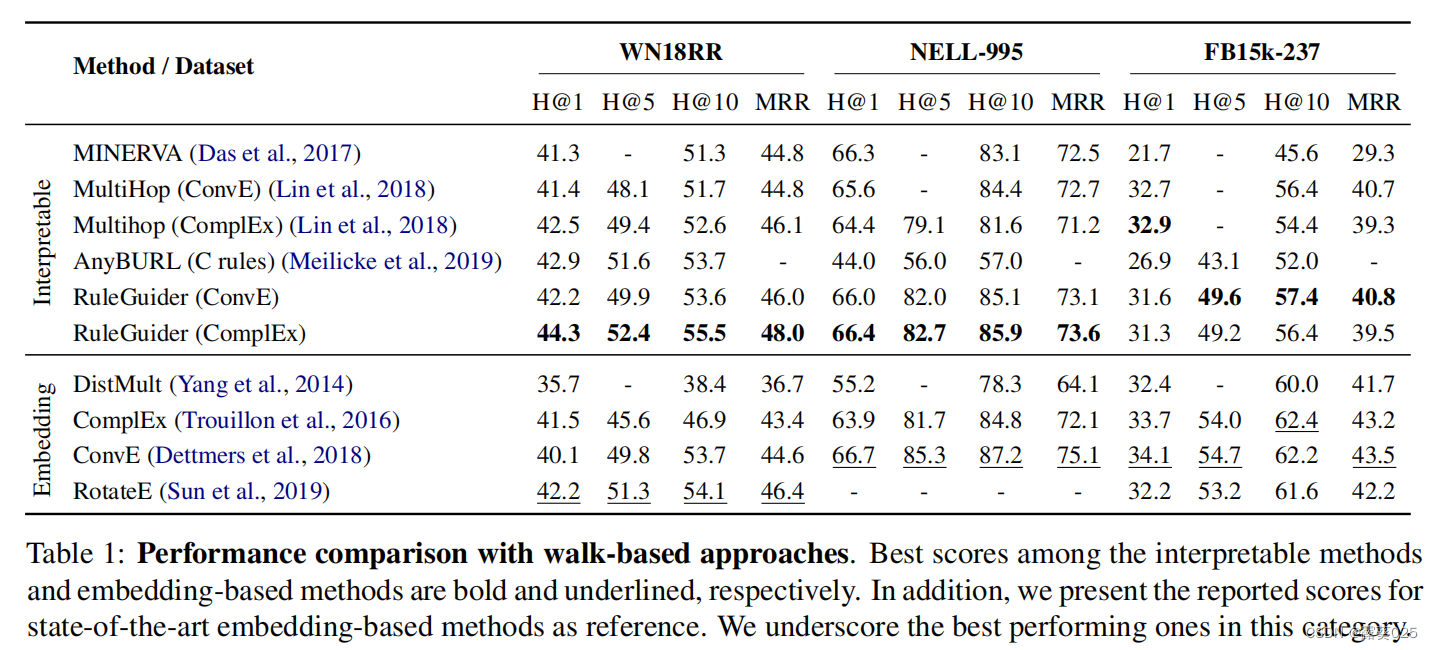
评价结果如表所示。
RuleGuider在WN18RR和NELL-995上展示了基于步行的最先进的结果,在FB15k-237上也展示了具有竞争力的结果。一个可能的原因是:与其他两个数据集相比,FB15k-237中的关系空间要大得多,并且在大型关系中规则相对稀疏路径空间,这使得关系主体更难选择所需的规则。
我们在WN18RR上找到了性能良好的基于符号的模型,并将λ设置得更高以获得更强的规则指导。
我们还观察到,我们还观察到,与基于步行的方法相比,基于嵌入式的方法在所有数据集上都有一致性能,尽管它们很简单。
一个可能的原因是,基于嵌入的方法将整个图的连通性隐含地编码到嵌入空间中。基于嵌入的算法不受图中严格遍历的约束,有时由于图的不完全性而受益于这种性质。通过利用规则,我们还结合了一些全局信息作为指导,以弥补 离散推理过程中潜在的搜索空间损失。
消融研究
人工评估
总结
首先,由于知识图谱数据稀疏,推理难以进行,为此提出了基于符号的方法——>但是基于符号的方法复杂,难以推广,为此提出了基于嵌入式的方法——>但基于嵌入式的方法解释性不好故而提出了基于行走的方法——>但是KG在行走过程中提供的稀疏奖励不足以指导复杂的基于行走的强化学习——>所以本文提出了RuleGuider方法,旨在不是去可解释性的基础上提高基于行走的方法的性能。
RuleGuider方法包括基于符号的模型和基于行走的代理。前者用于获取逻辑规则,后者用于在规则的指导下获得搜索路径。
且本文主要研究的是尾部查询。
关系代理先过滤掉所有规则中头部与 r q r_q rq不同的部分,再从剩余的规则体中的第t个原子中选择 r t r_t rt。用RL来使用规则挖掘器提供的规则执行度分数来对关系代理进行预训练。
实体代理从所有与 r t r_t rt有关的实体中选择一个实体。
关系代理与实体代理的协同工作:
-
实体代理提供实体的信息:实体代理负责对知识图谱中的实体进行处理和管理,并提供实体的基本信息,例如实体的类别、属性值、关系等。这些信息可以被关系代理用来进行关系的推理和判断。
-
关系代理推理关系:关系代理负责对知识图谱中的关系进行推理和判断,并根据实体代理提供的信息,推断实体之间的关系。例如,如果知识图谱中存在两个实体,但它们之间的关系没有被标注,关系代理可以通过分析实体的属性和关系,推断它们之间的关系。
-
实体代理更新实体:在关系代理推断出实体之间的关系后,实体代理可以根据关系的信息,更新实体的属性值和关系。例如,如果关系代理推断出两个实体之间存在某种关系,实体代理可以将该关系的信息添加到知识图谱中,并更新相应实体的属性值和关系。
-
关系代理验证关系:在实体代理更新实体后,关系代理可以再次对知识图谱中的关系进行验证和判断,以确保知识图谱的准确性和可靠性。如果发现某些关系不符合要求,关系代理可以对它们进行修正或删除。
















 2180
2180











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









